面向水下图像目标检测的退化特征增强算法
2022-11-18钱晓琪刘伟峰张敬曹洋
钱晓琪,刘伟峰,张敬,曹洋
1. 杭州电子科技大学自动化学院,杭州 310018; 2.陕西科技大学电气与控制工程学院,西安 710021;3. 悉尼大学计算机科学学院,悉尼 2006,澳大利亚; 4.中国科学技术大学信息科学技术学院自动化系,合肥 230026
0 引 言
海洋资源的开发和利用对人类可持续发展具有重要意义。为了更好地完成水下目标捕获和水下搜索等工作,往往需要水下机器人等自动化设备的协助。对于水下机器人而言,高效准确的目标识别能力是完成水下工作的关键。因此,水下目标检测技术具有重要的研究意义。基于深度学习的目标检测算法已经在Pascal VOC(pattern analysis, statistical modeling and computational learning visual object classes)(Everingham等,2010)和MS COCO(Microsoft common object in context)(Lin等,2014)等通用数据集上证明了其出色的性能,但在处理水下目标检测问题时精度往往严重下降。这是因为,一方面,水下检测数据集稀少,可用的水下数据集以及数据集中的目标对象类别很少,使这些基于深度学习的检测算法在少量数据上无法发挥优势(Jian等,2018);另一方面,由于复杂的水下环境和光照条件,水下图像通常具有低对比度、纹理失真和模糊等特点(Jian等,2021),影响了检测算法在水下环境的性能。
因为水下图像的采集非常困难,并且对采集的图像进行标注需要经验丰富的专门人员完成,所以构建水下数据集的成本高昂。而标记好的大型水下物体检测数据集极为有限,又容易导致深度神经网络模型发生过度拟合问题,影响检测精度。实践中,解决通用目标检测算法在水下场景中精度严重下降的一种可行方法是数据增强。数据增强旨在解决数据不足问题,主要包括两类技术。一是基于几何变换的方法,例如水平翻转、旋转、区域裁剪(Liu等,2016)和透视模拟(Huang等,2019)等。这类方法已经被证明在各个不同视觉任务上都是有效的。二是基于剪切粘贴的方法,例如随机剪切和粘贴(Dwibedi等,2017)、Mixup(Zhang等,2018)、CutMix(Yun等,2019)、PSIS(progressive and selective instance-switching)(Wang等,2019a)等。这类方法可帮助建模学习上下文不变性。尽管如此,它们对深度神经网络模型在小规模水下图像数据集上的性能提升仍然有限。另一种可行的方法是将水下图像恢复(增强)为清晰图像,提升可见度和对比度,并减小色偏。一般而言,水下图像恢复(增强)方法可以归纳为3类,即无模型方法、基于成像模型的方法和基于深度神经网络的方法(郭继昌 等,2017;Wang等,2017)。无模型方法不需要建模水下图像的形成过程,一般通过调整给定图像的像素值提高图像整体质量,例如对比度调整(Gibson,2015;李健 等,2021)、直方图均衡(Pizer等,1990)和图像融合(Ancuti等,2012)等。基于成像模型的方法首先建模水下图像的成像模型,然后将水下图像增强视做其逆问题,通过给定的水下图像估计模型中的参数求解逆问题。例如,Zhang等人(2014)考虑到光照在水下衰减这一因素提出新的水下成像模型;Peng和Cosman(2017)提出一种基于图像模糊和光吸收的水下场景深度估计方法;Carlevaris-Bianca等人(2010)提出利用RGB颜色空间中3个颜色通道之间的衰减差异预测水下场景传输图等方法。在基于学习的算法中,卷积神经网络能够以端到端的方式学习从水下图像到相应的清晰图像的直接映射(Li等,2020;Hou等,2018;Guo等,2020)。但由于缺少包含真实水下图像和其对应清晰图像的数据集,这类算法一般都是在合成数据集上训练,因此其在真实水下图像上的增强效果很大程度上取决于合成图像的质量。
现有的基于深度学习的目标检测方法通常假设训练数据和测试数据都来自相同的分布,但在实际应用中很难满足这一条件,这也导致了预训练模型在实际场景中精度下降。解决这个问题的有效方法是领域自适应,通过对抗性学习或核化训练将来自不同分布的源数据和目标数据进行匹配。这类方法通常假设深度神经网络可以在学习的特征空间中对齐源数据和目标数据的边缘分布。因此,在减少学习特征空间中边缘分布之间的差异后,使用源域图像训练的检测器会在目标域图像上保持良好的检测精度。例如Cai等人(2019)提出了适用于跨域检测的mean teacher范式,并提出具有对象关系的mean teacher解决从合成图像到真实图像的跨域检测问题。He和Zhang(2019)提出一种包含分层域特征对齐和聚合提议特征对齐的多对抗Faster R-CNN(faster region-convolutional neural network)解决不受限的目标检测问题。Zhang等人(2019)提出一种类别锚引导的无监督领域自适应模型用于语义分割。同样地,可以将水下目标检测问题转化为领域自适应问题,减小清晰图像(源域)和水下图像(目标域)在特征空间中的分布差异,以提高预训练的检测模型在水下场景的检测精度。但是,源域和目标域的物体类别不一致导致上述假设难以满足,使得直接采用域自适应的方法并不可行。
Wang等人(2020)发现低质图像和其对应的高质图像的特征表示之间存在特定关系,提出一种基于卷积神经网络的特征去漂移模块(feature de-drifting module, FDM)来学习两种特征之间的映射关系,并以此作为先验知识来提高分类器对低质图像的分类精度。受此启发,本文提出一种针对水下图像的特征增强模块FDM-Unet,将低层网络提取的水下图像特征恢复为对应清晰图像的特征,从而使得基于清晰图像训练的检测网络可以直接应用于水下图像目标检测。具体来说,首先提出一种基于成像模型的水下图像合成方法,将清晰图像合成为具有真实感的水下图像。然后在清晰图像和其对应的合成水下图像对上,采用清晰图像上预训练的检测器提取它们的浅层特征,并将水下图像对应的退化特征输入FDM-Unet进行增强,对增强后的特征与清晰图像对应的浅层特征计算均方误差损失,监督FDM-Unet进行训练。最后将训练好的FDM-Unet直接插入上述预训练的检测器的浅层位置,不需要对网络进行重新训练或微调,即可以直接处理水下图像目标检测。实验结果表明,FDM-Unet在PASCAL VOC 2007合成水下图像测试集上,针对YOLO v3(you only look once v3)(Redmon和Farhadi,2018)和SSD(single shot multibox detector)(Liu等,2016)预训练检测器,检测精度mAP(mean average precision)分别提高了8.58%和7.71%;在真实水下数据集URPC19(underwater robot professional contest 19)上,使用不同比例的数据进行微调,相比YOLO v3和SSD,mAP分别提高了4.4%~10.6%和3.9%~10.7%。
本文主要有两方面贡献:1)提出一种基于水下成像模型的图像合成方法,可以从清晰图像合成具有真实感的水下图像用于模型训练;2)提出一种针对水下场景的轻量高效的特征增强网络FDM-Unet,可以即插即用,提升清晰图像上的预训练检测器在水下图像上的目标检测精度。
1 相关工作
随着深度学习的快速发展,基于深度卷积神经网络的通用目标检测取得了显著进展。这些目标检测算法主要分为两大类。1)单阶段算法,如YOLO、SSD和RetinaNet(Lin等,2017),这类算法通常将图像中所有位置都视为潜在对象,然后将每个感兴趣区域分类为背景或目标对象;2)两阶段算法,如R-CNN(Girshick等,2014)、R-FCN(region-based fully convolutional network)(Dai等,2016b),这类算法在第1阶段生成一组候选区域,然后在第2阶段对候选区域提取特征用于目标类别预测和定位。一般而言,两阶段检测算法的精度更高,但是它们的推理速度相较单阶段算法更慢。由于其出色的性能表现,上述方法也成为了水下目标检测(Li等,2015;Islam等,2019;Chen等,2020a;Jian等,2018)的主要检测框架。但是水下图像通常具有低对比度、色偏和模糊等问题,且水下物体容易重叠造成遮挡,导致直接采用上述方法用于水下图像的检测效果并不理想。为了处理这些问题,Lyu等人(2019)提出一种弱监督对象检测方法,通过先弱拟合前景—背景分割网络,然后改进候选区域的策略来提高准确性。Lin等人(2020)对Faster R-CNN进行改进,提出一种增强策略Roimix来模拟训练阶段的重叠和遮挡对象,使模型具有更强的泛化能力,提高了遮挡场景下的精度。Chen等人(2020b)设计一种充分利用多重混合特征的网络结构来提高对小目标的检测精度。
图像降质会导致图像特征分布的高阶统计量发生移位,从而导致预训练的分类模型在降质图像上的分类精度严重下降(Sun等,2018)。一方面,图像增强算法可以将降质的图像恢复到清晰的版本,这对高层视觉任务(例如分类、检测等)有所帮助。例如,Li等人(2017)利用去雾网络提升雾天环境下的目标检测性能。Dai等人(2016)评估了超分辨率对高层视觉任务的影响。Liu等人(2018)采用去噪算法提升图像分割的性能。然而,这些图像增强算法并不能保证总是对后续的高层视觉任务带来提升效果,尤其在图像降质严重的情况下。另一方面,使用降质图像微调网络也是一种常用的提高检测精度的方法。然而,基于微调的方法需要语义标签来监督网络训练,当语义标签无法用于降质图像时,基于微调的方法将不适用。无监督领域自适应目标检测(Shen等,2019;Arruda等,2019;Inoue等,2018;Yu等,2021)使用源域(通用数据集)的标签丰富数据和目标域(降质图像)的无标签或少标签数据来训练性能良好的检测模型。尽管已经提出了各种域自适应目标检测方法(Chen等,2018;Wang等,2019b;Zhu等,2019),但表现出的性能与在标注良好的数据上训练的检测模型之间仍然存在差距。
不同于上述方法,Wang等人(2020)提出一个轻量级的插件式特征去漂移模块,可以增强低层网络提取的降质图像特征,显著提高了使用ImageNet预训练的分类网络在多种降质条件下的图像分类精度。受此启发,本文提出一种适合水下降质图像的轻量、高效的特征增强模块FDM-Unet。通过使用清晰图像和对应的合成水下图像来训练FDM-Unet,然后将其插入到预训练的检测模型中,从而提升其水下目标检测的精度。
2 本文方法
2.1 基于成像模型的水下图像合成方法
2.1.1 水下成像模型
根据大气散射模型(Zhang和Tao,2020)的描述,在散射介质中拍摄的图像由于吸收和散射的影响,只有一部分来自场景的反射光到达成像传感器。类似地,光线在水下传播过程中也受到介质吸收和散射的影响,所以有研究人员提出采用大气散射模型来描述水下图像的退化过程。具体地,大气散射模型为
(1)
ti=e-βdi
(2)

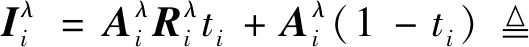
(3)
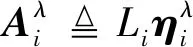
2.1.2 估计光照颜色
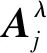

(4)
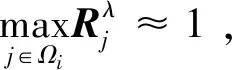
(5)
光照颜色可以估计为
(6)
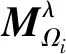

图1 真实水下图像光照颜色估计样例Fig.1 Examples of real underwater image illumination color estimation((a) real underwater images; (b) illumination color maps estimated from the underwater images in (a))
2.1.3 估计光照强度
式(3)两边同时除以光照颜色ηλ,可得
(7)
按照上文对各参数在局部区域Ωi中的假设以及最大反射率先验,式(7)可进一步推导为
(8)
式(8)得到的局部光照强度是一个向量,进一步计算其每个通道的局部光照强度,然后选择最大值作为最终估计值,具体表达式为
(9)
部分真实水下图像光照强度估计样例如图2所示。
2.1.4 估计深度图
按照式(2),对透射率ti的估计可以转化为对深度di的估计,本文使用Li等人(2018b)提出的方法获取di。图像深度估计样例如图3所示。

图2 真实水下图像光照强度估计样例Fig.2 Examples of real underwater image illumination intensity estimation((a) real underwater images; (b) illumination intensity maps estimated from the underwater images in (a))

图3 图像的深度图估计样例Fig.3 Examples of depth map estimation((a) original images;(b) the scene depth maps estimated from the images in (a))
2.1.5 水下图像合成
水下图像合成时使用的光照强度和颜色从真实水下图像中获取。合成步骤如下:
1)将真实水下数据集中的每一幅图像下采样到64×64像素的固定大小。
2)选择5×5的滑窗。
3)对每一个滑窗区域内的图像,分别按式(6)和式(9)估计光照颜色ηλ和光照强度L,然后计算光照向量Aλ=Lηλ。
4)得到N×K个光照向量A的集合A*,其中N是真实水下数据集的图像数量,K是每幅图像的滑窗数。
5)对每一幅待合成图像J,使用2.1.4节的方法得到深度图d,然后从A*随机采样一个A,按照式(1)和式(2)得到合成图像I。
2.2 水下目标检测
2.2.1 基本思路
Wang等人(2020)指出,虽然降质图像的特征分布相较清晰图像的特征分布会发生移位,但是卷积神经网络浅层部分提取的退化图像特征和其对应的清晰图像特征之间有着均匀的边距,并且结构相似图像的特征是均匀分布的。基于以上发现,本文提出一种基于U-Net结构的插入式特征增强模块FDM-Unet,将浅层网络提取的退化图像的特征恢复到其对应清晰图像的特征,使在清晰图像上预训练得到的深层网络可以对降质图像做出正确响应。如图4所示,将训练得到的FDM-Unet插入到预训练好的通用目标检测算法的主干网络中,使其将预训练的检测器的浅层网络(shallow pretrained layers,SPL)提取的水下图像(underwater image,UI)的退化特征(degraded features,DF)转化为增强特征(enhanced features,EF),从而使后面预训练的深层网络(deep pretrained layers,DPL)输出精确的检测结果。

图4 FDM-Unet部署阶段示意图Fig.4 Diagram of deployment phase of FDM-Unet
2.2.2 FDM-Unet
FDM-Unet的主要目的是将浅层主干网络提取的退化图像特征恢复成其对应清晰图像的特征。考虑到全局信息和局部信息都对特征恢复起着重要作用,本文设计了以编码—解码结构为主体的U-Net形式的网络结构。如图5所示,在编码阶段(卷积层E1、E2、E3、W)通过2次maxpooling和1次空洞(dilation)卷积获得足够大的感受野以获取丰富的全局信息,在解码阶段(卷积层D1、D2、D3),将具有全局信息的特征与低层特征多次融合来获取局部信息。此外,借鉴残差学习的思想,在输入的退化特征和网络输出的增强特征之间增加残差连接,从而降低训练难度。相较于直接学习增强特征而言,学习退化特征的残差更为容易。

图5 FDM-Unet网络结构Fig.5 The network structure of FDM-Unet
FDM-Unet主要由5部分构成:1)输入卷积层BB,将输入的退化特征x转化为中间特征F(x)。这层的主要作用是提取局部特征。2)U-Net形式的编码—解码结构(图5虚线框)经过提取、编码后得到融合多尺度上下文特征的U(F(x))。3)使用残差连接将局部特征和多尺度特征融合得到F(x)+U(F(x))。4)卷积层CC对3)中的融合特征进一步变换,得到B(F(x)+U(F(x)))。4)使用残差连接将退化特征和精修特征融合,得到增强特征x+B(F(x)+U(F(x)))。
FDM-Unet的详细参数如表1所示。其中,H和W是输入退化特征的高和宽,C是其通道数。
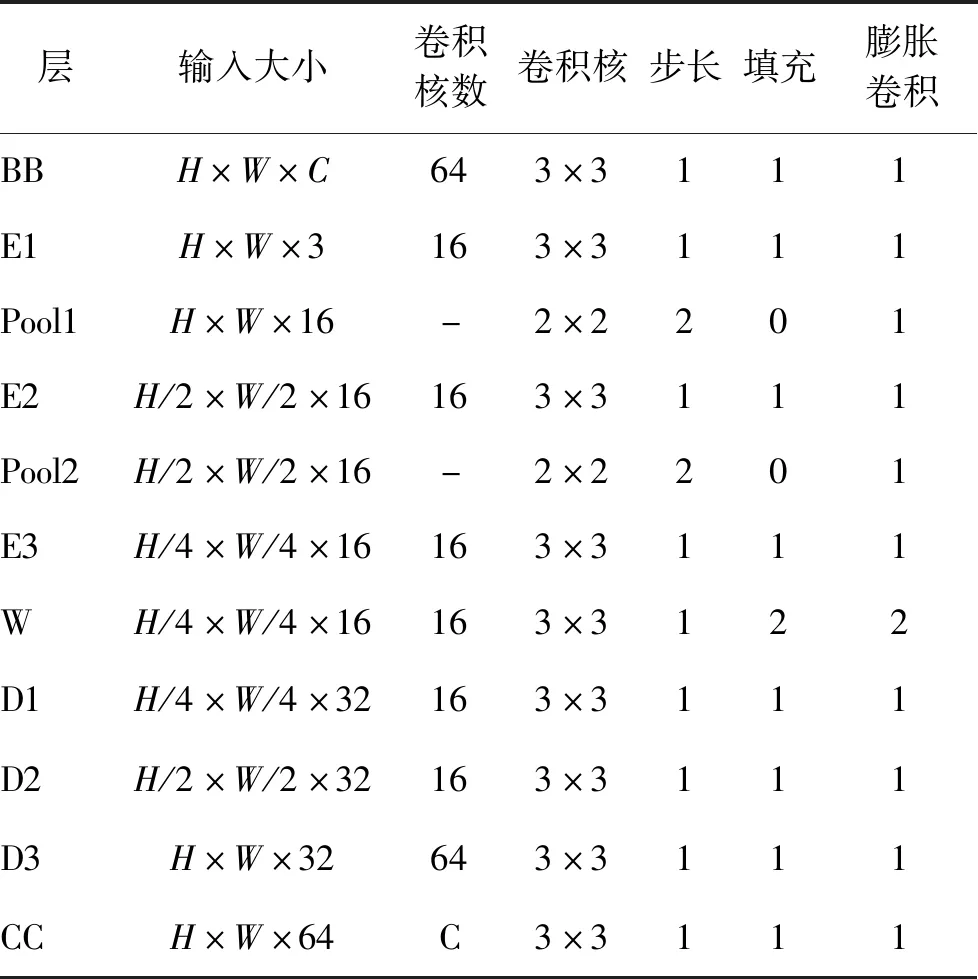
表1 FDM-Unet结构参数表Table 1 The details of FDM-Uet
2.2.3 FDM-Unet训练和测试
如图6所示,使用预训练的通用目标检测网络的浅层部分(SPL)分别提取水下图像和其对应的清晰图像的特征,得到退化特征(DF)和清晰特征(clear features,CF)。然后将DF输入到FDM-Unet中得到增强特征(EF)。将得到的增强特征(EF)与其配对的清晰特征(CF)进行比较,计算MSE(mean-square error)损失,并将误差反向传播到FDM-Unet中,以更新其参数。在FDM-Unet的训练过程中,SPL的参数不进行更新。具体地,训练过程中使用的MSE损失函数定义为
(10)
式中,EF和CF分别为增强特征和清晰特征。
在训练阶段结束之后,将训练好的FDM-Unet插入到预训练好的通用目标检测网络的浅层部分(SPL)与深层部分(DPL)之间,然后在水下图像上直接测试该预训练检测器的目标检测性能,如图4所示。值得注意的是,FDM-Unet训练和测试时使用的检测网络为同一网络。检测网络的浅层(SPL)和深层(DPL)是相对的,一般SPL取检测网络的前几层,剩余网络部分则为DPL。
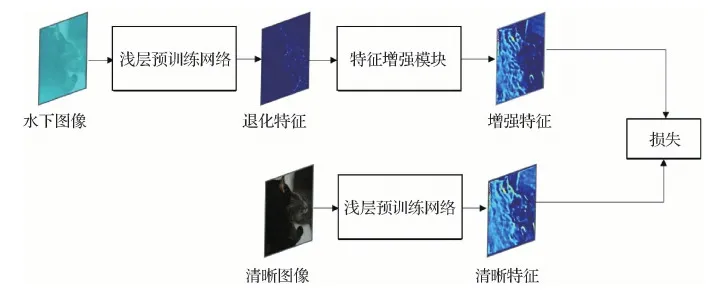
图6 FDM-Unet训练阶段示意图Fig.6 Diagram of training phase of FDM-Unet
3 实 验
3.1 实验环境及参数设置
实验使用的软硬件环境为Ubuntu16.04操作系统,Intel Core i7-8700K CPU@3.70 GHz 12核心,NVIDIA GeForce GTX 1080Ti 11GB显卡。实验程序在PyTorch深度学习框架下,使用Python语言编写。作为两种典型的单阶段目标检测模型,YOLO v3和SSD具有优异的检测性能和检测速度,本文采用它们作为检测框架代表验证提出的FDM-Unet模块的有效性。检测网络的训练参数均采用原文献的设定。训练FDM-Unet时,采用随机梯度下降(stochastic gradient descent, SGD)优化算法,将初始学习率设为0.001,使用multistep调整学习率,迭代次数为3 000,每批次有16幅图像。
3.2 数据集和评价指标
本文实验是在3个原始数据集:UIEB(underwater image enhancement benchmark)(Li等,2020)、URPC19、PASCAL VOC 2007+2012以及一个合成的水下PASCAL VOC 2007+2012数据集上进行。其中合成数据集是基于2.1节提出的合成方法对PASCAL VOC 2007+2012数据集中的图像进行合成得到。UIEB包含890幅真实水下环境中采集的图像,没有任何语义标签。URPC19是一个真实水下目标检测数据集,有4个物体类别,共4 757幅图像。PASCAL VOC 2007目标检测数据集有20类物体,共9 963幅图像,分为训练集、验证集和测试集3部分。PASCAL VOC 2012数据集的物体类别与PASCAL VOC 2007一致,但只对外公开了训练集和验证集,共11 540幅图像。
对水下图像合成实验效果的评价包括两部分。1)通过视觉效果评价合成图像的质量;2)采用原始PASCAL VOC数据集和对应的合成水下数据集对检测模型进行预训练,并对比它们在真实水下图像上微调的检测性能,从而间接反映合成图像的价值。
对检测精度进行评估时,选择平均精度(average precision,AP)和总平均精度(mean average precision,mAP)作为模型评价指标。AP的计算式为
(11)
式中,K是对模型预测结果进行统计后得到的召回(recall)数量,Pinterp(k)是第k个召回率下的最高精度(precision),Δr(k)=r(k)-r(k-1)表示召回率的变动情况。mAP是所有类的AP的平均值,计算AP的置信阈值取0.5。
3.3 实验设计与结果分析
3.3.1 水下图像合成
从真实水下图像数据集UIEB中随机选择500幅图像,按2.1.5节中步骤1)~5)得到光照向量集合A*,图7为真实水下图像估计得到的光照向量A的可视化结果。

图7 真实水下图像估计得到的光照Fig.7 Illuminance estimated from real underwater images

图8 合成图像样例Fig.8 Examples of synthetic image ((a) clear images from the PASCAL VOC 2007+2012 dataset; (b) corresponding synthetic underwater images)
使用Li和Snavely(2018b)的方法得到PASCAL VOC 2007+2012中每一幅图像的深度图。接着,对PASCAL VOC数据集中每一幅待合成图像,从A*中随机选取一个光照向量A,按式(1)和式(2)进行合成,得到水下PASCAL VOC数据集(underwater visual object classes,UW_VOC)。实验中,大气衰减系数β取1.2。如图8所示,本文方法合成的水下图像在视觉效果上偏蓝绿色且对比度下降,比较接近真实水下图像的视觉效果。
3.3.2 合成水下图像上的检测实验
本文贡献之一是提出一种针对水下环境的插入式特征增强模块FDM-Unet来提升通用目标检测算法在水下场景中的检测精度。为了证明FDM-Unet的有效性和通用性,在YOLO v3和SSD两种经典通用目标检测算法上进行测试。
首先按Liu等人(2016)以及Redmon和Farhadi(2018)的参数配置,在PASCAL VOC 2007通用目标检测数据集上训练SSD和YOLO v3。然后按表1的结构参数设置搭建FDM-Unet网络,按表2的训练参数设置训练FDM-Net。训练时,从合成的PASCAL VOC 2012数据集及其对应的原始PASCAL VOC 2012中各随机选取的1 000幅图像作为训练集。如图6所示,在FDM-Unet训练阶段,使用预训练的检测模型的低层部分提取水下图像和对应清晰图像的特征。在实验中,SSD和YOLO v3的低层部分分别为VGG(Visual Geometry Group)主干网络的conv2_2之前的网络层和darknet53的前两层。训练结束后,将得到的FDM-Unet分别插入到SSD和YOLO v3中,然后在合成的水下PASCAL VOC 2007数据集上分别测试其目标检测精度。

表2 FDM-Unet的训练参数设置Table 2 Parameters setting for training FDM-Unet
3.3.3 合成水下图像上的结果分析
为验证FDM-Unet的有效性,进行以下对比实验:1)清晰图像预训练的检测模型在清晰图像和合成水下图像的检测精度。其性能差异可以反映域差异引起的检测模型泛化性能下降程度。2)清晰图像预训练的检测模型采用特征去漂移(FDM)模块之后在合成水下模型的检测精度。通过对比Wang等人(2020)提出的FDM模块和本文FDM-Unet结构,可以验证特征去漂移思想的有效性以及本文模型相比Wang等人(2020)模型的优势。3)采用或不采用特征去漂移模块时,在水下图像训练并测试的结果。对比采用特征去漂移模块的结果和在合成水下图像直接训练和测试的结果,可以验证本文方法不需要在目标域上训练即可达到较好结果。实验结果如表3所示。实验1是在清晰图像预训练,在清晰图像测试。实验2是在清晰图像预训练,在合成水下图像测试。实验3是在清晰图像预训练,使用FDM在合成水下图像测试。实验4是在合成水下图像训练并测试。实验5是使用FDM在合成水下图像训练并测试。
表3从4个方面说明了本文FDM-Unet的效果。以YOLO v3为例,1)直接使用清晰图像预训练的检测模型在水下图像测试,性能出现了显著下降,mAP从清晰图像上的83.85%降低到72.81%,说明该模型面对不同域图像的泛化性较差;2)使用FDM模块(Wang等,2020)后,可提升模型的检测精度,mAP从72.81%提高到76.96%;3)使用本文FDM-Unet后,检测性能进一步提升,mAP提高到80.52%,与源域上的检测性能(83.85% mAP)以及目标域直接训练和测试的性能(80.75% mAP)接近,说明了本文模型相比FDM的优势(提升3.56% mAP),以及在不需要微调和重新训练的情况下,能显著提升清晰图像预训练模型的泛化性能;4)采用FDM或FDM-Unet在目标域训练并测试结果,相比YOLO v3基线模型也有提升,证明该模块在目标域训练情况下能提升模型的特征表示能力。
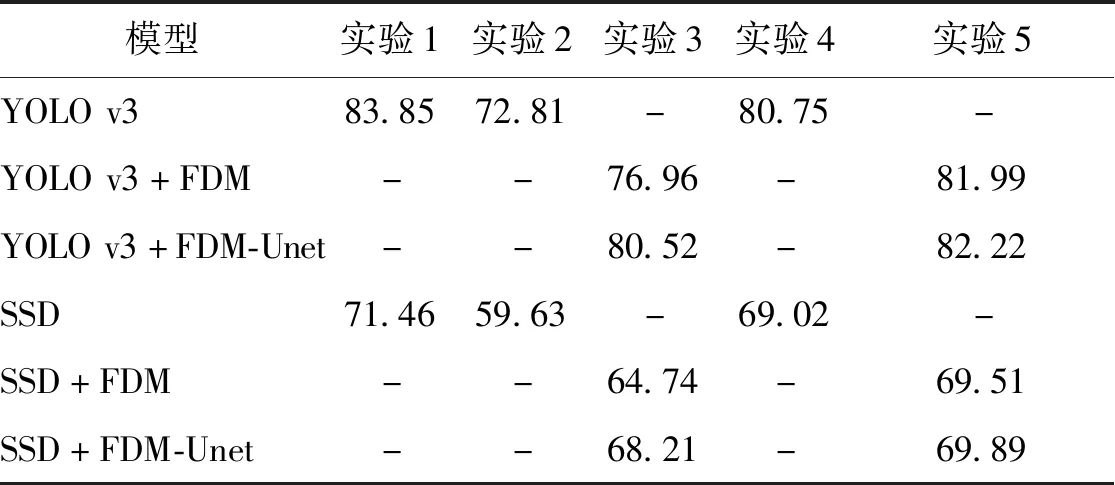
表3 PASCAL VOC合成图像检测实验结果(mAP)Table 3 Detection results(mAP) on synthetic images of PASCAL VOC dataset /%
图9是部分测试结果,图9(a)(b)分别为YOLO v3和SSD的样例测试结果,从左到右依次为清晰图像标签、清晰图像预训练模型测试结果、清晰图像预训练模型在合成图像上测试结果、清晰图像预训练模型使用FDM测试结果以及清晰图像预训练模型使用FDM-Unet测试结果,测试结果进一步验证了上述结论。

图9 合成水下图像检测结果对比Fig.9 Comparison of test results on synthetic images((a) YOLO v3 testing examples; (b) SSD testing examples)
3.3.4 参数量—计算量对比
如表4所示,FDM-Unet的浮点运算量和参数量都小于Wang等人(2020)提出的FDM,增加的参数量和计算量相较于整个检测网络来说可以忽略不计。另外,FDM-Unet对检测精度的提升效果却相当明显,并且可以方便地插入到现有的检测网络中,而不需要重新训练或微调。因此,FDM-Unet具有很强的实际应用价值。

表4 参数量—计算量对比Table 4 Comparison of parameters and FLOPs of FDM, FDM-Unet, YOLO v3 and SSD
3.3.5 真实水下图像的微调实验
为了验证FDM-Unet在真实水下场景中是否依然有效,将清晰图像上预训练的模型在URPC19数据集上使用不同数量的数据进行多组微调实验。微调时,batchsize为16,学习率为0.000 1,迭代30轮。实验结果如表5和表6所示。可以看出,如表5和表6中的第1、3行数据所示,使用FDM-Unet的模型进行微调之后的目标检测精度均高于其对应的基线模型,说明FDM-Unet在真实水下场景的有效性。如表5和表6中的第1、2行数据所示,使用清晰图像预训练和使用合成水下图像预训练的模型在真实水下图像上进行微调,基于合成图像预训练模型进行微调之后的目标检测精度更高,说明基于本文水下图像合成方法得到的水下图像与真实水下图像的域间差异更小,间接验证了本文方法的有效性。图10是部分测试结果,从左到右依次为水下图像标签、清晰图像预训练模型微调后测试结果、合成水下图像预训练模型微调后测试结果和使用FDM-Unet微调测试结果。测试结果与上述结论一致。

表5 YOLO v3真实水下图像微调实验结果(mAP)Table 5 Fine-tuning results(mAP) of YOLO v3 on real underwater images /%

表6 SSD真实水下图像微调实验结果(mAP)Table 6 Fine-tuning results(mAP) of SSD on real underwater images /%

图10 真实水下图像微调检测结果示例Fig.10 Comparison of fine-tuning results on real underwater images((a) YOLO v3 testing examples; (b) SSD testing examples)
4 结 论
本文针对现有基于卷积神经网络的通用目标检测算法在水下场景检测精度下降问题,提出一种基于U-Net结构的特征增强模块FDM-Unet以及一种水下图像合成方法。实验结果表明,FDM-Unet作为即插即用模块,仅增加极小的参数量和计算量,就可以大幅提升预训练模型以及真实水下微调模型的检测性能,并且采用合成水下图像进行预训练可以显著提升模型在真实水下图像上的检测性能。下一步将针对雾天、低光照等降质成像场景验证本文方法的有效性,探索更高效、轻量的特征增强模块。
