基于多特征场景描述的闭环检测方法
2022-11-22王通典刘洁瑜吴宗收李文华
王通典, 刘洁瑜, 吴宗收, 李文华, 沈 强
(火箭军工程大学导弹工程学院,西安 710000)
0 引言
同时定位与地图构建(SLAM)是移动载体实现自主定位导航与路径规划的关键技术。视觉里程计在长时间、大范围的位姿估计过程中,不可避免会导致累计误差的产生,较大的累计误差会严重影响定位精度,甚至导致算法收敛到完全错误的值。而闭环检测是SLAM问题的重要组成部分[1],闭环检测系统可以准确高效地检测出当前场景是否存在于历史场景中,从而消除里程计产生的累计误差。
闭环检测是通过对比当前场景与历史场景的相似性从而判断移动载体是否经过同一位置,该问题本质上是一个场景识别问题[2]。基于外观相似性的闭环检测方法是词袋模型(BoW)方法[3]。词袋模型的方法是对图像提取的局部特征采用K-means的方式实现聚类生成视觉词典,随后对查询的场景特征设置相应权重,将查询场景的特征向量和历史场景的特征向量利用单词量化,进行相似性对比从而识别闭环。FAB-MAP[4]在BoW基础上结合贝叶斯模型实现闭环检测方法,该方法在构建观测模型时采用LIU树拟合词汇间的拓扑关系,从而实现观测概率计算,该方法在计算观测似然时计算时间较长,为此后续提出了FAB-MAP2.0[5]以缩短算法用时。ANGELI等[6]将词袋模型扩展到增量条件下,提出了一种增量式闭环检测方法,无需离线训练词典,并结合SIFT特征和颜色直方图实现特征的视角不变性,该方法利用贝叶斯滤波估计闭环概率实现了较高的准确率;针对大视角变化的闭环检测问题,李维鹏等[7]选取场景中密集特征聚集成为一个显著区域从而实现特征描述,结合贝叶斯滤波概率模型和BoW方法进行闭环判断,有效提升大视角变化的闭环召回率;MURARTAL等[8]采用ORB特征构建词袋模型实现闭环检测算法,该算法通过不断地提高筛选条件,多层筛选闭环候选帧,最终得到最优匹配的闭环结果。
上述方法采用局部特征构建词袋模型实现闭环判断。除此之外,还可以采用全局特征对图像进行描述。MILFORD等[9]采用全局特征描述图像基于序列匹配对闭环进行判断,该方法具有一定的环境不变性,但是计算效率低;SIAM等[10]针对序列匹配的耗时问题进行改进;刘国忠等[11]采用ORB特征结合SURF特征对图像进行全局描述,并采用改进的混合K最近邻方法实现闭环查询。因只对图像进行全局描述,该方法具有较高的运行速率。
相较于局部描述特征,全局描述具有较好的外观不变性,对环境变化具有较强的鲁棒性,而局部描述特征具有较好的旋转和尺度不变性,对视角变化和位姿变化较为鲁棒。基于词袋模型的方法虽具有广泛的应用性,但仍存在一定问题。由于特征量化为单词是无序的,从而会导致感知偏差问题,产生大量的误匹配。
本文考虑单词之间的拓扑关系,基于闭环概率模型,结合全局特征和局部特征,提出了一种多特征场景描述的闭环检测方法,以提高场景描述的鲁棒性,排除大部分的感知偏差问题。
1 算法流程
本文算法首先对采集的图像进行场景描述,采用两种不同的特征空间进行场景描述:基于SURF局部特征的场景描述和基于ORB特征的全局描述。对于局部SURF特征进行特征单词化,对于全局特征进行归一化,融合局部特征和全局特征实现场景描述。随后对单词化的局部特征更新逆向索引,根据索引检测可能闭环场景;对全局ORB特征检索历史帧中可能闭环场景。构建闭环概率模型,根据以上结果更新闭环候选帧的后验概率。最后采用极限约束进一步筛选闭环帧。闭环检测算法流程如图1所示。

图1 闭环检测算法流程
2 场景描述
2.1 SURF局部特征的场景描述
词袋模型的方法是对提取的特征进行聚类从而构建视觉字典。考虑SURF特征[12]较为稳定,对旋转和尺度具有不变性,同时对仿射变换以及光照变化较为鲁棒,本文的局部特征空间描述采用SURF特征。
SURF算法基于SIFT进行了改进,采用一种更高效的方式实现特征点的定位与特征描述计算。SURF算法在尺度空间通过计算Hessian矩阵行列式的局部极大值定位图像的特征点,对于图像特征点p=f(u,v)经过高斯滤波后Hessian矩阵构造如下
(1)
式中:Lxx(p,σ)为二阶偏导与图像的卷积;σ为尺度。则Hessian矩阵的行列式为
det(H)=DxxDyy-(0.9Dxy)2
(2)
式中:Dxx,Dxy,Dyy为特征点经过滤波的结果;在得到矩阵行列式后经过滤波得到响应点,构建尺度空间,通过将响应点与图像空间邻域8个点以及上下尺度空间邻域中的18个点进行比较筛选出稳定的特征点。SURF特征点定位示意图见图2。
图2 SURF特征点定位示意图
在提取特征点后进行主方向分配,从而保证SURF特征的旋转不变性。在提取的特征点圆形邻域范围内相对水平x方向以及竖直y方向计算Harr小波响应,随后对x和y方向的小波响应进行高斯加权,加权后的值分别表示在水平和竖直方向的方向分量。以特征点为中心,在张角为π/3的扇形滑窗内计算Harr小波响应dx,dy的累加,即
(3)
滑窗以弧度间隔在圆形范围内滑动,统计范围内Harr小波特征响应,模长为
(4)
将模长最大响应值lmax对应的扇形方向θmax作为该特征的主方向,即
(5)
在得到特征点主方向后,生成该特征点对应的描述子。取特征点图像邻域的4×4区域块生成矩形区域,将矩形区域旋转至主方向,并统计各子矩形块内的8个梯度方向的Harr小波特征,分别求和构成该子矩形块的特征描述,将16个子矩形块的特征描述合并从而形成该特征的描述符,该描述符由64维构成,即
A=(a1a2a3…a64)。
(6)
当进行场景描述时,对查询的图像首先提取SURF特征,并计算特征描述符。一幅图像有ns(设定的提取数量)个特征,根据视觉词典对特征描述符向量单词化,以单词对应索引存储特征,由此得到局部特征场景描述。
2.2 基于ORB全局特征的场景描述
全局特征描述采用ORB算法,该算法具有较高的运行速率,由FAST角点检测和计算BRIEF描述子组成。FAST角点通过比较选定像素和周围像素灰度差值进行检测。以一定半径圆上的像素和中心点像素的差值求和进行比较,大于设定阈值的中心点作为角点。ORB算法在尺度金字塔上提取FAST角点,增加ORB特征的尺度不变性,结合灰度质心法增加特征点的旋转不变性。
BRIEF[13]描述子是一种二进制描述子,在提取的FAST角点的附近像素区域内选取256个点对,将点对的灰度值比较结果进行二进制编码,从而得到一个256维的由0和1组成的二进制特征向量。选取的256个点对的矩阵为
(7)
为增加BRIEF描述子的旋转不变性,采用灰度质心法进行补偿。以特征点为中心,根据邻域图像灰度值I(x,y)计算图像矩,即
(8)
根据邻域图像的图像矩,计算邻域图像质心
(9)
根据特征点到质心z的矢量计算特征点的方向为
θ=arctan 2(m01,m10)。
(10)
以特征点方向θ作为旋转矩阵Rθ,将Rθ与矩阵S相乘,由此得到具有旋转不变性的Rotation BRIEF描述子。对于两个描述子H1和H2相似性,本文采用汉明距离进行计算,即
(11)
式中:⊕为异或运算;bitsum(·)为对位进行计数;R为ORB特征描述符的全局空间。
本文的全局特征计算过程:首先对图像进行预处理,即灰度化和均衡化;随后对图像进行下采样,下采样至60 像素×60 像素大小的图像块;对下采样的图像中心提取FAST角点并计算方向信息;以图像中心作为中点,整个图像作为邻域计算BRIEF描述符,结合旋转信息,以此作为整个图像的全局场景描述。
3 闭环概率模型
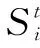
(12)
(13)

(14)

(15)
式中,Zm为不同的特征空间场景描述。本文有两个特征空间,即基于词袋模型的SURF局部特征和ORB的全局描述,为此分别构建局部特征的观测概率和全局特征的观测概率。
3.1 局部特征观测似然概率
不同尺度空间相互独立,共同表示同一个图像。本文基于词袋模型的方法表示局部特征,为了避免与历史图像帧逐帧比较从而导致计算过于耗时,本文采用BoW方法的逆向索引结构[13]从大量的历史图像帧中匹配与当前图像帧最相似的场景。对于当前图像中的每一个单词,逆向索引检索该词出现过的历史图像帧列表,当需要查询可能的闭环历史帧时,只需根据当前图像帧的单词索引历史帧列表,从而找出单词个数满足要求的历史帧场景,以实现快速检索历史图像帧。
逆向索引结构算法如图3所示。

图3 逆向索引结构算法示意图
考虑视觉字典树中不同尺度空间特征的表征能力,不同于文献[6]的方法,本文采用分层金字塔熵(Term Frequency-Inverse Document Frequency,TF-IDF[14])得分匹配计算似然概率,TF-IDF的熵为
(16)
式中:nw为单词w在图像It中出现的次数;n为图像It出现的单词总次数;Nw为包含单词w的总图像数,N为图像总数;为整合不同层次的得分信息,设在第l层图像It和Ii的匹配得分为
(17)
整合全部字典层的图像匹配得分为
(18)
式中,参数k1表示底层单词的权重系数,本文设置k1=2。对当前图像的所有单词矢量化并且根据式(16)计算得分后,观测似然概率计算为
(19)
式中,σ1,μ1分别为当前帧与历史帧匹配得分的均值和方差。当匹配得分高于均值和方差之和时,基于当前似然概率更新后验概率。
3.2 全局特征观测似然概率
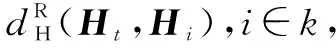
(20)
dw对当前帧It和历史图像帧Ii的汉明距离进行加权,即
(21)
由此可得ORB全局特征的闭环观测概率为
(22)
式中,σ2,μ2分别为当前帧与k个历史帧匹配得分的均值和方差。当匹配得分高于均值和方差之和时,基于当前似然概率更新后验概率。
3.3 闭环先验概率
在得到不同尺度空间的观测似然概率,后验概率的更新仍需要闭环先验概率。先验概率表征了当前图像的闭环概率与历史图像闭环概率之间的拓扑关系,根据全概率公式,闭环先验概率为
(23)
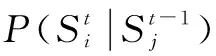
先验概率分两部分:t-1时刻后验闭环概率以及转移概率。转移概率表征从t-1时刻到t时刻状态转移的可能性,本文分以下4种情况进行讨论。

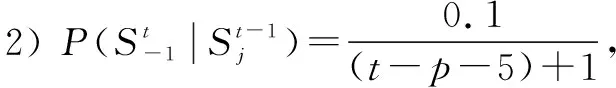
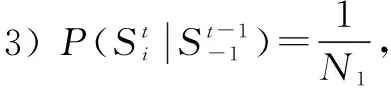
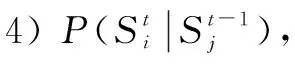
4 多步闭环候选帧筛选方法
在视觉SLAM中,与图像检索问题不同,图像帧是连续采集的,因此具有时间上的一致性。当计算出发生闭环的后验概率,为尽可能减少词袋模型方法在多歧义场景带来的感知偏差问题,本文考虑时间一致性提出一种多步的闭环候选帧筛选方法。
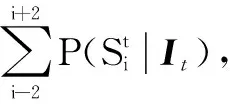
3) 在得到闭环候选帧后,基于极线约束对闭环候选图像帧进一步筛选排除错误闭环结果;对提取SURF特征进行特征匹配,RANSAC筛选内点,根据内点数量确定闭环图像帧。
5 实验与分析
为验证本文闭环检测算法的有效性,采用牛津大学移动机器人研究小组公开的数据集New College和City Center进行验证。数据集轨迹如图4所示,黄色轨迹线表示相近运行轨迹,红色表示发生闭环情况,分别由2146和2474张采集图像组成,采集间隔为1.5 m。其中包含了较多的歧义场景,可以较全面地评估本文算法针对感知偏差的情况。对比算法采用FAB-MAP以及BoW方法,实验硬件平台参数如表1所示。

图4 数据集轨迹图

表1 实验平台参数表
数据集分左、右相机采集,本文将两个数据集分左、右相机归类分别进行闭环实验。数据集提供的真实的标注矩阵也采用同样的方法分类,共分4组进行闭环实验。
5.1 闭环误匹配
为验证本文算法在多歧义场景下,可以减少闭环误匹配,选取New College和City Center 数据集中奇数图像序列进行闭环检测,对比算法采用BoW方法,闭环检测结果的可视化矩阵如图5和图6所示。其中,蓝色的为真实闭环结果,红色的为误正闭环结果(图中TTP表示闭环检测为闭环的数量,FFP表示非闭环检测为闭环的数量)。从图中可以看出,本文算法可以剔除绝大多数的误正闭环,且拥有较高的匹配率,即图中蓝色线条更多,更接近真实闭环结果,红色线条更少。这是由于本文算法融合两种特征进行场景描述对相似的场景具有较强的鲁棒性,且本文通过多步筛选确定闭环候选帧,解决了大部分的感知偏差问题。

图5 New College闭环检测对比

图6 City Center闭环检测对比
5.2 闭环检测性能分析
为进一步验证算法的有效性,采用准确率-召回率曲线(Precision-Recall,PR)进行评估。准确率P表示所检测到的闭环结果中的正确闭环匹配比例,召回率R表示所检测到的正确闭环占路径真实闭环个数的比例。P和R的算式如下
(24)
(25)
式中:TTP表示是闭环检测为闭环的数量;FFP表示不是闭环检测为闭环的数量;FFN为闭环检测为不是闭环的数量。本文对2个数据集奇数和偶数图像序列分4组进行闭环检测实验,与FAB-MAP2.0,BoW算法对比结果如图7所示。从图7中可以看出,在召回率接近零时,3组算法的准确率都为1;在保证100%准确率的情况下,在4个闭环实验中,本文算法的最大召回率均高于FAB-MAP2.0以及BoW算法;随着召回率的提高,准确率逐渐下降,本文算法整体趋势下降较慢,闭环检测效果优于BoW和FAB-MAP2.0的方法;其中,BoW的方法没有考虑单词之间的排序,在多歧义场景易产生感知偏差问题,使得整体趋势下降最快;本文算法由于采用全局特征和局部特征相结合进行场景描述构建闭环概率模型,因此对场景变化较为鲁棒,且考虑场景的时间一致性和空间一致性并采用极线约束检验对闭环候选帧进行筛选,因此可以解决大部分的感知偏差问题,减少闭环误匹配。图8和图9分别为本文闭环检测算法在New College和City Center数据集中的闭环检测结果展示,可知本文算法可以准确地查询出闭环情况。
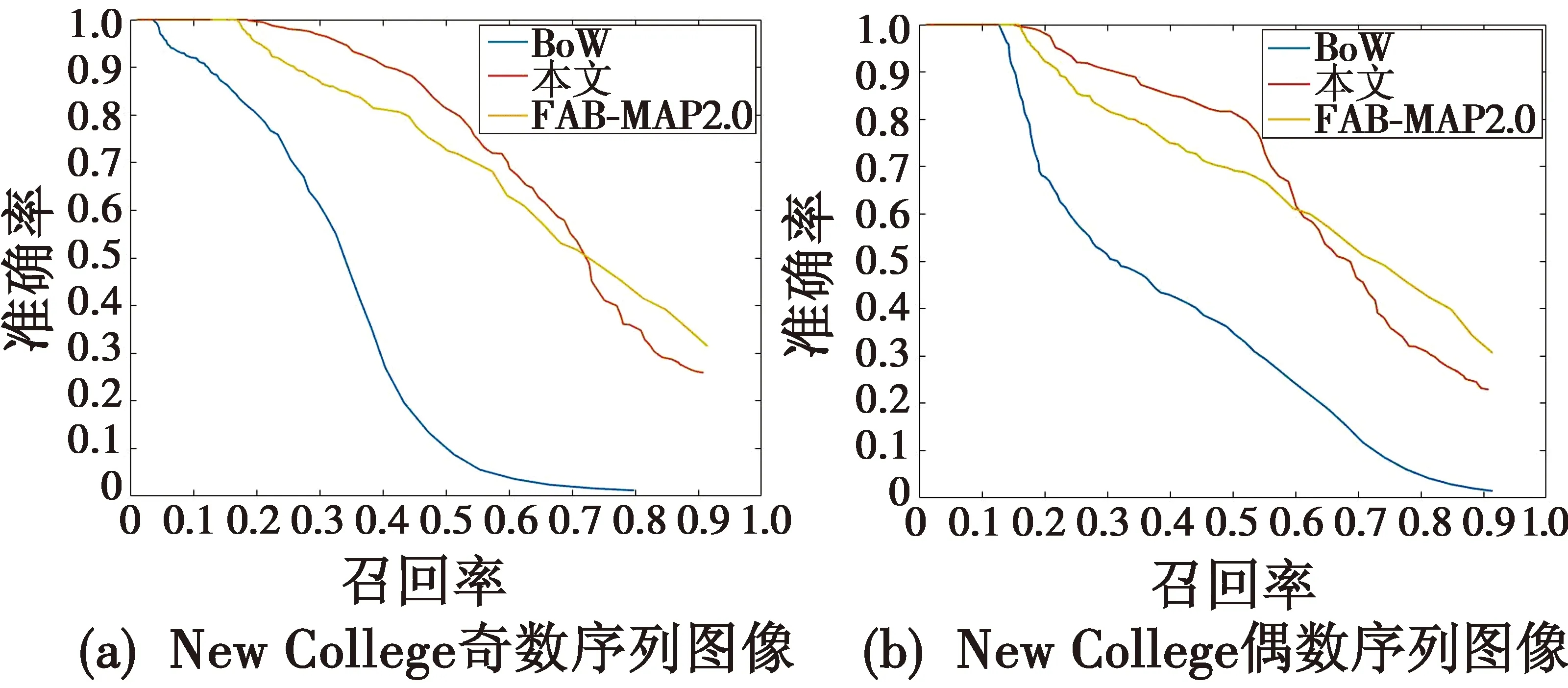
图7 准确率-召回率曲线

图8 New College闭环检测图像
6 结束语
闭环检测是视觉SLAM中的一个关键问题,针对多歧义场景,为提高闭环检测的准确率,提出了一种多特征空间描述的闭环检测方法,以提高闭环检测的鲁棒性和闭环准确性;基于闭环概率模型的框架下,融合局部SURF特征和全局ORB特征,提出基于极线约束的闭环候选帧筛选方法,进一步提高闭环准确率。
