基于开源社区分析的API使用案例推荐服务
2022-11-30张佳琪孙艳春黄罡
张佳琪,孙艳春*,黄罡
基于开源社区分析的API使用案例推荐服务
张佳琪1,2,孙艳春1,2*,黄罡1,2
(1.北京大学 信息科学技术学院,北京 100871; 2.高可信软件技术教育部重点实验室(北京大学),北京 100871)(∗通信作者电子邮箱sunyc@pku.edu.cn)
目前有关API学习和代码复用的研究主要集中在对于API调用频繁模式的挖掘、组件化信息的提取以及根据用户的需求和目标功能进行的个性化应用程序接口(API)推荐服务等方面。然而,作为缺少专业知识和经验技能来完成特定使用案例的软件开发初学者,在阅读官方文档之外,往往需要真实的使用案例作为参考。现有代码推荐研究大多为单片段式代码,缺少跨函数的案例选择,这不利于初学者学习构建完整的使用场景或功能模块;同时,从单个函数注释中提取的语义描述也不足以构建学习者对项目中完整功能实现方法的认识。为了解决上述问题,提出了一种基于开源社区分析的API使用案例推荐服务,并以软件开发后端框架Spring Boot为例,构建了跨函数的案例推荐辅助学习服务。随后,通过调查问卷、专家验证等方式验证了所提出的API使用案例推荐服务的可行性和有效性。
代码复用;应用程序界面;开源社区分析;推荐服务;使用案例
0 引言
目前,对于软件开发学习者来说,可供选择的学习渠道包括官方文档、中英文博客、开源项目仓库以及问答社区等。官方文档的学习难度取决于文档的组织方式和内容编排,其理解在大多数情况下需要一定的领域知识,没有该领域开发经验的学习者难以理解文档作者展示的内容。而博客教程倾向于碎片化学习,且缺少质量评估,需要学习者拥有一定的搜索和选择能力。问答社区内容丰富,但初学者依然存在描述问题的困难,缺少从专业知识角度提出问题的能力。
相较于上述几种学习方法,软件开发初学者经常需要借助实际的使用案例帮助理解特定工具或应用程序界面(Application Program Interface, API)的使用方法和调用规则。在开源社区海量的开源项目仓库中,有广阔的该类学习资源,但并未被很好地挖掘出来。软件开发初学者依靠自身能力定位需要的API使用案例有一定的困难。
现有的代码案例推荐服务研究中,倾向于构建API功能描述或代码功能描述,匹配用户输入,呈现给用户片段式的代码内容。除官方文档专业性强的描述文本外,片段式代码的功能描述大多来自注释。但在实际学习过程中,单函数的注释并不能很好地体现代码内容在整体项目中的作用。本文面向拥有较少编码经验且缺少软件开发实战经验的初学者,搜集了79份调查问卷,统计问卷参与者在单函数注释对完成某一使用场景或功能的帮助效果上的意见,结果如表1所示。由表1可知,单片段的注释倾向于表述函数承担的细节任务,与项目实现的完整使用场景之间有一定的差别。
其次,软件开发初学者缺少将不同代码片段组建成完整功能模块的能力。例如,如何将博客教程给出的碎片化功能函数实例,在实际项目中很好地组合复用,对于缺少经验的开发者来说有一定难度。又如,在面向对象编程过程中,开发者倾向于用不同代码文件中定义的类成员函数共同实现项目的完整功能,单一片段的实例不足以帮助用户理解它在整体项目中的复用方法。

表1 单函数注释对完成某一使用场景或功能的帮助效果的问卷调查结果
为此,本文提出了一种基于开源社区分析的API使用案例推荐服务,为初学者提供快速定位特定API及某一使用场景案例,以及进行跨函数案例代码学习的工具。
本文的主要工作包括:
1)提出了一种面向软件开发初学者的API使用案例推荐服务,解决初学者学习软件开发时难以获取以使用场景为粒度划分的参考案例的问题。
2)提出了一种基于开源社区分析的跨函数API使用案例构造与分析方法,采用静态代码分析方法,从开源项目中抽取使用场景实例,进行面向用户的评估与推荐。
1 相关工作
1.1 开源社区分析
迄今为止,以GitHub、Stack Overflow等平台为研究对象的开源社区分析研究基本涵盖到开发人员从入门到编码、协作、测试的方方面面,其中包含了对于用户、项目、问答内容等不同方面的数据分析。一方面,研究人员利用现存的大量开源社区数据,针对用户特性个性化推荐学习领域、协作人员,为待完成Issue或问答社区问题寻找可能的解答者,优化社区人员体验;另一方面,研究人员利用开发者已有的项目成果进行领域知识挖掘和文档重构,为开发者的学习、检索和复用提供不同粒度的支撑。
Seker等[1]对于GitHub的已有研究进行了二次分析,对GitHub开源数据集GHTorrent上的重要研究内容和较高质量论文的主题分布进行了总结。最终,论文总结出四个主要主题:项目、用户、数据及行为。每个主题都有多个相关子主题,如Issue、提交说明等,表明GitHub开源数据的流行研究方向和热门课题。GHTorrent是目前使用最广的GitHub开源数据集,在GitHub相关数据研究方面具有一定的代表性[2]。
在与开发者或学习者相关的研究课题中,主要研究内容集中在开发者的辅助开发活动上。如陈丹等[3]对开源社区中已有开发者的合作行为模式做了分析,探索开发人员建立新合作关系的方式以及合作关系建立的影响因素。Rahman等[4]提出了一种代码审核人员的推荐工具CORRECT,通过对开发人员跨项目的相关工作经验以及特定技术经验的分析,以推荐潜在的审核者。Montandon等[5]针对软件开发者技术能力水平难以衡量的问题,提出了一种基于GitHub数据的特征聚类,实现在现今流行的库和框架的开发人员中筛选专家级别的开发者的技术。此外,关联多开源平台进行数据分析与挖掘[6],构建开源社区数据集[7-8],也是这方面研究的重要内容。
综合上述分析,对于软件开发初学者而言,其学习需求并不需要很高专业度的人员才能满足。如学习者通过博客和问答社区寻找答案,查找教程的过程中并不存在严格审查回答者技术能力的过程。其次,初学者在学习入门阶段往往需要独立学习,在获得一定程度专业知识的基础后再进行协作开发。现有的开源社区分析研究并没有在面向初学者的方向上帮助他们解决初步的入门问题,而是集中于提升其成为社区开发者后的开发体验。
1.2 API推荐及代码推荐
目前大量软件开发集成工具包或API库,给编码人员的选择带来了一定的困难。如npm.js集成发布的JavaScript编程语言API,面对同一关键词搜索下,同一功能的不同工具包,经验不足的学习者并不能快速确定目标并进行使用。
Zerouali等[9]的研究工作详细分析了一个开源包的流行度衡量标准及影响因素,从GitHub、libraries.io和npm.js三个官方网站寻找指标数据,并分析它们之间的相关关系。但是结果表明,不同平台的指标之间没有太大的相关性,无法简单通过单一指标得到普遍结果,需要经过考量设计得到认可度高的评估选择框架。
API推荐研究一般从开源问答社区、官方文档和源代码中提取有关API的语义,匹配用户需求。张云帆等[10]的研究工作提出了一种基于自然语言语义相似度的推荐方法,通过查询信息和描述信息的语义相似度进行推荐选择。Lin等[11]设计了一种识别用户查询中包含潜在API的方法。从软件源代码中提取软件实体概念以及它们之间的关系,填补互联网上学习资源文档中缺少的知识空白。
Huang等[12]的研究同样致力于解决用户查询和API之间的匹配问题,将Stack Overflow和API文档合并,利用Stack Overflow中的帖子补充API信息。类似的研究还有Nie等[13]提出的代码搜索方法QECKRocchio。Xie等[14]的研究认为Stack Overflow问答社区涉及的API只包含大众流行度较高的部分,而基于纯文档的API检索又通常会产生较差的结果,所以试图通过官方文档构建API功能描述辅助API检索识别。
除此之外Shatnawi等[15-16]的研究认为,组件级别的代码复用比原有的面向对象的复用更加有效。在组件粒度上的API方法具有其功能语义,并且在内部结构中展示出相互之间的依赖关系。Matos等[17]的研究从拆分大的API库为小型API的目的出发,解决大型API复杂结构使用户很难快速学习和使用它们的问题。
在代码推荐方面,杨程等[18]提出了一种基于多维特征的开源项目个性化推荐方法,从开源项目自身流行度、关联项目技术相关度以及大众贡献者之间的社交关联度这三个维度的特征衡量开发者和开源项目之间的关联关系,为开发者提供个性化的项目推荐服务。Shen等[19]则设计了一种名为NLI2Code的抽象框架,通过基于库文档的功能特征提取、代码模式挖掘及填补中间变量三步过程生成推荐代码。Zimmerman等[20]则面向尝试学习常见算法的新手程序员,基于图形匹配和树编辑的方法提出了一种识别正在编写的代码的可能目标,从而推荐编码相关操作的框架。
综合上述分析,现有API推荐研究的主流思想在于匹配用户自然语言形式需求描述和API功能描述。通过开源代码重新分析API之间的组合关系,挖掘可复用的使用模式是其中的核心研究内容。代码推荐则需要对可选项目给出一定的评价标准,可以是从API角度的调用分析,也可以是基于开发者本身、项目流行度等多维度特征设计出的评价指标,总体上多为单片段代码推荐和生成,缺少跨函数的分析结果。对于代码案例的功能描述,多从注释获取信息,片段性的解释说明缺少对整体功能或场景的描述。对于初学者而言,这些不利于案例的理解与复用。
2 案例推荐服务的架构
本文提出的案例推荐服务架构如图1所示。
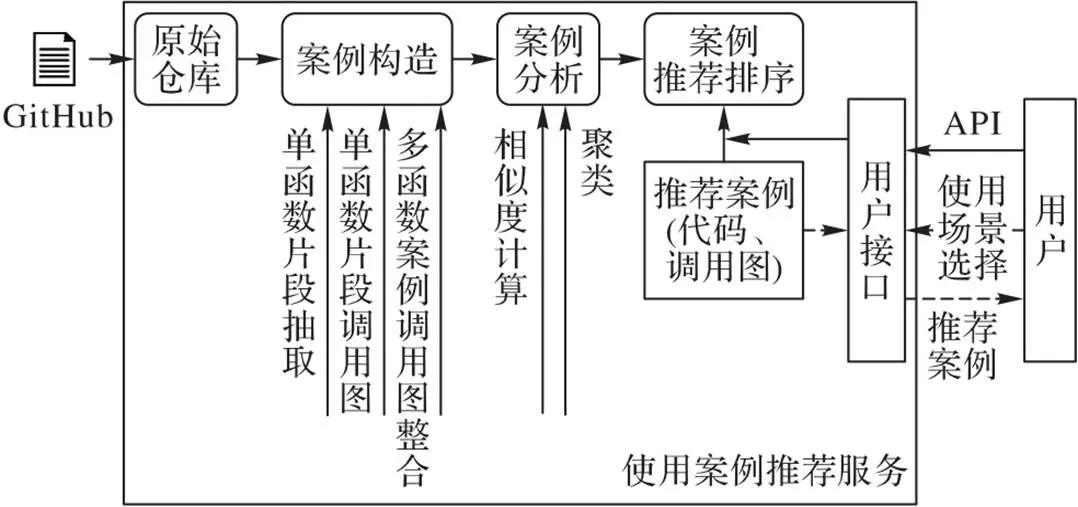
图1 案例推荐服务的系统架构
2.1 案例构造
2.1.1单函数片段抽取
在代码或API推荐、检索研究中,主要通过动词短语的提取划分功能或场景描述。本文对于使用场景的划分,主要通过前后端交互的动词形式监听接口实现。在实际开发过程中,开发者之间的协作要求和高质量项目的严谨性,要求前后端交互的接口路径名满足一定的可理解性,并在语义上符合代码实现内容。因此,本文以后端项目为例,以前后端交互请求的接收为入口构建案例。每一案例有统一明确的入口,其余用户函数的调用也将符合该入口处的功能描述。
本文选择Spring Boot框架实现的3 000个GitHub开源项目,识别监听接口注解代码行并抽取其中的URL命名,通过驼峰命名法切词并对特殊字符作额外处理,统计包含的动词描述。在得到的结果中,选择语义信息明确且拥有超过300个案例的动词作为选定使用场景,得到的7个使用场景分类如表2。案例数量少于300的使用场景不能很好地满足后续分析筛选的需要;同时,样本数量在数据集中较少,也说明在开发过程中学习需求较低,我们优先为初学者提供学习需求更大的场景选择。
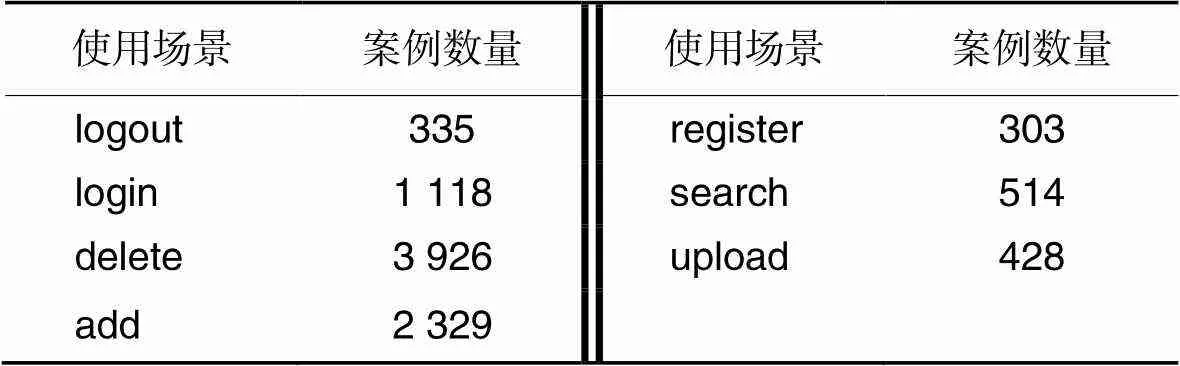
表2 不同使用场景下的案例数量
本文尝试标注每一条识别到的注解所处的代码文件,以及行标,以此匹配函数内容。对于单个文件,通过抽象语法树的分析和处理,将每一个函数方法按照一个整体剥离出来,识别每一行中各个元素的类别,并标注行数。对于这些含有文件即方法行数信息的函数处理结果,与注解相匹配,从而得到每个注解代表的请求入口函数片段。
抽取文件头部引用的包及类,确定可选范围,若是用户类,则通过引入的名称确定文件位置;若是API类,则留待后续API调用的提取和处理。同时,在代码段内,通过抽象语法树分析每一行代码,遍历其中有关函数调用和类对象声明部分,识别该代码段是否引用了用户函数。如果引用了用户函数,则定位指示的用户文件和用户函数,从而得到将该函数片段加入同一案例代码片段集合中。
每个使用场景分类下有多个候选案例,每个候选案例由一或多个代码片段组成。对于每个代码片段,抽取后续案例分析过程中需要的API调用信息。根据相关研究内容及本文分析需要,给出以下节点和边关系抽取规则:
1)节点分为以下几种:API类对象声明节点、API方法调用节点、参数生成和更改节点、用户类对象声明及更改节点。其中用户类和用户方法的节点便于不同文件代码片段的关联。
2)边关系分为以下几类:顺序执行连边、依赖连边、嵌套调用连边。其中嵌套调用表示在一个方法中的参数部分调用了下一个方法。
根据以上规则,可将每个函数的代码片段表示为图结构。如下所示代码实例和图2的调用图实例表示,其中图2为此代码片段按照规则表示的调用图。
@PostMapping(“/register”)
@ResponseBody
Public ResultVO register(User user){
userService.registerUser(user);
return ResultUtils.success();}
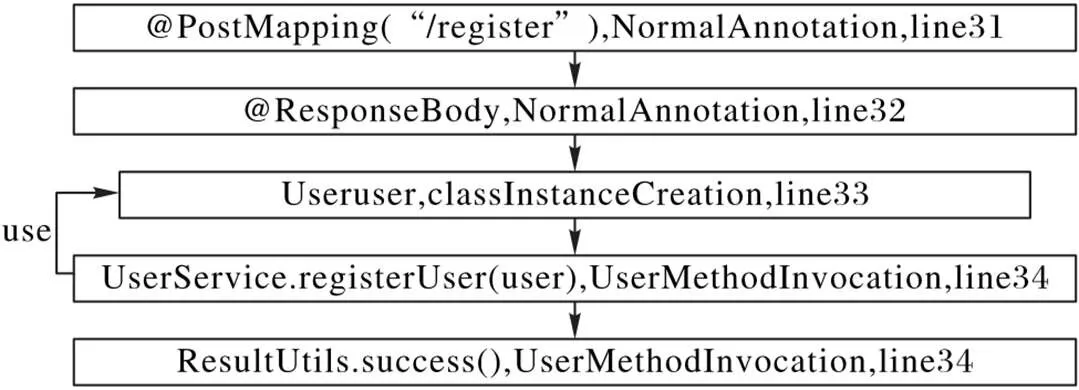
图2 对象函数调用图
2.1.2多函数片段融合
对于一个项目工程来说,一个使用场景的实现绝大多数情况下不可能单纯通过一个函数完成,虽然我们的初步图示在单个函数的粒度上构建,但对于不同的函数的图示,需要一个融合的过程。融合过程如图3所示。在一个函数的图结构中,如果主体函数中识别到某个用户函数的调用,则需要将该用户函数的图结构加到主体函数图结构中。主体函数中,指向该用户函数的节点,更改为指向用户函数图结构的入口节点;主体函数中,该用户函数指向的节点,改为由用户函数图结构出口节点指向。图3(b)中调用函数的节点在融合后消失,指向它的节点改为指向函数图的入口节点,A函数图的出口节点则改为指向原本主体函数中调用A函数的节点指向的节点。
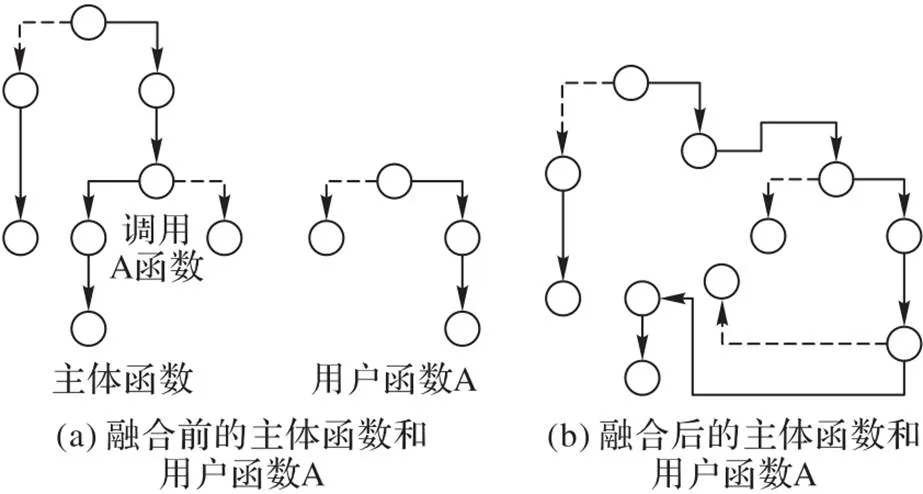
图3 融合前后的主体函数
2.2 案例分析
2.2.1案例相似度评估
基于抽象语法树结构统计特征向量[21]、基于调用序列挖掘频繁模式挖掘[18,22-23],都是常用的代码流程图降维分析方法。在此基础上,Nguyen等[24]提出了更有弹性的图方法进行模式挖掘和异常检测任务。该团队提出了具体的基于面向对象的源代码构建API方法调用图规则和算法设计[25]。Gu等[26]的工作及Chen等[27]的工作都沿用了类似的思想,并采用了图核[28]、图卷积等方法进行API调用代码分析。
本文采用图核算法进行分析处理,没有将图结构降维到向量空间的步骤,而是直接将核函数应用到图结构数据上,在很大程度上保留了结构化信息,为跨函数代码调用流程图的分类和聚类提供重要的中间手段。
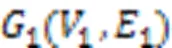
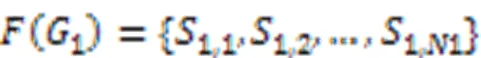
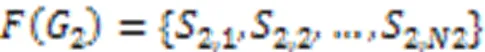
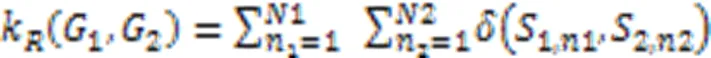
2.2.2聚类及推荐算法设计
在最短路径核计算的相似度矩阵中,存在相似度基本为0的同一使用场景实现案例。对此,根据上述图核计算得到的两两图对之间的相似度矩阵,经过谱聚类方法处理,采用类内平均相似度比类间平均相似度作为判别指标初步划分相似实现代码,从而给用户推荐每一相似实现方式集合下的最高推荐排序案例。
对于一个案例代码,衡量它对于所属类的代表性,本文参考Gu等[26]通过案例类内中心性和特异性排序的方法,给出三个重要指标:
1)它在这个类别中的中心性,中心性越高,则该案例对于所属类的代表作用越强。
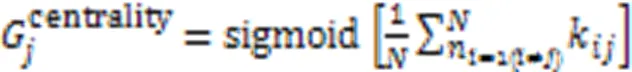
2)它在这个类别中的特异性,特异性越高,它在这个类别中的代表性越低。比如一些不常调用的API,对于软件开发初学者而言,增加了学习和理解的困难,因此需要降低它的推荐排名,尽量推荐更方便理解的开发案例。

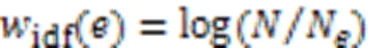
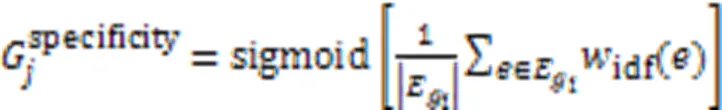
3)在面向初学者时,API选择的流行程度,越是被大多数项目选择的API,在学习者学习使用场景开发时越有必要被推荐学习。
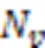
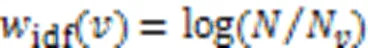
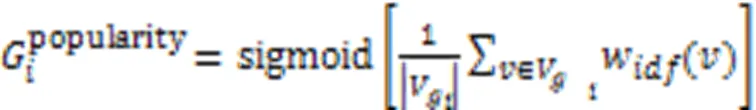
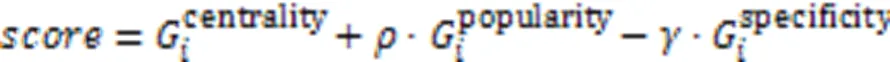
在按照上述推荐指标计算并排序得出的结果中,选择每类得分前5的案例推荐给学习者。
2.3 案例推荐服务
初学者存在两种类型的学习需求:第一种学习需求为选定目标API,学习其使用方式;第二种学习需求为不确定可用API,学习使用该框架或包进行场景或功能的实现。
本文设计的案例推荐服务允许用户可选地指定API,并在已有的推荐排序结果中筛选符合项,给出包含该API应用的使用案例。同时,也为学习者提供从使用场景出发的案例推荐,学习者可以在学习过程中了解可用的API。
本文以Spring Boot为例,实现了API使用案例推荐服务初学者可以搜索指定的API、选择使用场景并选择学习该推荐服务所推荐的案例。图4为推荐服务的案例学习界面,为用户提供代码片段、片段所在文件完整代码及调用图。用户跳转查看同意案例的不同片段,调用图标注相应节点颜色。
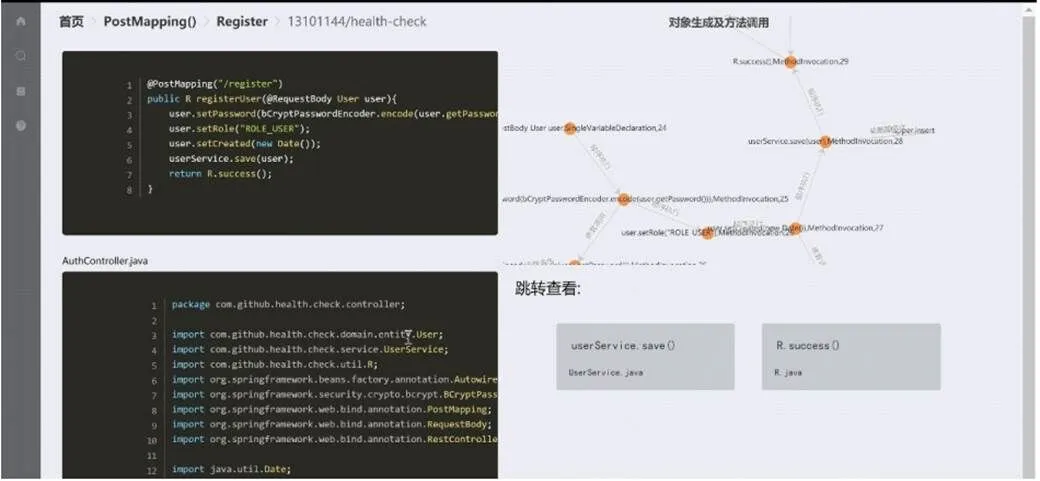
图4 推荐服务的案例学习界面
3 案例推荐服务验证
3.1 用户需求验证
对于用户需求的验证,主要以调查问卷的形式进行,调查用户对于实际案例辅助学习API效果的需求和本推荐服务所推荐的案例评价。
问卷面向某高校拥有一定编程经验的计算机专业本科生,共收集62份反馈结果,统计其中API学习方式使用情况和本文选取的使用场景是否符合用户需求,具体结果如表3示。同时,给出本文推荐服务排序后选择的推荐案例,统计有过后端开发经验的21人和没有后端开发经验的41人的评价,结果如表4、表5所示。表中的“占比”均指相应项目评价人数占总调查人数的比例。
从表3~5可以看出,不论是后端框架的初学者还是已有一定技术知识储备的学习者,本服务给出的推荐结果都有很高比例的认同,在帮助作用、代表性、可理解性上给出了较高评价。初学者在可理解性上的评价略低于有一定技术能力的学习者,有经验的学习者在帮助程度上的评价略低于初学者。这种调查结果符合预期,以及本推荐服务侧重初学者的推荐特点。
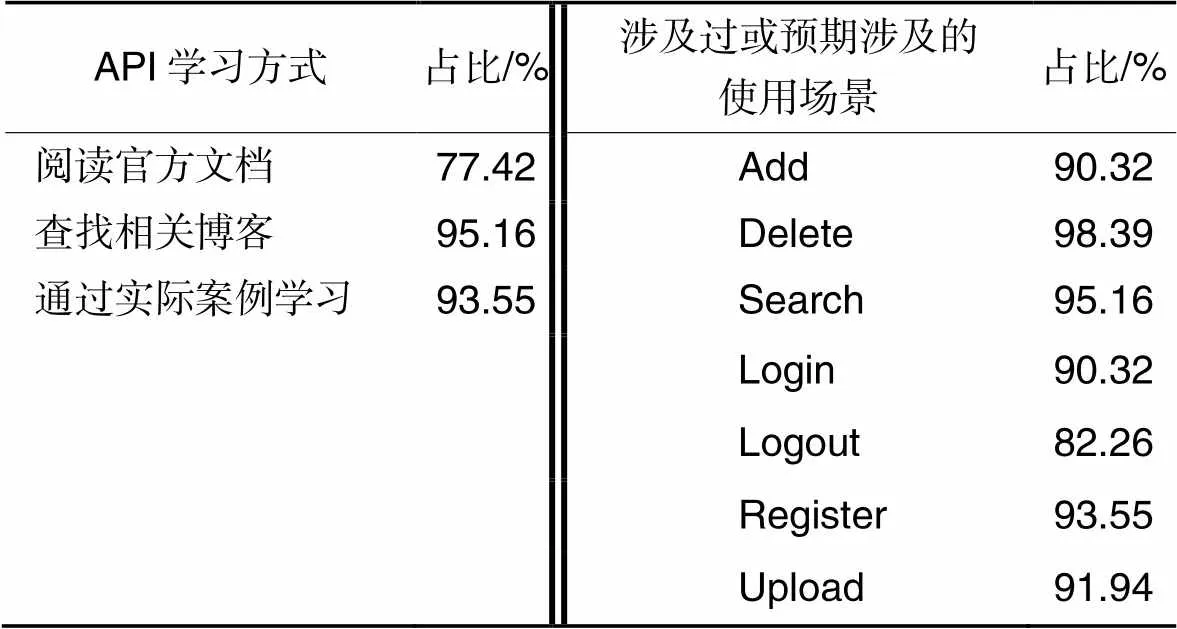
表3 API学习方式和本文选取的使用场景的问卷收集部分结果

表4 无经验开发者评价结果
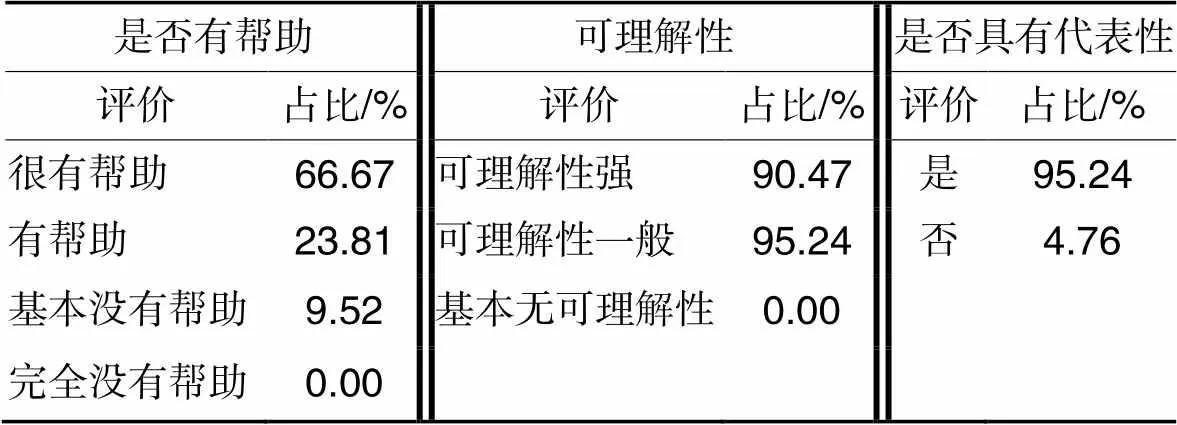
表5 有经验开发者评价结果
3.2 信息抽取验证
本文信息抽取规则在已有研究的基础上做了部分调整,用于后续分析处理。同时,以流程图的形式随案例一起推荐给用户,辅助用户理解案例内容。本节主要审查本文抽取代码行结果是否属于案例及API使用的重点信息,审查中间过程。
选择35个候选案例(每个场景分类下选择5个),通过两个对Java编程有三年以上经验且拥有后端开发经验的人员,标注他们所认为对该案例中体现API使用方法和逻辑框架的较重要的代码行,代码行数量为该案例中本文方法抽取结果行数上下浮动20%,比对结果如表6。其中的重合率为本文抽取的代码行占标注者认为重要代码行的比率。从表6结果可以看出,本文抽取内容可以反映大部分案例代码重点部分。标注结果和抽取结果差异性的造成有一定标注者总标注代码行不确定的原因,使得选择的代码行比本文抽取内容更精细或粗糙。

表6 信息抽取验证结果
3.3 推荐结果验证
第二部分验证主要针对的是推荐服务的推荐结果是否具有代表性和可理解性,以及基于图方法得出的结果与相关工作中采用特征向量抽取得到的结果相比是否具有更优效果。由于选择的Spring Boot后端框架项目代码缺少量化的评价指标,因此选择专家验证的方式。
抽取本文推荐算法排序中排名最高的5个代码案例,并在之后的代码案例中随机抽取20个。其次,在同样的原始数据上通过特征向量主导的API特征向量抽取和处理得到推荐结果,并选择同样数量的验证案例。由两个有四年及以上Java编程经历,拥有Spring Boot开发实践经历,且进行过三年及以上软件开发实践和实践指导的人员对这些案例做出评价,具体评价指标如下:
1)选择代码案例中个人认为可理解性和代表性最佳的5个案例,并给出排序。结果显示,案例与使用场景定义100%相符。这说明本文选择的使用场景划分方式能够正确对应代码案例内容。
2)选择代码案例中个人认为可理解性和代表性最佳的10个案例,并给出排序,结果如表7所示,其中的命中率即专家在给出的推荐排序中,选中的服务推荐结果与最多可选中的推荐结果之比。由表7可知,本文基于图方法得到的相似度度量和聚类排序,比通过特征向量抽取得到的结果认可度更高。后端API的开发实例,在保留结构化信息的处理方法下,经过筛选能得到更具有代表性的代码案例。

表7 推荐案例专家验证结果 单位: %
4 结语
本文提出了一种API学习案例推荐服务,相较于其他API及代码推荐研究,本文没有从单片段代码出发进行分析挖掘,而是基于更大粒度的多函数功能模块进行API推荐研究。同时,没有通过单函数注释抽取代码功能描述,而是从监听请求入口,得到概括性语义特征。这种较高抽象粒度的场景选择可以满足初学者的大部分学习需求。例如,初学者尝试构建论坛式网络应用,基本功能包括用户的登录注册、帖子的发布删除及搜索,均在本文所选使用场景的实现范围之内。
未来,我们将在以下方面进一步改进:首先,进一步细化使用场景的划分。在实际学习过程中,学习者会有更细粒度的案例需求,如在学习注册场景的实现时,允许指定常用注册方式可以优化用户的体验,提供更细粒度的帮助。其次,本文通过GitHub开源仓库获取候选案例,没有经过更精细的筛选,个别大型仓库中同一类使用场景的案例数量较多,API用法相似,在相似性度量和聚类排序过程中存在一定优势,更易被选中作为推荐案例。在后续工作中,可以通过改进评价指标等方式弥补现有方法的不足。最后,本文选择以Spring Boot为例实现推荐服务,而目前还有其他流行的API库。结合多编程语言分析方法,可以在不同的前后端场景中实现案例构造与分析处理。
[1] SEKER A, DIRI B, ARSLAN H, et al. Open source software development challenges: a systematic literature review on GitHub[J]. International Journal of Open Source Software and Processes, 2020, 11(4): 1-26.
[2] GOUSIOS G, SPINELLIS D. GHTorrent: GitHub’s data from a firehose[C]// Proceedings of the 9th IEEE Working Conference on Mining Software Repositories. Piscataway: IEEE, 2012: 12-21.
[3] 陈丹,王星,何鹏,等. 开源社区中已有开发者的合作行为分析[J]. 计算机科学, 2016, 43(6A):476-479, 501.(CHEN D, WANG X, HE P, et al. Towards understanding existing developers’ collaborative behavior in OSS communities[J]. Computer Science, 2016, 43(6A):476-479, 501.)
[4] RAHMAN M M, ROY C K, REDL J, et al. CORRECT: code reviewer recommendation at GitHub for Vendasta technologies[C]// Proceedings of the 31st IEEE/ACM International Conference on Automated Software Engineering. New York: ACM, 2016: 792-797.
[5] MONTANDON J E, SILVA L L, VALENTE M T. Identifying experts in software libraries and frameworks among GitHub users[C]// Proceedings of the IEEE/ACM 16th International Conference on Mining Software Repositories. Piscataway: IEEE, 2019: 276-287.
[6] MANES S S, BAYSAL O. How often and what StackOverflow posts do developers reference in their GitHub projects?[C]// Proceedings of the IEEE/ACM 16th International Conference on Mining Software Repositories. Piscataway: IEEE, 2019:235-239.
[7] BALTES S, DUMANI L, TREUDE C, et al. SOTorrent: reconstructing and analyzing the evolution of stack overflow posts[C]// Proceedings of the ACM/IEEE 15th International Conference on Mining Software Repositories. New York: ACM, 2018: 319-330.
[8] BALTES S, TREUDE C, DIEHL S. SOTorrent: studying the origin, evolution, and usage of stack overflow code snippets[C]// Proceedings of the IEEE/ACM 16th International Conference on Mining Software Repositories. Piscataway: IEEE, 2019: 191-194.
[9] ZEROUALI A, MENS T, ROBLES G, et al. On the diversity of software package popularity metrics: an empirical study of NPM[C]// Proceedings of the IEEE 26th International Conference on Software Analysis, Evolution and Reengineering. Piscataway: IEEE, 2019: 589-593.
[10] 张云帆,周宇,黄志球. 基于语义相似度的API使用模式推荐[J]. 计算机科学, 2020, 47(3): 34-40.(ZHANG Y F, ZHOU Y, HUANG Z Q. Semantic similarity based API usage pattern recommendation[J]. Computer Science, 2020, 47(3): 34-40.)
[11] LIN Z Q, ZOU Y Z, ZHAO J F, et al. Improving software text retrieval using conceptual knowledge in source code[C]// Proceedings of the 32nd IEEE/ACM International Conference on Automated Software Engineering. Piscataway: IEEE, 2017: 123-134.
[12] HUANG Q, XIA X, XING Z C, et al. API method recommendation without worrying about the task‑API knowledge gap[C]// Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering. Piscataway: IEEE, 2018: 293-304.
[13] NIE L M, HE J, REN Z L, et al. Query expansion based on crowd knowledge for code search[J]. IEEE Transactions on Services Computing, 2016, 9(5): 771-783.
[14] XIE W K, PENG X, LIU M W, et al. API method recommendation via explicit matching of functionality verb phrases[C]// Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. New York: ACM, 2020: 1015-1026.
[15] SHATNAWI A, SHATNAWI H, SAIED M A, et al. Identifying software components from object‑oriented APIs based on dynamic analysis[C]// Proceedings of the 2018 ACM/IEEE 26th International Conference on Program Comprehension. New York: ACM, 2018:189-199.
[16] SHATNAWI A, SERIAI A, SAHRAOUI H, et al. Mining software components from object‑oriented APIs[EB/OL]. (2016-06-02)[2021-05-06]. https://arxiv.org/pdf/1606.00561.pdf.
[17] MATOS A S, FERREIRA FILHO J B, ROCHA L S. Splitting APIs: an exploratory study of software unbundling[C]// Proceedings of the 2019 IEEE/ACM 16th International Conference on Mining Software Repositories. Piscataway: IEEE, 2019: 360-370.
[18] 杨程,范强,王涛,等. 基于多维特征的开源项目个性化推荐方法[J]. 软件学报, 2017, 28(6): 1357-1372.(YANG C, FAN Q, WANG T, et al. Multi‑feature based personal recommendation approach for open source project[J]. Journal of Software, 2017, 28(6): 1357-1372.)
[19] SHEN Q, XIE B, ZOU Y Z, et al. NLI2Code: reusing libraries with natural language interface[C]// Proceedings of the 2019 International Conference on Software and Systems Reuse, LNCS 11602. Cham: Springer, 2019: 168-184.
[20] ZIMMERMAN K, RUPAKHETI C R. An automated framework for recommending program elements to novices[C]// Proceedings of the 30th IEEE/ACM International Conference on Automated Software Engineering. Piscataway: IEEE, 2015: 283-288.
[21] KIM J, LEE S, HWANG S W, et al. Enriching documents with examples: a corpus mining approach[J]. ACM Transactions on Information Systems, 2013, 31(1): No.1.
[22] ZHONG H, XIE T, ZHANG L, et al. MAPO: mining and recommending API usage patterns[C]// Proceedings of the 2009 European Conference on Object‑Oriented Programming, LNCS 5653. Berlin: Springer, 2009: 318-343.
[23] WANG J, DANG Y N, ZHANG H Y, et al. Mining succinct and high‑coverage API usage patterns from source code[C]// Proceedings of the 10th Working Conference on Mining Software Repositories. Piscataway: IEEE, 2013: 319-328.
[24] NGUYEN T T, NGUYEN H A, PHAM N H, et al. Graph‑based mining of multiple object usage patterns[C]// Proceedings of the 7th Joint Meeting of the European Software Engineering Conference and the ACM SIGSOFT Symposium on the Foundations of Software Engineering. New York: ACM, 2009: 383-392.
[25] NGUYEN T T, PHAM H V, VU P M, et al. Learning API usages from bytecode: a statistical approach[C]// Proceedings of the IEEE/ACM 38th International Conference on Software Engineering. New York: ACM, 2016: 416-427.
[26] GU X D, ZHANG H Y, KIM S. CodeKernel: a graph kernel based approach to the selection of API usage examples[C]// Proceedings of the 34th IEEE/ACM International Conference on Automated Software Engineering. Piscataway: IEEE, 2019: 590-601.
[27] CHEN C, PENG X, XING Z C, et al. Holistic combination of structural and textual code information for context based API recommendation[J]. IEEE Transactions on Software Engineering, 2022, 48(8): 2987-3009.
[28] BORGWARDT K M, KRIEGEL H P. Shortest‑path kernels on graphs[C]// Proceedings of the 5th IEEE International Conference on Data Mining. Piscataway: IEEE, 2005: 74-81.
Recommendation service for API use cases based on open source community analysis
ZHANG Jiaqi1,2, SUN Yanchun1,2*, HUANG Gang1,2
(1,,100871,;2(),100871,)
Current research on Application Program Interface (API) learning and code reuse focuses on mining frequent API usage patterns, extracting component information, and recommending personalized API services based on user requirements and target functions. However, as beginners in software development who lack professional knowledge, experience and skills to implement specific use cases, they often need real code use cases as a reference except reading official documents. Most of the existing research about code recommendation is in single fragment mode. The lack of cross function case in case selection is not conducive for beginners to learn to build a complete use scenario or a functional module. At the same time, the semantic description extracted from a single function annotation is not enough for learners to understand the complete function implementation method of the project. To solve the above problems, an API use case recommendation service based on open source community analysis was proposed. Taking the software development back‑end framework Spring Boot as an example, a cross function case recommendation assistant learning service was constructed. Then, the feasibility and effectiveness of the proposed API use case recommendation service was verified through questionnaires and expert verification.
code reuse; Application Program Interface (API); open source community analysis; recommendation service; use case
This work is partially supported by Beijing Outstanding Young Scientist Program (BJJWZYJH01201910001004).
ZHANG Jiaqi, born in 1999, M. S. candidate. Her research interests include service computing, big data analysis.
SUN Yanchun, born in 1970, Ph. D., associate professor. Her research interests include service computing, big data analysis.
HUANG Gang, born in 1975, Ph. D., professor. His research interests include system software, self‑adaption.
1001-9081(2022)11-3520-07
10.11772/j.issn.1001-9081.2021122070
2021⁃12⁃07;
2022⁃01⁃02;
2022⁃01⁃13。
北京高等学校卓越青年科学家项目(BJJWZYJH01201910001004)。
TP311
A
张佳琪(1999—),女,河北石家庄人,硕士研究生,主要研究方向:服务计算、大数据分析;孙艳春(1970—),女,辽宁沈阳人,副教授,博士,CCF高级会员,主要研究方向:服务计算、大数据分析;黄罡(1975—),男,湖南株洲人,教授,博士,CCF会员,主要研究方向:系统软件、自适应。
