一种深度学习稀疏单快拍DOA估计方法
2022-11-16朱晗归冯存前冯为可刘成梁
朱晗归 冯存前 冯为可 刘成梁
(中国人民解放军空军工程大学,防空反导学院,陕西西安 710051)
1 引言
波达方向(Direction of Arrival,DOA)估计技术广泛应用于雷达、声纳、电子侦察、无线电通信等领域,是阵列信号处理的一个重要研究方向[1]。典型的DOA 估计方法包括:Capon 空间谱估计方法[2]、特征子空间类多重信号分类(Multiple Signal Classification,MUSIC)方法[3]和基于旋转不变技术的信号参数估计方法(Estimation of Signal Parameters via Rotational Invariance Technique,ESPRIT)[4]等。这些方法可以获得较高的角度分辨率,实际应用广泛,但需要利用多快拍接收数据对信号协方差矩阵进行估计,且无法对相干信号源进行有效处理。为解决这些问题,学者们提出了空间平滑和矩阵重构等改进方法[5-6]进行解相干处理,利用单快拍接收数据估计信号协方差矩阵进行DOA 估计。然而,这些方法往往具有角度分辨率降低、计算复杂度升高等问题。
近年来,稀疏恢复(Sparse Recovery,SR)理论的发展[7-11]为DOA 估计提供了新的思路。通过对角度空间或空间频率进行网格划分,构建导向矢量字典,使得阵列接收数据呈现稀疏特性,可以将DOA估计问题转化为稀疏信号的恢复问题,从而利用单快拍数据对相干信号源进行高分辨DOA 估计。目前,用于求解SR-DOA 模型的算法主要包括L1 范数最小化算法、正交匹配追踪(Orthogonal Matching Pursuit,OMP)算法和平滑L0(Smoothed L0,SL0)算法[12-14]等。其中,L1范数最小化算法将SR问题转化为二阶锥规划问题进行求解,具有较高的精度,但运算比较复杂;OMP 算法计算成本低、估计误差较小,但往往需要信号稀疏度等先验信息;SL0算法估计精度高、无需先验信息、运算复杂度低,但通常需要对其参数进行设置,限制了其在实际中的应用。
随着深度学习(Deep Learning,DL)技术的发展[15],相关学者将深度神经网络(Deep Neural Networks,DNN)技术应用到DOA 估计之中。例如,文献[16]首先基于自编码器进行空间滤波,然后通过多层感知器进行信号拟合,实现了两源DOA 估计;文献[17]将DOA 估计问题转化为多分类问题,利用卷积神经网络(Convolutional Neural Network,CNN)实现了不同信号源条件下的DOA 估计;文献[18]提出了Deep-MUSIC 方法,利用多个CNN 学习接收数据协方差矩阵与MUSIC 空间谱之间的非线性关系,实现了多源DOA 估计。但是,上述方法实现DOA估计的理论性和可解释性不强,且均需多快拍数据进行协方差矩阵估计,作为DNN的输入。
为利用DNN 的优点,并保持SR 的可解释性,Gregor 等提出了深度展开(Deep Unfolding,DU)方法[19]。DU 方法的本质是将特定的迭代SR 算法展开为一个DNN,网络层数代表SR 算法的迭代次数,网络各层的参数代表SR 算法的迭代参数。利用训练数据对该DNN 进行训练,可以获得所对应SR 算法的最优参数,从而提高稀疏恢复性能。受DU 方法的启发,为解决现有SR-DOA 方法存在的参数设置困难、精度有待提高等问题,本文结合模型驱动的SL0 算法和数据驱动的DL 方法,提出SL0 网络(SL0-Net),用于求解SR-DOA 模型,获得高分辨DOA 估计。首先,建立了SR-DOA 模型,对SL0算法进行了介绍,并分析了其数据流图。其次,将SL0算法展开为一个多层DNN,构建了SL0-Net,网络结构主要包括更新层和投影层,网络参数为SL0 算法的逼近参数和迭代步长。最后,通过定义网络损失函数、构建数据集,对SL0-Net 进行训练,得到最优参数进行DOA 估计。仿真实验结果表明,相比SL0 算法,本文所提出的SL0-Net 能够在运算复杂度较低的条件下提高DOA 估计性能;相比于L1 算法和OMP 算法,SL0-Net 能够在信号源数目未知的情况下快速获得高分辨DOA估计结果。
2 信号模型
2.1 SR-DOA模型
假设有Z个远场窄带信号入射到由M个阵元构成的一维均匀线阵(Uniform Linear Array,ULA),则第ti(i=1,2,…,I) 时刻阵列接收的信号可表示为:
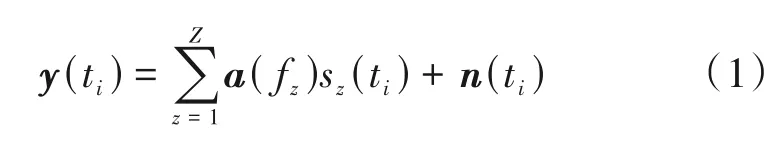
式中sz(ti)为第z个信号的复幅度,z=1,2,…,Z,n(ti)为零均值高斯白噪声,a(fz)为第z个信号的导向矢量,表示为:

式中fz=2dsinθz/λ为第z个信号所对应的空间频率,d为阵元间距,λ为信号波长,θz为第z个信号与阵列之间的夹角,[·]T表示转置。
式(1)可改写为矢量形式,表示为:

式中AZ=[a(f1),a(f2),…,a(fZ)]∈CM×Z为信号导向矢量矩阵,sZ(ti)=[s1(ti),s2(ti),…,sZ(ti)]∈CZ×1为信号幅度矢量。
DOA 估计的目的在于基于式(3)得到不同入射信号的空间频率f1,f2,…,fZ,从而得到信号角度θ1,θ2,…,θZ。若I=1,则对应单快拍DOA 估计模型;若I>1,则对应多快拍DOA 估计模型。本文仅考虑单快拍下的DOA 估计,因此在后续推导中将忽略时间变量ti。
为基于SR-DOA 模型进行DOA 估计,可将整个空间频率范围平均划分为N个网格,基于不同的空间频率f1,f2,…,fN构造导向矢量字典A,表示为:
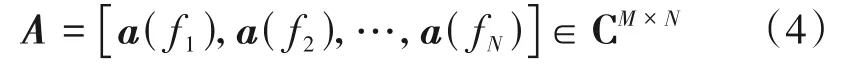
在此基础上,假设Z个入射信号的空间频率均位于所划分的网格上,则阵列接收信号矢量可表征为:

式中s∈CN×1为N个空间频率所对应的复幅度矢量。由于信号源个数Z一般远小于网格数N,因此s中仅包含少量非零元素,即s为稀疏的。基于此,可以将DOA 估计问题转化为如下所示的稀疏恢复问题:
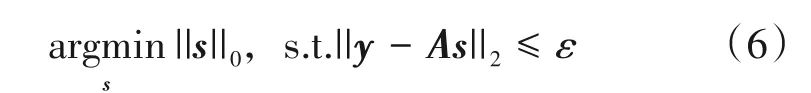
式中ε表示噪声电平分别表示向量的L0范数和L2范数。
2.2 SL0算法
由于L0范数是向量的不连续函数,因此需要利用组合搜索的方法对式(6)进行求解,这种方法运算复杂度高,无法在实际中进行应用。为解决这个问题,SL0 算法通过构造一簇高斯函数逼近L0 范数,从而将离散函数优化问题转化为连续函数优化问题,并结合最速下降法和梯度投影法最小化平滑函数所构成的代价函数,对式(6)进行求解。具体而言,考虑如下函数:
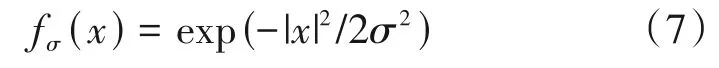
其满足:
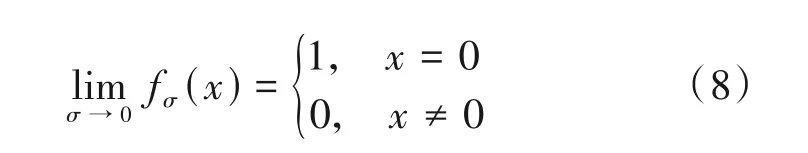
因此,假设sn为s的第n个元素,定义如下代价函数:
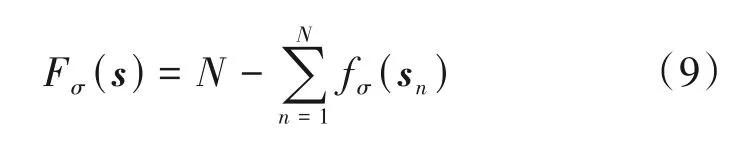
则式(6)可以转化为下式进行求解

逼近参数σ决定了Fσ(s)逼近L0范数的程度和平滑性:σ越小,则Fσ(s)越接近于L0 范数,但越不光滑,造成式(10)越难以求解。为了能够尽可能得到式(6)的最优解,SL0 算法采用一个σ的递减序列对式(10)进行求解,其具体过程如表1所示。

表1 SL0算法Tab.1 SL0 algorithm
对于SL0 算法,σ序列和μ序列均提前给定,一般情况下可令σ1=2max|s(0)|,σk=cσk-1,c=0.5~1,μ1=…=μK=μ>0。然而,固定的σ和μ并不能保证SL0 算法获得最好的收敛结果,不恰当的设置将会导致SL0算法估计精度下降、收敛速度变慢。
2.3 SL0数据流图
为了方便构建本文SL0-Net,如图1所示,将SL0算法的主要迭代步骤映射为一个数据流图,其主要由SL0算法所对应的不同节点和不同节点之间表示数据流动的有向边组成。数据流图的第k层表示SL0算法的第k次外层迭代,其包括2L个子层,即更新层和投影层。可以看出,SL0算法的K× 2L次迭代可以映射为一个K层的数据流图,输入的阵列接收数据将沿着此数据流图进行传递,获得DOA估计结果。
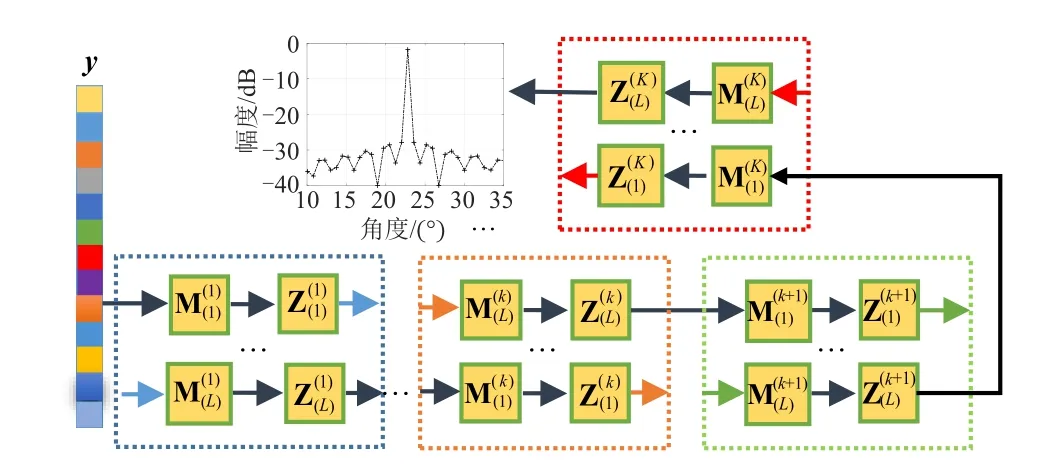
图1 SL0算法的数据流图Fig.1 The data flow graph of SL0 algorithm
3 基于SL0-Net的DOA估计
实际上,对于式(6)所示的SR 问题,当导向矢量字典A固定,且向量s服从一定的稀疏分布时,接收数据y也会服从一定的分布。此时,可假设存在一组最优的σ序列和μ序列,使得对于所有服从一定分布的数据,SL0算法均能够进行高效稀疏恢复。因此,为了解决SL0算法所存在的参数设置问题,结合模型驱动算法的可解释性和数据驱动深度学习方法的非线性拟合能力,本节基于SL0 算法的迭代步骤和数据流图,构建SL0-Net 网络,将其用于求解SR-DOA 模型。SL0-Net 主要包括更新层和投影层,网络参数为逼近参数σ和迭代步长μ。基于服从一定分布的训练数据对SL0-Net 进行训练,能够获得最优的σ序列和μ序列,提高DOA估计的性能。
下面,对SL0-Net 的网络结构、数据集构建、参数学习策略、初始化与训练方法四部分内容进行具体描述。
3.1 网络结构
根据表1 所示的算法步骤和图1 所示的数据流图,可以将SL0 算法等效为一个如图2 所示的K层网络,即SL0-Net,其输入为y、A和s(0),参数为{σ1,…,σK}和{μ1,…,μK},非线性激活函数为PL(·),输出为s(K)。其中,SL0-Net 的第k(k=1,2,…,K)层运算可表示为:
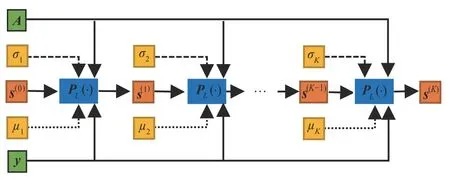
图2 SL0-Net网络结构Fig.2 The network structure of SL0-Net
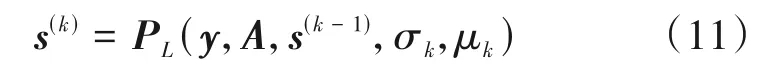
非线性激活函数PL(·)即为SL0 算法的内部循环(即表1中的步骤3),可以表示为一个L层的子网络,其输入为和μk,输出为第l层(l=1,2,…,L)的结构如图3所示,其主要包括更新层(蓝色框)和投影层(橙色框),具体描述如下。
图3 子网络P(L·)的第l层网络结构Fig.3 The structure of the l-th layer of sub-network P(L·)

3.2 数据集构建
本文所构建的SL0-Net 是一种“模型+数据”联合驱动的稀疏恢复方法,合理构建具有泛化能力的数据集是决定其有效性的关键。只有构建充足完备的数据集,SL0-Net 在训练过程中才不容易出现过拟合现象,从而获得较好的稀疏恢复性能。为了使得信号源的数量、DOA 和幅度以及阵列接收数据均具有一定的分布,本文按照“固定导向矢量字典A、随机产生具有一定分布的稀疏向量s、生成对应的阵列接收数据y”的方式构建数据集。具体而言:
1)给定阵元数M、阵元间隔d、波长λ、空间频率范围[fmin,fmax]和网格数N,根据式(4)构建导向矢量字典A;
2)产生Q个稀疏向量s作为训练标签集(即、O个稀疏向量s作为测试标签集(即,其中每个s的各个元素相互独立,服从伯努利分布,以概率P具有非零值,且非零元素的幅度服从复标准正态分布;

需要说明的是,由于在实际应用中噪声电平一般是未知的,因此本文在训练SL0-Net 的过程中,仅利用不含噪声的训练数据,在测试时则在数据中加入噪声以验证SL0-Net在不同SNR条件下的性能。
3.3 参数学习策略
所构建SL0-Net 的参数包括{σ1,…,σK}和{μ1,…,μK},为对它们进行优化,本文考虑两种网络参数学习策略,分别对应SL0-Net1和SL0-Net2。
(1)SL0-Net1
参考SL0 算法的参数设置,SL0-Net1令σk=cσk-1、μ1=…=μk,其中c为衰减因子。因此,该网络将仅对σ1、c和μ1三个参数进行学习,以获得较好的{σ1,…,σK}和{μ1,…,μK}。这种方式的优势在于网络学习参数较少,因此训练时间较短、陷入局部最优的概率较小,缺点在于网络的非线性拟合能力不足。
(2)SL0-Net2
SL0-Net2不再受限于σk=cσk-1和μ1=…=μk,而是对于每一层的σk和μk均进行学习,相应的网络学习参数个数为2K。这种学习策略的优势在于灵活性高,网络具有较高的非线性拟合能力,缺点在于网络容易陷入局部最优、训练时间较长。需要强调的是,由于包含的运算相同,因此在相同层数的条件下,经过训练的SL0-Net1 和SL0-Net2 在应用时将具有相同的运算复杂度。
3.4 初始化和训练方法
网络的初始化和训练方法对于SL0-Net 的性能具有一定的影响:较好的初始化和训练方法能够使得网络更容易达到收敛,在一定程度上避免陷入局部最优。
(1)初始化
为了使所提出的SL0-Net 网络适用于具有一定分布的所有阵列接收数据和稀疏向量,而不是仅对单一数据对有效,我们令网络的输入s(0)=0,且根据SL0 算法的典型参数设置,在SL0-Net1 中,按照的方式进行初始化,其中在SL0-Net2 中,按照的方式进行初始化。需要强调的是,与SL0 算法相比,SL0-Net 网络在初始化时避免了计算y=As的最小二乘范数解。因此,在迭代次数相同的情况下,SL0-Net网络的运算复杂度较低。
(2)训练方法
给定网络层数K和训练数据集,定义归一化均方误差(Normalized Mean Square Error,NMSE)为网络损失函数,表示为:

对于SL0-Net2,为了避免陷入局部最优,可利用逐层训练的方法对网络参数进行学习。具体而言,在对网络前k层进行训练获得的前提下,分两步对网络的前k+1层参数进行训练。首先,保持不变,利用后向传播算法求解如式(16)所示的优化问题学习网络的第k+1层参数Θk+1:


利用逐层训练的方法,从第1 层开始一直到第K层,即可学习得到SL0-Net2 的最优参数Θ*=
在对其网络参数进行学习优化后,即可将SL0-Net 应用于实际的DOA 估计之中。具体而言,对于新的阵列接收数据,可利用下式获得DOA估计结果:
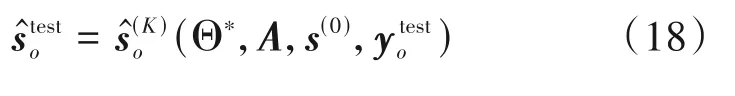
4 仿真实验
本节通过仿真实验对所提SL0-Net的DOA 估计性能进行验证,并与SL0 算法、OMP 算法和L1 范数最小化算法进行对比分析。其中,在不同仿真中均设阵元间隔d=λ/2、空间频率范围为[-1,1]、SL0 算法内部循环的次数和SL0-Net 子网络PL(·)的层数均为L=3。本文根据式(14)定义的NMSE 指标衡量不同算法的DOA 估计性能,所有仿真均基于MATLAB 2021a实现,平台为联想P920图形工作站,算法运行时间基于MATLAB的TIC和TOC命令获得。
4.1 DOA估计性能
首先,给定阵元数M=40、网格数N=161、稀疏概率P=0.01,验证SL0-Net 网络的DOA 估计性能及其相比其他算法的优势。
将SL0-Net 的网络层数设为K=10,根据3.2 节所述方法构建Q=10000 的不含噪声的训练数据集,利用Adam 算法(迭代次数为4000)对SL0-Net1和SL0-Net2 分别进行训练,可获得如表2 和表3 所示的网络参数优化结果。可以看出,两种参数学习策略得到的{σ1,…,σK}和{μ1,…,μK}均与SL0 算法的典型设置不同。特别是SL0-Net2,学习得到的参数不受σk=cσk-1和μ1=…=μk限制,具有更高的灵活性。在对网络进行训练后,构建O=1000 的不含噪声的测试数据集,分析比较SL0、SL0-Net1 和SL0-Net2 的DOA 估计性能。其中,SL0 算法的参数为:迭代次数K=10,对于每一测试数据。图4给出了SL0、SL0-Net1 和SL0-Net2 对四个测试样本进行处理所得到的DOA 估计结果。可以看出,在不同信号源数目的条件下,本文所提SL0-Net,特别是SL0-Net2,均能够获得相比SL0 算法更优的DOA 估计结果,SL0-Net的估计精度更高、旁瓣水平更低。

图4 SL0算法、SL0-Net1和SL0-Net2的DOA估计结果Fig.4 DOA estimation results obtained by SL0,SL0-Net1,and SL0-Net2
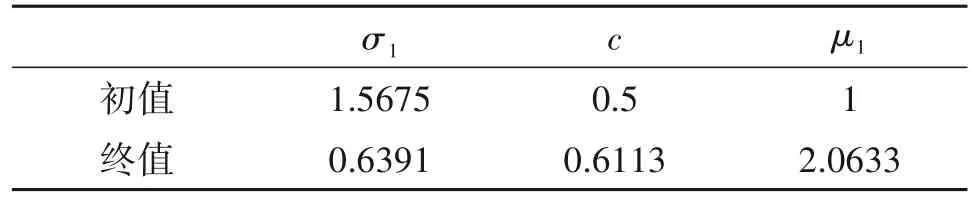
表2 SL0-Net1参数训练结果Tab.2 Parameter optimization results of SL0-Net1
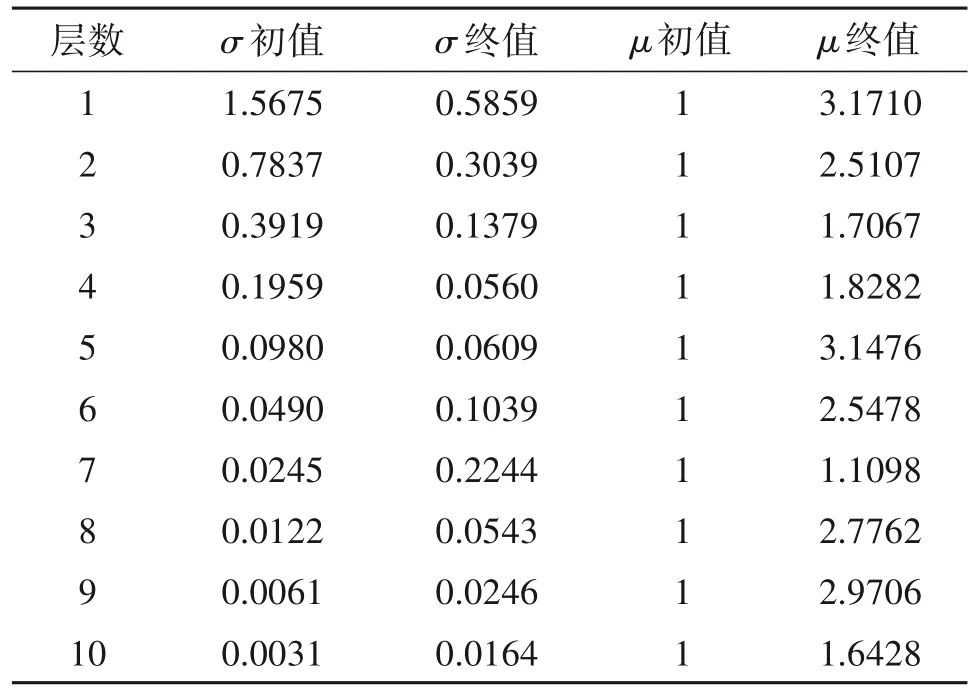
表3 SL0-Net2参数训练结果Tab.3 Parameter optimization results of SL0-Net2
图5给出了利用L1范数最小化算法、OMP 算法和所提SL0-Net2 对四个不同测试样本进行处理所得到的DOA 估计结果。由图5(a)和图5(c)可以看出,当信号源角度间隔较大且信号源个数已知时,L1 算法和OMP 算法相比所提方法性能较优。由图5(b)可以看出,当信号源角度间隔较小时,所提SL0-Net2 能够更容易分辨出不同的信号源,相比L1算法和OMP 算法具有更高的角度分辨率。由图5(d)可以看出,当信号源个数未知时,OMP 算法容易丢失信号源(该样本所包含的信号源个数为4,OMP 算法的迭代次数设为3)。进一步的,表4 给出了利用不同算法对所有测试样本(O=1000)进行处理所需要的运行时间和所得到的DOA 估计误差,其中OMP 算法的迭代次数按照不同测试样本所包含的信号源个数进行设置。可以看出,所提SL0-Net的DOA 估计性能仅次于L1 算法,运行时间仅次于OMP 算法。因此,相比于L1 算法、OMP 算法和SL0算法,SL0-Net 更适于实际环境中信号源个数未知条件下的快速高分辨DOA估计。
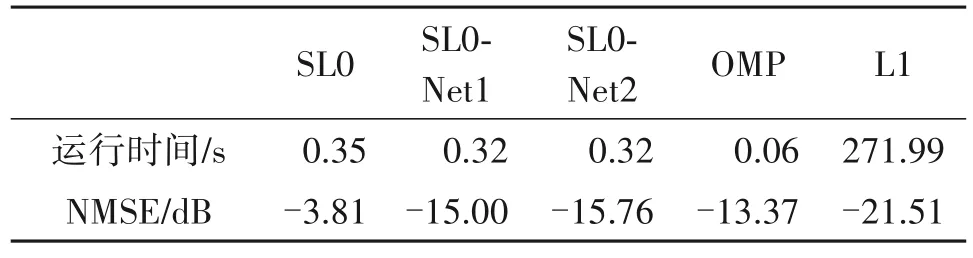
表4 不同算法DOA估计的运行时间和归一化均方根误差Tab.4 Running time and NMSEs of different algorithms
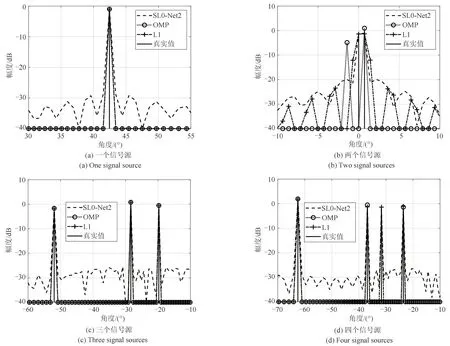
图5 L1算法、OMP算法和SL0-Net2的DOA估计结果Fig.5 DOA estimation results obtained by L1,OMP,and SL0-Net2
4.2 SL0-Net分析
本小节对SL0-Net的DOA 估计性能与网络层数K、稀疏概率P、网格数N、信噪比SNR 的关系进行分析。由于SL0-Net2 相比SL0-Net1 具有更优的性能,下面仅对SL0-Net2进行分析。
传统蒽环类药物目前依然广泛地用于治疗各种恶性肿瘤,但其骨髓抑制和心脏毒性等不良反应严重限制了临床应用。脂质体阿霉素的心脏毒性、骨髓抑制、脱发等不良反应较传统蒽环类药物显著降低,能否取代传统蒽环类药物有待进行更多、更大规模的临床研究加以验证。
首先,给定阵元数M=20/30/40、网格数N=161、稀疏概率P=0.01,生成不含噪声的测试数据,验证SL0-Net 网络性能与网络层数K之间的关系,所得结果如图6所示。可以看出,随着网络层数的增加,SL0-Net 的NMSE 逐渐减少,DOA 估计性能不断提高,且均优于SL0 算法。由于SL0 算法的参数固定,过多的迭代次数并不能显著提高其DOA 估计性能。相比之下,所提SL0-Net 网络的可学习参数随着网络层数的增加而增多,通过训练优化,可以获得更优的性能。此外,随着阵元数的增加,SL0算法和SL0-Net 网络的DOA 估计性能也相应提高。相比SL0 算法,为获得相近的DOA 估计性能,所提SL0-Net所需要的网络层数和阵元数更少。
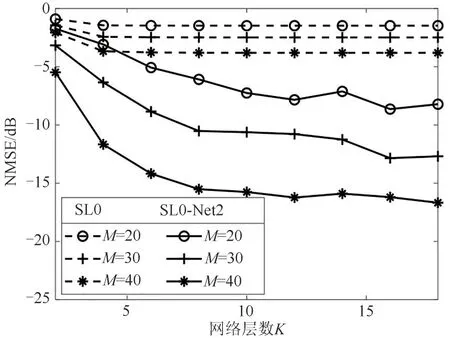
图6 NMSE与网络层数K的关系Fig.6 NMSE versus the network layer number K
接着,给定阵元数M=20/30/40、网格数N=161、网络层数K=10,生成不含噪声的测试数据,验证SL0-Net 网络性能与稀疏概率P之间的关系,所得结果如图7 所示。可以看出,在不同稀疏概率的情况下,所提SL0-Net 网络的DOA 估计性能均优于SL0 算法。因此,相比SL0 算法,在其他条件相同的情况下,所提SL0-Net 网络能够对更多信号源进行DOA 估计。但是,随着稀疏概率的增加,两种算法的NMSE 均逐渐增加,DOA 估计性能变差。这是因为在阵元数一定的情况下,信号源个数越少,稀疏恢复的性能越优,反之则越差。
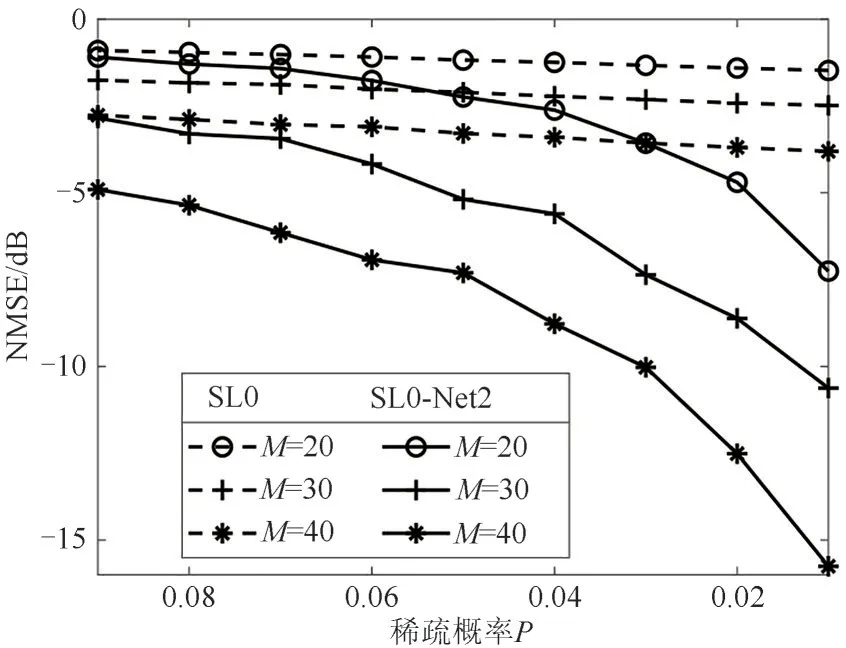
图7 NMSE与稀疏概率P的关系Fig.7 NMSE versus the sparse probability P
然后,给定阵元数M=20/30/40、稀疏概率P=0.01、网络层数K=10,生成不含噪声的测试数据,验证SL0-Net网络的性能与网格数N(对应角度分辨率)之间的关系,所得结果如图8 所示。可以看出,在不同网络数的情况下,所提SL0-Net 的DOA 估计性能均优于SL0 算法。因此,相比SL0 算法,在其他条件相同的情况下,所提SL0-Net 网络能够获得更高的角度分辨率。但是,随着网格数的增加(即可能的信号源角度间隔减小),两种算法的NMSE均逐渐增加,DOA 估计性能变差。这是因为在阵元数一定的情况下,多个信号源之间的角度越接近,稀疏恢复的性能越差,反之则越优。

图8 NMSE与网格数N的关系Fig.8 NMSE versus the grid number N
最后,给定阵元数M=20/30/40、网格数N=161、稀疏概率P=0.01、网络层数K=10,生成具有不同SNR 的测试数据,验证SL0-Net 网络的性能与阵列接收数据信噪比之间的关系,所得结果如图9所示。可以看出,虽然SL0 和SL0-Net 在SNR 小于10 dB 时性能均较差,但当SNR 大于10 dB 后,SL0-Net 的DOA 估计性能均优于SL0 算法。因此,在其他条件相同的条件下,SL0-Net 具有更高的噪声鲁棒性。此外,当SNR >20 dB,SL0-Net 的DOA 估计NMSE 趋于稳定,且接近于无噪声情况下获得的结果。这意味着,即使利用无噪声数据进行网络训练,SL0-Net 依然能够获得较好的参数结果,能够对含噪声的实际阵列接收数据进行DOA估计。
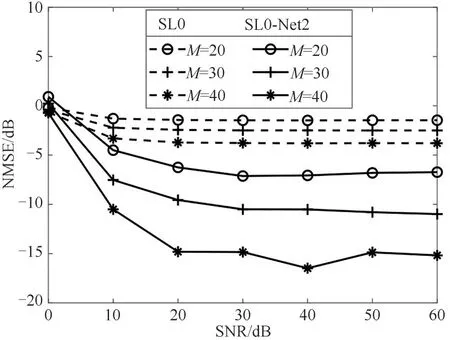
图9 NMSE与信噪比的关系Fig.9 NMSE versus SNR
5 结论
针对单快拍DOA 估计问题,本文在建立信号模型和对SL0 算法进行分析的基础上,提出了模型和数据联合驱动的SL0-Net 方法,对其网络结构、数据集构建、参数学习策略、初始化与训练方法等内容进行了详细介绍,并通过不同的仿真实验对其性能进行了验证。仿真结果表明,所提SL0-Net相比SL0算法具有更高的DOA 估计性能,且具有更低的运算复杂度。在其他条件相同的条件下,相比SL0算法,SL0-Net 所需的迭代次数和阵元数更少,能够对更多的信号源进行DOA 估计,且具有更高的分辨率和噪声鲁棒性。与L1 范数最小化算法和OMP 算法相比,SL0-Net 在信号源数目未知的条件下,能够快速获得高分辨DOA 估计结果。考虑到实际应用中不可避免地存在阵列误差,因此下一步将对误差条件下SL0-Net 的改进方法进行深入研究,并将其应用于实际数据的处理之中。
