基于聚类分析的大学生体质异常数据提取方法
2022-11-11朱春
朱 春
(芜湖职业技术学院 体育教学部,安徽 芜湖241003)
随着现代社会的发展,高校尤其重视大学生的体质测试。对体质测试的数据加以分析[1]能够有效得到大学生体质问题的信息,在未来阶段对大学生定制相应的教学方案[2],因此,对于体质测试的数据研究工作十分重要,但对于现阶段高校的教学工作者来说,对这些数据的采集、整理与分析[3]仅能通过教师手动上传,对于海量体质测试数据[4-6],教师无法全部精准快速地整理与汇总,无法高效地提取体质异常数据。
为此,相关学者对大学生体质异常数据提取方法进行了研究,取得了一定的进展。文献[7]基于改进平均影响值对遗传数据疾病进行分类并提取疾病数据特征。构建遗传病数据的logistic回归模型,利用多层感知技术对SVM训练器进行改进,实现遗传病特征分类,通过平均影响值实现疾病数据特征提取。但是,此方法特征提取覆盖率较低。文献[8]提出高斯核密度估计的人体健康数据异常值检测方法,利用t-分布邻域嵌入算法进行稳定性特征提取,利用GKDELOF法实现健康异常值检测。该方法可以更好解决大学生多样性体质差异导致数据产生稀疏性现象,但是在对异常数据提取方面存在提取速度较慢的问题。而聚类方法是一种能够依据数据本身的属性进行分区的技术,使同一簇内的数据越小越好,不同簇内的数据越大越好,即满足聚类的过程。针对数据采取聚类分析能够使复杂结构的数据变得统一化,使数据提取过程更加简便。因此,本研究基于聚类分析的大学生体质异常数据提取方法,通过Relief算法调整特征的距离,利用K-means算法获取所提取的大学生体质异常数据。
1 基于聚类分析的大学生体质异常数据提取方法
1.1 基于Relief算法的相关特征筛选
通过对大学生体质正常数据以及其中的异常数据两部分数据进行研究。根据时间将两种数据构建链接,并进行数据清洗,之后进行数据挖掘[9]。在数据清洗过程中,主要包含两部分检查,分别是对空值与无效值的检查,并删除存在两者的数据。当链接建立后,有效去除了信息冗余数值,这是由于数据的数量与维度都存在各种形式的不同,通过公式(1)描述归一化形式:
(1)
公式(1)中,异常数据的样本值由x描述,样本的最大值由xmax描述,样本的最小值由xmin描述,最终归一化处理的数据形式由q描述。
对处理后的数据进行特征选择,即将归一化后的数据进行“降维”。选取Relief算法,调整特征的距离,将不相似的样本隔开,将类似的样本靠近,即分类的成果受特征影响较大时,则将该特征的权重提升。该算法在进行特征选择时,能够依据数据的统计特性,提升特征选择的速度并降低开销,更适用于大数据集。在最终计算时,能够获取每个特征相应的权重,该特征的相关性与权重相关。为获取相关特征子集,可以依据给定权重阈值,使权重小于该阈值的特征得到筛选。该算法对各式特征权重阈值进行了给定,以获取各式的特征子集,以使下一步聚类分析更加方便,并对最终聚类受到各式特征权重阈值的改变进行了分析。

图1 大学生体质全部数据形式
1.2 聚类分析
在对大学生体质数据进行管理时,当出现异常数据时,仅通过一条异常信息很难准确判断异常数据的特征。因此,聚合相似异常情况的数据,将单条信息汇集为一类信息,以使得异常数据的特征能够有效地表示出来。
将数据划分为两大类别,分别为正常数据与异常数据,由于大学生体质异常的情况存在不同形式,因此在异常数据中,还划分了3类范围更小的数据集。并通过N1描述正常数据,异常数据中的数据集,分别由A1、A2、A3描述,如图1所示。由于A1与正常数据更为接近,能够较快发现正常数据与异常数据的区别,因此,在剖析阈值时,首先采集类簇A1,通过该种形式,不仅能够明显划分两类数据,还能够将更小的类簇挖掘出来,并在异常数据中实现更为细化的聚类。采用K-means算法进行聚类,该算法依据距离进行计算,且计算过程简便、速度更快,同时还能够给定各式的k值,使最终聚类结果不同[15]。为挖掘更小的类簇,可以采取修改k值的形式,但该算法在挑选初始点与干扰数据时较为细致,当目标函数未发生变化或不大于某个所设阈值时,该算法即结束。通过公式(2)描述目标函数:
(2)
公式(2)中,第i个簇的质心由ci描述;在簇ci内,质心与样本x的间隔由dist(ci,x)描述;所给定的聚类数量由k描述。
1.3 改进的K-means聚类算法
由于K值的选取受用户主观意向影响,具备随机性,为此,对K-means算法的所选取的K值进行改进。
1.3.1 改进K值的选取
依据K-means的聚类结果,对如下两部分总统计量进行计算,分别是总X值与V值。其中,全部聚类变量的离差平方和之和,用X表示,即采用公式(3)进行计算:
(3)
公式(3)中,第i个簇由ci描述;ci中的点由x描述;第i个簇的均值通过ci表示;两个对象的间距由dist表示。
在不同类别之间,聚类变量离差平方和之和,通过V描述,并采用公式(4)进行计算:
(4)

图2 K值选取流程图
公式(4)中,簇的大小用mi表示,第i个簇的均值用ci表示,总均值用c描述,dist的含义与上述一致。当K值已知时(该值代表聚类数量),该聚类算法设想拥有较小的总X值与更大的总V值,表示其组内数据拥有较高的聚集能力,组间数据拥有较好的分割性能,即拥有总V/总X的值越高,性能越强。
为使最终计算结果不被样本n以及聚类数量K改变,将总V/总X计算形式调整为公式(5):
(5)
公式(5)中,复杂性由(n-k)/(k-1)描述,其比率越高越优秀,该公式为Calinski-Harabasz公式,具有运算效率高等特点,因此采用该公式来确定最终的适应K值。
1.3.2 选取K值的流程
选取K值的过程如图2所示。依据枚举方式,依次对K值进行设定,分别为2~10,并反复进行1 000次操作,以防止局部最优解现象发生,并对K值的Calinski-Harabasz值形式进行计算,最终取Calinski-Harabasz值中最大形式相应的K值作为最后所选取的K值。
2 实验分析
为验证研究中所提出方法的可行性,将其应用于某高校大学生某次体质测验中,对该次体质测验中的数据进行分析,并选取文献[7]基于平均影响值的特征提取方法与文献[8]高斯核密度估计异常值提取方法作为对比方法对男生女生的标准差与平均数进行分析,通过SPSS内ONEWAY模块对此进行验证,并在计算机内采用SPSS FOR WINDOWS6.0操作所有数据。

表1 男女生的平均数与标准差检验
根据表1可知,所提方法对大学生体质中的异常数据提取较为清晰,根据标准差可知所提方法所提取的体质数据中的范围。分析3种方法在异常数据提取过程中的准确率与误报率,分析结果如表2所示。

表2 不同方法提取的准确率与误报率
根据表2可知,文献[7]的方法方法的提取数据准确率最低,为86.78%,但该方法的误报率要小于文献[8]的方法,文献[8]的方法具有最高的数据提取误报率,为17.70%,而所提方法的准确率一直保持最高,且误报率同时保持最低,因此选取研究中所提方法能够有效减少误报的发生,具有更高的异常数据提取准确度。

图3 不同方法异常数据提取覆盖率
分析在不同体质数据量下对异常数据提取的覆盖率,并通过两种对比方法进行对比,分析结果如图3所示。根据图3可知,随着数据量的增多,对异常数据提取覆盖率逐渐下降,文献[7]的方法最低覆盖率仅为62%,在3种方法中的覆盖率最低,而文献[7]方法的覆盖率高于文献[8]的方法,该方法在数据量为500个时,覆盖率为86%,当数据量达到4 000个时,该方法的覆盖率为74%,但依然低于研究中所提方法的覆盖率,研究中所提方法的覆盖率最高为94%~89%,因此,研究中所提方法的异常数据提取效果最好较高。
分析3种方法在不同数据量下对异常数据提取的内存开销,分析结果如图4所示。根据图4可知,随着数据量的增长,3种方法在异常数据提取过程中内存开销逐渐增加,且上升趋势较为稳定,3种方法在数据量较少时,内存开销均未有较大差别,都保持在4.0~5.0 kB之间,其中文献[8]的方法在提取过程中所占据的内存开销最高,在数据量为4 000个时内存开销达到8.5 kB,而文献[7]的方法的最高内存开销为7.5~8.0 kB之间,而研究中所提方法随着数据量的提升,最高内存开销仅达到5.6~6.0 kB之间,因此,采用此方法进行异常数据提取,能够有效降低内存开销。
分析不同方法在提取异常数据时的时间开销,分析结果如图5表示。

图4 不同方法的内存开销
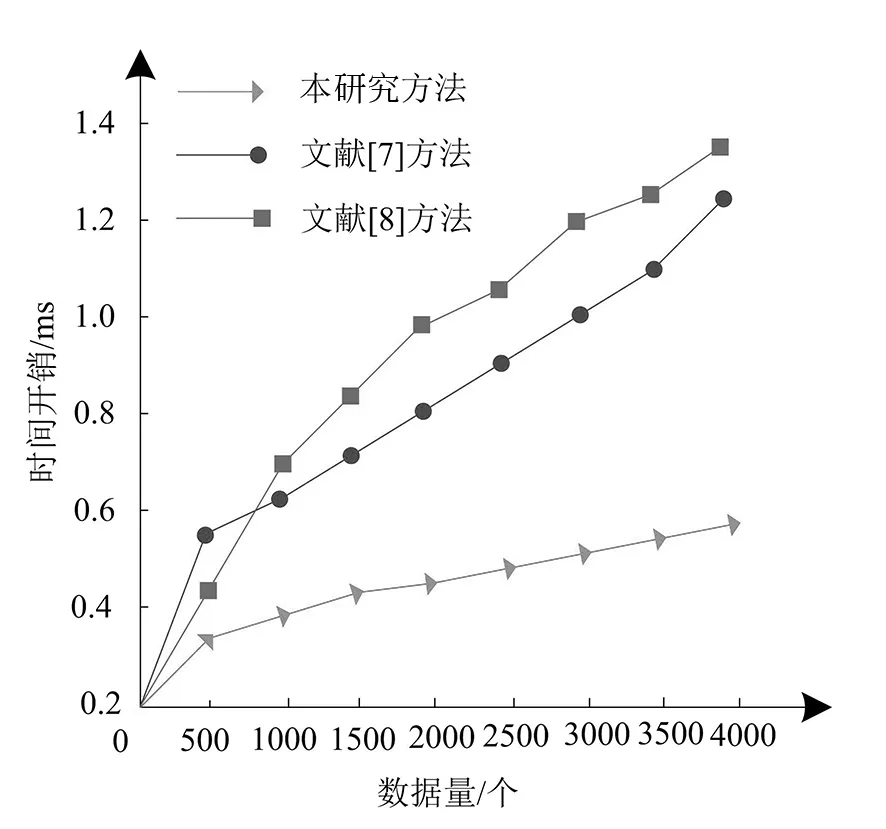
图5 提取异常数据时的时间开销
根据图5可知,随着数据量的增长,3种方法在提取异常数据时的时间开销也逐步提升,文献[8]在数据量为4 000个时时间开销最高,而在数据量为500个时,文献[7]的时间开销最高,当数据量达到1 000个时,文献[8]的时间开销提升较快,成为3种方法中最耗时的方法,研究中所提方法时间开销量增加较为稳定,数据量由0增加到4 000个时,时间开销始终控制在0.5 ms以内,始终保持最低的时间开销,采用此方法能够有效降低异常数据提取的时间。

图6 异常数据提取数量
选取该高校中5种类别的体质数据作为测量大学生体质的项目,每个项目中包含800个数据量,从中分析文中所提方法对异常数据的提取数量,分析结果如图6所示。根据图6可知,经研究中所提方法所提取的异常数据量,在800 m/1 000 m跑的大学生体质异常数据最高,在全部800个数据中占375个,座位体前屈占比最少,具体有175条异常数据,说明较多大学生的体质测试中800 m/1 000 m跑中容易产生异常数据,实验结果显示,所提方法可有效获取高校中大学生体质异常数据,可为相关教师提供数据支撑,以便后续开展针对性提升策略。
3 结语
基于聚类分析的大学生体质异常数据提取方法,通过Relief算法筛选体质异常数据冗余特征值,通过Calinski-Harabasz公式获取的设定K值,最终获取最佳聚类结果实现异常数据的提取。在未来阶段,可以此为基础继续加深研究,通过聚类方法实现大学生体质异常数据更加精准细致的提取过程。
