引入语义匹配和语言评价的跨语言图像描述
2022-11-18张静郭丹宋培培李坤汪萌
张静,郭丹,宋培培,李坤,汪萌
1.合肥工业大学计算机与信息学院,合肥 230601; 2.大数据知识工程教育部重点实验室(合肥工业大学),合肥 230601;3.智能互联系统安徽省实验室(合肥工业大学),合肥 230601
0 引 言
图像描述任务是指给定一幅图像,计算机能够自动生成正确的语言描述(Farhadi等,2010),涉及目标检测(汤鹏杰 等,2017;李志欣 等,2020)、关系推理(Hou等,2020)和语言序列生成(Zhou等,2020)等多项前沿技术。其成果不仅可应用于网页检索、人机交互等应用领域,还可以帮助视障人士更好地获取和理解信息。目前,得益于深度学习的快速发展和现有大规模成对的图像—句子数据集出现,图像描述任务已经取得了显著成果(Wang等,2019;Ji等,2020;罗会兰和岳亮亮,2020)。然而,大多数现有工作关注于图像英文描述生成;非英语母语者很难直接从现有的研究成果中受益。跨语言图像描述任务(如从英文描述迁移至中文描述)逐渐成为研究的一种趋势(Lan等,2017;Gu等,2018;Song等,2019)。
跨语言描述任务存在的一个客观原因是由于缺少大规模目标语言的图像描述数据集。如图1所示,在训练数据集中,图像只有成对的轴语言描述(即源语言,如英文)和无关的目标语料库(如中文)。收集成对的图像—句子数据集是一项耗时费力的工作,为世界上任意一种语言都构建图像—句子成对数据集,代价更为昂贵。幸运地是,现已有大规模的英文—图像对描述数据集的出现。在具有丰富的目标语言语料库的前提下,将已有的轴语言描述(如英文)视为连接图像和目标语言(如中文)描述的桥梁是解决跨语言图像描述任务的一种常见做法。Lan等人(2017)将轴语言数据通过翻译模型得到目标语言数据,视为句子伪标签,同时引入句子流畅性评估模型,根据流畅性得分奖励赋予伪标签相应的权重,减少不流畅的伪标签句子在模型训练中的作用。Gu等人(2018)则先利用轴语言训练图像描述模型生成轴语言描述,再将其由翻译模型得到目标语言描述,通过正则化轴语言编码器和目标语言解码器的词嵌入优化模型来减少轴语言与目标语言的风格化差异。上述两种代表性工作各自存在明显的弊端:一是伪标签存在翻译误差,不如人工标注语言自然流畅,过度依赖伪标签会导致模型生成的句子质量受限;二是关注图像自身语义信息到轴语言的翻译,忽视了轴语言作为真实标准引入的语义知识。
如图1所示,中文描述与英文描述存在语言风格差异,图像的源英文描述为“A photo of the back of a girl in a yellow dress”(一个穿黄色长裙的女孩的背影照片,短语句式),而目标域中文描述属于常规主谓宾的句式,翻译风格为“一个穿着黄色裙子的女生站在喷泉前”。而且,强调语义也不尽相同,虽然句子中都出现了“黄色长裙的女生”,但真实的中文描述以“女生”为描述中心,而英文描述却以“一张照片”为描述中心。
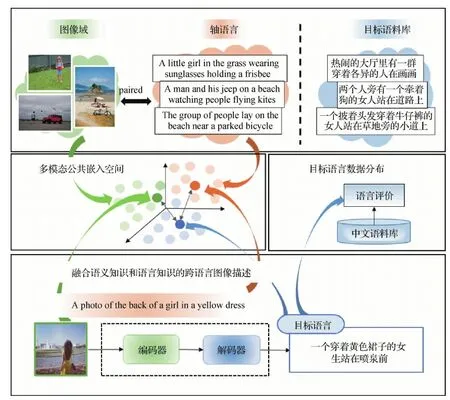
图1 跨语言图像描述任务及本文解决方案Fig.1 The task of cross-lingual image captioning and our solution
针对上述弊端及挑战,本文提出了一种引入语义匹配和语言评价奖励的跨语言图像描述方法。为了兼顾图像自身语义及其轴语言所包含的语义知识,分别构建了一个源域语义匹配模块和一个目标语言域评价模块,从而对模型进行语义匹配约束和语言知识指导:1)图像&轴语言域语义匹配模块是一个多模态视觉语义嵌入网络,通过将图像、轴语言以及目标语言描述映射到公共嵌入空间来衡量各自模态特征表示的语义一致性。2)目标语言域评价模块在独立的目标语言语料库上学习目标语言的数据分布和表达方式,并依据目标语言风格,对所生成的描述句子进行语言知识评分。本文方法在语义匹配和语言知识的共同约束下,从而生成更加自然流畅、语义更相关的目标语言描述。
1 相关工作
1.1 图像描述生成
图像描述任务是涉及计算机视觉和自然语言处理两个研究领域的交叉任务。目前基于深度学习的图像描述工作已经取得了有效进展。Vinyals等人(2015)首次提出端到端的CNN(convolutional neural networks)编码器—RNN(recurrent neural network)解码器结构,以最大化输入图像的目标句子的似然概率为训练目标求解图像描述任务。此后,在编码器—解码器的框架基础上出现了各类融合注意力机制的方法。Xu等人(2015)把图像分割为多个区域块,将区域块的各自空间注意力融合到图像卷积特征计算中,实现单词和局部视觉信息的对齐。Anderson等人(2018)在图像区域级和对象级(object-level)特征上分别计算注意力。上述方法建立在视觉空间特征上,没有考虑字幕丰富性。Wang等人(2019)提出了一个分层注意力网络,将文本特征与区域块、对象视觉特征一起输入特征金字塔层次结构同步计算,融合不同语义预测下一时刻的词。Ji等人(2020)引入记忆机制,在序列生成过程中建立强记忆连接,关注不同时间步下注意力区域的变化以及关联性。
另外,Ranzato等人(2016)早就指出图像编码器—句子解码器模型的改进并不能解决图像描述任务中训练—测试目标不匹配的问题。模型在训练时通常以真实单词最大似然概率为训练目标,在测试时却使用BLEU(bilingual evaluation understudy)、CIDEr(consensus-based image description evaluation)等评价指标。因此,将强化学习的方法引入到图像描述任务中。Rennie 等人(2017)提出自批判序列训练(self-critical sequence training),将当前模型在推理阶段生成的句子的特定指标(CIDEr)评分作为基准奖励以减少方差。比基准奖励得分高的句子得到鼓励,比基准奖励得分低的句子被抑制,经过反复循环的强化训练,模型会生成CIDEr得分更高的句子。Liu等人(2018)提出一个自检索模块以优化描述句子的多样性和独特性,该模块提供的奖励可以针对图像内容生成差异性描述句子。可见,语义指标的考量已引入到优化目标,成为传统图形描述任务的一个研究方向。本文延续采用编码器—解码器的基准框架求解跨语言图像描述生成任务,并将语义奖励优化引入本文方法。
1.2 跨语言图像描述生成
跨语言图像描述任务发展较慢,目前仍处于探索阶段。为了解决在不成对的图像—目标文本数据集上的图像描述问题,Lan等人(2017)直接利用翻译模型得到图像在目标语言的伪标签,同时提出一个句子流畅性评估模块,根据流畅度评分对于流畅与不流畅的句子的目标损失赋予不同的权重,以抑制不流畅句子在训练中的负面作用。即使生成不流畅的句子,也能包含正确的图像对象信息。目前,跨语言图像描述方法大多采用基于轴语言转换的方法。Gu等人(2018)提出了基于轴语言的跨语言描述模型,先使用图像描述模型为图像生成轴语言,然后利用翻译模型得到目标语言。为了克服不同语言的风格化差异,该模型进一步正则化轴语言的编码器和目标语言的解码器的词嵌入参数。当然,基于轴语言到目标语言的翻译误差也会被引入,翻译错误不会随着参数传递而缓解。
在语义奖励方面,Song等人(2019)为了提升跨语言描述与图像的视觉相关性,提出一种自监督的奖励模型(self-supervised rewarding,SSR),利用句子级语义匹配和概念级语义匹配分别提供粗粒度和细粒度的视觉相关奖励。然而,由于不同标注者的主观关注点不同,同一幅图像的不同描述可能包含不同的概念,得到的概念级语义奖励并不完全可靠。此外,得益于视觉概念检测Faster R-CNN(region based CNN) 模型 (Ren等,2017)的良好性能,Feng等人(2019)提出了无监督图像描述模型,引入Faster R-CNN对生成句子进行概念约束,采取图像—句子双向语义重构的方法来进一步提升句子质量。Ben等人(2022)提出一个语义约束自学习框架,迭代地进行伪标签生成和图像描述模型训练。这两个工作都由图像中检测出的对象(object)作为引导,来加强输入图像和输出句子之间的语义对齐。然而,视觉概念检测器Faster R-CNN是在大规模的英文图像描述集上预训练好的,仅适用于英文概念检测;对于其他语言的概念尤其是在缺失训练数据集的情况下无法直接应用。
本文同样关注于语义奖励优化的正向反馈。不同于概念语义反馈,本文方法关注在特征映射空间中图像、轴语言句子和目标语言域句子三者之间的语义匹配(句子级语义反馈),还引入了目标语言域的文本语料对生成的翻译句子实现语言评分,以期待生成与目标语言域风格一致的图像描述。
2 本文模型
如图2所示,本文提出跨语言图像描述模型由3部分构成:1)朴素的图像编码器—句子解码器(图像描述生成)模块;2)图像&轴语言域语义匹配模块,用于提供语义匹配的奖励优化,兼顾了源域图像与轴语言的语义信息,映射图像、轴语言和目标语言于公共嵌入空间进行语义匹配计算;3)目标语言域评价模块,用于提供语言评价奖励,引入目标域数据分布知识进行语言评价约束。第1个模块负责描述句子的生成,后两个模块引导模型学习语义匹配约束和语言知识优化,使模型生成更加流畅和语义丰富的描述。
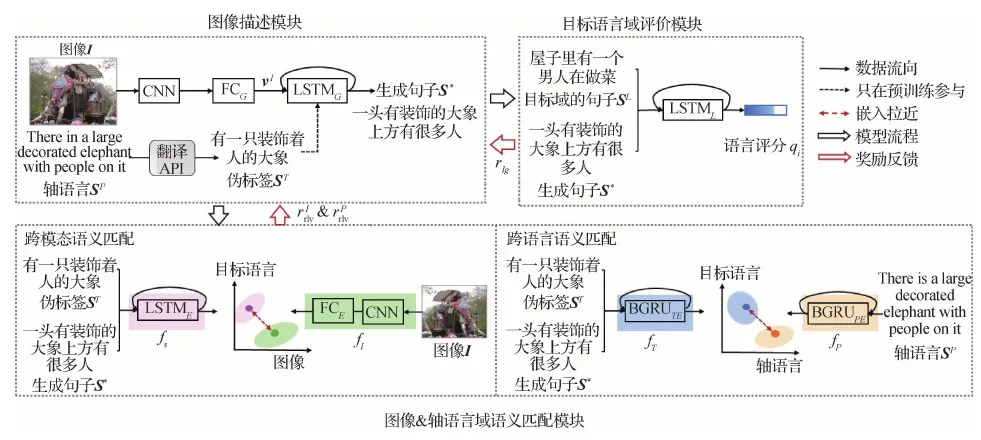
图2 跨语言图像描述模型Fig.2 Cross-lingual image captioning model
2.1 图像编码器—句子解码器模块
采用朴素的图像编码器—句子解码器框架生成描述句子。使用预训练网络模型ResNet(residual net)-101(He 等,2016)和一层全连接层(fully-connected layer,记为FCG)提取图像I的特征vI;使用单层LSTM(long short-term memor),记为LSTMG对vI进行解码生成当前时间步的单词。与前人工作(Lan等,2017;Song等,2019)类似,采用百度翻译API(http://api.fanyi.baidu.com)对图像I的源域描述语言SP获取目标域伪句子标签ST,对此模块进行初始化。在模型初始化训练中,预训练模型ResNet-101不参与模型优化,全连接层FCG和LSTMG参与模型优化。优化函数目标设为最小化句子中正确单词的负对数概率,即
(1)
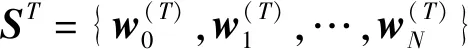
2.2 图像&轴语言域语义匹配模块
由2.1节初始化后的模型生成的描述具有如下特性:对伪标签的简单模仿或是高频词汇的重复组合,或缺少与图像内容的相关性。人工标注的轴语言具有丰富的语义,是对图像信息的切实描述。轴语言与图像应包含一致的语义信息。同时结合图像与轴语言两者语义信息,本文提出了一种多模态语义匹配模块进行语义相似度约束。
2.2.1 跨模态语义匹配
针对异构的图像与句子,首先将图像和句子映射到公共嵌入空间,衡量语义的关联度。如图2所示,图像语义嵌入网络fI由CNN编码器(使用预训练网络模型ResNet-101)和一层全连接层(记为FCE)构成。文本语义嵌入网络fS由单层LSTM(记为LSTME)构成。LSTME最后时刻的隐向量定义为输入句子在公共嵌入空间的语义向量。将图像—伪标签数据对(I,ST)输入,即可得到图像I在公共语义空间的嵌入特征fI(I),句子ST在公共语义空间的嵌入特征fS(ST)。对于匹配对(I,ST),寻找同组batch的句子集中与I不匹配的负例ST′,同组batch的图像集中与ST不匹配的负例I′。以最小化双向ranking 损失对公共语义空间进行预训练,即
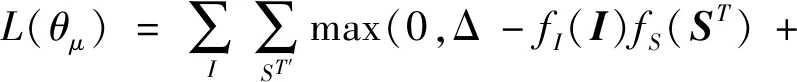
(2)
式中,Δ表示界限超参数;θμ是本模块FCE和LSTME的学习参数。
2.2.2 跨语言语义匹配
同时,本文还有轴语言句子—伪标签句子对(SP,ST),可以为目标语言句子与轴语言句子的语义相似性度量提供数据支持。本节引入跨语言语义匹配计算增强句子的语义相关性,采用类似2.2.1节的语义嵌入网络机制对齐目标语言与轴语言嵌入向量。目标语言和轴语言的编码器都采用单层BGRU(bidirectional gated recurrent unit)结构,以BGRU最后时刻的隐向量作为句子特征向量。fP是轴语言特征映射器(BGRUPE),fT是目标语言特征映射器(BGRUTE)。同样地,以最小化双向ranking 损失对公共语义空间进行预训练,即
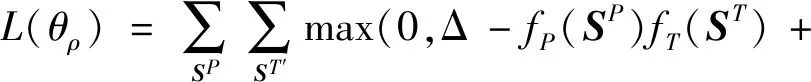
(3)
式中,对于匹配对(SP,ST),ST′是同组batch的伪标签句子集中与SP不匹配的负例,SP′是同组batch的轴语言句子集中与ST不匹配的负例。θρ是本模块BGRUPE和BGRUTE的学习参数。
2.3 目标语言域评价模块
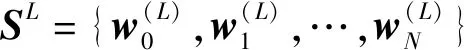
(4)
式中,θω是本模块LSTML的学习参数。
2.4 基于语义匹配和语言奖励的模型优化
在进行上述3个模块初始化的预训练自学习后,联合3个模块一起实现2.1节中图像编码器—句子解码器模块的奖励优化学习。具体地,利用2.2节的语义匹配奖励和2.3节的语言评价奖励对2.1节模块进行优化。其中,语义匹配奖励衡量目标语言与图像、轴语言在视觉对象(object)、对象关系(relation)上的一致性。首先,输入图像I,由2.1节自动生成目标语言域的句子S*。其次,计算如下语义匹配奖励和语言评价奖励:
1)图像—句子匹配奖励。图像I经由视觉语义嵌入网络fI映射,句子S*经由文本语义嵌入网络fS映射到公共嵌入空间,其跨模态语义匹配奖励可以定义为
(5)
2)轴语言—句子匹配奖励。同样地,源域句子SP经由轴语言特征映射器fP映射,句子S*经由目标语言特征映射器fT映射,其跨语言语义匹配奖励可以定义为
(6)
式中,SP是与图像I匹配的轴语言描述。
3)目标域句子语言评价奖励。将句子S*的每个单词迭代输入2.3节在目标语言域训练好的模块LSTML,语言评价的过程为
(7)
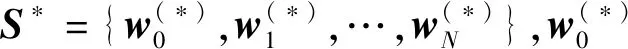
(8)
整个跨语言描述模型的总奖励设置为
(9)
式中,α、β和γ是超参数,取值范围为[0,1]。α、β和γ为经验参数,最佳值设置见3.2节。
为减少模型训练时的期望梯度方差,遵循自批判序列训练方式。当前模型利用多项式分布采样方式得到句子S*,另外默认按照最大概率贪婪采样方式得到句子S,以rtotal(S)作为基准奖励。对句子S*的总体奖励可表示为rtotal(S*)-rtotal(S),比基准奖励得分高的句子得到鼓励,比基准奖励得分低的句子被抑制,经过反复循环的强化训练,模型生成语义匹配奖励更好和语言评价奖励更好的句子。因此,跨语言描述模型的最终目标损失可定义为
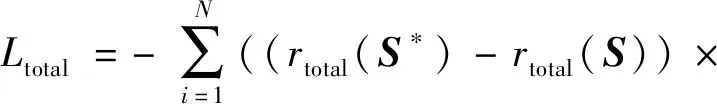
(10)
式中,θG是图像描述模块的参数。
3 实验及结果分析
为了验证模型在跨语言图像描述任务上的有效性,本文分别进行了两个子任务实验:以中文为轴语言实现图像英文描述和以英文为轴语言实现图像中文描述。
3.1 数据集及评价指标
采用两个基准数据集进行评测,如表1所示。1)英文数据集MS COCO(Microsoft common objects in context)(Lin等,2014),包含123 287幅图像,每幅图像至少有5个人工标注的英文描述。实验遵循Lin等人(2014)提出的划分方式:113 287幅图像用做训练集,5 000幅图像用做验证集,5 000幅图像用做测试集。中文单词划分使用“结巴”工具(https://github.com/fxsjy/jieba),保留出现频率不少于5的中文单词,同时将所有长度大于16的中文句子进行截断。英文单词的划分使用“斯坦福解析”工具(http://nlp.stanford.edu:8080/parser/index.jsp),保留出现频率不少于5的英文单词,同时将所有句子长度大于20的英文句子进行截断。2)中文数据集AIC-ICC(image Chinese captioning from artificial intelligence challenge)(Wu等,2017),训练集有208 354幅图像,验证集有30 000幅图像,每幅图像包含5个人工标注的中文描述。AIC-ICC没有官方公布的测试集,实验遵循Song等人(2019)提出的划分方式:在30 000幅的验证集中随机采样5 000幅图像作为测试集,5 000幅图像作为验证集,剩余20 000幅图像归到训练集中。注意AIC-ICC和MS COCO两个数据集中图像和句子各不相同。
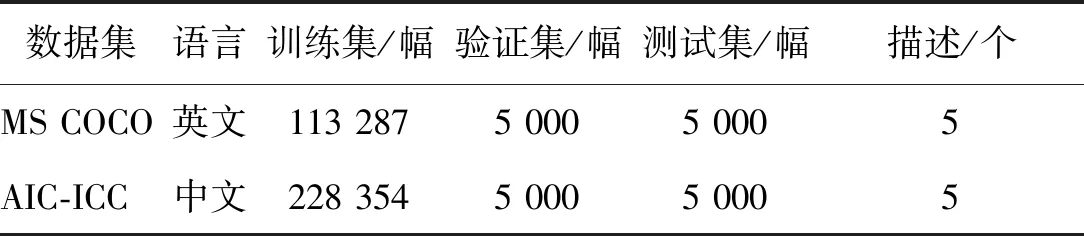
表1 实验使用的数据集信息Table 1 Statistics of the datasets used in our experiments
在从中文跨到英文的图像描述任务中,以AIC-ICC中文数据集联合MS COCO英文语料训练,使用MS COCO测试集进行评测。在从英文跨到中文的图像描述任务中,以MS COCO数据集联合AIC-ICC中文语料训练,使用AIC-ICC测试集进行评测。实验中,采用语义评估指标BLEU,METEOR(metric for evaluation of translation with explicit ordering)和CIDEr对生成的图像描述进行评测。
3.2 训练设置
在图像编码器—句子解码器模块(图像描述生成模块)中,图像特征vI由预训练模型ResNet-101和一层全连接层提取,维度d=512;并将其作为解码器LSTMG第0时刻的隐向量输入。在跨模态语义匹配模块中,图像语义嵌入网络由预训练模型ResNet-101和一层全连接层组成,目标语言编码器采用单层的LSTME结构。在跨语言语义匹配模块中,轴语言和目标语言的编码器分别采用单层的BGRUPE和BGRUTE框架,隐藏层维度均是512维,BGRU输出的维度是1 024维。在目标语言域评估模块中,语言序列模型使用单层的LSTML。本文所有的LSTM结构的隐藏层维度和单词嵌入维度均为d=512维。两个子任务实验在整个模型训练过程中,dropout设置为0.3,预训练时的batchsize设为128,强化训练时的batchsize设为256。
在语义匹配模块(2.2节)和语言优化模块(2.3节)预训练结束后,学习参数θμ,θρ和θω都保持固定。二者提供奖励共同引导图像描述生成模块(2.1节)学习更多的源域语义知识和目标域语言知识。
1)以中文为轴语言实现图像英文描述。图像描述生成模块预训练的学习率是1E-3,源域语义匹配模块和目标语言域评价模块的预训练的学习率设为2E-4。在使用语言评价奖励和多模态语义奖励训练时,图像描述生成模块的学习率是4E-5,α、β和γ分别取值1,1,0.15。
2)以英文为轴语言实现图像中文描述。图像描述生成模块预训练的学习率是1E-3,源域语义匹配模块和目标语言域评价模块预训练的学习率设为4E-4。在使用语言评价奖励和多模态语义匹配奖励训练时,图像描述生成模块的学习率是1E-5,α、β和γ分别取值1,1,1。
3.3 实验结果分析
3.3.1 消融实验
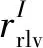
3.3.2 跨语言英文图像描述主性能分析
表3展现了不同方法关于跨语言英文图像描述任务在MS COCO测试集上的实验结果。本文工作与现有跨语言图像描述实验进行了对比,具体实验包括:1)Baseline仅利用伪标签和式(1)中损失函数初始化的模型(见2.1节);2)2-Stage pivot-Google API(Gu等,2018)使用图像描述生成模块生成轴语言,再将轴语言通过Google翻译器得到英文描述(目标语言);3)2-Stage pivot(Gu等,2018)-Baidu API采用实验2)中图像描述模型框架生成轴语言描述后,采用翻译API得到目标语言描述。不同之处在于将Google API替换为Baidu API。本文增加了Baidu API的测试;4)2-Stagepivot-joint model是Gu等人(2018)提出的一种跨语言图像描述方法,同样先将图像通过图像描述模块生成轴语言描述,再将轴语言描述通过翻译模块得到目标语言,与实验2)和实验3)不同之处在于共享了两个模块的编码器和解码器嵌入参数来减少风格化差异;5)SSR是Song等人(2019)针对不成对的图像—句子数据集提出的跨语言描述模型,利用句子级相关性奖励和概念级相关性奖励来提高描述的视觉语义相关性。为了实验对比,Song等人(2019)还设置了SSR-Baseline & CIDEr Reward模型,引入朴素的CIDEr评分奖励替换所提出的句子兼概念语义奖励,进行强化学习训练。
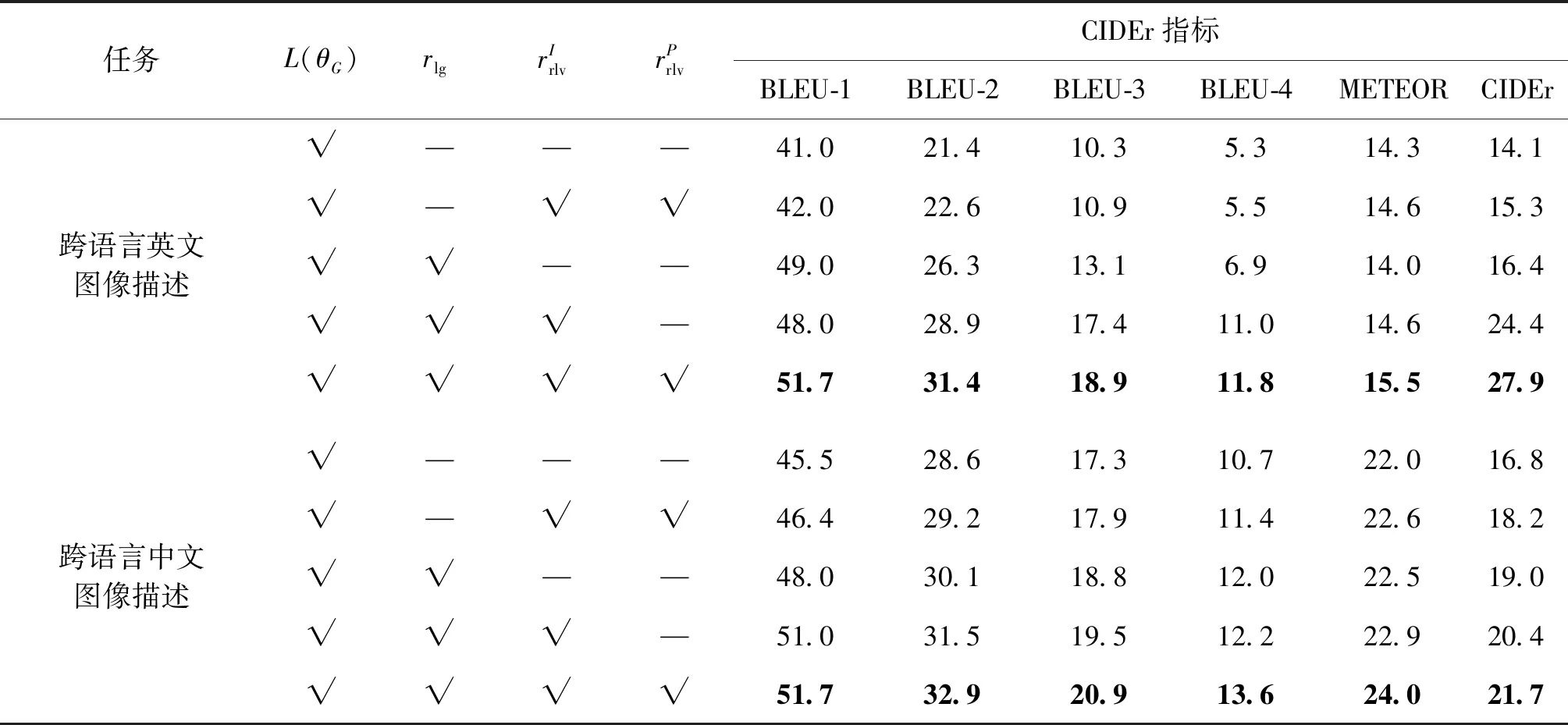
表2 不同奖励对于跨语言英文图像描述任务在MS COCO测试集上的贡献和不同奖励对于跨语言中文图像描述任务在AIC-ICC测试集上的贡献Table 2 The contribution of different rewards for cross-lingual English image captioning on MS COCO test dataset and cross-lingual Chinese image captioning on AIC-ICC test dataset /%
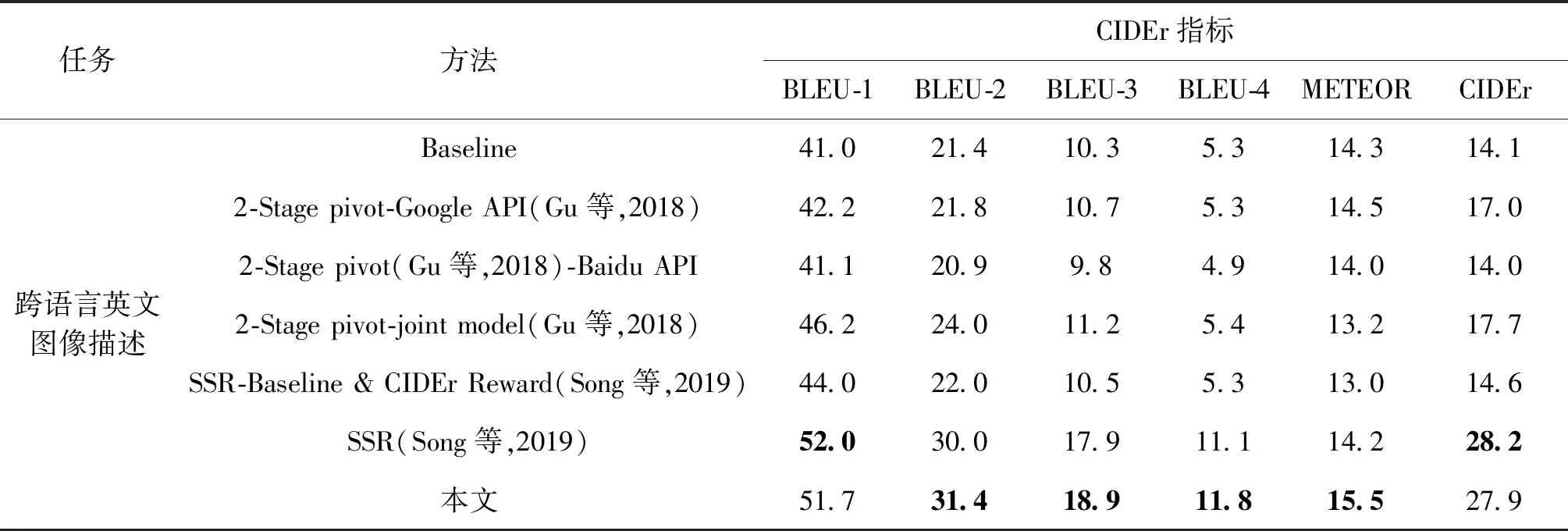
表3 不同方法关于跨语言英文图像描述任务在MS COCO测试集上的性能比较Table 3 Performance comparison with different methods for cross-lingual English image captioning evaluated on the MS COCO test dataset /%
如表3所示,与2-Stage pivot-Google API相比,2-Stage pivot-Baidu API性能表现不佳,在所有方法中为最低性能。同样也表明了Google API在英语翻译上比Baidu API有优势。尽管2-Stage pivot Google API的指标得分有所提升,相比之下,本文模型的BLEU-4得分和CIDEr得分高出了6.5%和10.9%。由此表明,与直接使用轴语言描述作为监督信息参与模型训练、再进行翻译的两阶段方法相比,本文模型表现更为优越。与2-Stage pivot-joint model相比,本文方法在BLEU-4评分上提升了6.4%,在CIDEr评分上提升了10.2%。结果表明,目标语言域评价模块引导模型学习了丰富的目标域语言表达方式,降低了翻译模型中不流畅句子对模型的负面影响。与SSR-Baseline & CIDEr Reward实验结果相比,本文模型在所有评价指标上都有明显提升,其中CIDEr评分提升13.3%。这一结果表明,仅使用CIDEr Reward强化学习策略,对求解复杂的跨语言图像描述任务还远远不够。与SSR方法相比,本文方法在BLEU-2、BLEU-3、BLEU-4和METEOR等4个评价指标上的得分分别提升了1.4%,1.0%,0.7%和1.3%。结果表明,相比SSR对生成句子使用句子级和概念级语义奖励机制,本文提出的强调多模态的语义匹配和语言指导模型,更重视图像、轴语言和目标语言的语义一致性约束,从不同模态数据出发向一致性语义表达优化,能学习到更丰富准确的语义知识。
图3是本文模型关于跨语言英文图像描述任务在MS COCO测试集的可视化效果,红色字体表示来自Baseline模型翻译的错误语义,绿色字体表示来自本文模型翻译的正确语义。图3表明,一方面,本文模型生成的描述更贴近图像视觉内容,例如,本文模型可以识别出物体属性:将错误的人物对象“woman”替换为“boy”;可以推理对象关系:一个男人“sitting on the green grass”纠正为“sitting on a horse in the grass”。另一方面,本文模型生成的句子与目标语言风格差异更小。例如,本文模型生成的句子更偏向目标语言风格的“某人在某地做某事”句式:“a man is skiing in the snow in the mountains.”(一个男人在山里的雪地上滑雪),而Baseline模型倾向给对象添加定语修饰:“a man with a ski pole in both hands was skiing in the snow”(一个双手拿着滑雪杖的人在滑雪)。

图3 跨语言英文图像描述在MS COCO测试集的样例Fig.3 Examples of the cross-lingual English image captioning from the MS COCO testing set
3.3.3 跨语言中文图像描述主性能分析
表4展现了不同方法关于跨语言中文图像描述任务在AIC-ICC测试集上的评分效果。本文方法与4项跨语言中文图像描述实验进行了对比:1)Baseline方法;2)SSR-Baseline & CIDEr Reward(Song等,2019)方法;3)2-Stage pivot(Gu等,2018)-Baidu API方法;4)SSR(Song等,2019)方法。
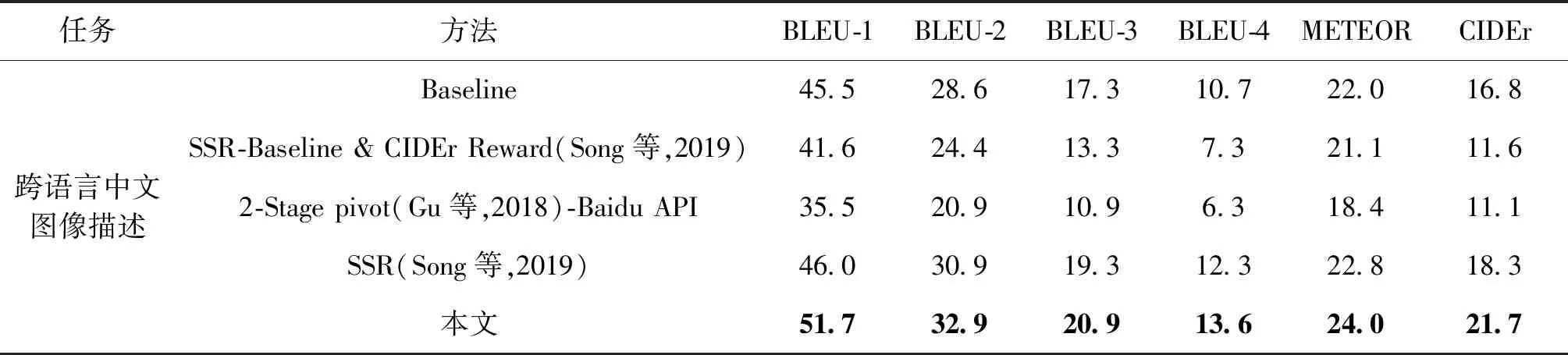
表4 不同方法关于跨语言中文图像描述任务在AIC-ICC测试集上的性能比较Table 4 Performance comparison with different methods for cross-lingual Chinese image captioning evaluated on the AIC-ICC test dataset /%
如表4所示,2-Stage pivot-Baidu model在所有方法中取得了最低性能。相比于2-Stage pivot-Baidu API方法,本文模型的BLEU-4和CIDEr得分分别高出7.3%和10.6%。这表明,针对跨语言中文图像描述任务,与两阶段的图像—轴语言—目标语言的方法相比,本文模型更具优越性。与Baseline方法相比,本文模型在所有指标上都取得了明显提升,其中BLEU-4和CIDEr分别提升了2.9%和4.9%。与SSR-Baseline & CIDEr Reward方法相比,本文模型在BLEU-4和CIDEr得分分别提升了6.3%和10.1%。与性能最好的SSR方法相比,本文方法在BLEU-1、BLEU-2、BLEU-3、BLEU-4、METEOR和CIDEr等6个评价指标上的评分分别提升了5.7%,2.0%,1.6%,1.3%,1.2%和3.4%。以上结果表明,跨语言中文图像描述任务中,在语义匹配模块和语言评价模块的共同作用下,也同样生成更加语义完整和流畅的句子。
图4是本文模型关于跨语言中文图像描述任务在AIC-ICC测试集的可视化效果,红色字体表示来自Baseline模型翻译的错误语义,绿色字体表示来自本文模型翻译的正确语义。从图4可见:一方面,本文模型生成的描述与真实描述语义更相关,例如,本文模型可以对缺少的、有误的视觉信息进行补充和替换:Baseline模型生成的句子“一个穿着西装打着领带的男人站在一起”只检测出一个人物对象且句子不流畅,本文模型的句子“一个穿着西装的男人站在一个穿着裙子的女人旁边”,关注了更丰富的语义信息且句子更加流畅;将错误的视觉信息“手里拿着冲浪板”修正为“站在海滩上的岩石上”。

图4 跨语言中文图像描述在AIC-ICC测试集的样例Fig.4 Examples of the cross-lingual Chinese image captioning from the AIC-ICC testing set
另一方面,本文模型生成的句子与真实描述语言风格更相近。例如本文模型生成的句子更偏向真实描述的“连续且简短的”描述风格,符合目标语料的风格“一个女人在外面的桌子旁吃东西”,而Baseline模型更倾向于生成“逗号分隔的”复杂句式“一个女人坐在一张桌子旁,手里拿着一部手机。”
4 结 论
针对现有的跨语言图像描述方法在缺乏成对图像—句子数据集下生成的目标语言描述与图像语义关联弱、与真实目标语言风格差异明显等问题,本文提出了一种引入语义匹配和语言评价的跨语言图像描述模型。在以编码器—解码器为基准架构的模型上,本文设计了图像&轴语言语义匹配模块,通过对目标语言、源域图像和轴语言句子进行语义匹配计算来约束描述的语义相关性。同时本文设计了目标语言评价模块,通过学习目标语料集中的语言表达来优化描述的语言质量。在语义匹配奖励和语言评价奖励的指导下,模型生成语义更准确和语言更流畅的描述。
在MS COCO和AIC-ICC两个数据集上与其他现有方法分别进行了跨语言英文图像描述和跨语言中文图像描述测试和比较。定量对比结果表明,本文模型在多个测评指标上达到最好,生成的描述与真实的目标语言描述更加接近,具有较好的鲁棒性和有效性。定性对比结果表明,本文模型提升了描述与图像的语义一致性。同时消融实验结果表明,本文提出的语义匹配奖励、语言评价奖励对模型都产生了积极作用。
由于本文模型对图像细节的关注较弱,生成的描述在精度上仍有不足。因此,在后续工作中将考虑引入注意力机制,探索更加细粒度的跨语言图像描述。
