基于机器学习的岩性分类识别研究
2022-11-21张嘉宝杨满玉万静华远鹏胡宇博高国忠
*张嘉宝 杨满玉 万静 华远鹏 胡宇博 高国忠
(长江大学地球物理与石油资源学院 湖北 430100)
岩性识别是用一些特定的方法来区分识别岩性的过程,如何描述岩性分类一直都是一个重要的问题。岩性识别的主要方法有重磁、测井、地震、遥感、电磁、地球化学及薄片分析方法等[1]。
国外常用的常规岩石分类方法,大多是基于岩心或测井资料导出的渗透率-孔隙度交会图。虽然测井数据不能直接提供渗透率估计值,但是已经开发了几种从其他测井数据间接获得渗透率估计值的方法。Pitman等[2]提出了一种基于注汞测量的岩石分类方法。把孔隙度和渗透率测量值与孔喉半径联系起来,观察到一种岩石类型的样品具有相似大小的主导孔喉半径。Amaefule等[3]基于渗透率和孔隙度的交会图,修改了Kozeney-Carman方程,引入了岩石质量指数(RQI)和流动带指标(FZI)界限来定义不同的岩石类型,建立了岩心、微观参数与测井宏观属性之间的因果关系,实现了在储层中预测其他岩石的岩性,但并未对取心层段或井的渗透率预测。该方法得到大量实验和数据证明,而后广泛应用于常规的岩性分类。
由于在页岩中缺乏足够的孔隙度和渗透率值范围来划分不同的岩石类型。其次,难以直接测得大多数岩石物理参数,因此上述的方法不适合在非常规油气藏中使用。
Kale等[4]提出了一种将地质岩心描述与孔隙度、总有机碳(TOC)、FTIR矿物学和注汞毛细管压力等相对容易测量的指标相结合的岩石分类方法。根据岩石物理聚类分析,把具有相似的物理性质的岩石组合为一种类型,建立了页岩岩相识别。Gupta等[5]提出了利用监督学习和无监督学习两个独立的算法对页岩进行岩性分类识别。采用了聚类算法和分类算法,对岩石类型进行划分,再将岩石衍生类型升级到基于测井日志的岩石类型。最后,将升级后的岩石类型测井曲线与生产数据进行关联,以测试岩石类型训练的稳健性。此方法可以在多个场景广泛应用。
随着电子信息的快速发展,机器学习在测井的岩性识别方向,提供了大量的算法。鞠武等[6]利用测井资料和岩心分资料,建立了岩性分类的判别函数,采用Bayes逐步判别法识别岩性,预测准确率达到了86%。段友祥等[7]提出了利用组合的机器学习算法,建立对岩性分类进行选择性集成学习预测模型。该方法综合了一些机器学习的表现优秀的个体学习模型,提高了模型的泛化能力。马陇飞等[8]利用梯度提升决策树算法,构建了GBDT算法模型,通过实验验证和分析,提高了岩性识别的准确率。
以上方法均存在不足之处,需要人工归纳岩石类型,在进行岩性预测,人工处理岩心数据耗时耗力,不利于成本控制,具有很大的不确定性。基于这些问题,本文提出了一种新的岩性分类识别方法,选取渗透率、孔隙度、密度、含油饱和度、含水饱和度共5种岩石物理参数进行监督学习的k-means聚类分析,确定岩石分类的类型;训练预测模型,使用KNN分类算法,用已知岩性类型的测井数据训练出预测模型,从而对自动进行整个井段或者邻近井的岩性识别预测。此方法可以应用于不同的油气藏的储层研究中,有助于提升测井地质解释工作的效率和精度,为岩性识别问题提供了一种新思路,对于储层研究的智能化开发具有重大意义。
1.方法原理
(1)模型搭建
首先对获取的实验室物理岩石参数进行预处理,检查数据的完整性,如果数据缺失利用插值法把缺失数据补全。对获取的岩心数据做标准化处理,岩性分类是无监督学习通过K-means聚类算法来划分,通过此方法,岩石类型的集群数量就被确定。再用监督学习的KNN分类算法训练预测模型,从而对没有岩心数据的井段进行预测。由于K-means和KNN算法都是基于样本间距离最小原则进行划分,因此用了K-means聚类以后,再用KNN分类,效果更好,预测的准确率也更高,样本的可分性也更强。
(2)聚类方法
K-means算法是一种常用的聚类算法,特点是簇内的对象越相似,聚类的效果越好。将算法的输入数据作为一个样本集,通过算法把样本进行聚类,使具有相似特征的样本聚为一类,再随机选取K个对象作为初始聚类中心,将数据集分为K组,计算每个对象与聚类中心的距离,分配到离它最近的聚类中心。每分配一个对象,重新计算一次聚类中心,直到聚类中心不在变化为止。假设簇划分为(C1,C1,…,Ck),新的聚类中心:
其中,μj是簇Cj的均值向量。
(3)分类方法
KNN分类算法是一种常见的监督学习方法,主要思想是,如果样本在特征区域有k个最近邻,这些样本中的大多数都属于某一类,则该样本也属于这一类。该方法在考虑分类决策的情况下,根据最近的一个或多个样本的类别来确定要分类的样本类别。
关于距离测量值,常用欧氏距离。欧氏距离衡量的是多维空间中两个点之间的绝对距离,即m维空间中两个点之间的真实距离或向量的自然长度。
n维空间点a(x11,x12,…,xn)与b(x11,x12,…,xn)间的欧氏距离:
为了选取KNN模型最合适k值,本文采用K折交叉验证确定k的大小。使用交叉拆分出不同的训练集和验证集分布测试模型的精准度,求出精准度的均值就是交叉验证的结果,选取精准度最高的超参数作为KNN模型的k值。
2.实验与分析
(1)数据处理
在这项研究中,我们使用了某油气田的3984.0m到6378.0m的深度区间,间隔为0.5m的119700个测井数据以及204个岩心数据。在处理岩心的数据时,先对筛选处理的岩心数据归一化处理,其计算公式如下:
其中,X'为归一化后的数据;X为原始岩心数据;Xmax,Xmin分别为某岩心数据的最大值最小值。将数据按比例缩放,便于不同单位之间的指标能够进行加权,有利于提高模型识别的准确率。
(2)聚类
接着对204个岩心数据进行最优化的K-means聚类分析,结合专家经验,将岩石类型分成5类最合理。根据岩心数据计算出每一类的岩石物理参数及范围,如表1所示。
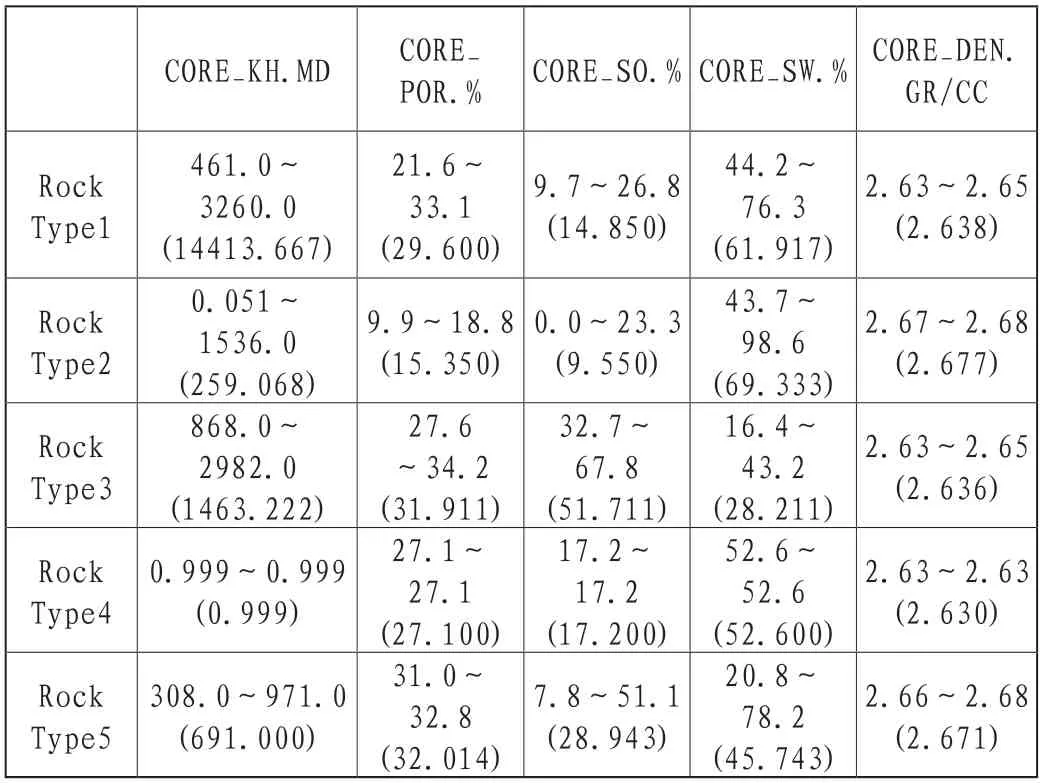
表1 K-means聚类分析各个岩石物理参数的范围以及平均值
对岩心数据K-means聚类分析后得到的5种岩石类型,根据每种岩石类型的渗透率、孔隙度、岩石密度绘制箱线图。如图1所示,岩石类型3具有最高的渗透率和孔隙度,其岩石密度最低;岩石类型1的渗透率和孔隙度较高,岩石类型2的渗透率和孔隙度最低,岩石密度最高。岩石类型3具有最高的含油饱和度,物理性质较好,大概率含油;根据表1所示,岩石类型5的含油饱和度较高,岩石类型2的含水饱和度最高,岩石类型1的含水饱和度较高。
(3)预测
在KNN模型中,模型的复杂度由k值决定。本文采用K折交叉验证,把训练数据等分为5组,将每个子数据集做一次交叉验证,其余4组子数据集作为训练集,最终求出验证集的分类准确率的平均值,如图2所示,每个点表示验证集的准确率,求取平均值,发现k为3,KNN模型的效果表现的最好。
本次实验,KNN算法在多分类的问题上表现比SVM分类算法好。如图3所示,图中(a)和(b)分别为KNN模型和SVM模型的混淆矩阵,根据混淆矩阵可以求得KNN模型的准确率为94.21%,SVM模型的准确率72.88%。KNN模型中,岩石类型1的预测结果都是岩石类型1;而SVM模型,岩石类型1的预测结果中,出现了11个岩石类型3的样本,7个岩石类型4的样本,1个岩石类型5的样本。综合评估,在本文的样本中KNN模型,表现效果比SVM模型好,预测的准确度更高。
利用本文的岩石分类预测模型,对整个井段的岩石类型进行预测,绘制测井曲线图,如图4所示,把岩石类型与测井曲线生产数据进行关联,岩石类型2的密度最高,含油饱和度最低,因此电阻率较低,岩石类型3的密度最低,含油饱和度最高,电阻率较大,预测所得岩石类型与测井曲线符合。
3.结论
(1)本文开发了一个利用少量岩心数据和测井数据进行岩性分类的综合流程。使用K-means聚类算法把岩性划分成5类。再通过KNN分类算法训练预测模型,在本次实验中,KNN算法相比较SVM算法在多分类问题上的准确率更高。继而对同一口井无岩心数据测井曲线进行岩石分型预测识别,证明在最优参数组合下的机器学习算法可以对岩石类型快速作出较为精准的识别预测。
(2)后期工作中,针对岩心数据样本量较少的问题,考虑在建立预测模型时采用半监督学习;对岩性分类识别研究,得出结果是否合理、哪一个的变量影响大、计算过程是否可控等问题,做出一定的解释。
(3)本文展示的岩性分类可以扩展到其他井段的数据集中,不仅可以在常规储层中应用,在非常规储层也可以采用此方法进行岩性分类。在分类算法中,还可以使用决策树,随机森林,在数据比较庞大的时候,还可以使用深度学习的算法训练预测模型。
