肺腺癌CT影像分子分型研究进展
2022-11-18卜菊聂生东魏珑
卜菊,聂生东,魏珑
1.上海理工大学医疗器械与食品学院,上海 200093; 2.山东建筑大学计算机科学与技术学院,济南 250101
0 引 言
根据世界卫生组织发布的2020年全球最新癌症负担数据显示,肺癌的发病率和死亡率在中国仍居首位(Wild等,2020)。在所有肺癌类型中,非小细胞肺癌(non-small cell lung cancer,NSCLC)占比约80%~85%,且多数患者一经确诊即为中晚期并多发转移。由于NSCLC具有易转移的特性,晚期NSCLC患者的预后效果极差,直接导致该型肺癌患者5年生存率低下,即使在新的治疗方法下也仅为所有癌症的一半(Zeng等,2018)。
在NSCLC中,基因突变状态在临床决策中起着举足轻重的作用。自美国食品药品监督管理局(Food and Drug Administration,FDA)批准在NSCLC治疗中使用靶向药物后(Sun等,2018),肺癌靶向药物接连面世。分子医学的高速高质量发展使肺癌的治疗手段进入了针对驱动基因的个体化分子靶向精准治疗时代。靶向治疗因其显著的疗效与良好的安全性,逐渐成为治疗晚期NSCLC的标准方法(韩志萍 等,2019)。活检作为肿瘤基因突变状态检测的金标准,最常用的分析技术包括直接测序法、聚合酶链反应(polymerase chain reaction,PCR)、高通量测序技术(next generation sequencing,NGS)、荧光原位杂交(fluorescence in situ hybridization,FISH)和免疫组化(immunohistochemistry,IHC)。直接测序法因容易产生假阴性结果而被淘汰,PCR技术仅能测试预先定义的突变,无法检测到新的突变,其他检测方法对各种突变状态检测的敏感性各有偏重(Garinet等,2018)。事实上,基于肿瘤的异质性,其病变的病理特征很难从活检取得的病理标本中完全反映出来。另外,活检存在有创性、基因检测耗时长及价格昂贵等弊端,不宜多次用于晚期肺癌患者,此时计算机断层扫描(computed tomography, CT)显示出优势。
CT扫描时间短、分辨率高且价格相对低廉,是监测NSCLC患者疗效的最常用手段。由于CT成像技术对肿瘤的整体性评估在一定程度上降低了肿瘤异质性对诊断结果的影响,美国国家癌症研究所(National Cancer Institute,NCI)在研讨会中提出将已知的基因表型及生物标记物和成像表型联系起来,寻找一种有可能取代重复活检的新方法,并将肺部CT置于数据收集优先列表之首(Colen等,2014)。由此,探寻与NSCLC驱动基因突变相关的CT影像标志物成为新的研究方向,亟需确定相关标志物从而进一步通过影像学手段预测肿瘤的基因表型。
此前,针对驱动基因的研究多集中于腺癌、无吸烟史或轻度吸烟的患者,对NSCLC其他类型的基因突变研究滞后,导致基于CT图像的肺癌分子分型研究也多在腺癌中进行。
本文使用PubMed和Web of Science数据库对2021年4月之前发表的相关论文进行检索,搜索关键词包括lung cancer、NSCLC、CT、PET(positron emission computed comography)/CT以及相关的突变基因,以识别与肺腺癌CT影像分子分型研究方法相关的文献。
首先介绍常见的肺腺癌分子分型,随后根据文献检索结果对国内外肺腺癌CT影像分子分型研究现状进行综述,依据主要的技术路线将这些方法划分为基于CT语义特征的相关性分析和基于机器学习构建预测模型,最后总结该领域现阶段面临的问题,并对未来研究方向做出展望,以期为癌症分子分型领域的研究提供有益参考。
1 肺腺癌分子分型
表皮生长因子受体(epidermal growth factorreceptor,EGFR)是中国最常见的肺腺癌驱动基因。自2003年其抑制剂(tyrosine kinase inhibitor,TKI)吉非替尼被发现开始,经过不断研究与临床实践,肺癌的分子靶向药物治疗得到飞速发展,成为近年来肺癌治疗研究的热点之一。EGFR-TKI一线治疗EGFR基因敏感突变患者的成功推动了肺癌个体化治疗进程,之后针对间变性淋巴瘤激酶(anaplastic lymphoma kinase,ALK)融合基因NSCLC靶向治疗的成功极大激发了研究者对肺癌驱动基因的研究热情(Gandhi和Jänne,2012)。
肺腺癌突变总阳性率达85%以上,其中仅EGFR的占比就超过60%,鼠类肉瘤病毒癌基因(kirsten rat sarcoma viral oncogene,KRAS)和间变性淋巴瘤激酶(anaplastic lymphoma kinase,ALK)占比位居其次,其他驱动基因,如ROS1(proto-oncogene receptor tyrosine kinase)、BRAF(v-raf murine sarcoma viral oncogene homolog B1)、HER2(human epidermal growth factor receptor-2)等在肺腺癌中占比较低(陈灵锋 等,2019)。美国国立综合癌症网络(National Comprehensive Cancer Network,NCCN)非小细胞肺癌治疗指南(Ettinger等,2018)表明EGFR突变、ALK融合、ROS1重排、BRAF突变及NTRK(neurotrophin receptor kinase)融合型肺腺癌都已有相应的靶向药物获得FDA批准在治疗中使用,而KRAS突变虽然常见,但几次确定KRAS特异性抑制剂的研究都未成功。除此之外,指南中建议进行基础广泛的分子检测,以评估可能存在有效药物的罕见驱动突变。即不仅将EGFR、KRAS、ALK、BRAF和ROS1等常见驱动突变基因纳入常规检测,对RET(rearranged during transfection)、HER2(同ERBB2(erythroblastic leukemia viral oncogene homolog 2))和MET(mesenchymal-epithelial transition)等新出现的罕见驱动突变基因也进行检测。
2 基于CT语义特征的相关性分析
早期的肺腺癌分子分型研究着重于分析肿瘤肺腺癌分子亚型与CT语义特征(肿瘤位置及大小、分叶征、毛刺征、空洞、钙化等)之间的关系。CT征象由多位医生共同定义,并使用组内相关系数(interobserver correlation coefficient,ICC)、kappa系数等进行一致性评估。所有特征先后进行单因素分析和多因素分析,研究各突变状态产生的潜在因素,构建多元逻辑回归模型等。
EGFR突变型肺癌在不吸烟的亚洲女性中发生率较高,研究表明,其与多种CT语义特征有一定关联。特别地,研究(Zhang等,2019)表明,磨玻璃结节密度影(ground glass opacity,GGO)、空气支气管征、胸膜凹陷征及血管集束征为引发EGFR突变的重要危险因素。另有研究(Shi等,2017;Suh等,2018)表明,EGFR 19号外显子(exon)突变型肿瘤较小,多存在胸膜凹陷征而无纤维化,而21号外显子突变型则更易存在毛刺征且GGO含量较高。但是,Han等人(2020)认为,EGFR突变型肺腺癌(包括多发性原发肺腺癌)多表现为存在部分GGO,而与其他CT特征相关性较低。
ALK重排型肺癌多在无吸烟史或轻度吸烟的年轻病人中产生,因其只占肺癌的3%~5%,关于ALK重排与其CT征象相关性的报道相对较少,综合文献初步研究认为,ALK重排型肺癌与一些语义特征相关。还有少量研究在KRAS、ROS1、HER2以及BRAF中进行,但这些研究皆为样本量偏小的回顾性分析,后续需要进一步扩大研究样本并进行系统综合分析。
EGFR和ALK的相关特征及与肺腺癌各分子亚型相关的CT语义特征如表1所示。
综上所述,统计分析的方法可以初步研究出EGFR突变型肺癌与其CT语义特征之间的相关性。但由于样本量较小,且肿瘤的异质性不只是CT语义特征上存在差异,更多表现为肉眼无法识别的纹理差异,因此,基于传统CT语义特征的相关性分析并未在其他分子亚型的影像学研究中得出更具说服力的结论。另外,对发生率较低的分子亚型,扩充数据无疑是十分困难的。为了充分利用仅有的样本数据,从有限数据中挖掘出更多更客观的信息,基于机器学习的分子分型研究方法应运而生。

表1 与肺腺癌各分子亚型相关的CT语义特征Table 1 CT semantic features related to molecular subtypes of lung adenocarcinoma
3 基于机器学习的预测模型
3.1 基于影像组学的预测模型
影像组学这一概念由荷兰学者Lambin于2012年提出(Lambin等,2012),作为医工交叉的产物,它能够有效解决肿瘤异质性难以定量评估的问题,在肿瘤诊断、治疗和预后分析等方面表现出巨大优势。与传统的相关性分析方法中将医生主观评估的CT语义特征输入模型不同,基于影像组学的肺腺癌分子分型研究方法首先手动或半自动地分割出感兴趣区域(即肿瘤区域),然后使用软件或自定义算法自动提取肿瘤图像的一阶统计量、形状和纹理等特征,经相关性分析、秩和检验以及其他特征选择算法筛选后,构建传统机器学习预测模型并评价其性能。
肺癌分子分型的影像组学研究起初的样本量较小,Weiss等人(2014)仅对48例肺腺癌患者的CT图像进行定量纹理分析并构建决策树(decision tree,DT)模型,发现低峰度和正偏度与KRAS突变显著相关。之后Velazquez等人(2017)和Pinheiro等人(2020)也使用了树算法且扩大了研究样本,但在鉴别KRAS突变型与泛野生型肺腺癌时并未得到好的结果。此外,大量的国内外研究在预测肺癌EGFR突变状态中展开。大部分文献中使用逻辑回归(logistic regression,LR)构建预测模型,其中Hong等人(2020)在CT平扫和增强图像中分别提取了影像组学特征,Lasso算法筛选后构建了朴素贝叶斯分类器(naive bayesian classifier,NBC)、K近邻 (k-nearest neighbor,KNN)、随机森林(radom forest,RF)和支持向量机(support vector machine,SVM)、DT和LR等6种预测模型,比较每个模型的接收者操作特征曲线(receiver operating characteristic curve,ROC)下面积(area under curve,AUC)后,选择最佳模型LR做进一步研究,最终得出结论:CT增强图像中提取的影像组学特征对EGFR突变型肺腺癌的预测性能较平扫图像中提取的更为优越。这些研究在鉴别EGFR突变型与泛野生型时获得了良好的结果,且普遍认为临床特征、CT语义特征与组学特征融合将对模型性能有显著提升,但在鉴别EGFR 19号、21号外显子及L858R型突变时,AUC最高仅有0.793。肺腺癌分子分型影像组学研究文献如表2所示。其中,PCA(principal components analysis)表示主成分分析,mRMR(max-relevance and min-redundancy)表示最大相关最小冗余,t-SNE(t-distributed stochastic neighbor embedding)表示t分布随机邻域嵌入,LASSO(least absolute shrinkage and selection operator)表示最小绝对收缩与选择算子,ICC(intraclass correlation coefficient)表示组内相关系数,RFE(recursive feature elimination)表示递归特征消除;DBSCAN(density-cased spatial clustering of applications with noise)表示具有噪声的基于密度的聚类方法,DT表示决策树;RF表示随机森林,XGBoost(extreme gradient boosting)表示分布式梯度增强,LR表示逻辑回归,ACC(accuracy)表示准确率,SEN(sensitivity)表示敏感性。

表2 肺腺癌分子分型影像组学研究文献综述Table 2 Literature review of molecular typing of lung adenocarcinoma based on radiomics
此外,一些预测肺腺癌EGFR突变的影像组学研究基于PET/CT进行(Zhang等,2020;Liu等,2020b;Yang等,2020),构建的模型同时包含从患者CT和PET影像上提取的组学特征,能够为分型研究提供功能成像信息,在一定程度上提高了模型的预测可靠性,但预测能力与基于CT影像的影像组学模型相似,AUC为0.82~0.87。
结合文献内容发现,基于医学影像的肺腺癌分子分型影像组学研究的关键在于特征的提取与筛选。各研究提取的影像组学特征虽多属于一阶统计量、形状和纹理特征这3大类,但具体的特征数量却千差万别。如Yang等人(2019)中仅对原图提取这3类特征,而Velazquez等人(2017)对原图进行小波变换和高斯滤波,而后在3种图像上提取特征。这种特征数量的差异导致两者之间特征筛选方法不同,前者直接使用所有特征构建RF模型,获得每个特征的重要性分数,仅选择分数大于0.01的特征构建最终的预测模型;后者则复杂得多,首先设计一种无监督的两步特征选择算法,而后通过最小冗余最大相关性(maximum relevance and minimum redundancy,mRMR)算法选择排名前20的特征构建RF模型。总之,特征工程是肺腺癌分子分型影像组学研究工作的重点,提取并筛选出来的特征的好坏几乎决定了最终模型预测结果的优劣。因此当人为设定的可解释特征无法满足预测需要时,能够更深层次挖掘图像信息的深度学习神经网络模型的优势逐渐凸显。
3.2 基于深度学习的预测模型
深度学习神经网络是机器学习的另一分支,能够模拟人脑分析学习的机制,高度自动化地学习图像深层次的特征,达到预测识别的最终目标。深度学习方法在图像识别等领域已趋于成熟,但在肺腺癌分子分型的应用研究尚处于起步阶段。
基于深度学习的预测模型多为基于卷积神经网络(convolutional neural network,CNN)的全监督学习。Li等人(2018a)构建了包含3个残差网络的多级残差卷积神经网络(multi-level residual convolutional neural networks,MCNNs)模型,输入为3种不同尺寸的3D图像块。研究还将MCNNs与影像组学模型、临床信息模型以及三者的融合模型进行比较,发现MCNNs(CNN1)对EGFR突变的检测能力明显优于影像组学模型(radiomics1),AUCCNN1= 0.81 > AUCradiomics1= 0.74(AUCCNN1为CNN1的AUC,余同),且无论是影像组学模型还是临床信息模型,与MCNNs融合后的检测性能都未有显著提升(p> 0.05)。Zhao等人(2019)得到了相似的结论,研究构建了3D DenseNets模型,在数据增强环节引入了mixup算法,且使用TCIA(the cancer imaging archive)公共数据集的数据作为验证集,使模型的鲁棒性更强。结果证明,深度学习模型(CNN2)检测EGFR突变的能力较影像组学模型(radiomics2)更优,AUCCNN2= 0.750 > AUCradiomics2= 0.687。但有些文献的结论则不同。Mahajan等人(2010)使用223个病例构建深度学习模型(CNN3)和影像组学模型(radiomics3),认为影像组学模型更能鉴别出EGFR突变,AUCradiomics3= 0.940 > AUCCNN3= 0.720;Qin等人(2020)创建了一种长短期记忆(long short-term memory,LSTM)循环神经网络(recurrent neural network,RNN)模型,将筛选后的临床特征与CNN提取的特征(CNN-features)融合,发现融合特征(fusion-features)能够显著提升模型的预测性能。AUCfusion-features= 0.78 > AUCCNN-features= 0.69;而Song等人(2021b)将临床信息模型与修改后的3D ResNet10模型融合,融合模型对ALK重排的检测能力较仅使用深度学习模型有极大提高,AUC从0.775 提高到 0.848。
除此之外,Wang等人(2019)构建基于密集连接的2D CNN模型,如图1所示,使用ImageNet自然数据集图像预先训练模型前20层,该模型对EGFR突变也有良好的预测能力,AUC = 0.81。

图1 Wang等人(2019)的神经网络模型Fig.1 The structure of neural network model in Wang et al. (2019)((a)the structure of neural network model in Wang et al. (2019);(b) the structure of block 1 and block 2 in (a))
由于构建模型的策略不同,深度学习模型的检测结果相差较大。Xiong等人(2019)研究了基于ResNet101的神经网络模型在不同策略(输入维度、输入尺寸、切片方法及训练方法)对EGFR突变的鉴别能力,认为采用融合输入尺寸、多视图切片方法及迁移学习建立的2D CNN模型性能最佳,AUC = 0.838,但在不使用迁移学习时,3D模型普遍优于2D模型。基于深度学习的肺腺癌分子分型研究基本流程如图2所示。
上述研究皆采用端到端的CNN模型,即2D或3D图像输入网络后直接输出最终的预测结果,也有研究仅在部分流程中使用深度学习模型。Yu等人(2017)用6层CNN模型提取特征,而在预测阶段使用SVM模型。Zhang等人(2021)在患者CT影像上提取并筛选了784个影像组学特征,根据重要性评分将其排列成一个28 × 28的2D特征矩阵,随后将其输入到基于通道注意力网络(squeeze-and-sxcitation network,SENet)的CNN模型中进行训练,即仅在最终的预测阶段使用深度学习模型。
与全监督学习不同,任雪婷等人(2020)设计了一种基于联合成对学习和图像聚类的无监督深度学习分类模型(unsupervised classification combined with paired learning and image clustering,UC-CPLIC)用于识别肺腺癌亚型。通过无监督卷积特征融合网络(unsupervised convolutional feature fusion network,UCFFN)深度提取图像特征,将获得的特征层次聚类后进行联合配对学习,根据配对信息更新图像聚类标签和UCFFN参数,迭代循环直到聚类结果收敛到一个稳定点,最终训练出的模型在合作医院及TCGA-LUAD(the cancer genome atlas-lung adenocarcinoma)两个数据集上的平均识别准确率达到了0.93。
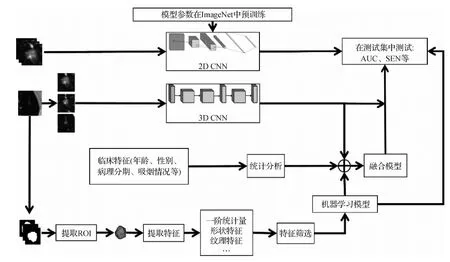
图2 基于机器学习的肺腺癌分子分型研究实验流程Fig.2 The experimental process of molecular typing of lung adenocarcinoma based on machine learning
综上所述,深度学习预测研究需要较大样本的支持,若样本较小,预测能力可能比影像组学模型差;3D CNN模型可以反映肿瘤的总体状态,对突变的预测能力更强,但是将迁移学习应用到2D CNN模型中,可能得到更好结果;深度学习模型不需要对肿瘤进行精细分割,仅需要大致框取肿瘤区域,在数据预处理阶段较影像组学方法节省了大量的时间和人力。总体上,基于深度学习的肺腺癌分子亚型预测研究虽然处于起步阶段,但已经获得了很好的结果,且随着公共数据库的逐步完善,深度学习神经网络模型具有极大的研究前景。
4 结 语
本文探讨了近年来肺腺癌CT影像分子分型研究的几种方法,从最初利用统计分析研究CT征象与基因表达间的关联,到如今建立深度学习神经网络模型实现自动化地预测肺腺癌分子分型,影像基因组学在肺癌诊断领域取得了突破,但仍具有一定局限性,尚不能完全满足实际临床应用需求,主要体现在以下3个方面:1)肺腺癌基因突变状态复杂,很多病例为双基因甚至多基因突变,而多数研究只专注于其中的一种基因突变状态,忽略了其他位点突变带来的影响。此外,大部分研究在探寻EGFR突变的影像学表型中展开,其他分子亚型的相关研究极少。以上问题限制了此类研究的泛化能力。2)相关的公用数据集不完备,同时具有基因表达和医学图像数据的数据集较少,甚至因长时间未更新导致一部分图像数据质量差,很难与当前医院获取的数据融合。这显然无法满足当前使用大数据建立深度神经网络模型以实现分子分型预测的需要。3)单一的CT图像不能完全展现肿瘤状态,需要其他医学图像补充肿瘤其他信息。
未来,应进一步将神经网络模型用于肺癌分子分型预测研究,优化特征提取与筛选算法,以达到提高预测结果准确性的目的。同时,根据基于机器学习的相关研究,将神经网络模型与临床信息、语义特征、影像组学特征构建的模型结合,能够显著提高模型预测能力。因此,基于语义特征的相关性分析以及基于影像组学的预测模型研究应扩大研究范围,考虑不同人种之间的差异,形成更为系统化的综合性研究,明确与各突变基因显著相关的可解释特征,从而为预测模型的建立提供重要依据。此外,可以考虑结合多视角的CT影像或其他医学图像(如PET图像)进行研究,多方面信息能够得到更精确的预测结果。然而,这些研究都需要有力的数据支持,通过建立规范统一的肺癌分子分型标准,以及包含肿瘤解剖图像和功能成像的标准化分子分型数据库,能够显著改善当前研究数据差异过大的现状,使研究人员将目光更多地集中在提高算法性能上,也使肺癌分子分型的影像学研究能够具有更好的临床应用前景。
