多尺度代价体信息共享的多视角立体重建网络
2022-11-18刘万军王俊恺曲海成
刘万军,王俊恺,曲海成
辽宁工程技术大学软件学院,葫芦岛 125105
0 引 言
随着虚拟现实、自动驾驶和现代医学等领域的应用需求增加,3维视觉技术(龙霄潇 等,2021)得以快速发展。本文主要研究的多视角立体(multi-view stereo,MVS)是一种通过已知相机参数的一组从不同视角拍摄的某个场景的图像恢复出图像内场景的3D模型方法。这种方法既可以对小型物体进行重建,也可以对大规模的室外场景(颜深 等,2021)进行重建。
传统的MVS方法通常可以分为4种类型,包括基于点云的算法、基于体素的算法、基于可变多边形网格的算法和基于深度图的算法。虽然这些方法在理想的朗伯场景下取得了很好的效果,但是在纹理匮乏、纹理重复或者光照变化的情况下经常无法得到令人满意的重建结果。此外,这些方法通常需要很长时间建立对应的3维关系,对大型场景的重建更是大幅增加了时间的消耗。
随着深度学习技术在计算机视觉领域的迅速发展,学者对多视角立体重建结构的改善研究展现了极大的兴趣。在基于深度学习的立体匹配问题上,Luo等人(2016)以及bontar和LeCun(2016)将学习到的特征用于立体匹配和半全局匹配中进行后处理。GCNet(geometry and context network)(Kendall等,2017)引入3维代价体正则化进行立体估计并使用soft argmin操作回归最终的视差图。在MVS问题上,借鉴这些方法的思想,Ji等人(2017)提出一种基于体素的方法,将整个空间分解成更小的立方体,并以立方体为单位对曲面进行回归;Kar等人(2017)在网络中应用了可微投影,并提出了第1个用于MVS重建的端到端可学习网络;Huang等人(2018)将任意数量各种姿态的图像作为输入,首先产生一组平面扫描体,并使用DeepMVS网络来预测高质量的深度图。这些方法使用深度卷积神经网络,结合全局语义信息进行重建,在纹理较差的区域完成了较好的重建效果,在提升整体场景的重建质量的同时还大幅缩减了重建时间。
在Yao等人(2018)提出了一种端到端的MVSNet之后,大多数的基于深度学习的MVS方法都是通过构建3D代价体,并用3D卷积神经网络对其进行正则化,最终回归深度图的方式进行。然而,由于3D卷积神经网络通常比较耗时且占用较大内存,便衍生出R-MVSNet(Yao等,2019)、Point-MVSNet(Chen等,2019)、Fast-MVSNet(Yu和Gao,2020)和CascadeMVSNet(Gu等,2020)等一系列网络模型。R-MVSNet采用在深度方向上使用循环神经网络的方法;Point-MVSNet采用直接基于点的匹配代价正则化的方法;Fast-MVSNet采用构造一个稀疏的代价体来学习稀疏的高分辨率深度图的方法;CascadeMVSNet则采用构建级联结构的3D代价体并由粗到细预测高分辨率深度图的方法。这些方法解决了耗时和占用内存较大的问题,实现高效率的重建。总体来说,MVS继承了立体匹配的立体几何理论基础,并借助更多的图像视角,有效地改善了遮挡问题的影响,在精度和泛化性方面都得到了较大的提升。但是,现有方法在特征提取的效果、匹配代价的正则化等方面依旧具有提升与改善的空间,在重建精度方面也有待进一步提高。
针对以上问题,本文提出了一个双U-Net进行特征提取的多尺度代价体共享的多视角立体重建网络模型(multi-scale cost volumes MVSNet, MCV-MVSNet),该模型主要由特征提取、生成代价体、代价体正则化3个部分组成,本文主要工作总结如下:
1)设计了一个改进的双U-Net特征提取模块,使提取到的特征更加精确,同时输出3个不同尺度的特征图,构成由粗到细的级联结构;
2)设计了一个多尺度代价体信息共享模块,在对代价体进行正则化之前,将低尺度代价体信息逐层传递给高尺度的代价体,使后续预测的深度图更加准确。
1 相关工作
1.1 传统的MVS方法
在早期处理MVS的问题上,衍生出4种不同类型的算法。1)基于点云的算法Furu(Furukawa和Ponce,2010)从一组稀疏的匹配特征点开始,将初始匹配向周围像素扩展,不断对特征点进行迭代处理,同时使用可见性约束来消除不正确的匹配,最终将其传播到低纹理区域实现稠密重建。由于这种方法对特征点的提取质量要求很高,在纹理分布不均匀的情况下很难取得较好的效果。2)基于体素的算法(Sinha等,2007)先计算包含场景的边界框,然后将3D空间离散成不规则网格,找出在场景表面附近的体素。这种方法的内存消耗会随着体素分辨率的增加而增加,同时,体素分辨率也限制了重建的精度。3)基于可变多边形网格的算法(Furukawa和Ponce,2009;Li等,2016)需要对场景表面进行初始猜测,对表面演化进行初始化,然后进行迭代操作,提高多视图光度一致性并对场景表面进行演化。4)基于深度图的算法Camp(Campbell等,2008)、Tola(Tola等,2012)、Gipuma(Galliani等,2015)和Colmap(Schönberger等,2016)等都是将整个重建过程分解成若干个单视图深度图估计过程,再将所有的深度图融合在一个坐标系下的点云中。这种方法可以轻易地将深度图融合到点云或体积重建中,是进行3维重建的最优方法。
1.2 基于深度学习的MVS方法
深度学习技术在近年来表现得愈发成熟,基于深度学习的MVS方法也在逐渐展现其巨大的潜力。Ji等人(2017)通过将相机参数与图像以3D体素共同编码表示的方式构建出了一个3D全卷积网络SurfaceNet。它将整个空间分割成更小的彩色立方体,然后使用通用的3D卷积神经网络对小立方体进行正则化并回归到场景表面。虽然这种方法解决了多视立体视觉问题,提高了空间分辨率,但是也导致时间复杂度大大提升。Kar等人(2017)提出了第1个用于低分辨率MVS重建的端到端可学习网络,通过可微分投影的方式将图像的特征构建成特征体,并对每个体素是否被场景表面占据进行分类,最后对每个视角的投影进行解码输出深度图。然而这种方法受到内存的限制,只能对小规模场景进行低分辨率重建。Huang等人(2018)将输入的图像进行预处理,并将其投影到生成的一组3D平面扫描体中,通过DeepMVS网络对3D平面扫描体进行处理,最终生成细化的深度图。整个DeepMVS网络主要分为3个部分,分别是补丁匹配网络、平面扫描体内特征聚合以及平面扫描体间相互特征聚合,最后将估计出的高质量深度图输出。
Yao等人(2018)提出了一种端到端的MVSNet,参照传统平面扫描法的策略,采用可微单应性变换来实现多视角图像特征的映射,用以构建参考图像的匹配代价。同时,为了使得匹配代价不受图像数量的影响,MVSNet采用了基于方差的匹配代价构建方式,通过一个沙漏型的3维卷积层与回归操作最终实现了对参考图像的深度估计,并成功超越了传统算法的性能。但是,受到深度采样数的影响,MVSNet对计算资源的占用较高。为了解决这一问题,Yao等人(2019)提出了一种基于递归神经网络的可扩展多视角立体重建框架R-MVSNet,此方法通过门控循环单元(gated recurrent unit,GRU)在不同深度处对特征图串行地进行正则化处理,避免了一次性对整个3D代价体进行正则化。虽然这种方法大大减少了对内存的占用,但是却会显著增加运行时间。Point-MVSNet(Chen等,2019)提出了直接利用点云表示来对目标场景进行处理,这种方法采用了由粗到细的深度估计策略,通过迭代的方式不断提升深度估计的精度,在深度图的基础上直接生成3维点云。此方法在构建每个3维点的匹配代价之后,通过K邻近搜索为3维点聚合空间邻域信息,并基于多层感知机对每个3维点单独进行匹配代价正则化,自然地保持了表面结构的连续性。因此实现了比基于空间代价矩阵的方法精度更高、计算效率更优的图像深度估计。Fast-MVSNet(Yu和Gao,2020)构造了一个稀疏的代价体,利用小尺度卷积神经网络对局部区域内像素的深度依赖性进行编码,以加密稀疏的高分辨率深度图,最后提出了一种简单而有效的高斯—牛顿层来进一步优化深度图。这种由稀疏到密集的策略保证了方法的效率,能够快速完成端到端的学习过程。CascadeMVSNet(Gu等,2020)将MVSNet的模型改成了层级的,先通过预测下采样四分之一的深度图,然后缩减当前尺度的深度假设范围,继续预测下采样二分之一的深度图,最终预测出原始图像大小的深度图。这种层级的方式,可以采用大的深度间隔和小的深度区间,从而可以一次训练更多数据。此方法中自适应的深度采样确保了内存资源用在更有意义的区域上,可以显著减少计算时间和内存消耗。
综上所述,现有的MVS方法仍然受到内存大小的限制,硬件上GPU内存的加大也为实现更高精度的重建结果提供了可能。因此,在特征提取阶段,可以增加卷积层数,以得到效果更好的特征图;在代价体的级联结构中也可以传递更多的有效信息,使深度图的估计更加准确。
2 本文算法
目前基于深度学习的多视角立体匹配方法的特征提取的效果一般和代价体之间的关联性较差,因此本文在Gu等人(2020)方法的基础上,在特征提取阶段和代价体正则化前期处理阶段进行了改进。整体网络框架如图1所示,与MVSNet类似,将输入的N幅图像分成两组,其中一组只有一幅图像,将其命名为参考图像;另外一组为其余的N-1幅图像,称为源图像。首先将图像进行特征提取,借助U-Net结构,同时分别输出原图像大小1/4、1/2和1倍大小的特征图,构成“由粗到细”的级联结构。然后对特征图进行可微单应性扭曲操作,将源图像的特征图扭曲到参考图像中,构建成多个特征体,再对特征体进行方差的差异度量操作,将多个特征体构建成一个代价体。再将第m(1≤m≤2)层生成的代价体分离,其中一个代价体进行正则化,回归并预测深度图,另一个代价体与第m+1层生成的代价体融合成新的代价体,再继续后续操作,直到预测出与原图像尺度大小相同的深度图。按照特征提取、代价体的构建、代价体正则化和损失函数4个部分详细说明MCV-MVSNet的完整流程。

图1 多尺度代价体信息共享的多视角立体重建网络模型框架图Fig.1 The framework of multi-view stereo network with multi-scale cost volumes information sharing
2.1 特征提取
特征提取是整个多视角立体匹配重建最重要的部分,重建效果取决于特征提取的效果。Yao等人(2018,2019)通过卷积神经网络进行特征提取,而Chen等人(2019)和Gu等人(2020)利用改进U-Net(Ronneberger等,2015)构建特征金字塔进行特征提取,且效果优于前者, 因此,本文设计了一个改进双U-Net特征提取模块,如图2所示,该模块通过两次U-Net网络的处理,进一步对纹理信息丰富的高频区域增加局部感受野,以获得更优的特征信息。

图2 双U-Net特征提取模块结构图Fig.2 Double U-Net feature extraction module structure diagram
U-Net网络模型起初用于医学影像处理中,它采用对称结构构成“U”的形状,前端为特征编码器,通过不断地卷积和池化提取图像的深层特征,但同时得到的特征图大小相较于原来的图像也在不断减小,网络越深,丢失的信息越多。因此,在后端的特征解码器中,对于每一次下采样,都采用一次上采样使之恢复原来的尺寸,而每一个上采样的结果都与前期相应尺寸的特征图进行叠加融合,这样便实现了高层特征与低层特征的结合,增加特征图像的细节信息,能更精确地预测每一个像素的类别。
本文在双U-Net特征提取模块中,对所有的分辨率为512×640像素的输入图像,经过卷积和ReLU后,将3通道的原始图像变为8通道再变为32通道,通过两次最大池化以及不断卷积,分别生成原图像尺寸的1、1/4和1/16倍的特征图。在上采样阶段,将不同尺度的特征信息在通道维度上进行拼接融合,形成更厚的特征,在侧边合并后继续卷积和上采样,得到32通道的与原图像分辨率相同的特征图,再将此作为输入,再经过一次U-Net网络,最终得到3组不同尺寸的特征图,按照特征图由大到小的顺序对应的通道数分别为8、16和32。这样的双U-Net特征提取模块可以保留更加丰富的细节特征,下采样减少池化层的空间维度,上采样修复物体的细节和空间维度,而侧边连接能更好地修复目标的细节,使后续的深度估计结果更加准确完整。
2.2 代价体的构建
代价体的构建使用平面扫描的方法,其原理是对于每个深度,将源图像投影到参考相机平截头体的前向平行平面上,然后再投影到参考图像上来匹配参考图像。大多数的MVS方法均采用平面扫描法来构建代价体,本文也沿用Yao等人(2018)方法。首先对特征图进行可微单应性扭曲变换将其聚合成多个特征体。在深度假设d处,使用d将源图像的所有像素投影到空间中,然后通过参考相机反向扭曲这些点,因此,第i个视角的源图像与参考图像在深度d上的单应性Hi(d)可以表示为
(1)
式中,Ki,Ri和ti分别代表第i个视角源图像相机的内参、旋转和平移,K0,R0和t0分别代表参考图像相机的内参、旋转和平移,n0代表参考相机的主轴,I表示假设平面间隔。通过单应性的变换,再将聚合到的特征体Fi进行基于方差的差异度量操作以构建成代价体C,这种操作方式能够适应任意数量N的输入特征体,可以表示为
(2)

2.3 代价体正则化
由于初步构建的代价体可能会因为存在非朗伯表面或物体遮挡而造成噪声污染,因此应该结合平滑度约束推断深度图,即代价体正则化操作,将生成的代价体经过一个类似3D U-Net的正则化网络生成进行深度图推断的概率体。Yang等人(2019)在立体匹配问题上提出了一种分层的特征体解码器,输入的特征体经过3维卷积和金字塔池化将其分为输出特征体和输出代价体,这样做的目的是利用构建的代价体金字塔中的潜在关系,提高其精度。因此,本文在代价体正则化操作之前对生成的代价体进行预处理,模块结构如图3所示。
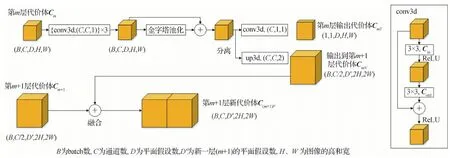
图3 多尺度代价体信息共享模块结构图Fig.3 Multi-scale cost volumes information sharing module structure diagram
由于3个尺度生成的代价体之间几乎没有任何联系,仅仅依靠特征提取模块的上采样保持仅有的关联,导致每层中代价体的信息无法传递。因此,本文在代价体正则化的预处理阶段设计了一个多尺度代价体信息共享模块,其作用是将每层生成的代价体进行分离并且将其融合到下一层中,使小尺度的代价体信息融合进下一层的代价体中,以提高深度图的估计质量。以顶层为例,生成的代价体C1的5维尺度为1×32×48×128×160,首先将其通过3次3维卷积块,随后将其进行金字塔池化以获取足够的上下文信息,随后的分离操作是对其分别进行上采样和3维卷积。经过上采样得到的1×16×32×256×320的代价体C1N与中间层生成的代价体C2具有同样大小的尺度,因此将其融合,形成第2层新的1×32×32×256×320代价体C2F,与此同时,经过3维卷积后的1×1×48×128×160的代价体C1T进入到3D U-Net模块中进行代价体正则化。以此类推,在第3层融合生成的代价体C3F,便可以直接将其送入3D U-Net模块中并估计最终的深度图。
2.4 损失函数
在3层级联模型中,对每一层的损失都进行监督,总损失定义为
Losstotal=λ1L1+λ2L2+λ3L3
(3)
式中,λ1,λ2,λ3为3个阶段的损失权重,在级联结构中,一般分辨率越高,设置的权重越大,因此本文也采用与CasMVSNet(Gu等,2020)相同的设置,即为0.5、1和2,L1,L2,L3分别为小、中、大3个不同尺度的损失。对于Lm,本文将其定义为SmoothL1Loss,具体如下
(4)
(5)
式中,n为图像个数,m为级联结构中的层数,xm和ym分别为估计深度和真实深度。
3 实验及结果分析
3.1 数据集及实验设置
本文采用DTU(Technical University of Denmark)数据集(Aanæs等,2016)进行实验。DTU数据集是针对MVS而专门拍摄并处理的室内数据集,利用一个搭载可调节亮度灯的工业机器臂对一个物体进行多视角的拍摄,每个物体所拍的视角都经过严格控制,可以直接获取每个视角的相机内、外参数。它由128个不同的物体或场景组成,其中有79个训练场景、18个验证场景和22个测试场景,每个训练的物体或场景共拍摄49个视角,每个视角共有7种不同的亮度,共有27 097个训练样本,每幅影像的分辨率为1 600×1 200 像素。同时,每个场景还提供了真值点云以供计算。
使用DTU训练集进行训练时,初始的输入图像分辨率为512×640像素,输入图像个数N=3。3层的深度假设的个数分别为48、32和8,对应的深度间隔分别为MVSNet(Yao等,2018)间隔的4、2和1倍。3个尺度的特征图分辨率分别为原始图像分辨率大小的1/16、1/4和1倍。在训练中,使用Adam优化器并设置参数β1=0.9和β2=0.999。训练的初始学习率设置为0.001,总共进行16轮训练,在第10、12和14轮后将学习率进行减半处理。本文方法在1块英伟达3090显卡上进行训练,批量大小设置为1,具体环境配置如表1所示。
表1 本文的环境配置Table 1 Environment configuration for this paper
3.2 评价指标
在DTU数据集提供的MATLAB代码上可以进行准确性和完整性的实验评估,输入生成的点云文件,与真值点云进行计算可得。评价指标主要有3个,分别是准确度误差Acc、完整度误差Comp和整体性误差Overall。其中,Acc计算的是重建点云到真实点云之间的平均距离,代表了MVS重建得到的点云整体质量;Comp计算的是真实点云到重建点云之间的平均距离,代表了MVS重建得到的点云捕获的点在重建曲面上的多少;Overall计算的是准确度误差Acc和完整度误差Comp的均值。同时,给定阈值的误差绝对值和准确率也可以反映出网络更加全面的性能,例如深度误差绝对值、2 mm误差绝对值及准确率,4 mm误差绝对值及准确率等。
3.3 对比实验
为了验证本文模型的有效性,以3个主要指标Acc、Comp和Overall(数值越小为越优)与前人模型的结果进行对比,详细信息如表2所示。
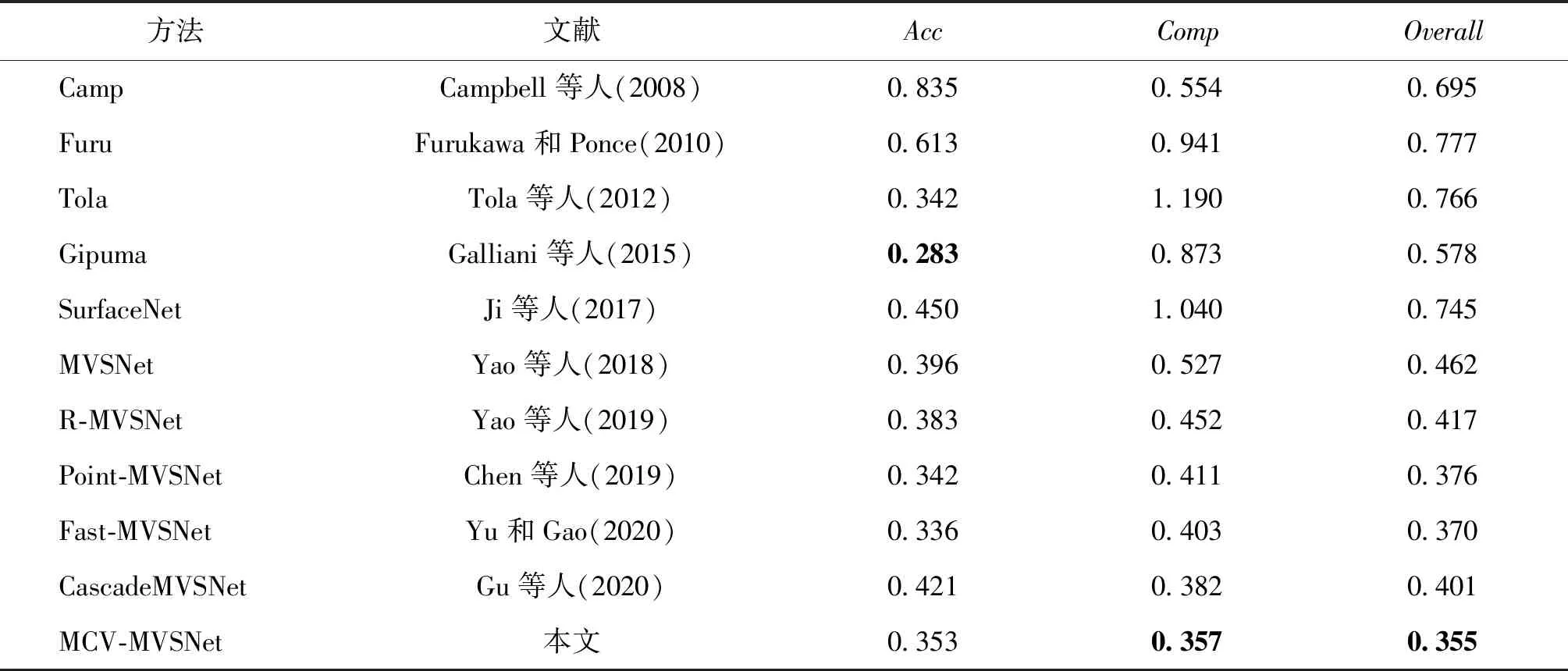
表2 MCV-MVSNet与其他方法主要评估指标对比Table 2 Comparison of the main evaluation metrics of MCV-MVSNet and other methods /mm
由表2可以看出,本文方法在Comp和Overall两个指标上均优于对比方法,在Acc指标上也排名靠前,证明了本文方法在定量结果上的真实有效。同时,与CascadeMVSNet(Gu等,2020)在绝对误差和准确率上的对比如表3所示,在深度误差绝对值上提升约7.3%,在2 mm误差绝对值和准确率上均有提升,虽然在4 mm误差绝对值的表现不如原方法,但是在4 mm准确率上也还是有所提升,也可以证明本文方法在改进后比原方法的效果更加明显。

表3 MCV-MVSNet与原方法次要评估指标对比Table 3 Comparison of the secondary evaluation metrics of MCV-MVSNet and the original method
本文选取了scan4和scan48两个场景重建后的效果与真值点云、MVSNet (Yao等,2018)和CascadeMVSNet(Gu等,2020)进行对比,如图4所示,本文方法相较于MVSNet方法,消除了很多噪声的影响,更加专注于对物体本身的重建,而相较于CasMVSNet方法,在红框内的细节表现更好,重建的完整性效果也得以证实。
3.4 消融实验
针对本文提出了两个改进,分别对其进行单独的测试,测试结果如表4所示。第1行为原始CascadeMVSNet(Gu等,2020)得到的结果,第2行、第3行分别为在原始模型基础上添加双U-Net特征提取模块和多尺度代价体信息共享模块后得到的结果,第4行为整体改进后的模型得到的结果。可以看出,两个模块相对于原始模型均有提升,证明了两个模块均具有有效性。
同时,如图5所示,对每个实验估计的深度图进行对比,同样选取scan4和scan48两个场景的最终深度估计图,可见在添加每一个模块后均比原始方法更加完整。相较于原方法以及单独添加某个模块的方法,本文方法对周边噪声的消除起到了更好的效果,重建物体边缘的平滑度也有所提升,使得根据深度图估计出的3维模型也有一定的提升。
本文主要针对重建的精度指标进行改进,以内存消耗和运行时间为代价获取更高的精度。使用双U-Net特征提取模块旨在提取到更加精准、完整的特征图,此模块对提取到的特征进行反复处理,增加了大量的计算,同时,需要缓存大量的中间数据。同理,在代价体正则化的预处理阶段,多尺度代价体信息共享模块也需要缓存大量的小尺度代价体计算结果,用于与大尺度代价体进行融合。因此,本文实验在每添加一个模块后,其对应的内存消耗和运行时间均有所提高,具体数据如表5所示,而这也是后续工作的主要目标,即如何在维持精度不变的同时,有效降低内存消耗和运行时间。
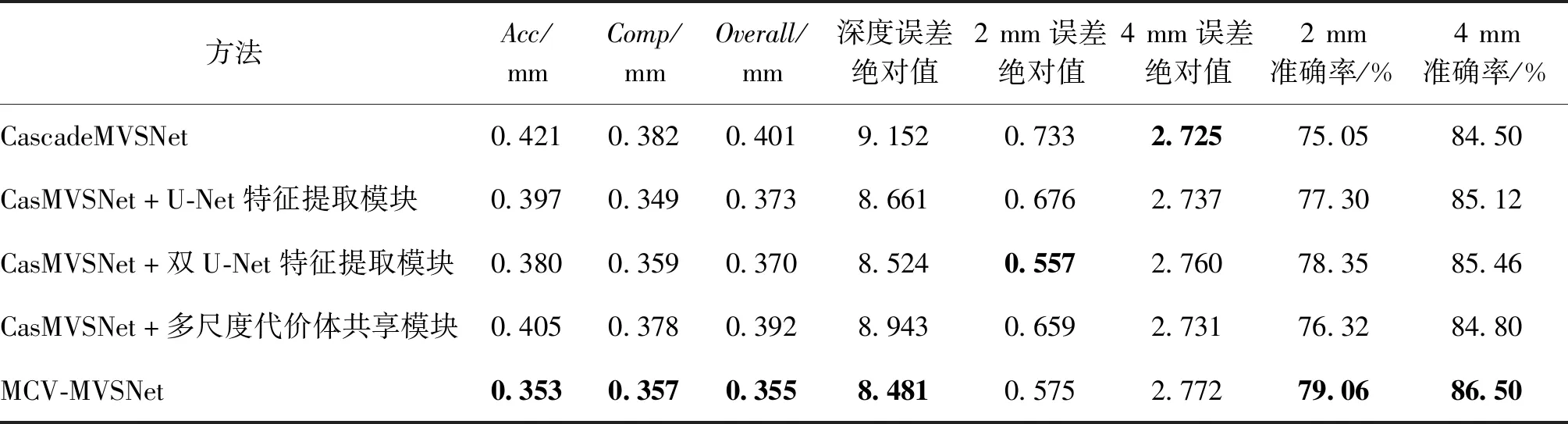
表4 消融实验评估指标对比Table 4 Comparison of evaluation metrics for ablation experiments

图5 scan4和scan48在分别添加不同模块后估计的最终深度图Fig.5 The final estimated depth maps of scan4 and scan48 after adding different modules respectively((a) original images;(b) ground truth depth maps;(c) CasMVSNet;(d) adding U-Net feature extraction module;(e) adding double U-Net feature extraction module;(f) adding multi-scale cost volumes information sharing module;(g) ours)
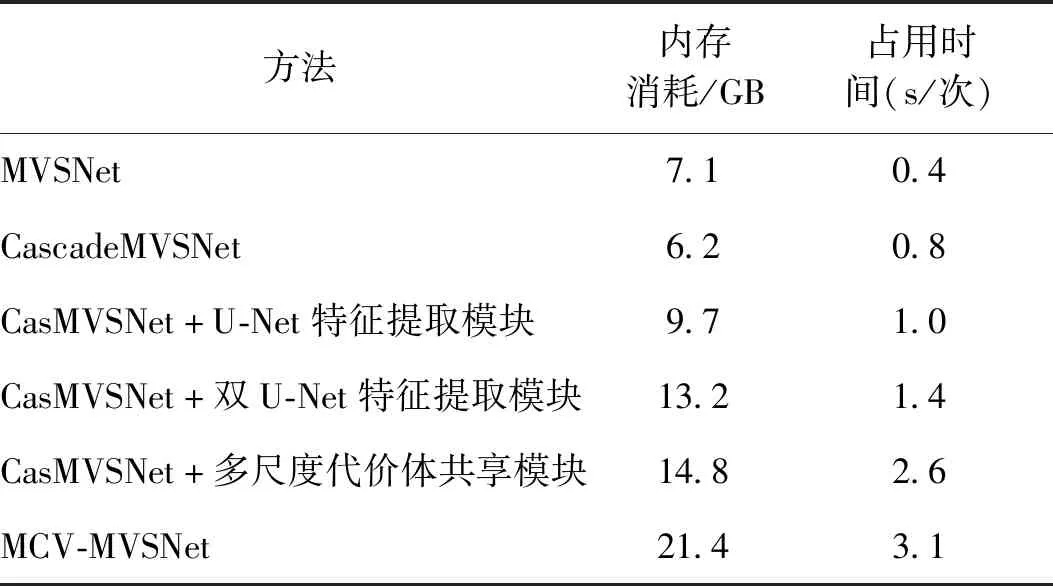
表5 消融实验内存消耗和占用时间对比Table 5 Comparison of memory consumption and occupied time for ablation experiments
4 结 论
针对基于深度学习的多视角立体重建方法中出现的特征提取的效果一般和代价体之间的关联性较差的问题,本文提出了一种新的多视角立体网络模型MCV-MVSNet,对特征提取和代价体正则化阶段分别进行了改进。为了提高特征的完整性和准确性,设计了一个双U-Net网络结构进行特征提取;为了增加不同层代价体之间的相互关联,使代价体内的信息可以逐层传递,设计了一个多尺度代价体信息共享模块,以提高深度图的估计质量。本文方法在DTU数据集上相比于其他基于深度学习的方法,在重建精度上取得了优异的效果,相比于传统方法更是大幅缩减了运行时间。但是,随着重建精度的提升,相较于其他基于深度学习的方法,本文方法由于卷积规模增大,代价体之间的计算也会加大,导致GPU的占用内存提高,同时训练时间也在增加。在后续工作中,将进一步调整网络结构,以减少内存消耗,缩短运行时间。
