自监督学习下小样本遥感图像场景分类
2022-11-18张睿杨义鑫李阳王家宝苗壮李航王梓祺
张睿,杨义鑫,李阳,王家宝,苗壮,李航,王梓祺
陆军工程大学指挥控制工程学院, 南京 210007
0 引 言
遥感场景分类是遥感图像处理和分析的重要组成部分,在灾害探测、环境监测以及地质勘探等任务中发挥着十分重要的作用(Anwer等,2018;Tao等,2021)。早期,遥感场景分类一般利用图像的手工特征构建分类器(Cheng等,2014),如光谱特征、纹理特征和结构特征等。手工特征提取模型需对遥感图像进行去噪、归一化和特征降维等数据预处理,然后通过图像编码得到相应的特征向量,最后利用分类器完成遥感图像的分类(Wang等,2017;Zhu等,2017)。基于手工特征的遥感图像分类方法针对性较强,能够适应特定类别的图像特征,但是特征选择会耗费研究者的大量精力,且往往很难推广到其他类别。
随着人工智能技术不断成熟以及硬件资源飞速发展,卷积神经网络(convolutional neural network,CNN)广泛应用于图像分类、目标识别以及目标检测等多个领域(Szegedy等,2015;Dong等,2020)。CNN对图像的表征能力越来越强,逐渐取代传统手工特征模型成为主流方法(Cheng等,2020)。CNN由大量神经元组成,本质上是一种人类大脑的形式化表示(Krizhevsky等,2012)。神经元中的权重与激活函数共同决定输入的特征是否被响应,输出结果又通过梯度反传更新神经元的权重,直到模型参数拟合(Simonyan和Zisserman,2015)。CNN通常利用大量数据以及相应的标签不断学习才能达到预期效果,在数据不足时,模型很容易出现过拟合等问题(刘颖 等,2021)。因此,如何模拟人类学习,进而设计一种可以适应小样本数据的遥感场景分类模型具有十分重要的意义(季鼎城 等,2019)。
小样本学习是指模型只需利用少量样本训练即可达到相应学习任务的要求。此外,一个性能较好的小样本遥感图像分类模型应具备在基类上训练后,只通过少量样本的学习就可以适应新类别的能力(Wang等,2021;刘颖 等,2021)。当前,小样本学习算法大多遵循元学习(Sun等,2019)框架。元学习(meta-learning)是一种面向任务的学习方式(Finn等,2017;Lee等,2019;Bertinetto等,2019),在模型训练准备阶段,元学习会抽取不同样本组成大量的子任务来增加训练复杂性。每个任务由元支撑集和元查询两部分组成,对应于传统深度学习中的训练和测试样本(Sun等,2019)。
由于较好的灵活性和准确性,目前基于度量的元学习模型(Yang等,2020)广泛应用于小样本图像分类任务。RS-MetaNet(remote sensing meta network)(Li等,2020)首先将基于度量的元学习引入到小样本遥感场景图像分类领域,在一定程度上缓解了样本不足问题。针对遥感场景图像分类任务中类内距离大的问题,RS-MetaNet提出的平衡损失使模型学习到了更好的线性分割平面。Relation Net(Sung等,2018)同样是一种基于度量的元学习模型,该模型使用深度非线性距离来度量元学习任务中待分类样本与类别中心的距离。然而,由于无法理解特征之间的空间关系,现有方法的泛化能力依然不足。本文认为造成这种泛化能力不足的原因主要是遥感图像中一些类别的类间距离小,类内距离大。虽然RS-MetaNet通过增加一个交叉熵损失来增加遥感图像类间距离,但忽略了类内样本关系的学习,在新类别上的泛化能力依然不足。
为解决以上问题,本文提出一种基于自监督学习的小样本遥感图像场景分类方法。该方法在小样本度量学习的基础上,通过引入自监督蒸馏学习和自监督对比学习来解决原有模型泛化能力不足的问题。自监督蒸馏学习利用老师网络的软标签作为学生网络的监督信息,为遥感图像分类提供更加丰富的类内类间关系信息。自监督对比学习通过度量样本在一个表示空间的相似性,为小样本学习提供对比关系信息,使模型具有更强的泛化能力。
本文的创新点包括3个方面:1)提出双学生蒸馏学习机制,将单一的硬标签替换成软标签信息,使模型能够学习到更丰富的类内类间关系;2)改进自监督对比学习过程,通过度量两个学生模型的类中心距离构建对比损失,使模型学习到一个更加明确的类间分界,从而提高模型的泛化能力;3)在NWPU-RESISC45(North Western Polytechnical University—remote sensing image scene classification)、AID(aerial image dataset)和UCMerced LandUse(UC merced land use dataset)3个数据集上进行实验。结果表明,本文方法可以使模型学习到丰富的类内类间关系,有效提升了小样本遥感场景图像分类模型的泛化能力。
1 问题定义
传统的遥感图像分类模型将数据集划分为训练集和测试集两个子数据集(He等,2015),一般这两个子数据集在类别上相同,在样本上没有交集。传统的模型会对训练集上的数据进行深度拟合,通过损失梯度逐步适应当前数据的特征分布。然而这限制了模型对新任务的拓展性,使模型失去对未知类别的鉴别能力。在实际应用中,待分类的目标也不一定属于训练集,所以传统的训练方法不适应小样本遥感图像分类任务。
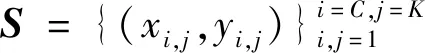
2 本文方法
虽然元学习在一定程度上摆脱了对大数据的依赖,但是模型的泛化能力依然不强。原因主要是遥感图像中一些类别的类间距离小、类内距离大。本文提出使用自监督蒸馏学习来解决这个问题,即利用老师网络的软标签作为学生网络的监督信息,这样可以进一步体现类间关系,有效减小类间距离不均衡对模型的影响。另外,为了进一步增加模型的泛化能力,本文引入自监督对比信息,使模型学习到一个更加明确的类间分界。
本文提出的小样本遥感图像分类模型主要包括数据预处理、特征提取和损失函数3个模块。如图1所示,该图为3-way 1-shot任务的示意图,模型由一个老师网络和两个学生网络组成。在数据预处理阶段,模型会依照元学习模式的样本抽取规则,分别构成元支撑集和元查询集。
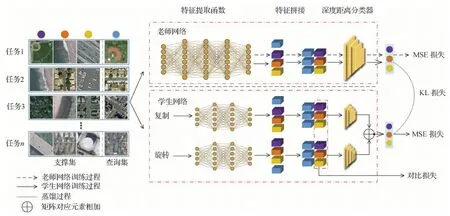
图1 3-way 1-shot时本文方法网络结构Fig.1 Our framework for 3-way 1-shot task
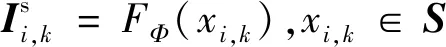
学生网络将支撑集S翻转构建一个新的支撑集S′,而后分别送入两个学生网络。特征提取函数是两个共享参数的Conv-64网络(Snell等,2017;Sung等,2018),分别为fφ1和fφ2,每个Conv-64网络由4个卷积块和2个最大化池化层构成。两个学生网络的预测输出会集成为一个结果用于计算损失。在损失函数方面,除了MSE (mean square error)损失,增加了用于自监督蒸馏学习的KL(Kullback-Leibler)损失和自监督对比损失。老师网络可以通过KL损失指导学生学习到更好的参数。自监督对比损失作用于类中心,可以指导模型判断生成的类别中心是否符合分类的要求,即类内距离要小、类间距离要大。
2.1 老师网络训练

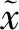
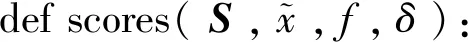
初始化:组合特征z、相似性分数RelationScores
1)计算样本特征;
(1)支撑集特征Is;
(2)查询样本特征Iq;
2)计算支撑集的每个类别中心P并与查询样本特征拼接;
foriin range(1,N):

zi=Concatenate(Pi,Iq)#拼接;
End for;
3)RelationScores=δ(z)#计算相似性分数;
4)returnRelationScores#返回相似性分数。
(1)
(2)
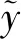
2.2 双学生网络训练
在第2阶段训练中,模型对双学生网络进行训练。双学生训练产生3个损失函数,分别是小样本度量学习的MSE损失、自监督蒸馏学习的KL损失以及自监督对比损失。
2.2.1 小样本度量学习
小样本度量学习的损失使用硬标签指导学生网络训练,主要目的是指导原有元学习的训练,模型通过计算相似性分数的损失值来更新模型的参数。
小样本度量学习的训练过程与老师网络学习过程相似。本文模型包括两个学生网络,其特征提取函数分别为fφ1和fφ2,分类器分别为δs1和δs2。两个学生网络输入的查询样本相同,但支撑集不相同,分别为S和S′。
(3)
(4)
式中,Ys1∈RC和Ys2∈RC代表两个学生网络各自计算出的相似性分数。
与老师网络计算损失不同,两个学生网络的输出结果使用平均加权的方法融合为一个相似性分数,即
Ys=(Ys1+Ys2)/2
(5)
式中,Ys∈RC代表融合后的相似性分数。与老师网络相同,融合后的相似性分数用于计算梯度损失更新fφ1、fφ2、δs1和δs2的参数,即
(6)
2.2.2 自监督蒸馏学习
蒸馏学习的最后一步是利用KL损失指导双学生网络的学习。KL损失是计算老师网络和双学生网络输出的相对熵。具体为
(7)
式中,τ1代表蒸馏学习的温度系数。
KL散度可以度量两个网络预测概率分布的相似程度。具体地,老师网络预测的概率分布Yt可以看做一个置信度很高的基准,学生网络预测的概率分布Ys的目标是逼近老师网络预测的概率分布Yt。当两者预测分布接近时,蒸馏学习的KL损失值会变小,模型也逐渐收敛。
2.2.3 自监督对比学习
自监督对比学习(Hendrycks等,2019)通过度量两个类中心的距离来计算对比损失,从而增加模型的泛化能力。两个学生产生的类中心标签两两对应,在计算对比损失时,来自相同类别的类别中心互为正例样本,否则互为负例样本。
(8)
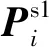
(9)
式中,τ2为对比损失温度系数。
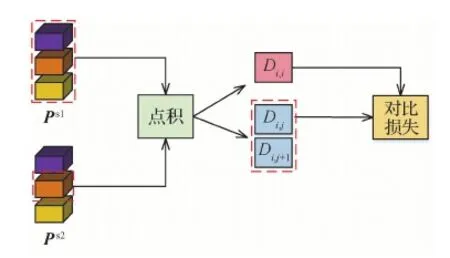
图2 对比损失示意图Fig.2 Structure of contrastive loss
对比损失的基本思想是利用来自两个学生网络的类别中心进行相似性比较。从对比损失的表达式来看,正例数据之间的相似性分数越接近,损失值越低。
本文将小样本度量损失、自监督蒸馏损失和自监督对比损失统一成最终的损失L,通过最小化L使不同损失产生的梯度共同作用于梯度更新过程。模型最终的优化目标为
L=Ls+LKL+β×Lct
(10)
式中,β是超参数。
3 实 验
3.1 数据集与实验设置
实验在遥感场景图像分类常用的3个数据集UCMerced LandUse(Yang和Newsam,2010)、AID(Xia等,2017)和NWPU-RESISC45(Cheng等,2017)上进行,评价指标为分类精度。所有分类精度都在相同实验设定下使用3折交叉验证方法测试600次取平均得到,对比的任务为5-way 1-shot任务和5-way 5-shot任务。
UCMerced LandUse数据集是一个较小规模的遥感图像分类标准数据集,包含21个不同的类别,每个类别有100幅航拍图像。这些样本由美国地质勘查局从美国21个地区采集得到,样本尺寸固定为256 × 256像素,空间分辨率为0.3 m。
AID数据集由武汉大学发布,包含30个场景类别,每个类别的样本有220~240个不等。由于AID数据集来自谷歌地球,因此该数据集拥有多分辨率的特性,空间分辨率为8~0.5 m不等,样本尺寸固定为600 × 600像素。
NWPU-RESISC45数据集由西北工业大学发布,是目前最大的遥感场景分类数据集,包含45个场景类别,每个类别有700个样本。这些样本从谷歌地球采集而来,样本尺寸固定为256 × 256像素,空间分辨率为30~0.2 m。
实验时,为了固定骨干网络,将所有样本在数据预处理阶段压缩为84 × 84像素,并经过数据标准化操作,查询集Q的大小设置为8。本文采用ResNet-50为教师网络,4层CNN网络为学生网络,所有网络使用Adam优化器训练50 000次。初始学习率设置为0.001,并在训练次数达到一半时减半。温度系数τ1和τ2分别设置为5和0.2,超参数β设置为0.5。
3.2 实验结果对比与分析
为了验证本文方法的有效性,在3个标准遥感场景图像分类数据集上与MAML(model-agnostic meta-learning)(Finn等,2017)、Prototypical Net(Snell等,2017)、RS-MetaNet(Li等,2020)和Relation Net*(Sung等,2018)等模型进行对比分析。实验结果如表1所示。可以看出,本文方法的分类精度在3个数据集上都有一定提高,并超越了其他方法。其中,基于迁移学习的传统遥感场景分类在5-way 1-shot任务上的精度普遍都低于30%,在5-way 5-shot任务上的精度依然很低。这说明传统方法对未知类别的泛化能力较差。本文方法在相同条件下,在NWPU-RESISC45、AID和UCMerced LandUse数据集上的分类精度分别达到了72.72%±0.15%、68.62%±0.76%和68.21%±0.65%,比Relation Net*分别提高了4.43%、1.93%和0.68%。随着可用标签的增加,本文方法的提升作用依然能够保持,在5-way 5-shot条件下,本文方法的分类精度比Relation Net*分别提高了3.89%、2.99%和1.25%。实验结果表明,本文方法能够进一步消除类间噪声,增加类间距离,从而提高模型的鲁棒性。
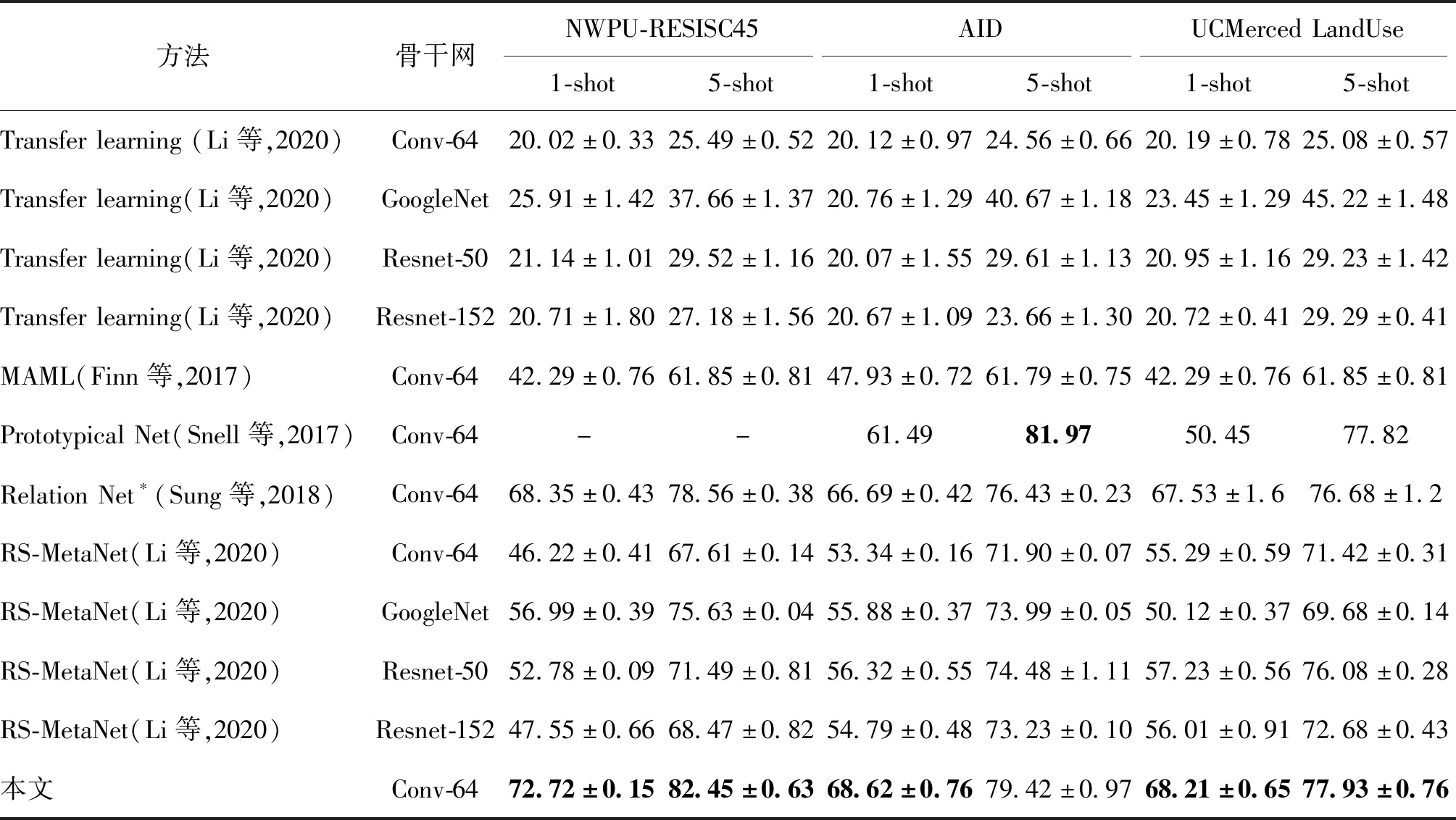
表1 各种小样本方法在3个数据集上分类精度对比Table 1 Comparison of classification precision of different few-shot learning methods on three datasets
图3和图4分别为本文方法和Relation Net*在AID和UCMerced LandUse数据集的混淆矩阵。混淆矩阵是评价机器学习分类性能的一个指标,矩阵的行列分别表示真实样本和预测样本的标签。混淆矩阵能够体现模型分类结果的概率分布。
如图3所示,由于类别“稀疏的住宅”与类别“公园”有一些相似性,因此模型分类上就会有一定的偏差。Relation Net*将类别“公园”分类到类别“稀疏的住宅”的错误率为12%,反之则为13%。而本文方法的错误率为7%和9%,分别下降了5%和4%。在UCMerced LandUse数据集上也有相同的结果,如图4所示。这说明本文方法能够使模型学习到类与类的边界信息,拉大类与类之间的距离。
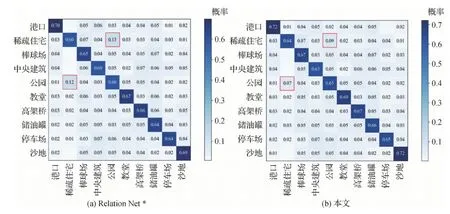
图3 本文方法和Relation Net*在AID数据集的混淆矩阵Fig.3 Confusion matrices of Relation Net* and ours on the AID dataset((a)Relation Net*;(b)ours)
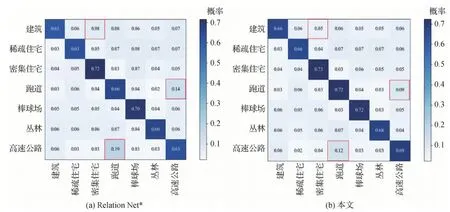
图4 本文方法和Relation Net*在UCMerced LandUse数据集的混淆矩阵Fig.4 Confusion matrices of Relation Net* and ours on the UCMerced LandUse dataset((a)Relation Net*;(b)ours)
3.3 消融实验
为了验证本文提出的蒸馏学习和对比损失两个模块对模型的影响,在3个数据集上执行5-way 1-shot任务进行消融实验。
对比实验一共5组,如表2所示。使用Relation Net*作为Baseline;“Baseline+双学生”代表只使用两个学生网络训练;“Baseline+双学生+蒸馏学习”代表使用两个学生网络并进行蒸馏学习;“Baseline+双学生+对比损失”代表使用两个学生网络并使用对比损失;本文方法使用两个学生网络进行蒸馏学习和对比损失。
从表2可以看出,在3个数据集上,本文提出的两个模块都有正向的结果。例如,在NWPU-RESISC45数据集上,Baseline的精度为68.35%±0.43%,引入双学生网络后精度提升幅度较小,但同时引入双学生网络和知识蒸馏,性能提升了1.52%,同时引入双学生网络和对比损失,性能提升了2.36%。本文方法同时采用双学生网络、蒸馏学习和对比损失,相对于Baseline性能提升了4.43%。另外,在AID和UCMerced LandUse两个数据集上,相比于Baseline,本文方法的各个模块均能带来性能提升。消融实验表明,本文提出的两个模块能够有效提升模型的性能。虽然两个自监督机制在UCMerced LandUse只有0.14%和0.33%的提升,但是本文方法可以将结果的方差从1.6%降到0.65%,这也说明本文模型更加鲁棒。
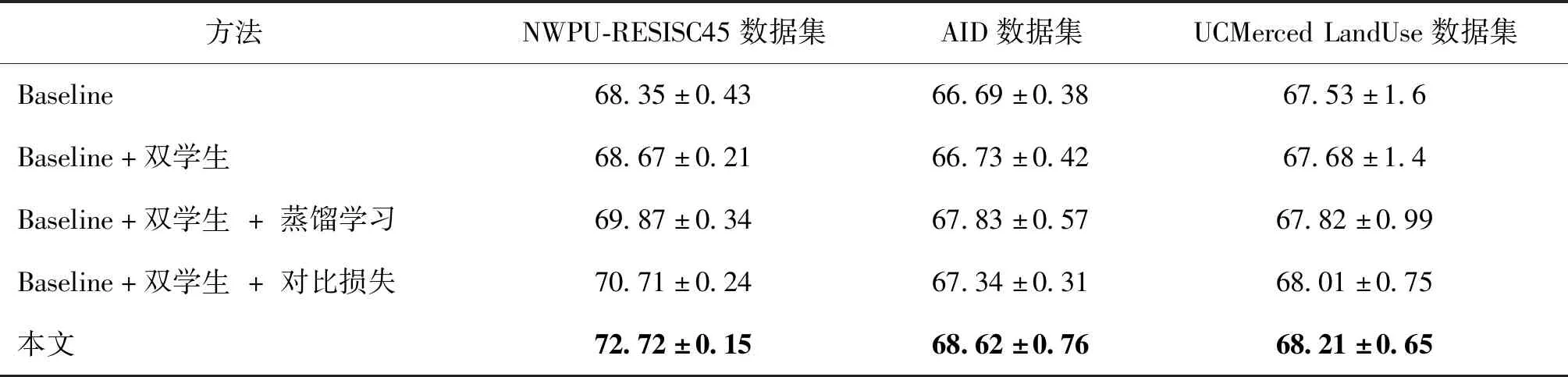
表2 消融实验Table 2 Ablation experiments /%
3.4 参数分析
分析蒸馏损失的温度系数τ1、对比损失的温度系数τ2以及超参数β对实验结果的影响。
在去掉对比损失模块的条件下,验证不同温度系数τ1对模型的影响,结果如图5所示。当温度系数τ1= 1时,模型使用老师网络的预测标签的真值来指导学生网络的学习。但是利用真值指导学生网络学习会导致蒸馏损失的作用降低。当τ1>1时,不同的预测概率会被压缩到一个更小的区间,使蒸馏损失的作用上升。当τ1= 5时,模型的精度最高。

图5 温度系数τ1的分析Fig.5 Temperature hyper-parameterτ1analysis
与蒸馏损失的温度系数τ1不同,MOCO v2(momentum contrast v2)(Chen等,2020)指出温度系数τ2通过归一化至0~1之间可到达更好的效果。因此,在测试温度系数τ2时,只使用对比损失模块,在0~1区间测试不同τ2取值对本文结果的影响,结果如图6所示。可以看出,当τ2= 0.2时,模型的精度最高。
超参数β用于控制对比损失在总损失的比重,它的取值在0.1~1之间,分别表示不同的比重。不同超参数β对应的精度如图6,当β= 0.5时,模型的精度最高。
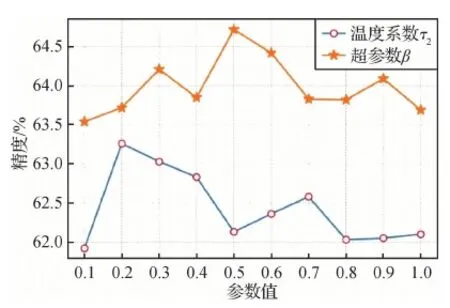
图6 温度系数τ2和超参数β的分析Fig.6 Temperatureτ2and hyper-parameterβanalysis
4 结 论
本文提出在自监督学习下使用双学生蒸馏学习机制和自监督对比学习机制进一步提升小样本遥感场景图像分类问题。双学生蒸馏学习机制将单一的硬标签替换成软标签信息,使模型能够学习到更丰富的类内类间关系。自监督对比学习机制通过度量两个学生模型的类中心距离构建对比损失,使得模型学习到一个更加明确的类间分界,提高了模型的泛化能力。本文做了大量实验来说明两个自监督机制的有效性。首先,对比实验表明自监督机制在5-way 1-shot任务和5-way 5-shot任务都能够取得较好的效果。其次,混淆矩阵的结果表明本文方法可以有效提升相似类别的识别正确率。最后,通过消融实验表明两种自监督机制对模型的提升作用明显。
目前,小样本遥感场景图像分类研究处在起步阶段,专门研究这类任务的工作还很有限。本文工作只是初步探索了自监督蒸馏和对比学习在该领域的可行性,下一步考虑将自监督迁移学习任务与小样本遥感场景图像分类进一步有效结合。
