基于预训练模型的A股停牌预测研究
2022-11-18孙夫雄梁嘉欣
孙夫雄 谢 翔 熊 平 梁嘉欣 彭 畅
一、引言
停牌即“停止证券上市”,指的是某一种证券临时停止交易的行为。股票停牌触发后,市场交易将被强制中止,使交易各方有时间获取最新信息重新评估交易价格、调整交易策略,以提升信息披露程度、降低交易信息的不对称性,削弱上市公司风险事项的不确定性影响、维护市场秩序和保护投资者合法权益。但A股停牌的频次高、时间长与随意性等问题侵犯了投资者的交易权,影响了市场效率。部分上市公司利用筹划重大事项等名义停牌,进行股价操纵与内幕交易以攫取非法利益,严重背离了股票停牌制度设立的初衷,降低了价格发现效率。
在2015年“6·15股灾”期间,7月9日这天停牌的上市公司数量有1 438家之多,占所有上市公司数量比例逾50%。投资者的资金大面积套牢,盈利股票无法兑现浮盈,大量抛压难以释放,整个交易市场被悲观恐慌情绪所笼罩。另外我国A股还存在停牌时间超长且强制复牌程序不配套的问题,例如*ST新亿(600145)停牌时间从2015年到2020年长达54个月,成为中国证券历史上的最长停牌时间记录,而深深房A(000029) 停牌自2016年至2020年时长为51个月。长期停牌极大挫伤了投资者的投资意愿和信心,给交易市场流动性带来严重损害,也为监管层带来了更大的工作挑战,不利于股票市场的长期稳定运行。
中国股市存在的停牌滥用、超长停牌等问题已经引起了学术界、监管层和投资者的重视。国内外学者们从多个角度入手开展了股票停牌相关研究,包括国内外停牌制度对比、停牌时长影响因素、停牌前后股价波动的分析等已发生的确定性事件,但对于股票停牌预测等不确定事件研究尚存在空白。
因此,本文采用预训练模型和迁移学习的深度学习方法用于股票停牌的预测,主要贡献如下: 一是首次从停牌预测的视角,提出了基于预训练模型的股票停牌预测,首先预训练模型用于学习A股上市公司股票停牌的共性特征,再通过迁移学习机制获得个股停牌的特征,进而实现精确的个股停牌预测,为相关研究提供了新的研究方法与实证证据。二是研究成果在一定程度上解决了交易各方的信息不对称问题,使我国中小投资者能有效地规避停牌风险,进而减少投资损失以及实现资产保值,或为部分投资者利用个股停牌后的股价波动,实现收益最大化等目标提供帮助。三是通过对A股市场不同行业板块的停牌预测分析,使监管机构能够对市场整体停牌趋势做出前瞻性判断,对宏观调控和政策调整提供了参考。
二、文献综述
金融数据波动的分析方法主要涵盖了统计学、机器学习以及深度学习,中外学者在该领域皆取得了卓越的研究成果。
在统计学方法研究方面,Doroudyan等(2017)[1]研究ARMA-GARCH模型对德黑兰证券交易所价格指数的时间序列进行拟合,实现了金融过程的监控和预警。蔡光辉等(2021)[2]提出了基于偏t分布的混频Realized GARCH模型,进而推导其参数估计方法,并通过MCS检验判别扩展模型与滚动时间窗预测技术对中国黄金期货市场波动进行预测研究,实验结果显示相较于GARCH模型与Realized GARCH模型,结合高频信息的Realized GARCH模型在样本内估计的预测精度和拟合优度表现更好;在机器学习研究方面,Gupta等(2021)[3]利用随机森林技术预测了投资者信心对美国股票市场波动的影响。Vara等(2022)[4]比较了卡尔曼滤波器、XGBoost和ARIMA三种主要算法对股票价格的预测,提出了卡尔曼滤波器和XGBoost的混合模型,研究结果显示其预测精度优于单一模型。张剑和王波(2017)[5]采用SVM(Support Vector Machine)理论搭建沪深300股指期货量化交易模型,并根据动态预测模型设计了量化交易策略,实验显示量化交易模型整体可以获得较高的投资回报;在深度学习研究方面,Chatzis等(2018)[6]比较分析了分类树、支持向量机、随机森林、深度神经网络等技术对股市危机事件预测性能,指出深度神经网络具有显著的分类精度。Althelaya等(2021)[7]利用小波变换技术捕捉不同尺度的金融时间序列波动,结合深度学习模型提高了股票预测的精度。Sun等(2021)[8]基于时间卷积网络(Temporal Convolutional Network,TCN)对股民的情感信息进行建模,用于对股票和期货价格进行预测,实验结果表明TCN在MAE、MAPE、RMSE和精度方面优于GRU模型。
对于股票停牌的研究,国内外学者基本上侧重于停牌的制度性研究,以及停牌对股价影响的实证研究。Kabir和Engelen(2006)[9]评估监管机构是否能够成功利用停牌机制,迫使公司向资本市场披露新的重大信息,研究结果显示了停牌机制在传播新信息方面的有效性。Taechapiroontong等(2012)[10]考察了亚洲新兴股市停牌期间停牌的有效性以及不同类型投资者或交易员的交易表现。Rahim等(2021)[11]以印尼证券交易所为研究对象,分析投资者对停牌的反应。国内学者也对我国股市进行了卓有成效的实证研究,如在取消异常波动停牌的政策背景下分别对中小板股价波动、股市流动性与价格发现效率等方面进行了相关研究(陈舒宁等,2016[12];胡婷等,2017[13];李洋等,2018[14])。石阳等(2019)[15]以重大事项停牌数据为实验对象,实证检验了随意停牌对投资者利益的影响,指出了上市公司的部分停牌行为并不能符合投资者保护的初衷,反而有助于内部私利交易行为,对投资者利益造成了损害。李明琨等(2022)[16]从进化博弈分析的角度研究我国熔断机制的有效性,以及政府监管作用。He等(2019)[17]研究了强制和自愿停牌对中国股市股价、波动性和成交量的影响。
综上所述,深度学习方法在金融时间序列预测上具有较好的运用效果。但针对股票停牌的研究多反映在制度有效性、现有缺陷和制度改进方向,对股票停牌预测研究尤为匮乏,因此本文研究了基于预训练模型的股票停牌预测方法。
三、相关理论基础
(一)停牌理论分析
市场中如果出现对股票交易有特殊影响的重要信息,股票停牌能够为投资者主动划割出可以获取充分信息反馈的时间区间,对股价再预估,进而对之前与当前股价预期存在差异的投资策略进行调整,以削弱交易各方的信息不对称,股票停牌制度制定初衷也在于此。包括股市发生异常波动与企业并购活动在内的多种因素均可能诱发股票停牌。
从停牌原因来看,停牌发生主要是归结于以下三类事件:(一)上市公司披露期中业绩报告、年报,召集股东大会,重要收购合并,扩股增资,公布分红计划,投资以及股权增减变动等需公布重大信息时;(二)上市公司就关于对公司产生重大影响的事项被证券监管机关认为应当澄清与公告时;(三)需就上市公司涉嫌违规开展调查时。
这三类事件的共同核心在于上市公司当前经营中出现了新的重要信息,为消除不同投资者获取该信息的时间差异,保护市场交易的公平性与有效性,上市公司需要暂停其股票交易。依据有效市场假说(Efficient Markets Hypothesis,EHM)理论(Fama,1970[18]),在作为有效市场的股票交易市场中,全部有价值的信息已经准确、及时并充分地反映在股票价格波动上。因此,由上市公司经营过程引发的停牌事件虽然直接原因是新信息发生与传播,但是这种信息与公司的历史经营信息不是割裂的、独立的,应当是由公司管理层或者监管机构根据历史信息进行决策或者在历史信息中读取到了隐藏信息,公司经营发生的新信息与历史信息是存在紧密联系的。
上市公司经营信息的直接体现是股票每日行情,其中包括了股票的交易价格、成交量以及换手率等信息,衍生出最高价、最低价、开盘价、收盘价、成交量、成交额、股价涨跌幅等交易基础指标。根据基本交易信息,可以计算股票交易技术分析指标,这类指标通过综合考量多个基本交易信息,对价格的波动较为敏感,在实际交易分析中被广泛应用,其常见分类如下。
1.超买超卖型指标。
超买,是指在买入需求过旺推动下某股票或市场股价陡升,股价同实质价值发生严重偏离,制造大量股价泡沫。在历经一轮急升后,一旦高位承接力较弱,股票价格出现技术性下跌是有可能的。
超卖,指受大面积沽售影响而导致某股票或市场股价发生急挫,股价显著低于实质价值,但是经过一轮急跌变动,大幅减少了低位抛售压力,价格技术性向上反弹可能会出现。
对市场上这种价格和实质价值不匹配的暂时性现象的度量即超买超卖指标,具体指标包括随机指标KDJ、威廉指标WR、动态买卖气指标ADTM、相对强弱指标RSI和布林极限BB等。
2.趋势型指标。
市场人气盛衰与趋势走向是通过趋势型指标进行反映,均线或者股价通道是判断趋势的方法。通常观点是趋势一经形成则将在特定时段内延续,这就是利用对趋势的研判推断股价变动趋势的基础。趋势型指标计算过程纳入了股价、成交量以及涨跌指数等数据,指标具体包括趋向指标DMI、市场趋势CYE、平滑异同平均线MACD、威廉变异离散量WVAD、筹码引力PAV和量价曲线VPT等。
3.能量型指标。
人气的热度、价格动量的潜能能够利用能量型指标进行测量,而且股票价格的支撑带与压力带也可以被其显示出,具有为预测分析股价后续走向趋势,研判买卖股票的时机节点提供参考借鉴的作用。一般能量型指标包括: 成交量变异率VR、带状能量线CR、威廉多空力度线WAD、市场强弱CYR和心理线PSY等。
4.均线型指标。
均线指标又称移动平均线指标,其主要作用是反映价格运行趋势,尤其是其可以根据投资者需求对不同时间尺度的均线进行计算,能够直观展现长期、中期和短期的趋势,如K线图。常见均线指标有:MA 均线、顾比均线GMMA、多均线BBI、多布林线BBIBOLL和鳄鱼线ALLIGAT等。
其他股票交易技术分析指标还包括成交量型、图表型和五彩K线等。
(二)相关深度学习理论
本文研究基于的深度学习理论包括时间卷积神经网络、注意力机制、迁移学习和变分自编码器等。
1.时间卷积神经网络。
Bai等(2018)[19]基于卷积神经网络模型提出了时间卷积网络(Temporal Convolutional Network,TCN)模型,针对序列问题采用因果卷积加以改进,模型记忆历史信息过程是通过残差模型进行堆叠卷积层实现的。
单向结构的因果卷积(causal convolution)在时间约束上十分严格,表现为神经元的输出仅利用卷积运算与其有因果联系的数据产生,以致限制了时间序列建模的长度。膨胀卷积(dilated convolution)允许卷积时的输入存在间隔采样,使得包含长距离依赖关系的较大范围的信息被每个卷积的输出所容纳,网络输出则能提取较大范围的时间序列特征。采样间隔d(通常以2为底的指数形式递增)称为膨胀因子(dilation rate),设1维序列输入x∈n和滤波器f:{0,…,k-1}→n,则在xt处的膨胀卷积运算F定义如下:
(1)
其中:k表示卷积核的大小。假设d=1,2,4且k=3,则膨胀因果卷积示意图如图1所示。
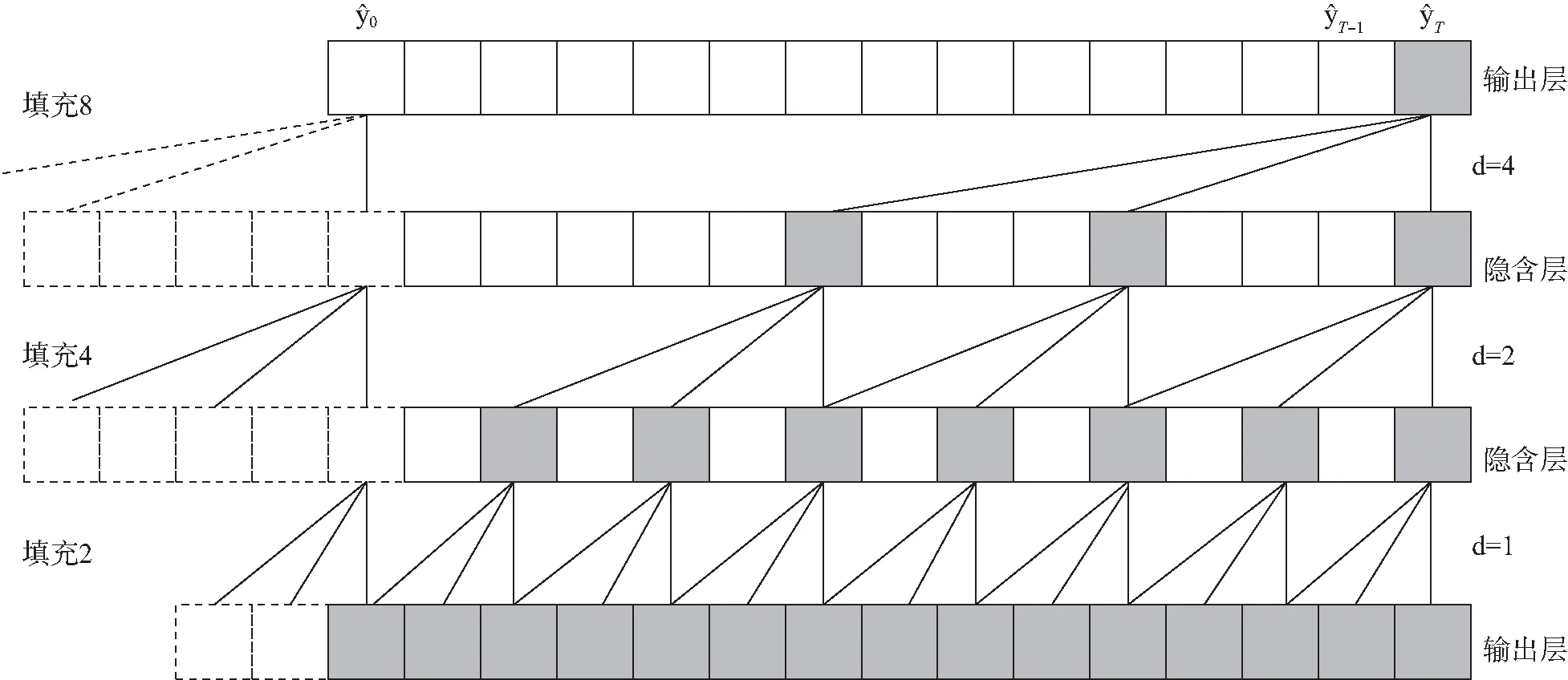
图1 TCN示意图
膨胀卷积和因果卷积在TCN网络结构的卷积层中进行了融合,由卷积核大小、网络深度以及膨胀系数共同决定了其网络感受野。考虑到对网络深度进一步加深以及提升对时间序列信息的学习能力,原本的卷积层由TCN残差模块取代且结构相同,皆包含了膨胀因果卷积层、权重归一化层、ReLU激活函数、Dropout层。如果输入与输出的数据维度不一致,则通过1×1卷积进行处理。
2.注意力机制。
注意力(Attention)机制来源于对生物观察行为的模仿(Mnih等,2014[20]),即在看到整体信息的时候,会主动发现重要信息并分配更多的注意力到目标部分,以获取更多与之相关的信息。注意力机制能够在稀疏数据中提取重要的信息。自注意机制(self-attention)是注意力机制的一种改进方案(刘建伟等,2021[21]),能够对全局的不同特征分配不同的权重,用于分析数据内部的相关性。Attention计算示意图如图2所示(Raffel和Ellis,2015[22])。

图2 Attention计算示意图
图2中Attention计算过程为:首先将隐含层的输出向量[h1,…,hT]组成的矩阵H∈RT×d作为注意力层输入,其中T表示时间序列长度,d代表输出向量的维度。然后利用多层全连接层进行非线性转换并通过Softmax函数完成归一化,得到注意力权重矩阵A=[α1,…,αT]。最后将输入矩阵乘以对应的注意力权重矩阵,加和获得向量c。对应公式定义如下:
A=softmax(Vαtanh(WαHT)
(2)
c=AH
(3)

3.迁移学习。
将已经发展成熟的知识向近(相)似领域迁移的研究方法称作迁移学习(Kumar等,2020[23];Gu和Dai,2021[24])。一般将已有知识表述为源域(Source domain,Ds),而对近(相)似领域又称为目标域(Target domain,Dt),迁移学习的具体过程就是在相似领域应用其从一个或多个源域中提炼的关联知识处理目标域的新问题,迁移学习基本原理如图3所示。

图3 迁移学习示意图
源域Ds一般包含了特征空间x与边缘分布概率P(X),其中X=(x1,…,xn)代表源域数据样本,预测函数f=P(Y|X)和标签空间Y=(y1,…,yn)共同组成任务O,倘若预测函数不知,仍可通过多组源域与目标域训练数据学习而获得。假定存在源域Ds、目标域Dt和有差别的学习任务Os、Ot,迁移学习目的是通过Ds与Dt提升归属于任务Ot的预测函数f在目标域Dt中的预测表现。
4.变分自编码器。
变分自编码器(Variational auto-encoder,VAE)是属于深度生成模型的一种生成式网络结构(Kingma和Welling,2013[25];Utyamishev和Partin-Vaisband,2019[26];Zhou等,2021[27]; Liu等,2022[28]),其基本结构如图4所示,主要分为编码器(Encoder)与解码器(Decoder)两部分。

图4 VAE模型结构图
图4中数据样本x经过输入层到达Encoder,由Encoder生成均值μ和方差σ2,从正态分布N(0,1)中随机采样得到ε,由μ、σ2和ε共同确定隐变量z=μi+ε·σ2,并作为Decoder的输入,由Decoder对隐变量Z进行重构,输出样本x′。定义损失函数L如下:
L=l1+l2
(4)

四、研究方法及模型构建
(一)模型总体设计
股票停牌预测模型的研究过程主要包括:(1)选取部分交易基本指标和技术分析指标,建立停牌预测指标体系;(2)数据预处理后,通过滑动窗口形成时序数据集;(3)训练VAE模型,生成停牌的模拟时序数据,以平衡数据集;(4)预训练模型训练与测试;(5)迁移学习模型参数,训练与测试个股停牌预测模型。模型研究框架如图5所示。

图5 模型研究框架图
(二)模型指标体系
图5中股票交易原始数据包括基本交易指标和技术分析指标,其中基本交易指标是股票市场交易过程中最直接和原始的记录,而技术分析指标是利用交易价格、成交量的变动等数据计算得到的能够反映交易规律的综合信息(谢丁,2009[29])。在综合性、可解释性和客观性原则指导下,选择了22个指标如表1所示。

表1 模型指标体系
(三)数据预处理
设数据集为X=[X1,…,XN],其中N为股票总数,Xi是第i只股票的数据集,分别对Xi进行预处理。首先选择Min-Max进行标准化,然后采用移动滑窗法生成时序数据集S,设定滑动窗口大小为t,窗口的滑动步长为step(即滑动step个交易日)。滑窗从数据集Xi的始部向末尾滑动,同时逐个标记时序的类别。图6显示了当step=1时,S的形成过程。

图6 时序数据生成示意图
(1)设置停牌持续时间阈值为Δ天。
(2)计算时间间隔(Data(xt+1)-Data(xt))>Δ,则yi=1表示停牌,否则yi=0表示正常。
(3)如果yi=1,则设置si-1,…,si-的标签yi-1, yi-2,…,yi-为1,这是因为在个连续的时序中包含停牌特征。
(四)VAE模型平衡数据集
在股票市场交易中,股票停牌属于低频行为,客观上形成了停牌样本的数量大大低于非停牌样本的局面,分类模型的判别能力会被这种不平衡性严重扭曲。引入VAE模型对停牌时序数据进行学习,进而生成模拟数据以平衡数据集。
1.模型训练。
将所有标记为停牌的时序数据转为1维向量作为VAE模型的训练集Sstop={x1,…,xM},其中M为数据集大小。VAE的训练如算法1所示。
算法1:训练VAE。
输入:Sstop;e:迭代次数。
输出:已训练VAE。
① 随机初始化各层权重矩阵W与偏置向量b;
② forepoch=1∶edo
③ fori=1∶Mdo

⑤ 生成标准正态分布的随机变量ε;

⑦ 最小化公式(4)的损失函数,更新W与b;
⑧ end for
⑨ end for
2.生成模拟数据。
利用已训练的VAE模型生成模拟停牌数据x′。为了能够评估x′的质量,需要度量x和x′相似度。通常向量相似度计算的方法包括曼哈顿距离、欧式距离和余弦相似度等,经过实验测试和对比,本文选用余弦相似度,定义如下:
(5)
VAE生成模拟数据过程如算法2所示。
算法2:VAE生成模拟数据。
输入:VAE;Sstop;e:迭代次数;λ:相似度阈值;γ:比较次数阈值;m:随机抽取样本次数。
输出:停牌模拟数据集S’stop。
① 加载VAE;
② forepoch=1:edo
③ VAE的解码器生成新样本x′;
④cnt=0;
⑤ fori=1:Mdo
⑥ 从Sstop中随机抽取1个样本x;
⑦ 根据公式(5),计算相似度Sim=cos(x,x′);
⑧ ifSim>=λthen
⑨cnt++;
⑩ end if
(五)预训练模型
神经网络模型TCN、BiLSTM 、CNN和Attention等在时间序列分析中皆有良好的表现(Fan等,2021[30];Wang等,2021[31]; Yang和Wang,2022[32];Abbasimehr和Paki,2022[33])。鉴于股票停牌时间序列复杂性,单一模型在时空特征提取方面存在一定局限性,本文研究了多种深度学习组合模型包括:
1.TADM:包括输入层、TCN层、Attention层、Dense层、输出层。
2.TBADM:包括输入层、TCN层、BiLSTM 层、Attention层、Dense层、输出层。
3.CBADM:包括输入层、1D-CNN层、BiLSTM 层、Attention层、Dense层、输出层。
4.BADM:包括输入层、3层BiLSTM、Attention层、Dense层、输出层。
5.BDM:包括输入层、3层BiLSTM、Dense层、输出层。
(六)个股停牌预测模型
根据基于模型/参数的迁移方法(Model/ Parameter Based Transfer Learning),通过预训练-微调方式将预训练模型的部分参数进行迁移,构建基于预训练模型的个股停牌预测模型,如图7所示。

图7 模型预训练-微调过程
神经网络的浅层完成一般特征(general feature)的学习,而深层需完成和具体任务关联的特殊特征(specific features)的学习。伴随网络层次的深入,模型的学习表征逐渐由一般特征平滑到特殊特征。由于源域数据集和目标数据集的类别一致性,参数迁移时采用all-to-all迁移策略即目标域的第m层由源域中的第n层迁移得到。以TADM为例,将输入层到注意力层参数逐层迁移到个股停牌预测模型对应各层之中,如图8所示。
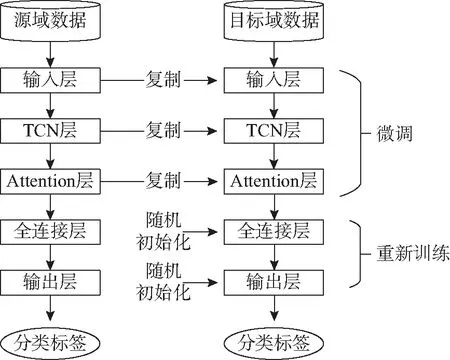
图8 模型预训练-微调过程
参数迁移完成后,个股预测模型利用预训练模型强大的股票停牌特征提取能力从目标域数据中分析潜在停牌信息,鉴于目标个股自身的波动特征,需要个股预测模型对其提取以提升预测的准确度,将模型全连接层与输出层随机初始化后再重新进行训练。

算法3:VAE生成个股模拟数据。

① 加载VAE;

③cnt=0;
④x=Sstop[n];
⑤ for epoch=1:edo
⑥VAE的解码器生成新样本x′;
⑦ 根据公式(5),计算相似度Sim=cos(x,x′);
⑧ ifSim>=λthen
⑨cnt++;

个股的每个停牌时间序列生成m条模拟数据,由于模型VAE是由所有停牌类数据训练而得,个股的部分停牌时间序列可能背离整体特征导致无法在特定λ下产生模拟数据。
(七)评价标准
通常的模型评估指标包括准确率(Accuracy)、精准率(Precision)、召回率(Recall)以及F1值(F1-score),四个比率值的区间为[0,1],值越趋近于0表示预测表现越差,越趋近于1表示预测表现越好。
对所有股票的停牌类样本分类正确率反映了预训练模型提取A盘整体停牌特征的能力,因此设置Q评分如下:
1.将停牌类别(y=1)的分类正确率TP(True Positive)划分3个区间:L1=[0.8,1.0],L2=[0.5,0.8)和L3=[0.0,0.5),分别设置权重w1=1.0,w2=0.6,w3=0.2。
2.统计落在L1,L2和L3中的股票数:c1,c2和c3。
3.定义Q:
(6)
其中N是股票总数。
五、实验及结果分析
(一)实验数据
以我国A股市场2 539家上市公司作为研究对象,其中2家公司未发生停牌事件。从Tushare平台采集股票交易基本数据,包括日线行情与每日指标数据,并由其计算技术分析指标。采集时间区间为2013年5月13日至2021年9月30日。统计各指标数据并进行数据的计算处理后,获得了共计4 390 024条记录的实验数据集,每一条数据中包括12个股票交易基本数据和10个技术分析指标,合计22个属性特征。
本文主要利用市场中长期信息研究A股的停牌问题,因此采用移动滑窗法生成股票停牌时间序列数据集,各参数设置分别为:时间滑窗宽度t=15个交易日,停牌持续时间阈值Δ=7天,窗口的滑动步长step为1,参数=7。实验共生成了3 764 841条时间序列数据,其中正常类3 740 960条,停牌类23 881条,数据维度为[15,22]。为减少正常类的冗余和降低样本不平衡程度,每隔10个交易日重新抽样,生成训练集的正常类为373 772条。
(二)VAE模型平衡训练集
选取所有停牌时序数据作为VAE模型训练集,并将时间序列转换为1维向量,其维度为330=15×22。设置VAE模型参数结构为:330-128-64-32-[4,4]-32-64-128-330,即输入层与输出层包含330个神经元,Encoder层包含3个隐含层,神经元个数分别是128、64和32,而Decoder层也包含3个隐含层,神经元数为32、64和128。隐变层的μ和σ2分别有4个神经元,计算z=μ+ε·σ2得到隐变量输入到Decoder层。
实验中设置算法1中的参数M=23 881,e=100。算法2中的参数λ=0.85,m=10,γ=6,e=1 000 000。已训练VAE模型生成模拟停牌数据71 065条,平衡前后训练集类别样本的分布见表2所示。
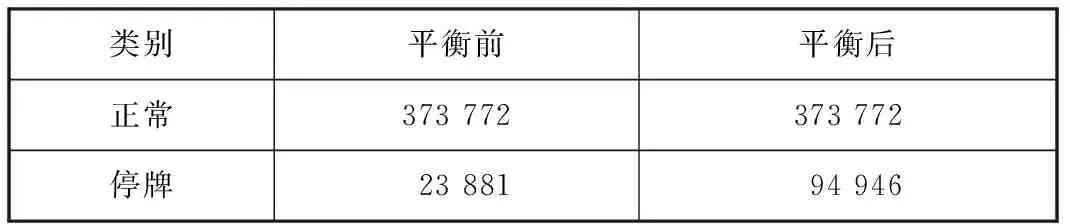
表2 平衡前后训练集样本分布
为了验证VAE模型的有效性,采用BDM模型测试平衡前后的训练集,实验结果如表3所示。

表3 训练集平衡前后的对比实验结果
表3显示采用VAE模型对样本类别不平衡问题的处理对提升模型的分类效果十分明显。
(三)预训练模型实验及分析
抽取平衡前训练集的2%作为预训练模型的测试集,将剩余数据进行类别平衡后,取其80%为训练集,剩下20%为验证集。
1.模型参数设置。
模型TADM、TBADM和CBADM中的BiLSTM 层、TCN层、1D-CNN层的主要参数设置如表4所示。
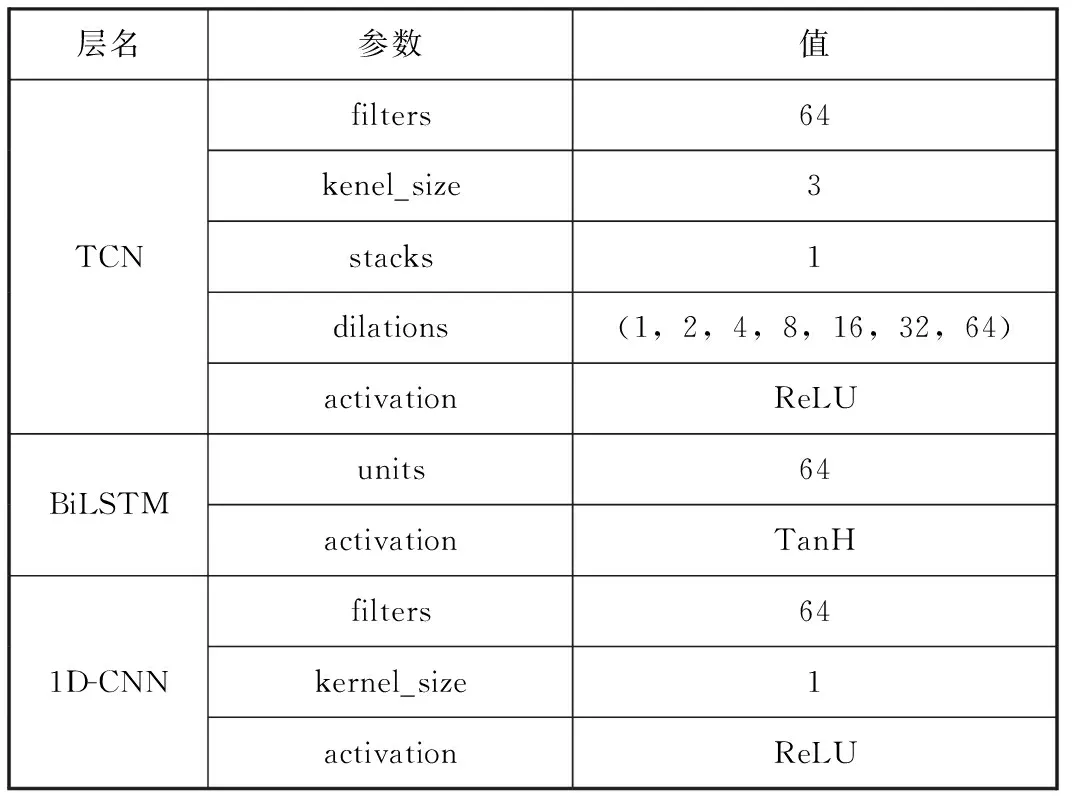
表4 主要参数
模型BADM和BDM中3层BiLSTM 层的units分别为:64,32和16,激活函数设为TanH。
2.对比实验及结果分析。
模型训练参数设为:epochs=100,batch size=32和dropout=0.2,采用Adam优化器,学习率设为0.001。5个模型在测试集上的实验结果如表5所示。

表5 模型实验结果
表5显示TBADM 的模型性能最佳,但TCN已经拥有了CNN和LSTM的优点,能提取较大范围的时间序列特征,而进一步使用BiLSTM 层学习TCN输出的双向特征以及注意力机制突出了其输出特征向量,导致其过拟合严重。CBADM、BADM和BDM的模型性能相似,也存在过拟合问题,源于受限于BiLSTM 层对时间序列建模的长度。TADM的模型性能虽略低,但其学习A盘整体停牌特征能力是最强的,因此本文以TADM作为预训练模型。用模型TADM分别对2 539个股的时序数据(不包含模拟停牌数据)进行分类测试,表6统计了落在不同TP区间中的股票数量。

表6 预测结果统计
表6中股票数合计2 537只,有2只股票没有停牌记录,结果显示TP≥80%的股票数合计占比超过总体股数的75%以上。
3.模型性能的行业分析。
进一步分析预训练模型TADM在各个行业中的预测性能。依据证监会行业划分标准,在所有79个行业中选取股票数超过100的6个行业,如表7所示。

表7 行业股票分布统计
图9给出了落在区间L1、L2和L3的6个行业股票数占比直方图。

图9 不同行业的模型性能对比直方图
图9显示针对6个行业的股票预测,TADM模型皆具有良好的表现。只有一只股票的TP低于50%(46.15%),是属于行业C27中某药业,曾一直被怀疑存在严重的财务舞弊,最终因其造假被证监会处罚,模型对其预测TP结果说明虚假财务数据误导了投资者,背离了模型从正常交易中发掘的停牌规律,所以无法进行有效预测。另外,不同行业受到的政策市场等影响不一样,因此它们的停牌规律是有差异的,TADM模型的表现也就略有不同,如表8所示。
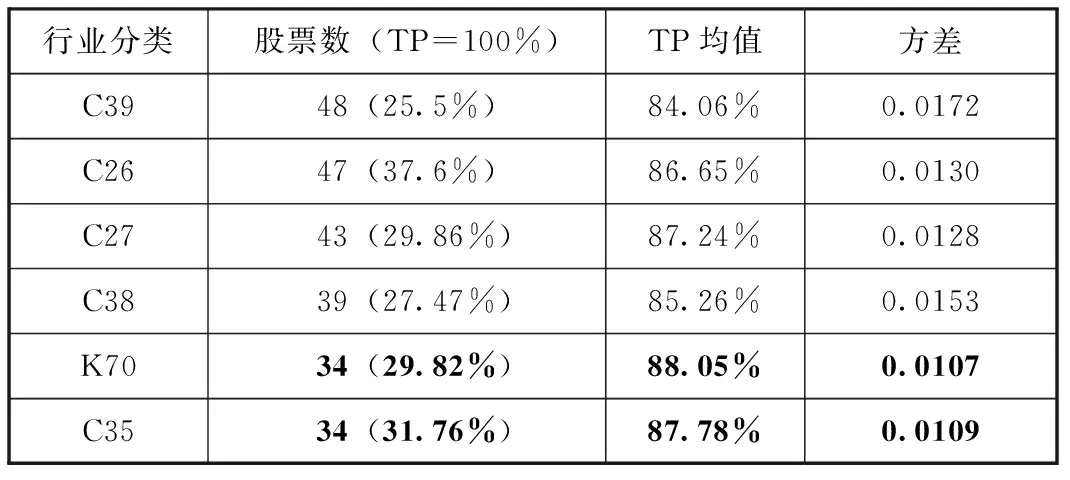
表8 不同行业的模型性能分析
表8显示K70和C35的TP均值较高且方差较小,说明TADM模型在这2个行业中表现更佳。
(四)个股停牌预测模型实验及分析
基于TADM预训练模型的迁移学习构建个股的停牌预测模型STFTADM(Single Transfer Learning Model base on TADM)。TADM模型的参数共计174 209个,设计重新训练参数的数量为1 921,即只有1%的参数参与学习,如图8所示。
1.个股选择与平衡处理。
为了较全面评估迁移学习的效果,实验中分别从区间L1、L2和L3中选取股票。选取表6中落在L1区间的所有6只股票。被选取股票的相关信息如表9所示。

表9 选取的股票信息
表9显示个股的训练集存在极度不平衡,采用算法3进行处理,设置参数λ=0.83,m=50,e=10 000。生成的个股模拟停牌数据如表10所示。

表10 个股模拟停牌数据
表10显示个股的个别停牌类数据未能产生模拟数据,这是由于模型VAE是由A股所有停牌类数据训练而得,个股的部分停牌时间序列可能背离整体特征,导致其在阈值0.83下无法产生对应的模拟数据。
2.模型训练与结果分析。
将个股平衡后的数据集依照6∶2∶2的比例依次划分为训练集、验证集与测试集。模型STFTADM训练参数设为:epochs=25,batch size=1和dropout=0.2,采用Adam优化器,学习率的设置:L1中的股票为0.005;L2为0.001;L3为0.000 5。各个模型STFTADM测试对应个股的时序数据(不包含模拟停牌数据),与对应的预训练模型测试的对比结果如表11所示。

表11 个股模型实验结果对比
表11的实验结果显示个股的STFTADM模型相对于TADM的测试效果有着较大幅度的提高,如股票002356的停牌分类正确率由64.285 7%提升到100%。表11中东方银星(股票代码:600753)的预测结果较差,其STFTADM模型的TP=76.470 6%,该公司曾亏损约5 002万元,经营性现金流大幅下降,近年才由盈转亏。康美药业(股票代码:600518)的STFTADM模型的TP=75%,该公司曾存在严重的财务舞弊。贝肯能源(股票代码:002828)的STFTADM模型的TP=77.78%,该公司作为民营企业,其收入对中石油集团单一客户依赖性较高,存在业绩下滑的风险。
相较于预训练模型TADM,个股的模型STFTADM表现出更强的样本识别能力且误报率较低。这是因为利用了预训练模型的网络层参数,能较好地捕获停牌样本的时间序列特征,同时基于预训练模型在无形中拓展了目标个股数据集,使得模型更加鲁棒,增强了模型的泛化能力。
六、结论
本文基于停牌预测的视角,选取2013—2021年A股市场2 539家上市公司的数据,采用预训练模型和迁移学习等深度学习方法对股票停牌事件进行预测研究。研究结果表明:(1)虽然现行股票停牌存在随意性强、时间长以及诱因复杂性等问题,但仍能从中长期金融数据波动中提取其中关于停牌的特征模式,引入深度学习模型能学习到所有上市公司股票停牌的共性特征,在此基础上通过迁移学习机制获得个股停牌特征,进而实现精确预测。(2)在股票市场交易中,股票停牌属于低频行为,本文提出的基于VAE的停牌模拟数据生成算法能有效模拟停牌时序数据,极大改善了深度学习分类模型的性能。(3)预训练模型能较好地预测A股市场各个行业板块的停牌事件,约75%的股票停牌预测准确度在80%以上,六个行业板块的实验结果分析显示房地产业和专用设备制造业的预测效果最佳。在此基础上的个股迁移学习模型测试结果表现出更高的预测精度。(4)预测效果较差的上市公司往往存在较严重的财务舞弊或经营不善等问题,其中长期金融数据波动背离了模型从正常交易中发掘的停牌规律。
A股市场的随意停牌现象不仅限制了投资者正常交易的权利,而且还存在着信息不对称下内部人对于股东权益侵蚀的可能(石阳等,2019[15])。本文研究能够对未来可能发生的股票停牌做出较为准确的判断,能为资本市场提供更好的信息服务。基于此,本文提出以下相关建议: (1)我国中小投资者在信息不对称的情况下,一方面可以借鉴个股停牌预测结果,有效地规避停牌风险,进而减少投资损失以及实现资产保值;另一方面也可为部分投资者利用个股停牌后的股价波动,实现收益最大化等目标提供帮助。(2)个股停牌预测结果在一定程度上反映了上市公司的财务或经营状况,投资者可以适当规避停牌预测结果较差的个股,以优化投资方案。(3)本文的研究为证监会与交易所预测停牌行为提供了可能,监管部门可以动态监控A股市场各个行业板块的停牌事件,及时对整体停牌趋势做出前瞻性判断,为宏观调控和政策调整提供了参考。
