基于字体骨架提取的结构相似性度量研究
2022-11-17陈舒祥薛安懿战国栋
陈舒祥,薛安懿,许 爽,战国栋
(1.大连民族大学 a.信息与通信工程学院;b.设计学院;c. 大连市汉字计算机字库设计技术创新中心,辽宁 大连 116605)
汉字字体骨架代表字体的结构特征。汉字字体骨架化是将字体图像由外轮廓起逐渐剥离,得到与原图结构类似但由单像素线条组成的图像[1]。目前,利用深度神经网络进行字体生成的技术得到广泛的应用,但参考字体对于生成效果具有影响如图1。以宋体作为参考字体生成目标字体,因为目标字体与参考字体结构差异大,容易产生错误的结果。Lei等[2]证明了源字体的结构对生成结果影响较大。

图1 参考字体图像对神经网络生成的影响
因此,本文拟先把字体骨架化,通过字体骨架相似度对比寻找与目标字体更相近的参考字体,进而生成更高质量的目标字体。
目前字体骨架提取的研究中,主要对于汉字图像进行细化处理[3],经处理后提取出的骨架能够表达字体的结构特征。骨架与原始字体保持了一致的拓扑结构。此外,由于书法字笔划交叉处存在变形弯曲等情况,利用ZS并行细化算法[4]在整体上能取得不错的效果,但是在细节上比如书法字骨架上出现的冗余像素及毛刺现象还需要进一步完善。
本文在分析书法字结构特点的基础上,发现书法字的倾斜笔画上容易出现冗余像素,也就是斜线区域易出现细化不完整的情况,同样由于书法字书写随意,容易在交叉处产生骨架毛刺如图2。
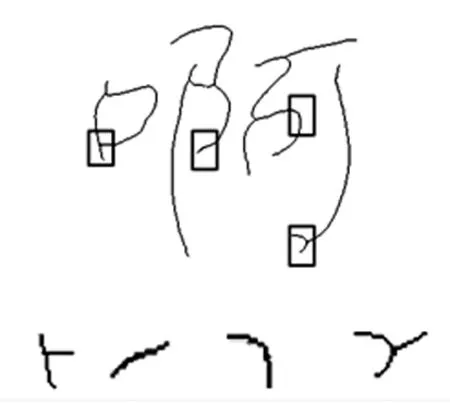
图2 斜线和交叉处冗余示意图
1 本文骨架提取方法
本文提出一种改进的书法字骨架化算法如图3。
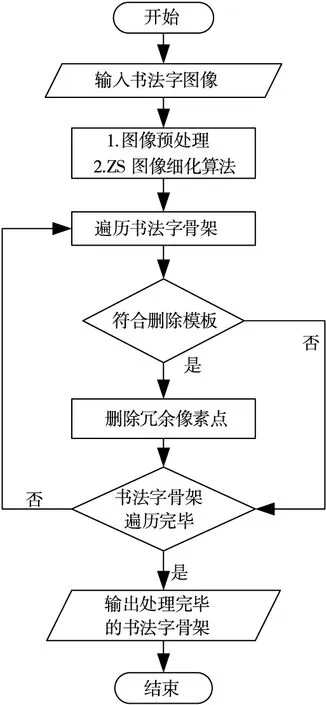
图3 本文书法字骨架化算法流程图
本文使用斜线冗余像素消除模板对骨架细节进行冗余去除如图4。其中P1代表待检测的中心像素点,领域中的数值包括0、1和X,其中X表示该位置可以为任意值。
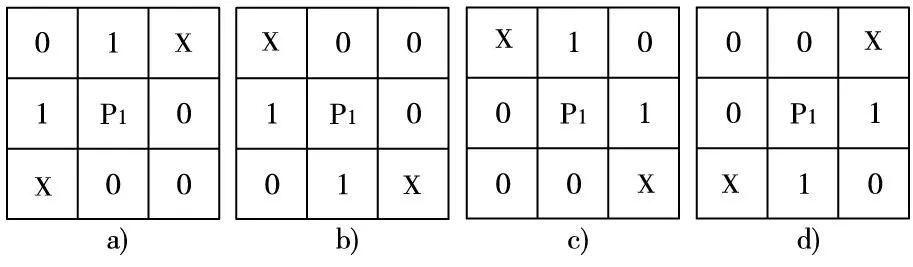
图4 斜线冗余像素消除模板
其中消除模板中P1须满足公式(1)条件。
(1)
公式(1)表明P2和P8须同时为黑色像素,且P4、P5、P6和P9须同时为白色像素,此时存在一条向左下方的斜线如图4a所示,其中P1是冗余的,可以删除;类似地,对于图4b,4c和4d四个方向的斜线冗余点,添加以下公式(2)~(4)进行删除。
(2)
(3)
(4)
上述4个条件主要用来消除图中斜线区域的像素冗余。当N(P1) = 3时,其中N(P1)为目标像素点P1八邻域中像素值是1的点的数量,P1表示是分叉点或边界点中的一种。由于图像分叉处也会出现像素冗余的情况,添加了消除模板如图5。
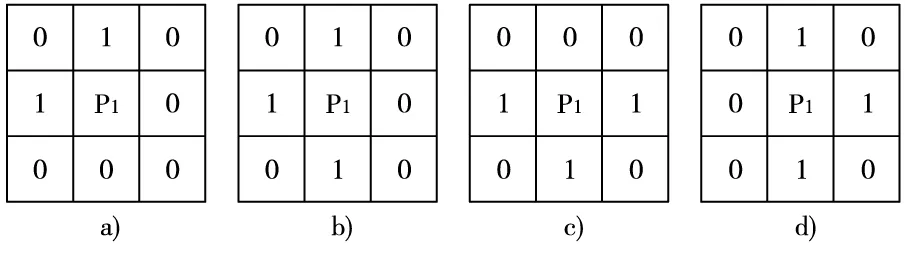
图5 消除模板示意图
其中,P1需要满足以下条件如式(5):
(5)
其中,第一是P、P4、P6和P8都同时为白色背景像素,第二是P1、P3、P5和P7中需要有三个黑色像素,其构成了如图5所示的四个方向上的分叉情况,此时,P1成为分叉情况中的冗余点,需要删除。
(6)
基于索引表的细化结果如图6。,可以看出由于各个方向的像素剥离速度不一致,会导致出现明显的断裂以及毛刺情况,在笔画端点处还会出现单个像素,破坏了原有字体的拓扑结构。

图6 基于索引表的细化结果
ZS算法和本文改进的ZS算法的实验结果对比如图7。通过笔画对交叉处以及斜线区域的放大图可以看出,相较传统的ZS算法,本文改进后的算法不仅保证像素宽度为1,还去除了ZS细化算法中的毛刺及冗余像素,可以充分准确地保留书法字的拓扑结构特征。
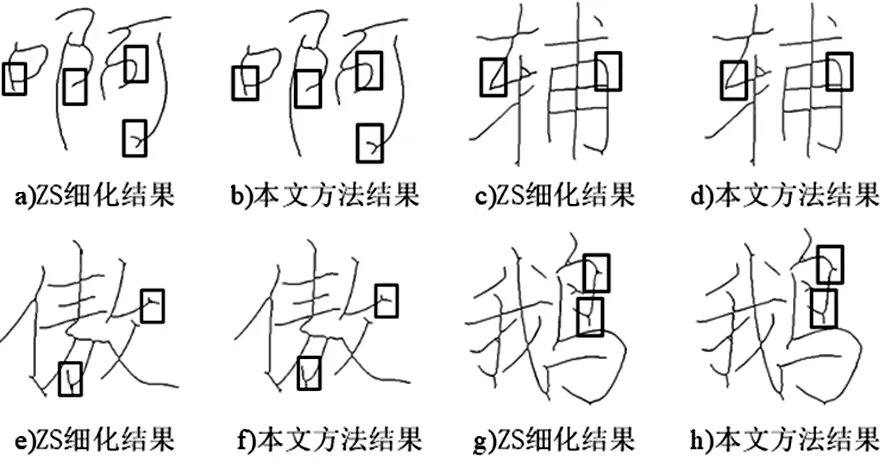
图7 本文改进算法细化结果
2 骨架相似度计算
在书法字体设计中,存在字体的中心线,中心线即指书法字体的简化版本,而骨架与书法字中心线非常近似,其可以代表书法字体整体结构特征和拓扑信息。本文中,利用不变矩以及皮尔逊相关系数度量几种书法字骨架之间的相似程度,利用计算得出的相似度作为书法字之间的相似度评分。
对书法图像骨架的提取算法,本文在尝试多种骨架化方法后提出了改进的ZS骨架提取算法,该算法经前文论证可以证明其能够较好的保留书法字体的形体特征,同时在处理时能消除笔画毛刺和冗余点,保护了笔画端点及交叉点的笔形信息,不会造成由于细化而产生的笔画断裂,使用该方法提取出的骨架能够较好地完成本文后续的书法字体相似度计算。
2.1 Hu矩
矩是用来量化描述图像特征的算子[5],其定义为图像像素强度的加权平均值,对所有像素的总和进行计算,也就是说像素的强度的权重与它们所处的图像的位置无关。一幅图像的Hu矩能够表示一幅图像的全局性结构特征,它的值相对稳定,在平移、旋转和尺度变换之后仍旧保持着相对不变性,因此,不变矩在计算机视觉、目标识别等等领域被广泛运用。因此,Hu矩能够表达书法字骨架的结构特征。
在提取图像Hu矩时,首先要将图像进行二值化处理,假设处理完的图像为pic(x,y),它的p+q阶原点矩可以作如下式(7)表示[6]:
(7)
那么,连续函数pic(x,y)的p+q阶矩阵的离散形式为式(8):
(8)
上述公式求得的矩的值是唯一的,所以能够反映书法字骨架图像的拓扑形状特征。
图像的中心位置可以由公式(9)计算出:
(9)
求中心矩阵的公式为(10):
(10)
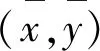
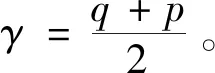
(11)
由中心矩以及普通矩的公式,可以推导出不变矩组如式(12):
(12)
Hu矩为普通矩和中心距变化而成,所以有平移,旋转,缩放不变性,因此本文用其描述骨架形状特征[7]。
2.2 基于Hu矩的骨架九宫格相似度研究
提取书法字骨架图像的Hu矩后,计算书法字骨架之间的相似度就变成了计算Hu矩之间的相似程度。皮尔逊相关系数提供了对变量的取值范围不同的处理步骤,相比欧几里得更加复杂,结果更加精确[8],本文采用皮尔逊相关系数计算书法字骨架之间不变矩的相关程度,用以测试两个书法字骨架之间的相似程度。
皮尔逊相关系数输出的范围在-1到+1之间,0代表不相关,负数值代表负相关,正数值代表正相关。在对两组数据X和Y进行相似度计算时,它们的相关公式为式(13):
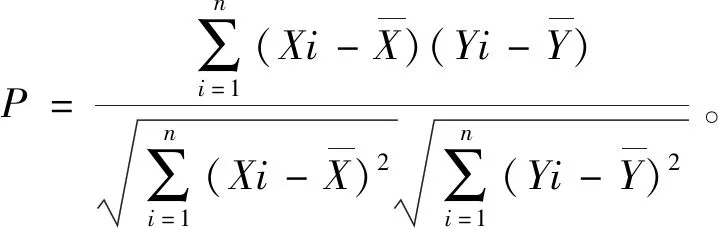
(13)
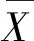
本文实验的书法字骨架相似度对比见表1。目标书法字骨架提取之后,分别与源字体库中楷书、仿宋、隶书、行书、黑体以及宋体六类中同一个字做骨架九宫格相似度判别,实验结果表示,目标书法字与行书较为类似,与隶书、仿宋等相差较大。
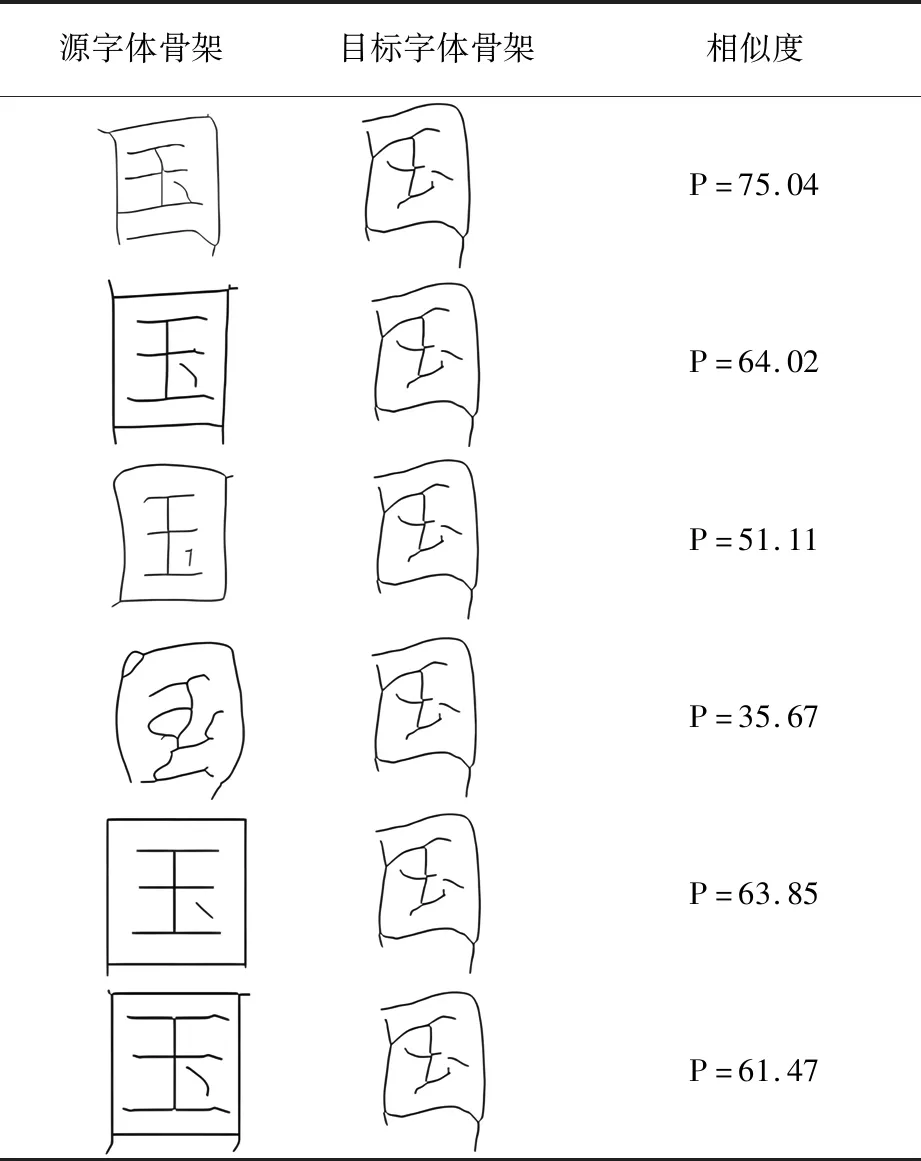
表1 书法字骨架相似度评价
3 结 语
本文主要为字体风格预配对网络设计解决方案,研究算法并实现。主要分为两部分:一是分析了几种常用的细化算法,并提出一种基于ZS细化算法的改进算法进行书法字骨架化实验,使用这种方法处理得到的书法字图像一方面减少了冗余像素点,一方面在笔画相交处无断点情况,整体骨架连通性好,毛刺少,能够较好保留书法字的拓扑结构信息,并且提取出的骨架大致位于书法字图像中心线上;二是将书法字采用九宫格方法分割后,利用不变矩和皮尔逊相关系数计算两个书法字之间的相似度,对其进行评分。
