视频描述中多参考语义生成网络
2022-11-17杨大伟
高 航,杨大伟,毛 琳
(大连民族大学 机电工程学院,辽宁 大连 116605)
视频语义信息常被用来提升视频描述性能,但视频中场景、对象和行为等因素较为复杂,语义特征不能够对视频内容充分表示,影响视频描述准确性。目前主流的视频描述模型多采用编码-解码框架,提取视频特征的编码器一般采用卷积神经网络[1](Convolutional Neural Networks,CNN)、长短时记忆(Long Short-Term Memory,LSTM)[2,3]等循环神经网络(Recurrent Neural Network,RNN)[4]作为解码器生成文本描述。语义特征作为一种有效的编码特征在视频描述中较为常见,Tu等[5,6]通过Fast R-CNN获取目标语义特征,将其与卷积特征一同送入LSTM输出视频描述,该方法有效捕捉了视频中的目标,但不能充分地表示其属性和行为。Nayyer等[7]使用目标检测算法和3D卷积获取目标和行为语义信息[8],得到较好的视频描述结果,表明丰富的特征内容有利于提升网络性能。Vasili等[9]提出多模态视频描述,将视觉特征、声音特征和表示视频主题的行为语义特征作为输入,融合多个信息源以求得到准确的文本描述,但并非所有声音特征都能表达视频场景,存在特征冗余问题,且少量标签的语义特征不能充分地表达视频内容。为解决上述问题,Gan等[10]提出用于图像和视频描述的语义检测网络SCN,采用多层感知机[11](Multilayer Perceptron,MLP)提取更多分类标签的词汇语义特征,但视频或图像中场景等因素较为复杂,简单MLP获取的语义信息不够丰富,从而影响描述效果。Chen等[12]提出语义辅助视频描述网络SAVC(Semantic-assisted video captioning network),采用卷积网络提取视觉特征,将语义特征作为视觉特征的辅助生成文本描述,与SCN类似,MLP获取的语义特征表达能力不足,影响文本描述效果。
为获取表征能力更强的词汇语义信息,提升视频描述性能,本文提出视频描述中多参考语义生成网络(Multi-Reference Semantic Generation Network for Video Captioning,MRNet)。该网络通过多参考MLP结构生成语义特征,在MLP获取语义特征过程中引入视觉信息,利用视觉信息对特征进行补充和调整,丰富语义特征内容并提高其准确程度。MRNet还具备残差结构缓解网络退化现象等优点,在保证视觉信息完整表达的基础上,实现了语义特征表达能力的增强。
1 MRNet算法
MLP获取的语义信息常被用来提升视频描述性能。SAVC网络利用语义信息辅助视觉特征生成文本描述[12],语义信息辅助的网络一般形式如图1。
语义生成网络获取语义特征y的数学表达如下:
y=σ3(F3(σ2(F2(σ1(F1(x))))));
(1)
F(x)=Wx+b。
(2)
式中:x为输入的视觉特征;F1、F2和F3为MLP三层处理函数,获得途径如式(2);σ(·)表示相应层激活函数。

图1 SAVC结构示意图
由于常规MLP结构提取语义特征的能力有限,由此构建多参考语义生成网络—MRNet,在语义提取过程中融合视觉信息,以视觉信息为参考对特征进行补充和修正,增强特征有效性和准确性,参考型MLP分为单参考和多参考两种形式,多参考MLP由单参考MLP结构复用而来,可以进一步提升语义特征的表达能力。
1.1 单参考MLP结构
本文在MLP基础上引入其他通道信息,形成单参考MLP结构,网络结构如图2。

图2 单参考MLP结构
单参考MLP结构数学表达如下:
y1=x;
(3)
y2=σ(F(x)+x1);
(4)
F(x)=Wx+b;
(5)
x1=G(x)。
(6)
式中:x是双通道网络结构的输入;C1、C2代表通道1和通道2;y1和y2是两个通道的输出;函数F(x)表示MLP对特征的处理;W和b是权重和偏置,W与x做全连接计算。x1是输入特征x的恒等映射,当F(x)与x维度不一致时,G(x)采用池化或resize上下采样等方式调整x的维度,x可表示为x={s0,s1, …,sn},x1、y2均为此形式特征向量,且x1、y2维度相同。
特征x在通道1直接输出,与简单MLP结构不同,通道2的单参考MLP结构引入了参考信息x1,在MLP对特征进行萃取的过程中,以其他通道信息作为参考和补充使特征表达更加充分,增强特征的表征能力。且该结构与残差类似,以捷径连接方式将MLP处理结果与原始特征相加,通过优化残差单元得到更有效的输出特征,由于在特征提取过程中融入原始特征x,故可保证原始信息的完整表达。
1.2 多参考MLP结构
随着分类能力需求的增强,MLP的层数逐渐增多,由此可将单参考结构复用,形成多参考MLP结构如图3。

图3 多参考MLP结构
多参考MLP结构数学表达如下:
y2=σn(Fn(…(σ2(F2(σ1(F1(x)+x1))+x2))…)+xn);
(7)
Fn=Wnσn-1(Fn-1+xn-1)+bn。
(8)
式中:x是网络的输入;y1、y2是两个通道输出;F1、F2、…、Fn表示MLP每一层处理;x1、x2、…、xn表示特征x的恒等映射,此处将调整维度的G(x)省略。
将MLP每一层输出与x的恒等映射相加,其本质是一种逐层嵌套的残差MLP,利用这种本质形式直观地分析多参考MLP的结构特点如图4。

图4 多参考MLP结构的本质分析
多参考MLP结构的本质分析数学表达如下:
Hn(x)=Fn(…(F2(F1(x)+x1)+x2)…)+xn;
(9)
An(x)=Fn(…(F2(F1(x)+x1)+x2)…) ;
(10)
Hn(x) =An(x)+xn。
(11)
将公式(7)中激活函数省略,且第n层输出定义为Hn(x),得到公式(9)。将引入xn之前的处理设为An(x),则有公式(11),可知网络第n层确是一种残差连接,且进一步可知多参考MLP的每一层均实现了这种残差连接,可有效解决网络退化等问题。不同的是,本文在每一层引入原始x,可确保特征中原始信息的完整表达,利用原始特征的补充和参考作用丰富特征内容进而提升其表达能力。
1.3 网络模型
为获取表达能力较强的视频语义特征,基于本文提出的以上结构设计多参考语义生成网络MRNet,以视觉特征为参考,由3层多参考MLP结构生成语义特征,将该语义生成网络应用于视频描述任务,通过获取表达能力更强的语义特征,提升视频描述网络的整体性能,网络模型如图5。

图5 视频描述网络结构图
算法流程如下:
(1)输入数据集视频,对视频预处理得到固定的帧数和图像尺寸;
(2)分别采用3D卷积和2D卷积提取视频特征,将两种特征级联,得到视觉特征;
(3)将视觉特征传递到双通道网络中,在第一通道直接输出视觉特征,在第二通道MRNet中输出语义特征;
(4)将视觉特征和语义特征送入LSTM网络,生成文本描述。
2 实验结果与分析
2.1 数据集
选择MSR-VTT[13]和MSVD[14]两个数据集进行训练和测试。MSR-VTT数据集包含10 000个长度约为10 s的短视频,内容涉及生活中的各种场景,每个视频配有人工标注的文本描述作为Ground Truth,在实验中将7 010个视频用于训练,2 990个视频用于测试。MSVD数据集中共有1 970个视频,将1 300个视频用于训练,670个视频用于测试。
2.2 实验设计
在TensorFlow深度学习框架下使用Python语言编程实现,在Ubuntu16.04系统中采用单张NVIDIA 1080Ti显卡训练和测试。
对于整体视频描述网络,首先对视频进行预处理,对每个视频均匀提取32帧图像后剪裁为固定尺寸256×256,利用预训练的ECO[15]和ResNeXt[16]网络获取3D和2D特征,得到3 584维视觉特征向量,采用多参考语义生成网络获取语义特征,将其与视觉特征共同送入LSTM,重新训练后输出文本描述。训练时将学习率设置为0.000 4,批次大小为64,迭代次数为50,采用Adam算法优化模型。
使用视频描述任务最常用的四个评价指标衡量文本描述的准确程度,分别为BLEU-4、CIDEr、METEOR和ROUGE-L,四个指标综合考虑准确度、召回度、句子的流畅性、近义词等多方面因素对句子进行评价,计算公式如式(12)~式(15)。
(12)
式中:pn表示生成句子中连续的n个词语(n元词)的预测精度,即统计n元词是否在生成句子和参考句子中同时出现;wn表示该n元词的权重(本文n=4);BP是对过短句子的惩罚因子。
(13)
式中:c是生成句子;s是参考句子;M是参考句子的数量;gn(·)表示基于n元词的TF-IDF向量(统计一个词语在语料库或文件中出现的频率进而判断其重要程度)。
Meteor=Fmean(1-p) 。
(14)
式中:Fmean表示1元词的调和平均值(将精度和召回率以一定权重组合);p为惩罚因子(抑制1元词的调和平均值,有利于生成准确的词组)。
ROUGE-L=(1+β2)RlcsPlcs/(Rlcs+β2Plcs)。
(15)
式中,Rlcs和Plcs是根据生成句子和参考句子的最大公共子序列长度计算获得的召回率和准确率。
对于MRNet,将MLP每一层神经元个数设置为512、512、300。学习率为0.000 2,批次大小为128,迭代次数设置为1 000。语义特征的Ground Truth是人工标注的300维特征向量,第i个视频的语义Ground Truth可表示为
(16)
其中每个值代表某个词汇在视频中是否涉及。在网络中,采用准确率accuracy衡量语义特征的准确程度,如式(17),Nt为预测的全部单词个数300,Nr为300维向量中预测正确的单词个数。accuracy值越大,说明语义特征越准确。
(17)
2.3 视觉特征参考强度的实验与分析
为验证MRNet参考结构的有效性,引入不同数量的视觉特征参考如图6,分析参考强度对性能的影响。

a)No reference b)R=1 c)R=2 d)R=3图6 参考强度示意图
图6a为无参考的语义生成网络为基准,图6b、图6c和图6d为逐渐增加参考数量,且由相关实验可知参考特征的位置和顺序对性能无显著影响。在MSR-VTT和MSVD数据集上不同参考数量的性能对比结果见表1。

表1 两数据集不同参考数量性能对比结果
网络仅引入一条特征参考时,生成的词汇语义特征准确率有所降低,却得到了视频描述性能的显著提升,可知参考型MLP结构可以增强语义有效性。整体来看,语义特征的准确率随参考数量的增加逐步提升,视频描述的四个评价指标也整体呈上升趋势,当参考特征数量为3时性能达到最佳,验证了在每一阶段引入视觉特征参考的必要性和有效性。
2.4 与残差结构对比的实验与分析
为验证MRNet优于残差MLP结构,对两种结构进行对比如图7。图7a和图7b分别是残差MLP和多参考MLP结构,除捷径连接方式,两种结构的参数均相同。
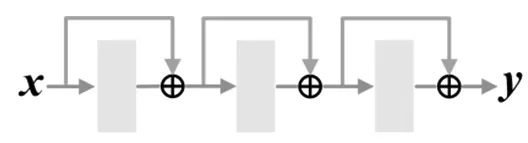
a) 残差MLP b) 多参考MLP图7 MLP结构对比示意图
在MSR-VTT和MSVD数据集上两种结构的性能对比结果见表2。

表2 在两个数据集上两种结构的性能对比结果
在两个数据集中,多参考MLP在四个评价指标上均优于残差MLP结构,表明多参考MLP结构并非捷径连接的简单堆叠,在具备残差优点的基础上,可以增强语义特征的表达能力,进而提升视频描述模型性能。
2.5 多参考MLP层数确定
为确定多参考MLP最佳网络层数,进行如下对比实验。MLP网络层数由1到5逐渐递增,且在每一层都引入视觉特征参考。视频描述性能对比见表3。当层数为1时性能较低,从1层到3层网络性能逐渐提升且达到最优,此后趋于稳定,且未发生明显网络退化现象。

表3 在MSR-VTT和MSVD数据集上网络层数性能对比
2.6 算法整体性能对比
在两个数据集上进行实验仿真,得到了较好的视频描述结果,在MSR-VTT数据集上,将MRNet与其他13种现有模型进行对比,结果见表3。BLEU-4和ROUGE-L两个评价指标优于现有同类方法,CIDEr和METEOR两个指标也表现较好。
在MSVD数据集上的性能对比见表4。四个评价指标均有不同程度的提升,且优于现有同类方法。
将两种视频描述方法的结果进行对比如图8。相比于无参考的视频描述方法,MRNet可以得到更准确的文本描述。图8a中MRNet可以准确识别“数学”这一视频语义;图8b中可以准确表达“一个男孩正在与一组评委谈话”这一场景;图8c更全面地指出活动地点为篮球场;图8d则表达了“正在被采访”这一具体行为。以上四个实例验证了MRNet的优越性。
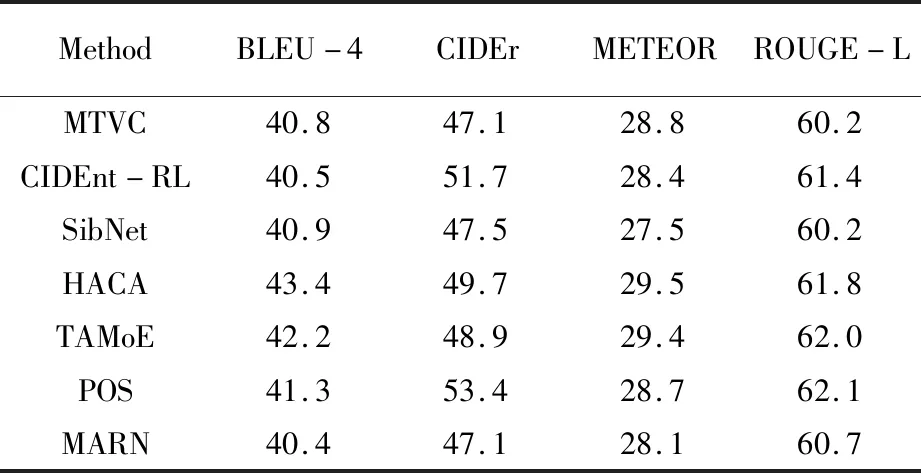
表4 MSR-VTT数据集视频描述性能对比

续4 MSR-VTT数据集视频描述性能对比

表5 MSVD数据集视频描述性能对比
3 结 语
针对视频描述中语义特征表达能力不足导致的文本描述不准确问题,本文提出多参考语义生成网络MRNet。该网络采用多参考MLP结构获取语义特征,在MLP语义萃取过程中融入视觉信息,以视觉信息为参考对特征进行修正和补充,且该结构具备残差网络的优点,可以消除网络退化现象,增强特征的表达能力,同时确保视觉信息的完整表达。通过对比实验验证了多参考结构的有效性和必要性,且MRNet优于现有同类方法,在ROUGE-L指标上平均提升了0.99%。在后续工作中,将对通道间特征的参考方式做进一步研究。

图8 视频描述结果对比
