工作流网频繁子网挖掘研究进展①
2022-11-06张书涵费超群黄锡昆李阳阳
张书涵 费超群 黄锡昆* 李阳阳
(*中国科学院计算技术研究所智能信息处理重点实验室 北京100190)
(**中国科学院数学与系统科学研究院管理、决策与信息系统重点实验室 北京100190)
(***中国科学院大学 北京100049)
0 引言
工作流网频繁子网挖掘是指以工作流网为输入,分析工作流网中频繁出现的子结构(子模式),发现数据的内在规律,使其能够为工业上了解、优化、应用数据提供重要信息的一类问题[1]。随着网络技术飞速发展,工作流网已经成为刻画业务执行逻辑的主要形式[2],被广泛用于网络交易系统、业务流程管理等应用场景的建模和分析中[3]。
当前工作流网频繁子网挖掘研究在新型应用场景下面临着诸多挑战。例如,在业务流程管理领域,存在大量重复出现、高度可重用的子流程[4],尤其是近年来,在跨组织工作流网挖掘的场景下存在许多子网变体[5]。变体的存在使得工作流网频繁子网变得多种多样、纷繁复杂,缺乏通用性。
按照输入数据类型进行划分,工作流网频繁子网挖掘相关研究分为两大主流方向。其一,从一维的日志进程序列中实施进程挖掘,构造出工作流网及其子网[6-7]。如何更高效地从日志中抽取、发现工作流网及其子网,是当前研究的热点问题[8-13]。另外,从二维的工作流网中挖掘其频繁的子网结构[1,14]。相关工作大多采用频繁模式挖掘(frequent pattern mining,FPM)相关方法进行求解。由于工作流网中大量存在的选择、循环、并发等复杂模式及其特殊的语义约束,在工作流网上进行频繁子网挖掘比传统的FPM 问题更加复杂[15]。
本文基于频繁模式挖掘的相关方法,总结了目前工作流网频繁子网挖掘所取得的研究成果。详细分析了将传统FPM 用于工作流网频繁子网挖掘存在的问题及挑战,分析了基于工作流网进行频繁子网挖掘与基于一般图进行频繁子图挖掘的本质区别。本文的主要贡献包括以下几个方面。
(1) 针对输入是一维日志序列的情形,研究方法分为基于过程式模式检测、基于日志转换和基于声明式规则检测3 类方法,本文给出了各代表性方法,总结了优缺点。
(2) 针对输入输出均是二维工作流网的情形,研究方法分为基于工作流网转换、基于序列与网混合式两类方法,本文给出了各代表性方法,总结了优缺点。
(3) 从理论上分析了传统频繁模式挖掘方法在工作流网频繁子网挖掘问题中的不适用情况及其根本原因,总结了工作流网频繁子网挖掘与频繁子图挖掘的本质区别。
本文剩余部分组织结构如下。第1 节简要介绍相关的频繁模式挖掘方法;第2 节给出工作流网频繁子网挖掘相关研究的两大主流方向,包括基于一维日志进程构造工作流网及其子网的研究方法和基于工作流网的频繁子网挖掘研究方法;第3 节分析将传统FPM 用于工作流网频繁子网挖掘存在的问题及挑战;第4 节列举分析了工作流网频繁子网挖掘中的几种典型应用;第5 节总结了工作流网频繁子网挖掘技术的发展趋势及存在的挑战。
1 频繁模式挖掘
为了具体阐述工作流网频繁子网挖掘相关研究方向的分类,本节针对其使用的传统频繁模式挖掘方法进行梳理,详见图1。频繁模式挖掘是数据挖掘中重要的研究问题,从最初的分析顾客购买记录到近几年用于进程挖掘,FPM 一直有着十分广泛的应用[8,10,16-19]。依据不同的数据类型,相关方法分为频繁项挖掘、序列模式挖掘和频繁子图挖掘。
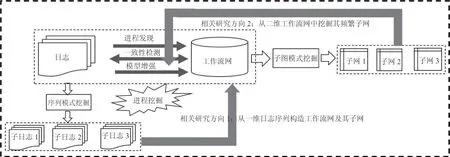
图1 工作流网频繁子网挖掘研究方向分类
1.1 频繁项挖掘
频繁项挖掘(frequent itemset mining,FIM)问题提出之初旨在分析购物车中经常被一起购买的物品,得到顾客的购买习惯,为商店提供决策服务[20]。FIM 问题的首个解决算法是Apriori 算法[21],其核心在于向下反单调性的保障,即如果一个项集不频繁,那么它的超集必定不频繁;反之,如果一个项集是频繁的,那么它的子集必定是频繁的。该性质可用偏序≼表示,即给定任意模式p1及p2,如果p1≼p2且p2为频繁的,则p1也是频繁的。向下反单调性是指导FPM 及工作流网频繁子网挖掘的关键理论支撑。利用该性质,可以大大减小搜索空间。作为FPM 最经典的算法框架,Apriori 具有良好的可扩展性。近年来,高性能计算、硬件加速等新技术被融合至Apriori算法。目前,已有数百个后续改进工作[22-28]。
1.2 序列模式挖掘
序列数据库由有序元素或事件组成,典型的序列数据包括顾客购物序列、DNA 序列、时间序列等[16,29-36]。随着数据类型的多样化,序列模式挖掘(sequential pattern mining,SPM)算法处理的对象也越来越复杂。首个处理SPM 问题的算法为广义序列模式(generalized sequential pattern,GSP)挖掘算法[16]。GSP 遵循逐层遍历的方式,但候选集的生成十分耗时。参考FP-Growth 算法[37]提出的模式增长计算方式,Jian 等人[38]提出了PrefixSpan 算法,以深度优先遍历的方法计算候选子序列的支持度。此外,PrefixSpan 利用向下反单调性提出了一种有效的剪枝策略,减小搜索空间。随着序列数据维度及类型的复杂化,许多约束被融合到SPM 问题的解决算法中。例如,Pex-Spam 算法使用的时间间隔约束[39],MaxSP 算法使用的长度约束[40]等。
1.3 频繁子图挖掘
作为数据结构中最为复杂的一种,图结构广泛应用于生物数据分析、社交网络分析等实际问题的数据建模中[41-45]。Cook 和Holder[46]提出频繁子图挖掘(frequent subgraph mining,FSM)问题,旨在从给定的图集中抽取出频次大于一定阈值的子图。
首个解决FSM 问题的算法是基于Apriori 的图挖掘(Apriori-based graph mining,AGM)算法[47],采取逐层两两连接的方式。如图2(a)所示,大小为k的所有频繁子图连接生成大小为(k +1) 的候选子图,利用向下反单调性删除候选子图中的非频繁子图。AGM 类方法代表性的工作包括AGM/AcGM 算法[47]、FSG 算法[48]、Path-Join 算法[49]等,但不足之处是生成大量的候选集,需要耗费大量的内存。
基于以上不足,基于模式扩充的方法特点是在k级频繁子图p的基础上,每次扩展一条边,生成p的超图模式,然后计算支持度得到(k +1) 级频繁子图。从每个(k +1) 级频繁子图开始继续扩展,直到无法再扩展为止。此方法是一种全内存的计算,工作机制如图2(b)所示,代表工作包括gSpan算法[44]、GASTON 算法[50]、SPIN 算法[51]等。

图2 频繁子图挖掘两种主要方法
2 工作流网频繁子网挖掘
按照输入数据类型进行划分,工作流网频繁子网挖掘相关研究分为两大主流方向。其一,从一维的日志进程序列中实施进程挖掘,构造出工作流网及其子网[6,7]。另外,从二维的工作流网中挖掘其频繁的子网结构[1,14]。
2.1 基于一维日志进程构造工作流网及其子网
进程挖掘在文献[52]中被提出,IBM 艾曼登研究中心将进程发现思想引入业务过程管理中[53]。进程挖掘旨在以大规模日志为原始输入,从中抽取系统运行过程,通常以工作流网的形式呈现。随着业务流程管理系统的兴起,日志信息日益丰富,进程挖掘方法的重要性逐步提升[6,7,54-56]。当前,进程挖掘任务分为3 种类型,即进程发现、一致性检测和模型增强,如图1 所示。而每种任务要解决的核心问题是确保模型能够“重演”。进程发现问题主要采用基于规则匹配的方法[55]进行求解。一致性检测问题主要采用分解日志的方法进行对齐计算[57]。模型增强问题关注日志中时间、资源等组织信息的提取。
由于进程挖掘和序列模式挖掘具备问题的相似性,已有许多SPM 方法被用于进程挖掘中[8-11,58-62]。
目前,日志中包含的关系可分为两类:
(1)控制流依赖关系,即日志中包含的所有活动都遵循一定的次序,例如直接依赖、选择、并发关系。
(2)声明式约束,即日志中的活动可用时态逻辑描述,如发生的情况最终一定会发生。
根据日志关系类型划分,基于进程挖掘构造工作流网及其子网的研究方法可分为基于过程式模型检测、基于日志转换和基于声明式检测的方法。
2.1.1 基于过程式模型检测的方法
定义1 过程式模型检测问题[55]
给定一组活动集合A,由一系列活动组成的非空序列称为工作流执行轨迹σ∈A*,轨迹的多重集合表示为日志L∈B(A*),其中B(A*) 表示A*的幂集。过程式模型是指事件次序与日志中的活动次序保持一致,如顺序模式、并行分支模式、同步模式等。过程式模型检测问题是指将日志转化为端到端过程模式的过程。
表1列举了过程式模型检测任务清单,各任务均是以序列模式挖掘方法为解决方案。其中,最具代表性的任务为频繁子片段(episode)挖掘问题。
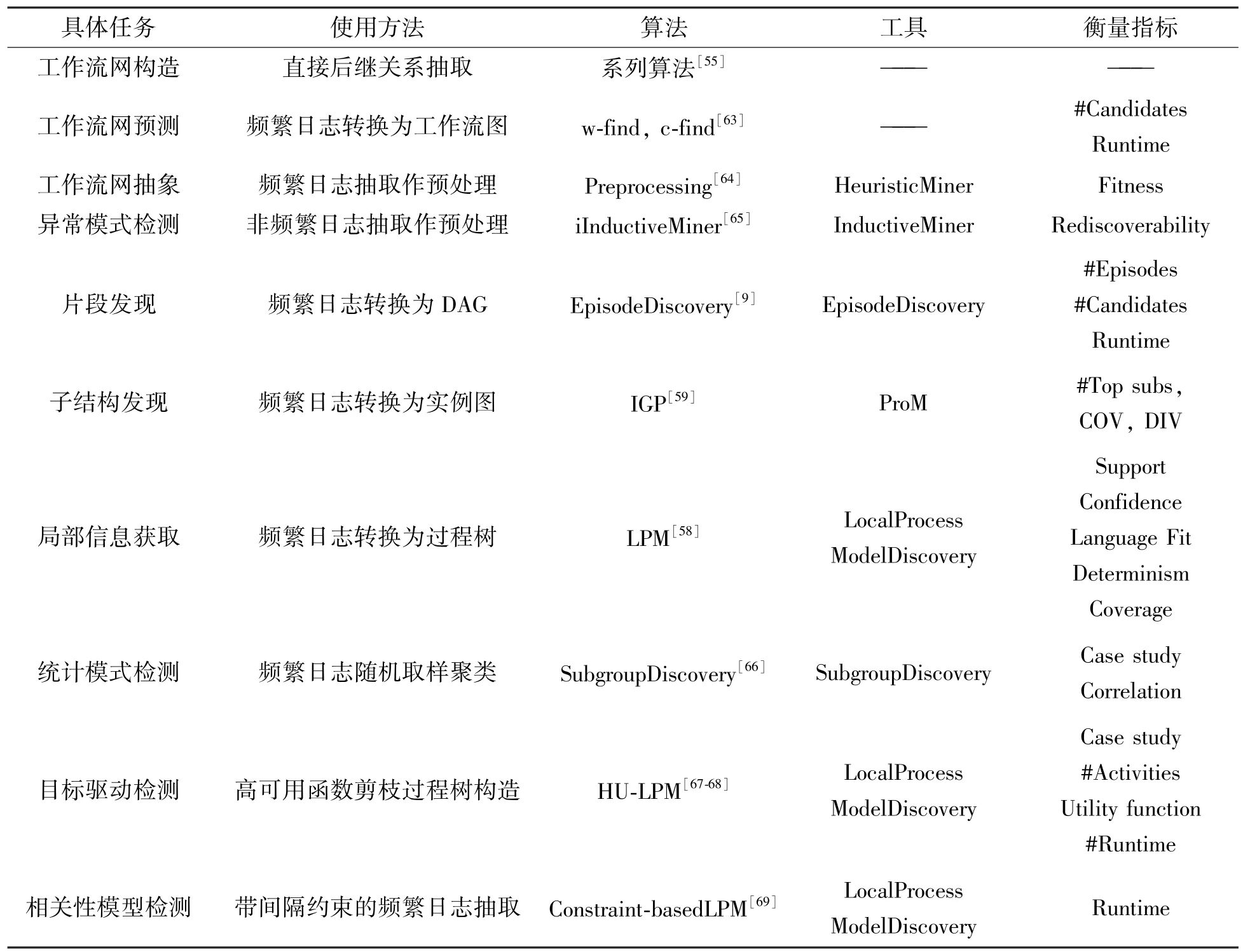
表1 过程式模型检测问题任务清单
定义2 片段,子片段[9]
片段为事件的偏序集合,表示为三元组α=<V,≤,g >,其中V为一组事件的集合,≤为定义在V上的偏序关系集合,g:V→A为事件和活动之间的对应函数。存在另一个片段β=<V′,≤′,g′ >是α的子片段,记作β≼α,当且仅当存在内射函数f:V′→V,使得以下2 个条件同时满足:
(1) ∀v∈V′:g′(v)=g(f(v)),即β中的所有节点都出现在α中;
(2) ∀v,w∈V′∧v≤′w:f(v) ≤f(w),即β中的所有边都出现在α中。
片段使用有向无环图(directed acyclic graph,DAG)进行表示,DAG 中的节点代表事件(出现在日志的活动集合中),DAG 中的边代表事件之间存在偏序关系。如图3 所示为3 个片段,其中E1表示事件A(D)与事件B(E)并发执行,事件C 只能在事件A 和B 发生之后执行;E2表示事件A 执行后有事件B 和事件C 两种选择,而事件B 执行后D 才能执行,或者事件C 执行后D 才能执行;E3表示,事件A和B 并发执行,其中A 和B 之间没有连边。

图3 片段示例
定义3 频繁子片段挖掘问题[9]
片段α=<V,≤,g >在工作流执行轨迹σ=<a1,a2,…,an >中出现,记作α⊆σ,当且仅当存在一个内射函数h:V→{1,…,n},使得以下2 个条件同时满足:
(1) ∀v∈V:g(v)=ah(v)∈σ成立,即片段中的事件与日志中的活动一致;
(2) ∀v,w∈V∧v≤w:h(v)≤h(w),即片段中事件之间的偏序关系与日志中活动间的次序一致。
片段α在日志L∈B(A*)中出现的频率定义为

表示片段中的偏序关系在日志中出现的次数。片段发现问题旨在从事件日志中找到所有满足freq(α) 大于等于给定阈值的片段。
2.1.2 基于日志转换的方法
求解过程式模型检测问题,通常采用基于转换的方法,即将频繁日志转换为图/树模式。(1)工作流图是最早提出的频繁日志的转换对象[53],它的特点是不能识别工作流中的AND/OR 汇集结构和分支结构。因此,工作流图只能用来表示不包含OR结构的工作流网。(2)有向无环图(directed acyclic graphs,DAG)是最常用的转换表示[9]。然而目前,DAG 只能表示频繁日志中的顺序和并发模式,对于日志中出现的选择、循环等复杂结构仍不能检测。(3)实例图常用于聚类,实施步骤为首先将每条频繁日志转换为实例图,然后运行图聚类算法[59]。与DAG 类似,实例图也仅能表示频繁日志中的顺序和并发模式。(4)过程树是一种直观的树型结构,树中的叶子节点代表日志中的活动,分支节点代表活动之间的关系[70]。使用过程树构造Petri 网的步骤是,首先从频繁日志中提取过程树,然后根据6 种预设规则,将过程树转换为可靠的(也称为良构的)端到端过程模型。与前几种表示不同,基于过程树的方法不仅支持基本的控制流模式,还可表示复杂的选择、循环等结构。
2.1.3 基于声明式规则检测的方法
近年来,由进程挖掘中的进程发现任务衍生出了另一项具有挑战性的任务——声明式规则发现(declarative rule discovery)[71],是指从日志中提取一系列符合时态逻辑规则的任务,又称约束发现。已往的进程挖掘中的进程发现任务,只能得到结构化(structured)的工作流网,而声明式规则是一种弱结构化(less-structured)的表示形式,是对进程挖掘任务的补充。
定义4 声明式规则发现[72]
给定活动集合A={a1,a2,…,am} 和一条日志L={t1,t2,…,tn},其中tq(1 ≤q≤n) 表示一条取值于A的有限活动记录。声明式规则挖掘旨在从日志中抽取满足时态逻辑关系的一系列约束。其中,约束由以下3 部分组成。
(1)取值于A的活动。
(2)活动之间的布尔型连接关系,包括非(¬)、与(∧)、或(∨)、蕴含(⇒)、等价(⇔)。
(3)基于有限序列的线性时态逻辑(linear temporal logic on finite traces,LTLf)算子,包括必然算子(□)、可能算子(◇)、直到算子(∪)、下一时刻算子(○)。
例1给定活动集合A={S,A} 和日志t=其中1,2,… 代表活动在日志中的下标。日志t中包含一条声明式规则RESPONSE(S,A),其含义为□(S⇒◇(A)),S发生时都有A跟随发生。
日志t中规则RESPONSE(S,A) 的实例为{S1A1},{S2A1},{S3A1},{S4A2},{S5A3},{S6A3}。
在声明式规则发现任务中,仍然是以日志作为主要输入数据类型。但不同的是,关注日志的视角和粒度与传统进程挖掘不同。日志中记录着大量已经发生的活动(也称事件、案例、任务)以及活动间的逻辑依赖关系。这些依赖关系是联系日志与进程模型、日志与Declare 规则之间的重要纽带[73]。作为常用的数据预处理方法,FIM 方法首先针对日志中大量的活动进行初步过滤,然后提取活动之间的依赖关系。FIM 问题与声明式挖掘问题的数据类型有着密不可分的联系,如表2 所示。表3 列举了声明式规则检测问题任务清单。

表2 频繁项挖掘与声明式规则挖掘对比

表3 声明式规则检测问题任务清单
2.2 基于二维工作流网挖掘频繁子网
定义5 频繁工作流网子网挖掘
给定工作流网集W={w1,w2,…,wT},子网x的支持度定义为包含它的工作流网占比

频繁工作流子网挖掘旨在从工作流网集中挖掘得到子网/片段,以供工作流网重用、设计。工作流网频繁子网挖掘的相关研究重点关注以下两方面问题。
(1)工作流网标签一致性。工作流网的标签往往使用WordNet 进行统一规范,标签有固定的语法形式,即动词+宾语,例如检查订单、创建账户等。
(2)工作流网适合的图形表示方法为基于转换的方法。本文主要关注此类问题。
2.2.1 基于工作流网转换的方法
目前已有的工作流网频繁子网挖掘通常采用两步走的解决方案。
第一步,对工作流网进行转换。例如,(1)仅将工作流网中的事件转换为图节点,将条件以及输入输出弧作为图的边,多用于转换一种特殊类型的工作流网—标识图。(2)仅将工作流网中的条件转换为图节点,将事件、输入输出弧作为图的边[75],多用于另一类工作流网—状态机。(3)将工作流网中的两类节点(事件、条件)转换为图的一种节点,将输入输出弧作为图的边[76]。
第二步,基于转换的图直接运行频繁子图挖掘、图聚类等算法。首个工作流网挖掘方法是w-find 算法[77]。该算法的输入是工作流转换而成的控制流图(control flow graph,CFG),算法的目标是挖掘出CFG 中所有满足闭合约束的子图。然而,CFG 只包含一类节点,代表日志中的活动,边代表活动之间的数据流。可以发现,w-find 算法利用频繁子图挖掘技术得到频繁的活动,是对进程挖掘任务的验证和扩充。文献[78]提出BPMClustering 算法,利用图聚类方法基于多个工作流网进行聚类计算,计算多个工作流网之间的相似度。然而,该方法不能挖掘常见的选择和并发结构。文献[79]提出IGP 算法,该算法将每条日志都转换为一个实例图(instance graph),然后在大规模的实例图之间实施频繁子图挖掘,但挖掘出的实例图仅能还原顺序和并发结构,一些复杂模式无法挖掘。类似w-find 算法,IGP 算法的目标也是对于进程挖掘任务进行部分验证。文献[1]基于w-find 算法提出从进程模型中挖掘频繁模式的问题,将频繁子图挖掘的方法应用于工作流网模式抽取中,并开发出工具WoMine 对工作流网的拓扑结构进行挖掘。然而算法得到的子结构不再是工作流网。常见的基于图集合的频繁子图挖掘算法在工作流网挖掘中的应用如表4 所示。

表4 基于图集合的频繁子图挖掘算法在工作流网挖掘中的应用
2.2.2 序列与网混合式方法
混合的方法是指从一维日志序列中构造二维的工作流网,然后再将工作流网与日志序列进行比对计算。代表性的混合方法是一致性检测算法[80]。一致性检测利用对齐映射等方式解决模型重演问题,但是大多数一致性检测技术仅提供基本统计信息,例如不一致的偏差数量。关于序列与网混合的方法研究仍是少数,表5 中列举了几种代表性的序列与网混合方法。

表5 序列与网混合式方法所适用的具体任务清单
业务流程的执行顺序决定了业务的正确性和完整性。检测此工作流网与日志序列之间的一致性程度,关乎业务流程的正常运行。但如果单独的检测每个流程的偏差,十分耗时耗力。利用频繁子网的方式将工作流网中重复执行的片段进行提取,利用分治的策略将日志进行分解,是一种常用的技术手段[82]。
例如,银行的汇款流程预定义了检测步骤:开始汇款处理、读取系统配置文件、核查收款人的银行信息等,完整的流程在每次汇款时都会重复发生。
实际上,在上述重复执行的汇款进程中通常存在一种异常模式,即具有高级权限的VIP 客户可以跳过冗长的预配置检测阶段。然而这种异常模型并非每次都出现在日志序列中,这就需要使用频繁模式挖掘的手段对工作流网的子结构进行混合分析。
3 FPM 用于工作流网频繁子网挖掘的问题及缺陷分析
3.1 基于SPM 构造工作流网的问题
在进程挖掘研究中,关注更多的是如何从日志中抽取满足偏序关系、控制流依赖关系的工作流网。Leemans 和Aalst[9]提出EpisodeDiscovery 算法,利用序列挖掘算法PrefixSpan 分析日志序列。但要求所采用的日志必须具备时间、资源等具有偏序关系的数据。EpisodeDiscovery 算法的目的是从日志中抽取出工作流网的顺序结构,体现出与日志中一致的偏序关系。Tax 等人[58]提出LocalProcessModel 算法,旨在从一维的日志序列中构造出工作流网的顺序结构、并发结构、选择结构等复杂的结构。该算法的目的与前面的方法均有所不同,算法并不要求得到完整的工作流网,只需要得到局部结构作为重要的模式。
尽管当前序列模式挖掘、进程挖掘问题已被广泛研究,但将序列模式挖掘方法用在进程挖掘,解决工作流网及其子网的构造仍存在以下问题。
(1)构造的工作流网结构复杂。由于进程挖掘的诸多方法基于规则匹配,存在封闭世界的假设,使得构造出的许多工作流网存在过拟合的现象,存在许多结构复杂、重复、冗长的工作流网模型。在大数据的场景下,文献[84]中提出利用分治策略将日志和模型进行分解,从而降低进程挖掘构造工作流网的复杂度,但挖掘到的工作流网仍然十分复杂,许多研究者称之为“意大利面”式。
(2)声明式规则发现低效。由于声明式规则使用基于有限序列的线性时态逻辑LTLf的操作算子进行表示,当规则数量庞大时,算法处理十分耗时。但声明式规则的优点是比较灵活,适合于不同层面的日志解析,不再局限于以结构为导向。
(3)可解释性差。许多挖掘出的频繁子结构/子模式的意义难以解释,因为缺乏领域知识的支撑,通常被认作无意义。例如,在生物信息学中,挖掘出的频繁模式是否有意义需要由领域专家决定。
3.2 基于FSM 进行工作流网挖掘的问题
工作流网是一种具有单一入口、单一出口,并且执行流程受结构化约束的Petri 网,是刻画业务执行逻辑的主要形式。Petri 网中的元素“条件”、“事件”、“流关系”与工作流网中的“案例”、“任务”、“过程”一一对应。
定义6 工作流网[55]
令N=(C,E;F) 一个Petri 网,N是工作流网,若
(1) ∀e∈E:·e≠Ø ∧e·≠Ø;
(2) ∃i∈C:|{i|·i=Ø}|=1,其中i称为N的源条件;
(3) ∃o∈C:|{o| o·=Ø}|=1,其中o称为N的汇结条件;
(4) ∀x∈C∪E都位于从i到o一条正向路径或反向路径上。
由于频繁子图挖掘算法在一般图上的成功应用,许多研究者致力于将FSM 技术推广到其他领域。在工作流网上的应用需要将工作流网进行转换。然而大多数情况下,这种转换无法还原,不满足双射关系,会丢失重要信息。因此,传统的频繁子图挖掘方法无法直接用于工作流网挖掘。其本质原因如下。
(1)复杂、异构拓扑结构。从定义6 中不难看出,工作流网具有两类节点集和一类边集,而一般图通常由一类节点集和一类边集组成。通常情况下,工作流网的第一类节点叫做事件(表示动作)节点,第二类节点叫做条件(表示状态)节点。
(2)非独立带约束连接类型。遵循Petri 网的结构性质,在工作流网中,弧(连接)是不能独立的,必需依附在它两端的条件/事件节点,且同一类型的节点之间不能有弧。这也使得工作流网的结构约束性更强,是工作流网处理中高复杂度的主要来源。
(3)完备性语义。一般图结构可无语义约束(或可赋予任意语义)。Petri 教授本人曾指出,Petri网具有内置完备性语义。一个Petri 网中的流关系通常是“前提条件事件后提条件”。此内置语义为Petri 网中不可分割的单元。然而转换为一般图后丢失了完备性语义。工作流网是Petri 网的一种特殊子类,因此,工作流子网应是一种不可分割的执行单元[15]。
(4)执行约束。定义6 的2、3 条件规定了工作流网具有唯一的入口和出口,即工作流网具有执行约束[5],此约束是工作流网满足可靠性、无死锁的重要理论依据。
目前,工作流网挖掘工作得到的子网都不再是工作流网,因为转换破坏了工作流网的语义特性。从理论角度分析,目前缺乏关于工作流子网的统一定义,通常将其与一般图等同处理。进一步讲,缺乏工作流子网同构的严格定义。这些都是工作流频繁子网挖掘工作中有待探索的问题。
4 工作流网频繁子网挖掘典型应用
4.1 异常检测
对于构建工作流网及挖掘工作流网结构这两类主要任务而言,异常模式的存在都为问题求解增加了难度。许多异常体现出统计意义上的特征,例如出现的较少(低于频繁阈值),即可被判定为异常。已有很多研究成果利用FPM 方法对异常进行检测、过滤处理[85-87]。基于关系对日志过滤、基于统计概率对日志过滤,都在一定程度上提升了日志质量,使得构造的工作流网质量有所保障。
4.2 跨组织变体分析
在业务流程管理(business process management,BPM)领域,广泛存在子结构重复出现的现象。它们具有高度重用的特点。跨组织变体问题是指针对同一个流程,在不同组织、不同地域之间会存在着共性和差异性,这些差异性被称为变体[6]。变体中的共性信息体现了不同变体之间的关联,得到共性信息可以促进不同组织之间的信息共享、甚至是平台共用。例如,对于医生诊断流程,不同医院和不同医生检查在诊断步骤上会存在一些差别,但不同的医院、不同医生之间往往遵循一个公共的模式[88]。得到这种公共模式可以为许多医院提供病例模版和诊断指导。
4.3 模型重用
对于大多数制造企业来说,设计新的业务流程(如零件装配流水线)耗费巨大,需要多部门协调、整合历史资源。文献[89]针对不同组织环境、不同部门之间相同/相似的子结构/子模式进行相似度计算,同时也表明了已有Petri 网模式的重用对于企业的流程设计而言意义重大。生物信息学领域提出工作流数据集myExperiment[90]、Taverna[91]及其配套的开发软件,旨在检索、共享、重用工作流。利用频繁模式挖掘(FPM)方法提取频繁的子结构是常用的研究方法。
4.4 其他应用
除上述应用外,频繁模式挖掘技术也在不断进步,提出了更能够体现模式意义的算法[67,92-94]。频繁模式挖掘技术在不同领域中也发挥着重要作用,例如医疗辅助保健系统、决策系统以及e-learning 电子学习系统。在这些系统中,软件执行过程通常存在重复、循环[95-96]。在e-learning 系统中,通过学生与课堂之间的互动分析频繁的行为模式[1]。另一方面,老师可以根据挖掘的频繁模式改进课程设计。
5 总结与展望
本文首先依据3 种数据类型,对于工作流网频繁子网挖掘的研究方法进行分类,其次,针对2 种主流研究方向,即从一维日志进程中构造工作流网及其子网和从二维工作流网中挖掘其频繁子网结构,分别给出具体的问题描述、任务列表及相关数据表示。本研究可得到如下结论。
(1)在以进程挖掘技术作为手段,构建工作流网的任务中,诸多SPM 算法被应用,聚焦于工作流网在控制流层面(简单的拓扑结构)的构造。然而针对复杂拓扑结构,如选择、循环等结构以及不可见的隐含信息,当前SPM 算法仍然不能平衡准确度和泛化程度,并且容易过拟合。
(2)在进程挖掘技术的演进发展中,构建声明式的规则为一项比较新颖的任务。FIM 算法被用于日志预处理阶段,其关键在于保持日志活动序。然而,目前只有少量FIM 算法被用于此任务中。
(3)对于具有二维异构拓扑结构的工作流网挖掘分析问题,解决方法更为复杂。当前,经典的FSM 算法,如gSpan 算法、SUBDUE 算法被广泛用于挖掘工作流网子网问题中。然而,由于缺乏针对工作流网的理论问题探究,例如,对于工作流网结构的特殊性、工作流网表示方法的正确性等的考察,适合于工作流网的频繁子网算法还有待严格的理论验证。
伴随着网络技术的飞速发展,网络交易系统、业务流程管理系统等应用场景产生了海量大规模工作流网。复杂异构的网络结构、丰富的语义,为FPM在工作流网中的应用带来了新的挑战。将工作流网频繁子网挖掘研究推广至一般Petri 网更具难度。因为一般Petri 网类型众多,性质更复杂。文献[15]提出完备子网的概念和适用于一般Petri 网的压缩数据表示方法,是对一般类型Petri 网的频繁子网挖掘研究的尝试。但是文献[15,97]中的一般Petri 网频繁子网挖掘技术仍不能用于工作流网,这是因为缺乏保特殊语义的划分工作流子网的方法。因此,以下几点是工作流网频繁子网挖掘研究可能的发展趋势:
(1)针对海量数据特征,设计一种包容异构性、完备性语义的工作流网子网划分方法,以及满足完备性语义的新的表示形式,并设计更高效的工作流网挖掘算法,将频繁模式挖掘理论推广至工作流网及其广义领域。
(2)一直以来,在Petri 网(包含工作流网)研究领域中,带token(托肯,也被称为令牌)的动态信息一直是工作流网性能分析的瓶颈[98]。特别是,托肯体现全局范围内资源的流动,而子网技术是局部层面的研究。文献[98]考虑动态性质的同时探讨了网络交易系统漏洞检测问题的解决思路。如何设计子网挖掘算法,保持整个工作流网的性质,并在电信诈骗检测、用户行为分析等更具挑战性的场景中发挥作用,是未来工作的重点。
(3)工作流网是一种特殊类型的Petri 网,而Petri 网区别于其他建模工具的根本性优势在于其能够描述真并发、具有严格的执行语义。除了本文聚焦的拓扑层面的完备性语义,Petri 网通用网论(包括多种Petri 网的共有特性挖掘,如并发特性、同步特性、冲突特性)还有待进一步研究。
