融合通道层注意力机制的多支路卷积网络抑郁症识别
2022-11-18孙浩浩邵珠宏尚媛园孙晓妮胡强孔佑勇
孙浩浩,邵珠宏*,尚媛园,孙晓妮,胡强,孔佑勇
1. 首都师范大学信息工程学院,北京 100048; 2. 上海交通大学医学院附属精神卫生中心, 上海 200030 3. 上海交通大学生物医学工程学院, 上海 200240; 4. 东南大学计算机科学与工程学院, 南京 210096
0 引 言
抑郁症(尤其是重度抑郁症)是一种常见的情感性精神疾病,给人们的思维和行为等造成负面影响,严重影响日常工作和生活。同时,还会增加其他疾病发病率,例如癌症或心脏病(Sotelo和Nemeroff,2017)。据世界卫生组织报道,全球现有大约3.5亿抑郁症患者,并且呈现年轻化趋势(https://www.who.int/topics/depression/zh/)。目前,中国抑郁症患者的终身患病率为6.9%,12个月患病率为3.6%(Huang等,2019)。此外,在自杀人群中,超过60%患有抑郁症或其他精神障碍疾病(Lynch和Duval,2011)。2020年,国家卫生健康委员会在《探索抑郁症防治特色服务工作方案》中提出将抑郁症筛查纳入学生健康体检内容(http://www.nhc.gov.cn/)。
当前,临床对抑郁症的诊断主要根据病人的病史和临床表现,采用标准化问卷如BDI(beck depression inventory)(Beck等,1996)和具有专业知识的精神科医生访谈的方式判断就诊人是否患有抑郁症及严重程度(Chmielewski等,2015;Pampouchidou等,2019)。然而,这种诊断方式存在主观性、评估过程耗时、容易误诊和漏诊等问题。随着人们工作和生活节奏的不断加快,抑郁症的发生率呈上升趋势,但是我国精神科医生的数量偏少。
1 相关工作
研究表明,抑郁症患者在面部活动、手势、头部运动和语言表达方面与健康人群有所区别,而且面部活动是抑郁状态的有效外在表现(Jan等,2014;Ellgring等,1989)。相对于问卷/访谈的诊断方式,通过机器学习方法对面部序列图像进行分析,能够准确捕捉人脸表情的细微变化和实现持续性检测,可用于抑郁症早期筛查和严重程度评估。相对于传统诊断方式,这种计算机辅助的抑郁症识别更加具有客观性和稳定性,也能够进行自主的状态评估并用于治疗后的跟踪观察。
在AVEC2013(The Continuous Audio/Visual Emotion and Depression Recognition Challenge)抑郁症数据库(Valstar等,2013)中,首先对视频帧进行人脸检测、裁剪和对齐得到面部图像,然后提取局部相位量化(local phase quantization,LPQ)特征,最后用支持向量回归(support vector regression,SVR)预测抑郁症严重程度。在AVEC2014抑郁症数据库(Valstar等,2014)中,采用LGBP-TOP(local gabor binary patterns from three orthogonal planes)作为基线视频特征,在一个连续帧的分块上利用多个Gabor滤波器作为输入,然后从块的3个不同的正交切片XY、XT和YT中提取局部二值模式(local binary patterns,LBP)特征,再将这些特征直方图化并连接为最终的特征。Wen等人(2015)提出基于面部动态分析和稀疏编码用于抑郁症识别的方法,从面部子空间的LPQ-TOP特征中提取时间的动态性,再通过稀疏编码学习相关的行为模式,进而捕捉所有随时间推移的动态线索。然后通过SVR,在决策层融合输出抑郁症分值。He等人(2019)提出MRLBP-TOP(media robust local binary patterns from three orthogonal planes),同时捕捉人脸的微观结构和动态特征,然后生成DPFV(Dirichlet process Fisher vector),最后使用SVR进行抑郁症识别。Niu等人(2019a)使用LSOGCP(local second-order gradient cross pattern)提取视频中细微的面部动态,提高抑郁症识别的准确性。该方法首先通过高阶梯度和交叉编码方法获得LSOGCP特征来表征每一帧的纹理细节,然后生成3个正交平面的LSOGCP直方图,形成视频表示LSOGCP-TOP,最后用组间分类和组内回归的方法进行抑郁症识别。
基于卷积神经网络的深度特征学习在计算机视觉领域备受关注,而且基于深度学习的方法逐渐应用于抑郁症的自动识别(De Melo等,2020,2022;Pampouchidou等,2020;Song等,2022;Zhou等,2020)。卷积神经网络的深度特征学习方法是基于多层神经网络进行深度表示学习,可以对与特定视觉任务相关的数据进行高级语义结构建模,能够实现从低层次到高层次的分层表示。在这种深层架构中,将卷积和池化等多层数据叠加在一起,以表示不同尺度下的显著图像信息。与传统学习方式相比,卷积神经网络的特征提取和识别可以在统一的框架中共同进行和优化,因此学习到的特征表示更加具有鉴别性,识别效果更好。
Zhu等人(2018)提出基于深度卷积神经网络(deep convolutional neural network,DCNN)的抑郁症识别方法,首先利用连续的视频帧生成光流图像,然后送入Dynamic-DCNN网络提取动态特征,将裁剪后的原始人脸图像送入Appearance-DCNN网络,提取静态特征。并在全连接层进行联合训练,最终输出分值。Al Jazaery和Guo(2021)提出循环神经网络(recurrent neural network,RNN)与3D卷积相结合的网络架构,首先用3D卷积神经网络自动学习由两种不同预处理方法提取的不同尺度下的人脸时空特征,然后使用循环神经网络从序列中进一步学习时空信息,以预测抑郁症的严重程度。Uddin等人(2022)提出采用深度时空特征和多层双向长短时记忆(bi-directional long short-term memory,Bi-LSTM)识别抑郁症的方法,首先使用Inception-ResNet-v2网络结构提取空间信息,用动态特征描述子VLDN(volume local directional number)捕捉面部运动,将VLDN得到的特征图送入卷积神经网络,获得更具鉴别性的特征。然后将二者分别输入到多层Bi-LSTM,在决策层融合后输出抑郁症分值。江筱等人(2019)提出基于级联深度神经网络的抑郁症识别算法,首先将原始人脸图像送入FaceNet直接提取全局特征,同时将裁剪的眼睛和嘴部区域表示成四元数矩阵,并用非对称异或进行编码统计灰度直方图,然后送入localDNN网络提取局部特征,最后将全局特征和局部特征拼接在一起送入新的深度神经网络(deep neural network,DNN)输出抑郁症分值。
上述基于机器学习的抑郁症自动识别方法大多具有较强的特征提取能力,但是忽略了高级语义特征特征与通道之间的关联性对抑郁症识别的重要性。
2 本文算法
为了从人脸图像中获得有效的全局信息,并且充分利用眼睛和嘴等情感表达丰富的局部区域,本文提出一种融合通道层注意力机制的多支路深度卷积神经网络的抑郁症识别方法,主要包括人脸关键点检测与定位、局部—全局特征提取和特征融合。
2.1 通道层注意力机制残差块
本文提出的通道层注意力机制残差块结构如图1所示,它由两个基本的残差网络结构堆叠而成,并在最后一个残差网络结构的输出加入通道层注意力机制。输入特征图尺寸为C/2×H×W,其中C代表特征图通道数,H和W分别代表特征图高和宽。每两个卷积层之间有一层批归一化层(batch norm)和ReLU激活函数。在第1个残差网络结构的第1个卷积层将特征图通道数加倍,同时特征图尺寸减半。为了保证第1次相加时的特征图尺寸相同,将输入数据经过1×1卷积层处理,进行通道数加倍和特征图尺寸减半。
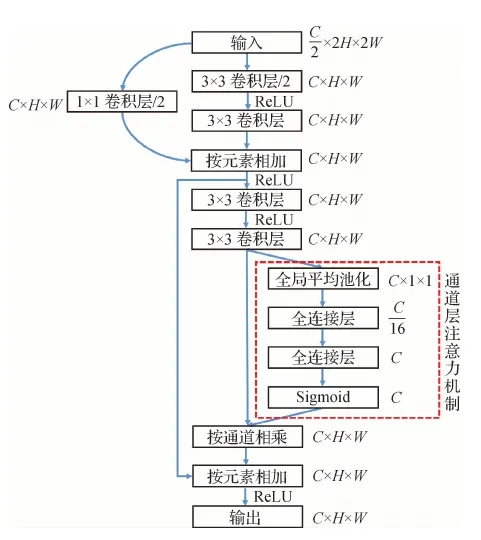
图1 通道层注意力机制残差块结构Fig.1 The residual block structure of channel-wise attention mechanism
首先,对最后一个卷积层的输出特征图沿着空间维度进行压缩,采用全局平均池化将特征图尺寸由原来的C×H×W变为C×1×1,即
(1)
式中,FC为压缩后的特征图,X表示最后一个卷积层的输出特征图。
然后,建模通道之间的相关性,在第1个全连接层将通道特征维度降低到原来的1/16,经过ReLU激活后,再通过一个全连接层升到原来的特征通道维度。这样比只用一个全连接层的优点在于具有更多的非线性,能够更好地拟合通道间的复杂相关性,并且减少参数量和计算量。对于全连接层输入FC,其输出为
FO=ReLU(FC×w+b)
(2)
式中,FO表示全连接的输出,w表示全连接层的权重,b表示全连接层的偏置。
对最后一层全连接层的输出用Sigmoid激活函数(Sigmoid)进行非线性变换,得到每个通道0~1之间的归一化权重,然后按通道乘回原始通道特征,完成在通道维度上的对原始特征的重标定。该过程表示为
(3)

2.2 通道层注意力机制的深度卷积神经网络
提出的通道层注意力机制深度卷积神经网络的结构如图2所示,由卷积核大小为7×7的卷积层、3×3的最大池化层、4个通道层注意力机制残差块和全局平均池化层组成,最后输出512维的特征向量。

图2 通道层注意力机制深度卷积神经网络结构Fig.2 The deep convolutional neural network structure of channel-wise attention mechanism
为了减少计算量,并在靠近输入的地方获得较大的感受野,首先利用7×7卷积和3×3最大池化层对特征图尺寸连续进行两次降采样。同时为了保证信息不过多丢失,在第1个残差块特征图尺寸保持不变,其余3个残差块在第1个卷积时对特征图通道加倍且高、宽减半。以输入特征图尺寸3×256×256为例,该神经网络每层的输入和输出特征图尺寸如表1所示。
2.3 多支路卷积网络模型
本文提出的抑郁症自动识别算法流程如图3所示。

表1 特征图尺寸变化Table 1 Size changes of feature map

图3 算法流程Fig.3 The flowchart of proposed algorithm
首先,从原始视频抽取帧,进行人脸检测、裁剪和对齐,将人脸图像的眼睛和嘴部区域与整幅人脸图像联合作为输入,送入与通道层注意力机制结合的深度卷积神经网络,得到眼睛区域的特征向量Fe、嘴部区域的特征向量Fm和面部的特征向量Ff,其维度均为512。
然后,在特征融合层将3个支路网络提取的特征拼接在一起,得到混合特征向量Ft,即
Ft=[Ff,Fe,Fm]
(4)
最后,将融合后的特征向量送入全连接层,输出识别分数,具体为
Score=Ft×w+b
(5)
式中,Score表示识别分数。
2.4 多支路卷积网络的训练
本文算法主要是基于面部图像进行抑郁症识别,为了减少视频帧的冗余量,对原始视频每隔10帧提取1帧。通过多任务卷积神经网络(multi-task cascade convolutional neural networks,MTCNN)(Zhang等,2016)对视频帧中的人脸进行关键点检测和定位,并利用OpenCV(open source computer vision library)仿射变换进行人脸对齐。根据人脸关键点坐标将人脸裁剪并调整为256×256像素,将眼部裁剪并调整为96×192像素,将嘴部裁剪并调整为96×128像素。
首先对训练图像进行归一化处理,将像素值映射到[0,1],并将每幅图像的RGB通道分别减去整个数据集的均值、除以整个数据集的标准差,使训练数据符合标准高斯分布。训练时将0~63的标签映射到[-1,1],测试时将输出结果恢复到0~63。同时,为了缓解由于图像数量较少可能导致训练的模型容易过拟合和泛化能力差等问题,对训练图像进行翻转和随机裁剪等数据增强。此外,从CASIA-WebFace人脸数据库(Yi等,2014)中提取了1万个ID(identity document),约30万幅人脸图像用于网络的预训练。
在微调阶段,用预训练好的参数来初始化抑郁症识别任务网络模型的参数,并将最后全连接层的输出改为1,以输出抑郁症严重程度的分值。微调时设置学习率为0.000 1,并且每30个epoch将学习率变为原来的1/10,共迭代100个epoch,批量大小(batch size)设为128。使用Adam优化器,β1、β2和ε分别设为0.9、0.999和1×10-8。为了提高网络的泛化能力,在实验中对所有网络层使用L2正则化,权重衰减系数(weight decay)为0.000 5。损失函数MSELoss(mean squared error loss)计算为
(6)
式中,B表示批大小,yi代表真值,y′i表示识别值。
2.5 空间权重图计算
假设在全局特征提取网络最后1个卷积层有N个特征图,令Pn(i,j)表示最后1个卷积层第n个特征图在空间位置(i,j)处的值(n=1,2,3,…,N),其也代表原始输入图像感受野经过卷积计算后的结果。gn代表每个特征图经过全局平均池化后的值,具体为
(7)
式中,k表示特征图尺寸。
然后,经过一个全连接层计算抑郁症严重程度的分值,即
(8)
式中,wn表示全连接层第n个神经元的权重。S可进一步变形为
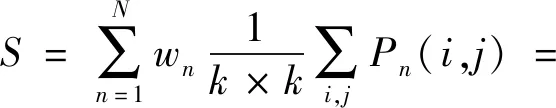
(9)
(10)
式中,W(i,j)表示在空间位置(i,j)上对抑郁症识别分数贡献的大小。
3 实验结果与分析
本文实验环境为Linux操作系统,CPU型号为Intel(R) Xeon(R) CPU E5-2680 v4@ 2.40 GHz,内存为256 GB,显卡型号为TITAN RTX,显存为24 GB,深度学习框架为Pytorch,算法实现编程语言为Python。
本文算法的训练和测试在公开数据集AVEC 2013和AEVC2014进行。AVEC2013共有82名受试者的150个视频片段,这些视频片段均由摄像头和麦克风收集图像和语音。每个视频片段均只有1个受试者通过人机交互完成问卷任务,每个人被记录1~4次,两次测量间隔两周时间。受试者年龄在18~63岁之间,平均年龄31.5岁。视频剪辑的平均长度为25 min,视频的分辨率为640×480像素,帧率为30帧/s。AVEC2013数据库分为训练、验证和测试3个子集,每个子集包含50个视频。每个视频都有对应其抑郁严重程度的标签,标签根据BDI-II问卷评估。AVEC2014抑郁症数据库包含来自AViD-Corpus数据库中12个任务中的两个,分别为Freedom和Northwind。在Northwind中,受试者读一段the north wind and sun中的内容,Freeform是关于受试者的个人生活问题,例如讲述一段童年的伤心往事或聊一下喜欢的食物等。AVEC2014同样分为训练、验证和测试3个数据集,每个子集包含两个任务各50个视频。抑郁症数据库中的部分样本如图4所示。

图4 抑郁症数据库样本Fig.4 Samples of the depression database
为了客观评价算法的性能,将平均绝对误差MAE(mean absolute error)和均方根误差RMSE(root mean square error)作为评价指标。
3.1 通道层注意力机制对抑郁症识别结果影响
为了评估通道层注意力机制对抑郁症识别结果的影响,实验中,网络输入均为人脸图像、眼睛和嘴部区域图像,并将网络提取的全局特征和局部特征进行融合。图5给出了在ACEV2014数据库上加注意力机制前后在训练集和验证集上的每个epoch平均损失曲线。可以看出,在加入注意力机制后,网络收敛加快,振荡减小,且最终损失值较低。

图5 加入注意力机制前后网络损失Fig.5 Network loss before and after adding the attention mechanism
网络加入注意力机制后在两个数据库测试集上的MAE和RMSE如表2所示。可以看出,二者均低于未加入注意力机制的网路。实验结果表明,注意力机制对特征提取和抑郁症识别起着重要作用。
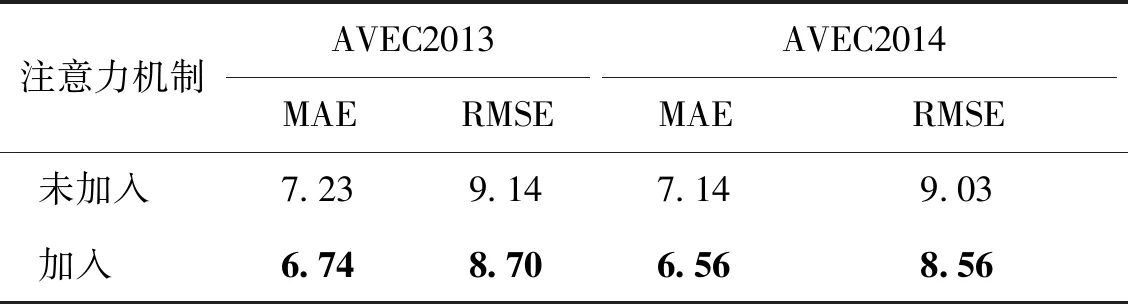
表2 通道层注意力机制对抑郁症识别结果的影响Table 2 The effect of channel-wise attention mechanism on depression recognition results
3.2 特征融合对抑郁症识别结果的影响
为了评估融合全局特征和局部特征对抑郁症识别结果的影响,进行4组实验,分别为仅使用人脸图像、使用人脸图像与眼睛区域的联合、使用人脸图像与嘴部区域的联合、使用人脸图像与眼睛以及嘴部区域的联合。实验结果如表3所示。

表3 不同特征融合的识别结果Table 3 Recognition results fused with different features
从图3可以看出,全局特征与嘴巴局部特征融合后,相较仅用全局特征进行抑郁症识别,在AVEC2013和AVEC2014数据库上,MAE分别下降了0.36和0.41,RMSE分别下降了0.38和0.38。全局特征与眼睛局部特征融合后,相较于仅用全局特征对抑郁症预测的结果,在AVEC2013和AVEC2014数据库上,MAE分别下降了0.80和0.84,RMSE下降了0.79和0.79。这表明在抑郁症识别任务中,眼睛和嘴部等局部特征是对全局特征的有效补充,而且眼睛相对于嘴部而言更能反映抑郁症患者的真实状态。在融合眼睛和嘴部两种局部特征后,在两个数据库上的MAE和RMSE均低于只用全局特征、全局特征与嘴部局部特征融合、全局特征与眼睛局部特征融合,这是因为眼睛和嘴等局部区域特征互为补充,传达了更有效的突出信息,这也与临床医生在判断抑郁症患者严重程度时的经验一致。
3.3 与其他方法对比
为了进一步验证本文提出的抑郁症识别模型的性能,与其他抑郁症识别方法进行比较,评价指标为MAE和RMSE。表4展示了本文算法和其他基于视觉的抑郁症识别算法在AVEC2013和AVEC2014数据库上的识别结果。其中,Baseline(Valstar等,2013)、Baseline(Valstar等,2014)、Wen等人(2015)、He等人(2019)、Niu等人(2019a)是手工特征加分类器的传统识别方法,Zhu等人(2018)、Al Jazaery和Guo(2021)、Uddin等人(2022)、江筱等人(2019)是基于深度学习的识别方法。

表4 不同方法在AVEC2013和AVEC2014数据库上的识别结果比较Table 4 Comparison of recognition results of different methods on AVEC2013 and AVEC2014 databases
从表4可以看出,本文算法在两个数据库上均取得了较低的MAE和RMSE,表明了本文算法在抑郁症识别任务上的优越性和可行性。在其他基于深度学习的方法中,Zhu等人(2018)、Al Jazaery和Guo(2021)、江筱等人(2019)方法均采用双流架构,融合静态特征和动态特征。江筱等人(2019)方法虽然进行了全局特征与局部特征的融合,但是没有考虑通道之间的特征关系,而且在局部特征提取时采用手工提取特征的方法,并将特征变为1维特征向量灰度直方图送进1维卷积神经网络。这种处理方式割裂了像素点在空间上的关系,不能很好地表示眼睛和嘴部周围的空间纹理特征。
除了基于视觉的抑郁症识别方法之外,基于语音特征(Zhao等,2020;Niu等,2019b)或多模态(视觉+语音)特征(Jan等,2018;Meng等,2013;Ma等,2016;Williamson等,2014;Niu等,2020)进行抑郁症识别也是当前的研究热点。为全面验证本文算法的性能,在AVEC2013和AVEC2014数据库上,与语音和多模态方法的结果进行比较,对比结果分别如图6和图7所示。其中,A表示只用语音,V表示只用视觉,A+V表示多模态。可以看出,即使只使用视觉特征,本文算法也取得了与多模态方法相当的结果,这进一步说明了本文算法对抑郁症进行识别的有效性。

图6 AVEC2013数据库识别结果对比Fig.6 Comparison of recognition results on the AVEC2013 database
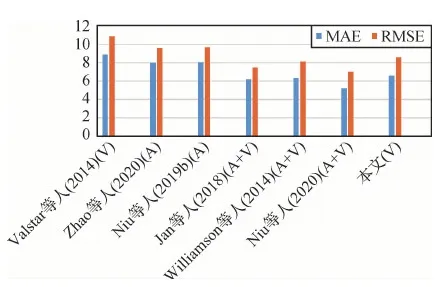
图7 AVEC2014数据库识别结果对比Fig.7 Comparison of recognition results on the AVEC2014 database
3.4 识别结果分析
图8展示了在两个数据库测试集上随机抽取一个batch的真值和识别结果。相比较于真值,本文算法在绝大部分测试样本上的识别值相对较小,这可能与训练集样本分布不均衡有关。

图8 真值和识别值Fig.8 Truth and recognized values((a) AVEC2013;(b) AVEC2014)
图9给出了两个数据库的训练样本和测试样本抑郁分值区间统计结果,低抑郁分数样本,尤其是正常人(0~13)的样本相对较多。
图10给出了本文方法输入为人脸图像时,根据空间像素点对最终识别分数的贡献大小得出的空间权重图。可以看出,无抑郁样本(图10(a)(b))的眼睛区域对最终识别分数贡献较小,中度和重度抑郁症患者样本(图10(c)—(f))的眼睛区域对识别分数贡献最大。值得注意的是,对同一患者(图10(e)(f))在不同时间的不同抑郁程度,本文算法仍可以正确识别,并通过空间权重图来揭示哪些区域对抑郁症的识别贡献最大。分析实验结果可知,模型会将注意力集中在脸部中心区域,即眼睛与嘴之间的区域,尤其是眼睛区域对抑郁症患者最终识别分数影响最大。这些结果与临床上抑郁症患者很少微笑、经常愁眉苦脸、眼神呆滞表现一致,也验证了本文的假设,即关注眼睛和嘴部等表达情感丰富的重点区域将有助于抑郁症的识别。
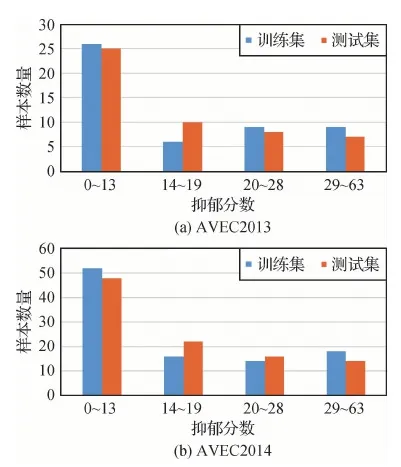
图9 数据库样本分布Fig.9 Database sample distribution ((a) AVEC2013; (b) AVEC2014)

图10 不同抑郁等级空间权重Fig.10 Spatial weighting of different depression levels ((a) true value is 0 and recognized value is 0.32; (b) true value is 8 and recognized value is 8.17; (c) true value is 28 and recognized value is 27.40; (d) true value is 41 and recognized value is 35.30; (e) true value is 29 and recognized value is 29.14; (f) true value is 43 and recognized value is 36.61)
4 结 论
针对使用单一特征进行抑郁症识别存在的不够准确问题,本文提出一种融合通道层注意力机制的多支路深度卷积神经网络的抑郁症识别方法。该方法融合了人脸图像的全局特征和眼睛、嘴部区域的局部特征。其优势在于,一方面,与传统方法的手工提取特征相比,通过深度卷积网络学习得到的视觉特征可以揭示和捕获视觉训练数据中的高级语义结构,使用深度特征进行抑郁症严重程度的识别更加准确;另一方面,针对面部不同区域的多个局部特征深度模型和全局特征深度模型联合训练,不同特征之间实现优势互补,进一步提高了算法的泛化能力。与此同时,引入的通道层注意力机制能够自适应地分配权重以突出抑郁症的显著特征。相较于大多数基于卷积神经网络的识别方法,本文算法在AVEC2013和AVEC2014数据库上取得了最小的平均绝对误差和均方根误差,实验结果证明了本文算法的有效性和可行性。
但是,本文算法在对视频进行预处理时,仅裁剪出人脸图像而未使用语音的相关信息。在未来的研究工作中,将使用深度卷积网络提取语音特征作为现有多视觉特征的补充,同时联合时间维度上的信息,挖掘视频数据的动态特征,以进一步提高算法的识别性能。
