基于自然语言处理和机器学习的长期股权投资分类模型
2022-11-22厦门大学管理学院叶莉莉陈亚盛
文 · 厦门大学管理学院 叶莉莉 陈亚盛
一、引言
随着全球经济的不断发展与变化,投资在企业三大活动中所占的比例越来越高,成为企业中极其重要的活动。长期股权投资作为投资活动的重要类别,可分为对子公司的投资、对合营企业的投资和对联营企业的投资三类。根据会计准则要求、分类不同,适用的初始计量和后期核算方法都不一样。在此背景下,有些企业可能会钻空子,将投资分类为利好业绩的一类,达到调整报表业绩的目的,影响市场投资者的判断。因此,一个能对长期股权投资进行正确分类的工具,不论是对保证企业会计核算的准确性、提高审计的质量,抑或是增强监管机构的监督能力,都具有十分重要的意义。
目前,因构成股权投资的合同、协议等有大量的文字,对它们的分类只能依赖人工判断。而从审计工作和政府监管的需求来看,面对企业大量的长期股权投资,若仅采用人工分类,耗时长且效率低。为弥补人工分类的不足,本文尝试运用自然语言处理技术和机器学习方法,构建一个长期股权投资的分类模型,希望能通过此模型实现对股权投资的初步分类,在一定程度上实现股权投资分类的自动化和批量化。
二、长期股权投资
(一)股权投资定义
股权投资,又称权益性投资,是指投资方通过付出现金或其他资产获得被投资单位的股份,享有被投资单位的相关股东权利。股权投资形成投资方的金融资产、被投资单位的权益工具。根据投资之后投资方能够对被投资单位施加影响的程度,将其分为按照《企业会计准则第22号—金融工具确认和计量》进行核算和按照《企业会计准则第2号—长期股权投资》进行核算两类。本文研究的是长期股权投资的分类。
(二)长期股权投资的分类依据
根据投资方对被投资单位施加影响的程度,长期股权投资可以分为对联营企业投资、对合营企业投资和对子公司投资三类。
1.对联营企业投资
对联营企业投资,是指投资方能够对被投资单位施加重大影响的股权投资。对于重大影响的判定,企业会计准则没有给出具体的判断标准,只是将其定义为“投资方对被投资单位的财务和生产经营决策有参与决策的权力,但并不能够控制或者与其他方一起共同控制这些政策的制定”。会计准则应用指南中举例了以下情况来判断是否具有重大影响:在董事会或类似机构派有代表、发生重要交易、派有管理人员、提供关键技术材料等。
2.对合营企业投资
对合营企业投资,是指投资方持有的对构成合营企业的合营安排的投资。判断对合营企业的投资时,首先看是否构成合营安排,其次看有关合营安排是否构成合营企业。
3.对子公司投资
当投资方能够直接对被投资单位实施控制时,该投资即为对子公司的投资。控制,是指投资方拥有对被投资方的权力,通过参与被投资方的相关活动而享有可变回报,并且有能力运用对被投资方的权力影响其回报金额。会计准则中定义控制的三项基本要素为相关活动主导权、获利权和影响回报权。
基于以上会计准则的要求,在判断长期股权投资的类别时,最重要的是寻找关于权力来源、控股比例、董事会结构等方面的关键信息。
三、自然语言处理与机器学习方法
本文尝试实现长期股权投资的智能分类,是对文本类型的数据进行分类。因此,在构建模型前,我们需要先将数据进行自然语言处理,对文本进行分词,通过统计方法将文本数据转换为向量形式的数值型数据。在此基础上,我们再构建适合的机器学习分类模型对数据进行分类。
(一)文本分词技术
分词是将一段文本分割为词语,主要应用于自然语言处理,如进行关键词提取优化搜索、智能问答系统中语义分析等。英文中使用空格来分开每个单词,而中文词语和单个字之间的含义有时相差甚远,因此需要采用专门的中文分词来进行语句切割。本文的研究是基于Python语言进行代码编写,Python中有许多中文分词库,常见的有jieba、THULAC、pkuseg等。本文选用的是jieba分词。
jieba分词支持四种分词模式:精确模式、全模式、搜索引擎模式和paddle模式。除简单的分词模式外,jieba还支持繁体分词、自定义词典和词性标注等,是一个强大的中文开源分词包,拥有高性能与高准确率、可扩展等特点。
(二)TF-IDF统计方法
TF-IDF是用于评估字词对于一个文件集或一个语料库中的其中一份文件的重要程度的统计方法。TF-IDF统计方法的主要思想是:如果某个词语或短语在一篇文章中出现的频率很高,同时它在其他文章中很少出现,则认为此词语或短语具有很好的类别区分能力,适合用来分类。其实际上是TF(Term frequency,词频)* IDF(Inverse document frequency,逆文档频率)。
TF,词频,即某个词语在文档中出现的次数。出现频率越高的词语,TF值越大。TF的计算公式为:
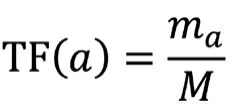
TF(a)表示词语a在一篇文档Di中出现的频率,ma表示词语a在文档Di中出现的频数,M表示文档Di中所有的词语总数。
IDF,逆文档频率,即一个词语普遍重要性的度量。其思想是当包含某个词语的文档数越少时,该词语越适合用来做分类;而当包含某个词语的文档数很多时,其类别区分能力就很弱,不适合用来做分类,比如介词、代词等在大多数文档中均存在的词语便不适合用来分类。IDF的计算公式为:
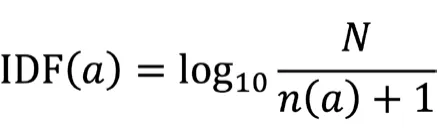
其中a为词语,N为语料库中包含的文档数量,n(a)为包含词语a的文档数量。因此:

该权重值包含了词语在一篇文档中所占的比例以及在其他文档中所占的比例两个部分,兼顾了词语的重要性和对于文档的代表性两个方面,能帮助找出每一篇文档中的特征词,可以作为很好的分类辅助工具。通过计算词语的TF-IDF值,并对应组合成一个长向量,便可以将文本型数据转换为机器能理解和处理的数值型数据,通过对每一篇文档对应的向量进行分类,即可实现对文档的分类。
(三)支持向量机分类模型
支持向量机(Support Vector Machine,SVM)是按监督学习方式的分类算法,通过输入已标记好类别的数据来对模型进行训练,机器通过数据计算得到待分类数据的分类边界,对输入的数据进行分类。以下通过二维数据点对支持向量机模型做简要解释。
如图1所示,在二维数据下,对图中两类数据(橙色三角形和蓝色圆点)进行分类,模型需找到其最好的分类边界,这样不仅能在现存数据下进行最优分类,还能在后续有新加入的数据点时做到分类最优,准确率最高。在该二维数据分布下,图中的绿色直线便是最佳决策边界。此时,两边数据点都与决策边界有一定的距离,蓝色直线和橙色直线间的空白处成为缓冲区。当蓝色直线和橙色直线的间隔最大时,待分类数据点便有足够大的缓冲区,分类出现错误的概率就最低。因此,模型要解决的问题是找到最佳决策边界,即找到两条直线的最大间隔。
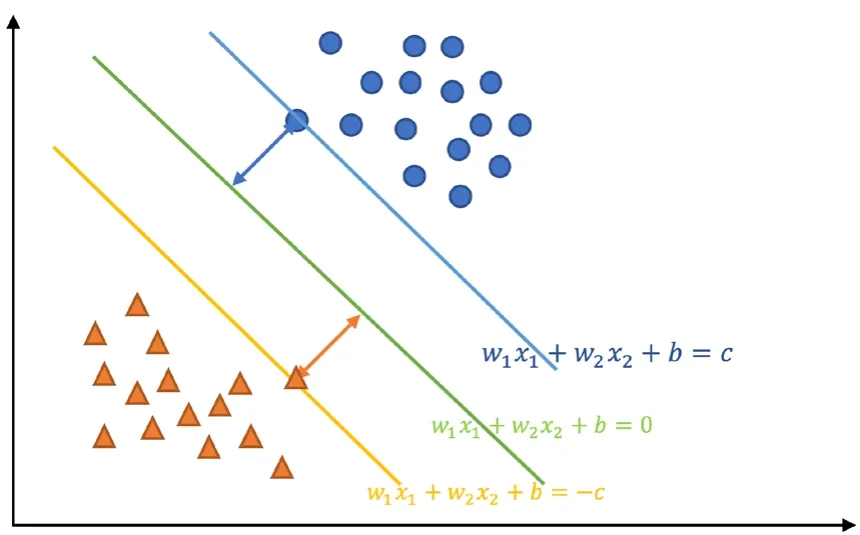
图1 二维数据下决策边界的确定
要使间隔最大,则要找到两类数据中分别处于最边界的两个点,即图1中在蓝色直线上的圆点和橙色直线上的三角形,我们将这两个点称为支持向量。中间的决策边界为,蓝色直线为,橙色直线为(此处和为二维向量的两个维度输入值;和为两个维度值对应的权重值,决定决策边界的方向;b为偏置项,决定决策边界左右移动的距离;c为两侧支持向量点与决策边界的距离)。通过数学公式转换与相应代替,基于支持向量点,结合决策边界的函数式,利用向量运算的规则,可以推导出求解最大间隔等同于在约束条件下求解长度的最小值。此时,通过转换约束条件格式和运用拉格朗日函数即可求解出和b值。
当数据从二维拓展到高维度下,SVM模型运用核技巧,使用核函数获取数据的高维度向量差异度,来减少因升维而导致的计算量和避免维度爆炸,简化运算,提高效率。同时,不同的核函数也会有不同的参数,在调用过程中不断调整来选择最合适的参数匹配模型,达到模型最优化。与其他分类算法相比,SVM更适合于小样本训练,可简化分类和回归问题。同时,SVM对异常值不敏感,有优秀的泛化能力,也便于通过调整参数来达到更好的拟合。
(四)自然语言处理和机器学习算法应用于投资类型分类的原理
在构建模型过程中,本文首先将数据通过文本分词技术分成单个字或词,将所有的字词构建成一个词典。之后计算每一条数据分词后所得的字词在整个语料库中的TF-IDF值,并按照词典统一的顺序形成一个包含各个字词TF-IDF值的多维向量,总维数是词典中字词的数量,如此能确保所有数据的维数都一样,之后才能进行模型构造。一条数据中不存在的词语即按TFIDF的计算公式计算所得为0标注,因此每条数据对应的向量都会有一些维数是0,数据越短则向量中为0的维数可能越多。将收集到的数据分为训练集和测试集。训练集预先人工标注好类别以供机器进行监督学习。机器通过训练集的向量数据和标记类别进行监督学习,生成划分两类数据向量的最佳决策边界。之后输入测试集的向量数据,模型通过判断其位于决策边界的哪一侧来对其进行分类,输出结果。
因此,在模型构建中,机器进行学习主要依靠的是向量数据。基于上文介绍的TF-IDF统计方法,TF-IDF值可用来衡量词语的重要性和对于文档的代表性,即可以帮助机器找出每段数据文本的关键词,如董事会、成员人数、表决权、重要影响等。这和人在进行长期股权投资分类时,需要关注董事会人数和控股比例等关键内容类似。
例如,冠城大通股份有限公司2021年的年度报告披露:“公司对北京海淀科技园建设股份有限公司下属公司北京盛世翌豪房地产经纪有限公司(以下简称‘盛世翌豪’)的间接持股比例合计为50%,鉴于公司委派的董事占盛世翌豪董事会成员总人数的一半以上,在盛世翌豪董事会中占多数表决权,能够控制盛世翌豪。”会计人员在读取完本段文字时,会着重注意“持股比例合计为50%”和“委派的董事占盛世翌豪董事会成员总人数的一半以上”这两个关键内容,基于其占多数表决权、能控制盛世翌豪来将该股权投资分类为对子公司的投资。而机器在通过分词和TF-IDF计算后,读取到的关键词包括“持股比例”“50%”“总人数”“一半以上”“多数表决权”“控制”等。在大量读取并处理我们标记好的数据后,通过不断的学习,机器会生成算法将文本中有“多数表决权”“一半以上”等词语作为子公司投资类别的关键词。因为这几个关键词更有可能在被标记为子公司投资类别的文本样本中出现。
四、长期股权投资分类模型构建
本文选取上海证券交易所披露的上市公司定期报告中“在其他主体中的权益”部分关于对子公司的投资和对合营企业或联营企业的投资文本描述内容作为数据来源,通过构建支持向量机模型,对这些包含有长期股权投资内容的文本数据进行分类,将长期股权投资分为对子公司的投资和对合营企业或联营企业的投资。
(一)文本分词处理
首先对收集到的数据进行标注,以便之后进行模型训练:将合营企业或联营企业股权投资的文本标注为“1”,对子公司的投资文本标注为“2”,共计147条相关数据,如图2所示。在收集、标注数据后,将其存为txt文件类型,使用jieba分词库对文本数据,即图2中所示data列进行分词。

图2 完成数据标注的数据集
首先导入pandas和numpy扩展程序库和jieba分词库,再利用pandas扩展库工具上传、读取文件;使用jieba进行分词,并将分词后的结果存入result_1文本文件中,通过jieba分词处理后的文本数据变成了一个个分隔开的字词。如图3所示,每一个段落为一个文本数据,对应一种类别。

图3 经过jieba分词后的文本
(二)计算TF-IDF值,生成向量
对文本做好预处理工作后,便要将文本数据转化为数值型数据,方便模型的识别与读取。如上文介绍,本文选取TF-IDF值来度量每个词语的重要性和对于文档的代表性,将其转化为向量形式的数值。
首先导入scipy学习库和sk learn中特征选择的工具包,再将分词后得到的文件result_1读取到corpus中,一共147行,每行代表一个文本数据:

将文本中的词语转换为词频矩阵,计算每条数据中每个字词的TF-IDF值,得到对应的TF-IDF向量。

(三)构建支持向量机模型
得到每个文本数据的TF-IDF向量后,便可通过构建支持向量机模型来对向量进行分类,进而实现对长期股权投资文本数据的分类。
首先导入sklearn中模型构建库。其次设置计算出的TF-IDF向量值作为x,读取预先做好标记的label文件设置为y。

导入sk learn中模型评估库,用于输出评价模型的指标:精确度(precision)、召回率(recall)和F1值(F1-score)。其中精确度precision=A/(A+B),召回率recall=A/(A+C);F1值为精确度和召回率的均值。A、B、C、D所代表的具体含义如表1所示。
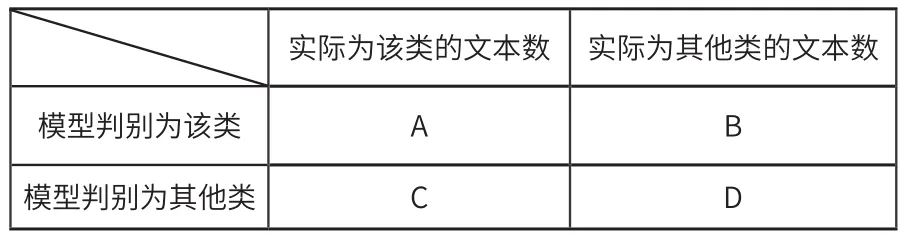
表1 判别列联表
对数据集进行划分:将其中的70%划分为训练集,即102条数据;30%划分为测试集,即45条数据。对x值进行归一化处理;

我们分别采用线性核函数、高斯核函数、多项式核函数、Sigmoid核函数和其对应的不同参数进行SVM模型构建,得出最适合此次分类的SVM模型。以下代码以高斯核函数为例:


在调整参数和核函数的过程中,我们发现模型的精确度、召回率和F1值并没有显著差异。最终模型的测试准确率可达0.711111,测试集中实际共有分类为联营企业和合营企业投资的文本24个,模型正确分类20个;实际数据中分类为对子公司的投资的文本21个,模型正确分类12个。其具体判别列联表如表2所示。对合营企业或联营企业的投资文本分类的精确度为0.69,召回率为0.83,F1值为0.75;对子公司的投资文本分类的精确度为0.75,召回率为0.57,F1值为0.65。具体数据如图4所示。

表2 模型结果判别列联表
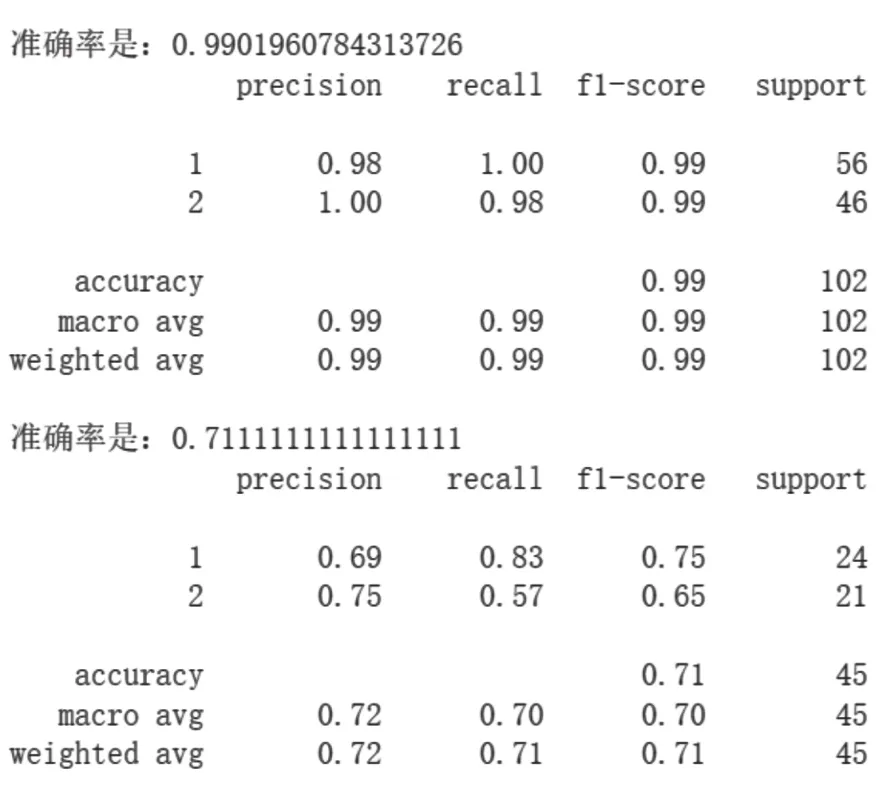
图4 训练模型和测试模型评价指标
通过上述正确分类个数以及各个评价模型的指标等数据,可以发现模型对于联营企业和合营企业投资的分类准确率高于对子公司投资的分类。
五、结论与展望
本文根据会计准则的规定,梳理出关于长期股权投资分类的相关定义和影响因素,并利用关键词在分类中的决定性作用这一规律,通过Python编程构建支持向量机机器学习模型,实现对长期股权投资的智能分类。最终构建的模型能在71.11%的准确率下对长期股权投资进行分类,将其分为对子公司的投资和对联营企业与合营企业的投资,在一定程度上实现了计算机对会计专业文本数据自动处理和分类。该模型可在实务中辅助财务人员、审计师和监管机构进行股权投资分类筛查,提高工作效率。本文使用的文本分类方法也可运用于其他会计分类判断,如金融资产分类、租赁合同分类等。希望本文的研究能促进会计和自然语言处理技术及机器学习的结合,进一步推动会计智能化的发展。
