基于块坐标下降法的外存异步图计算系统①
2022-11-06赵程张志斌郭嘉丰刘丁玮
赵程 张志斌 郭嘉丰 刘丁玮
(中国科学院计算技术研究所网络数据科学与技术重点实验室 北京100190)
(中国科学院大学 北京100049)
0 引言
图数据普遍存在于各个领域,如社交网络、网页链接、金融网络、生物网络等,其中大图计算任务吸引了大量的关注,构建高效易用的图计算系统迫在眉睫。近些年的研究设计并实现了基于各类计算资源的高性能图计算系统[1-9],其中,尽可能地利用外存扩展处理数据的规模,并且探索更高效的外存计算模式成为图计算系统扩展能力研究的关键。
大部分基于外存的系统[2,7-8]在执行图计算的任务时采用整体同步并行计算(bulk synchronous parallel,BSP)模型,在图计算的每轮迭代中都需要从外存加载全量图数据进行计算。外存图计算系统使用相对简单的划分算法划分图数据,并据此安排流水线模式,通过计算时间掩盖加载开销。然而,它们依据划分信息顺序执行,每轮计算中的数据块最多处理一次,从而造成数据的重复加载与计算,浪费了外存带宽。异步计算模式的外存图计算系统通过有选择的加载数据块并对其进行多次计算来减少外存加载的冗余,如Clip[5]、Lumos[3]等。然而,Lumos设置了每个数据块计算的硬上限,而Clip 缺少对内存异步执行程度的控制,它们只是一定程度上缓解了冗余加载的问题。
使用基于优先选择的异步图计算仍然存在诸多挑战:第一,计算优先级需要综合全图点信息,需要额外开销;第二,BSP 模型系统中的加载计算流水线设计得益于其顺序执行策略,而优先选择的策略会破坏这种顺序执行流程;第三,由于图数据的偏斜性[10],基于点集的优先级选择策略要求每个数据块包含相同的点数,这会造成图计算的负载不均衡。
本文提出了一个基于块坐标下降法(block coordinate descent,BCD) 的外存异步图计算系统(BCD based asynchronous out-of-core graph computing system,BCDG)。首先将图算法转化为最优化问题,然后使用块坐标下降法作为块优先级算法,每次计算选择对算法收敛贡献最大的块,以减少冗余计算。利用BCD 的优先级序列能够预测后续若干轮选择的特性,设计了一次选择多轮优先的调度策略,从而降低了优先级计算的平均开销。基于此特性,设计了后续计算的预取机制和对应的计算加载流水线,填补了中央处理器(central processing unit,CPU)计算优先级时加载线程的空闲。考虑到负载均衡问题,设计了计算调度分离的划分策略,根据边将图平均分为一个个分片,并将一个分片视为BCDG 中的最小计算调度单元。调度时将分片按点集合拼成BCD 选中的数据块,计算时按边对这些分片并发计算。使用BCDG 的系统框架实现了图计算中的经典问题PageRank 和弱连通分量,并进行了充分的实验验证。
1 相关工作
目前,外存图计算系统设计外存友好的数据结构以及对应的划分策略,并且据此设计对应的执行引擎。这些设计往往采用流式地加载、计算划分后的数据库的方式,以求最大化数据处理的局部性。下面简要讨论近年来一些相关工作。
同步外存图计算系统。Graphene[2]使用I/O 请求为中心的图处理模型,通过将高层数据访问转化为细粒度的I/O 请求来简化I/O 管理。Dynamic-Shards[11]通过动态分区,从分区中移除不必要的边,以减少磁盘I/O。GraphOne[12]使用了邻接表和压缩系数矩阵两套结构存储图数据以实现部分的动态图数据处理的负载能力。
异步外存图计算系统。Wonderland[13]抽取有效的图摘要以捕捉特定的图属性,在图摘要的引导下执行处理,推断出更好的优先处理顺序和更快的图信息传播。虽然这种基于图摘要的技术很有效,但其应用范围仅限于基于路径的单调图算法,此外算法的适用性仍未确定。AsyncStripe[14]使用非对称分区和基于条带的自适应访问策略来处理异步算法。由于这些工作没有提供同步保证,它们仅适用于基于路径的异步算法。文献[15]针对libaio 引擎设计了自适应的I/O 和计算调度机制并利用批(batch)机制平衡了异步计算的负载。
外存计算之外的工作。Gemini[1]和Symple-Graph[6]提供了分布式图计算的同步处理模型。文献[16]探讨了分布式图计算时的容错计算问题。Teseo[17]关注动态图的存储并提供同步处理模型。Kaleido[18]针对图挖掘类任务以子图为中心的模型计算提供了同步处理模型。
2 背景与动机
本节首先讨论最先进的外存图计算系统,然后介绍整体同步并行、异步并行模式在图计算中的应用,随后分析在外存图计算系统中应用异步并行的动机与挑战。
2.1 基于外存的图计算系统
基于外存的单机图计算系统对于图划分问题采用不需要复杂计算的线性划分策略,然后以流式的方式按照划分后的数据块计算图数据,以此最大化利用图数据的顺序局部性。
同步并行计算。GraphChi[7]在点集上进行图划分,并保证每个分块包含的边数尽可能相同。GraphChi 为每个图划分在内存中维护内存缓冲区,当缓冲区耗尽时从外存中加载划分数据,并且使用协程来实现重叠计算与加载的时间。GridGraph[8]将点集划分为若干子集,将边集划分为基于点划分子集的二维网络;然后构建基于二维数据块的流式执行,根据不同的算法优先选择按行或按列执行。加载任务被拆分成小块,以队列的形式维护到协程中,从而实现加载与计算的重叠。
缺陷:上述外存图计算系统根据图数据的划分信息顺序执行,其数据划分的计算顺序是在计算前确定的,并且每轮计算中每个加载的块最多处理一次。这类预先确定执行顺序和最多处理一次的限制浪费了宝贵的外存带宽,造成了重复的数据加载与计算。
异步并行计算。上述系统除了支持同步并行计算模型,还支持简单的异步执行,在图算法迭代过程中允许更新函数使用最新的中间结果,然而每个加载的块在每轮迭代中最多仍然只能处理一次。Lumos[3]在GridGraph 的基础上,使用无序的异步执行在多轮计算中共用计算结果,以减少外存加载。Clip[5]针对此设计了同步与异步计算的折中,其在块之间进行同步处理以确保磁盘的顺序I/O,在每个块内实现异步处理。
缺陷:Lumos 一定程度上缓解了每个加载块在每轮计算中最多处理一次的问题,但缓解程度受限于其设定的硬上限。Clip 缺少对于内存异步执行程度的控制,整体设计通过块内的异步计算的CPU 资源换取外存I/O,仍然存在冗余计算与加载。Clip仅提供了异步算法的支持,如广度优先搜索、最短路径等,对于传统的同步算法如PageRank 支持能力有限。
2.2 动机与挑战
近年来,有些在分布式场景和异构计算场景的图计算系统使用块选择策略在图算法迭代过程中优先选择“重要”的数据块进行计算,以此加速图算法收敛。分布式图计算系统PrIter[19]和Maiter[20]的优先选择策略是利用基于差值的计算方法选择并更新每轮图算法迭代中差值最大的数据块。基于CPUFPGA 的异构计算图计算系统GraphABCD[21]将图算法转化为最优化问题,并使用块坐标下降方法,每轮选择对目标函数下降最大的块进行计算,以此最大程度地减少冗余计算。这些系统在多计算资源(分布式CPU、CPU-FPGA)环境中验证了对图划分进行优先选择策略能够减少冗余计算、提升收敛效率。在外存图计算系统中,优先选择策略有助于计算过程中总是计算对于算法收敛帮助最大的数据块,从而最大程度地提升算法收敛效率并减少冗余的数据加载。
在外存图计算系统中应用异步并行的挑战有:第一,由于计算数据块被选择的优先级带来的每轮额外选择时间开销不容忽略。数据块的优先级与块内容以及计算中间结果息息相关[19],需要综合块的数量、块中包含的点信息以及点对应的中间结果进行计算;第二,基于优先选择设计外存图计算框架还需要进一步设计加载、计算的流水线。由于优先选择策略的计算模式为选择-计算,每轮计算依赖于上一轮的计算结果,串行的执行选择、加载、计算操作将会浪费大量CPU 时间。第三,基于点集的数据块的优先级选择会造成图计算的负载不均衡。考虑到优先选择的计算量,不论PrIter 还是基于BCD 的优先选择策略都是基于均分点集进行计算、选择的,图数据的偏斜性平均分割的点集极易造成负载的不均衡。
3 系统架构
为了解决上述问题,本文提出了基于最优化方法的外存图计算系统BCDG。本节将介绍系统架构以及BCDG 的工作流程。
如图1 所示,本系统由图存储单元、选择单元、计算单元和加载单元组成。对于输入图,图存储单元分别将按源点和目的点排序的图数据分别存储为压缩稀疏行(compressedsparserow,CSR)和压缩稀疏列(compressed sparse column,CSC)结构,其中顶点偏移量数组存储在内存中,边集列表存储在固态硬盘(solid state disk,SSD)中。该单元在逻辑上将边集列表维护为数个分片(无数据拷贝),其中每个分片指示等量的边数据。选择单元使用优先选择策略中定义的优先级为块维护一个优先级队列。该单元计算出前τ个运算必要的块和需要预取的块。加载单元作为守护进程维护一个加载队列和一个预取队列,根据选择单元从SSD 上的图存储单元加载运算必要的边数据和预取的边数据。计算单元维护图算法的计算边缘(frontier),其中包含选中的前τ个块和相应的顶点。该单元为在使用push/pull 模式[4]的定制图算法提供接口。

图1 系统架构
在BCDG 中运行迭代图算法时,首先将顶点集分为β个块,每个块在内存中以若干分片的形式维护,每个分片中包含相等数量的边。每次迭代中,选择单元选择优先级最高的2τ个块。其步骤如下:(1)选择单元告知加载单元要加载的τ个块和预取的τ个块,加载单元从内存中的图存储单元获取这些块的元数据;(2)加载单元作为协程从SSD 中加载相应的边数据;(3)计算单元从加载单元读取边数据,并从图存储单元获取相应的数据分片信息,然后在块上并行运行用户定义的push/pull 操作;(4)一轮迭代结束时计算单元重新计算每个块的优先级,并通知选择单元更新块的优先级队列。其中,只有步骤(2)包含外存的读操作,而其他的都是原地计算。
4 优先选择策略
将图计算问题转化为最优化问题并使用最优化问题的解决方法是目前最直观且有效的方案。沿用GraphABCD[21]中的思路,使用块坐标下降方法解决图计算的最优化问题。本节首先介绍将图计算任务转化为最优化问题的方法,再探讨基于最优化选择的块的重用距离,最后介绍根据此设计BCDG 的优先选择策略。
4.1 最优化图计算任务
最优化问题可以被描述为找到能够使得目标函数F(x) 最小化的向量x∈Rn。用于解决最优化问题的BCD 算法已经被充分研究[21]。在BCD 中,x被分解为β个等长块x1,x2,…,xβ;记第k轮计算中的向量x为xk=。在第k轮迭代中,除了被选定的块xki外,其余所有块的值都是固定的。更新过程为其中为步长,为下降方向。
本文中,使用G={V,E} 表示输入图;V、E分别为点集和边集;vi表示第i个点;eij表示从点vi到点vj的边;分别表示点vi的出度和入度;A表示邻接矩阵;分别表示点vi的出邻居集和入邻居集。
下面将图计算任务中的一个经典任务PageRank 转化为最优化问题,并介绍如何应用BCD 求解。PageRank 的更新公式为xk+1=Pxk +b,其中P=α(D-1A)T,b=(1-α)/ | V|,D为由每个点的出度构成的对角阵,α为PageRank 的阻尼系数。当PageRank 收敛时,记最终结果为x*,那么有x*=Px*+b。由此构建PageRank 收敛的最优化问题的目标函数,其L-2 正则形式为+b-x*)2选择的下降方向d为目标函数的梯度。

至此,将PageRank 转化为了使用BCD 解决的最优化问题。关于图算法的转化以及块选择方法的选择在现有的工作中有详尽的讨论[19-21],包括弱连通分量、最短路径和协同过滤等。
BCD 算法给定3 个可配置参数,块大小σ、块选择方法和块更新方法。块大小表示被分配到一个块中的点数,取值范围为1 ≤σ≤| V|。块选择方法可以是预定义的固定顺序或者是目标函数的梯度方向。块更新方法指定图算法使用的迭代更新函数。若以梯度下降方法为块选择方法,BCD 中的坐标下降方向沿着目标函数的梯度方向。以上述PageRank为例,式(1)计算每个点的梯度下降方向,式(2)表示每次迭代的更新函数。坐标下降方向表示给定图的哪些部分对算法的收敛最“有价值”,也即能够让目标函数最速下降的方向。
4.2 调度策略
基于4.1 节描述的方法,实现了基于BCD 的PageRank 算法,并在LiveJournal(LJ)和Twitter-2010(TW)数据集上进行了测试。对于任意BCD 迭代轮次k,块选择方法产生的优先块顺序为其中β为总块数,块的优先级大于块的优先级,那么在第k轮中块被选中。
定义事件A:块在第(k+i-1) 轮中被选中,即。考察事件A的频率,结果如图2 所示,左右图分别为LJ 和TW 数据集,每条曲线表示不同的测试块大小,水平和垂直的虚线表示每次块选择方法产生的优先序列中的前τ个块与接下来τ轮中被选中的块一致的频率超过90%。由此可以得到,每轮的块选择方法可以预测接下来若干轮的选择结果。

图2 事件A 发生频率(归一化)
据此,设计BCDG 的调度策略为一次选择多轮优先。在BCDG 中,为了区分与BSP 模型中图计算算法迭代轮次的概念,称从一次选择开始到下一次选择开始前为一个超步(superstep)。记每个超步的块选择个数为τ。在每个超步开始时,执行块选择方法计算数据块的优先级,选择优先级最大的前τ个块加载、计算,如图3 中的①所示。那么相较于原始的BCD 算法,BCDG 节省了τ-1 次计算块选择方法的时间,并且能够将加载与计算重叠起来。而考虑到不能精确地预测,τ越大会出现越多的冗余计算,并且影响收敛效率。根据图2 的结果,推荐选取能够保障预测准确率90%的τ=5~10。
预取策略。图3 为调度和预取流水线示意图,t2 时刻前后分别表示超步1 和超步2。由于加载队列的任务是根据选择的结果派发,当计算超步中最后一个块以及计算块选择方法时,加载线程必定为空闲,如图3①中的时刻t1~t3。为了更好地重叠加载与计算,并且进一步利用SSD 的读带宽,引入预取机制,即在计算过程中,当加载任务队列中本轮的τ个块加载任务完成时,继续从中加载。图3②中时刻t1~t3继续加载块优先列表中的内容,以期在下一个超步中可以命中选择的块。算法1 展示在t3时刻(第4 行)主线程收到第k +1 的优先选择结果,如果加载队列中的任务尚未完成,则需要分情况处理:如果正在加载的块不在超步2 的选择列表中(第7 行),则立即停止加载,并将选择列表中的尚未被加载的块加入加载队列(第9 行);否则,如果选择列表中存在尚未被加载、且优先级高于当前块的块(第13 行),就停止当前加载,并将这些块加入加载队列(第15 行),如果不存在,则继续当前加载。另外,如果加载过程中(包括预取阶段)内存不足,则将已经计算完毕且不在加载队列中的块汰换出内存。
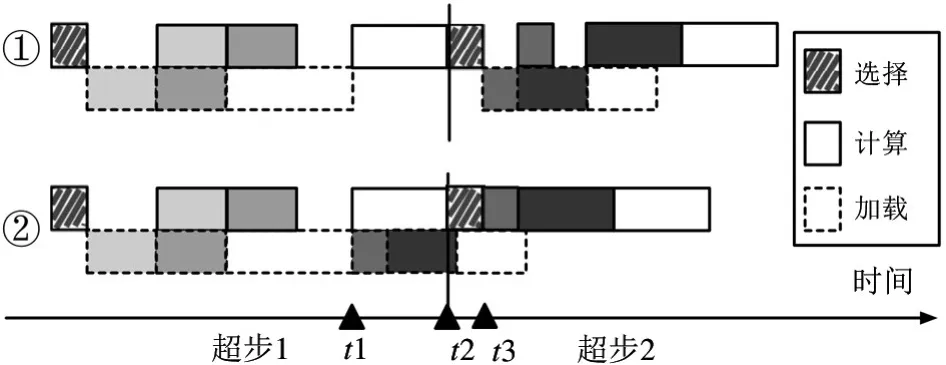
图3 调度和预取流水线(①未使用预取②使用预取)

5 图数据的划分与计算
本节介绍BCDG 的计算调度分离的划分策略与其相应的计算模式。根据第2.2 节的分析,在BCD算法中,数据块的大小对于性能的影响很大。更大的块有利于计算局部性和点间的计算并行性,但是牺牲了收敛速度;更小的块整体收敛轮次减少,但是计算性能会降低。在第4 节中介绍了BCDG 的调度策略,基于BCD 算法对图数据根据点集进行了划分,每个数据块包含的点数一致。在图计算任务中,由于图数据的偏斜性,为了负载均衡,往往需要均衡每个数据块的边数量而非点数。因此,BCDG 首先针对图的边数据构建等宽的分片(chunk),然后以分片为最小运算单元进行计算和调度。
5.1 图数据的分片
对于给定图G(V,E),G的原始压缩稀疏列结构如图4(a)所示;图4(b)展示了在原始的CSC 数组上的划分策略,左侧每行表示一个分片,不同的灰度表示不同点的邻居,右侧为分片的数据结构。BCDG 中,假设图计算中每条边上需要的计算资源是等价的。为了平衡计算负载,BCDG 将边集列表切分为包含同等数量边的若干部分,每个部分为一个分片。每个分片则为整体图计算的最小运算单元,针对每个分片的计算是通过单线程串行执行的。
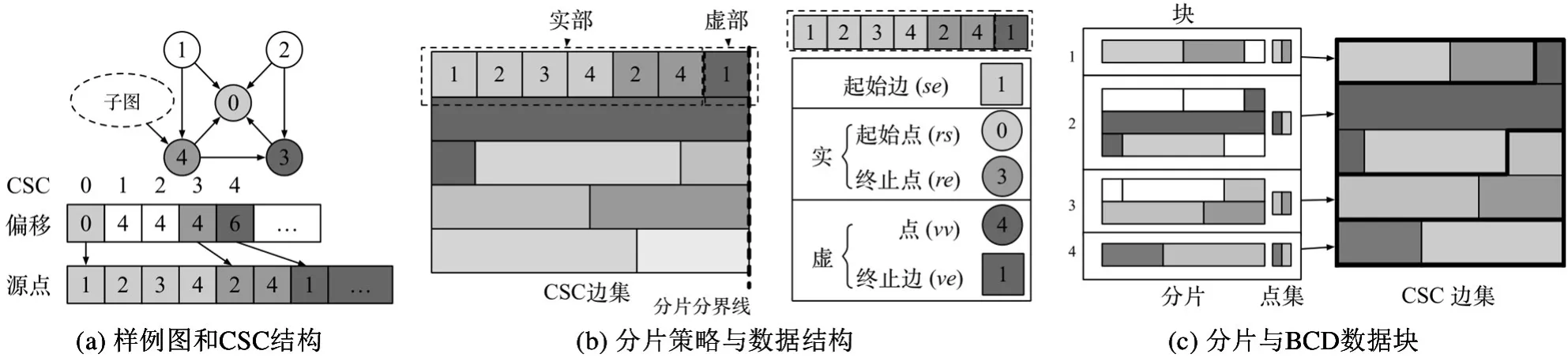
图4 图划分策略与数据块调度
然而,如此切分会在面对相同目标点的时候引入写冲突,如图4(b)所示,分片分界线将处在分片边界的目标点的邻居划分到了不同分片。为了解决写冲突的问题,引入实虚点机制。在每个分片中,若一点的邻居列表中的最后一个点属于本分片,那么称此点为实点,反之称之为虚点。分别称实点、虚点对应的边集为实部、虚部。那么一个分片Ci的逻辑构成如下:

其中se表示起始边,rs、re分别表示实部中的起始和终止点,vv、ve分别表示虚部中的虚点和其在虚部中的终止边。注意,一个分片中的虚部只包含一个虚点。BCDG 维护分片的集合C。BCDG 维护了每个虚点和其对应的实点的映射:

那么,在一轮迭代计算中,BCDG 首先将每个虚点添加至计算边缘中,并对虚点进行等价实点的计算、更新操作;在此轮计算结束前,将每个虚点的更新至合并到对应的实点结果中。
算法2 描述了基于分片的最小运算单元计算流程CalChunk。其中第1~2 行从输入图中读入CSC结构图数据,包含偏移量数组和数据数组(图4(a))。它串行计算了单个分片的实部和虚部,并分别更新了对应的计算边缘(frontier)值。函数Comp的输入值为每条边的源点和目标点,用于执行在每条边上的计算。函数Filter 作为计算中的可选项,其作用为自定义过滤计算时的不必要计算的点或边。并行计算时,首先将虚点扩展至计算边缘,然后每轮迭代中利用CalChunk 并行计算每个分块的内容,利用用户定义的Reduce 函数在上RV计算,将虚点的结果合并至其对应的实点结果中,并更新计算边缘,重复此过程直至收敛。

5.2 基于分片的块计算
为了应用BCD 算法于图计算,BCDG 以分片作为粒度将给定的图划分为若干个块,然后按照分片运行基于BCD 的图算法。图4(c)展示了图划分的设计。对于BCD 视角,点集被分割为β个片段,其中β由BCD 算法的块大小确定。据此,给定图被划分为β个子图。一个点集片段和其对应的边集构成子图,其中1 ≤i≤β。以分片作为计算粒度,因此子图Bi由分片集合CBi构成,其包含所有中的边。满足下述条件:其中Vc表示分片c中的点集,包括真实点和其对应的虚拟点;Ec表示分片c中的边集。在BCD 计算中,BCDG 依据块选择方法在初始迭代轮次选择τ个块,其中1 ≤τ≤s。图计算的计算边缘由这些被选中的块中的点集构成。然后,BCDG 以分片作为粒度依次遍历被选中的子图中的所有边。
算法3 描述了基于分片的块计算流程。其中第1~2 行为BCD 算法中的特殊过滤器BlockFilter 函数,其消除了不属于被选中块的真实点以及其对应的虚拟点。第3 行初始化计算边缘,并将虚拟点扩展至计算边缘。第4~12 行为迭代计算过程,重复计算直到收敛。第5 行使用SelectBlock 函数选择一个或多个块。第7~8 行并行计算分片。第9~10行将所有虚拟点的结果合并至其对应的真实点结果中。当所有优先块计算完毕后,第11 行扩展计算边缘。

6 实验
6.1 实验设置
实验环境:单台计算节点,CPU 为Intel(R) Xeon(R) E5-2640 v4 CPU(双节点;40 个超线程),128 GB内存,1 块477 GB 的SSD(读写带宽分别为3.0 GB/s 和2.7 GB/s)。
基线:GridGraph[8]是外存图处理系统的一个强有力的基线。Lumos[3]是基于GridGraph 实现的框架,其提供了对十亿级图处理的同步执行框架。由于实验环境中的计算单元是CPU,所以本文复现了GraphABCD 的CPU 版本作为基线。在第6.2 节中对比了GraphABCD 文中的基线GraphMat[22],结果见表1,可以看出复现的结果与文中报告的性能提升一致,因此可以以此来作为基线。
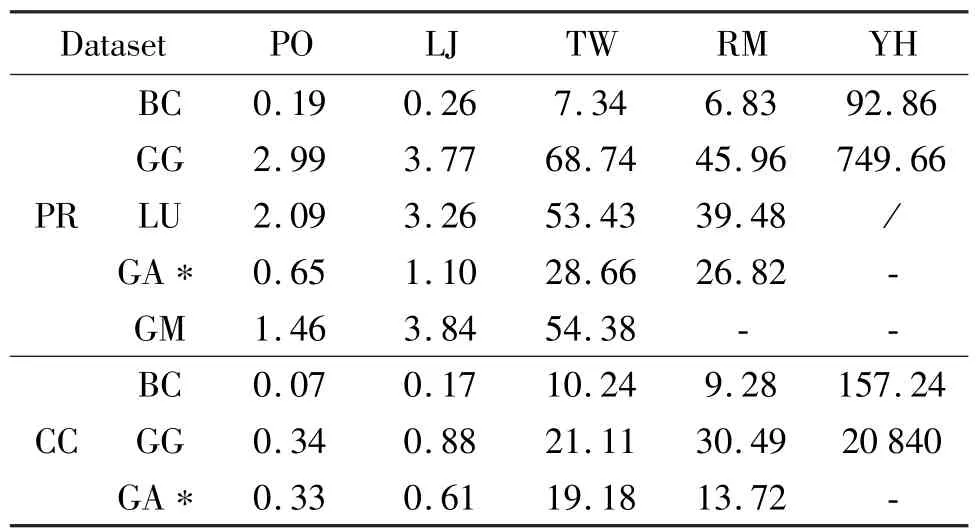
表1 BCDG 与基线的运行时间(s)对比
数据集:使用4 个真实世界的图数据和1 个合成图数据,如表2 所示,其中Pokec[23](PO)、Live-Journal[24](LJ)和Twitter-2010[25](TW)为社交网络图,Yahoo[26](YH)为网页链接图,RMat27[27](RM)为使用幂律分布合成的图数据。文件大小为二进制边集文件大小,图计算系统一般存储CSC、CSR结构各一份,与二进制边集文件大小相近。

表2 实验中使用的数据集
6.2 与现有工作比较
将BCDG 与GridGraph(GG)、Lumos(LU)和复现的GraphABCD(GA*)以及其基线GraphMat(GM)进行对比,在表2 中的数据集上测试了PageRank 应用直到收敛于相同的条件。每次测试均使用全部40 个超线程,运行10 次取平均结果。表1 报告了测试的结果,“-”表示超内存,“/”表示无法运行。其中复现的GraphABCD 和GraphMat 在纯内存中运行,BCDG 与GridGraph、Lumos 运行中均使用了SSD。对于外存测试,使用了cgroup 限制程序运行内存。在所有数据集上,BCDG 的性能均优于其他系统。
对比GraphABCD。首先,复现的GraphABCD 相较于GraphMat 性能平均提升2.46 倍,与其报告的2.1~2.5 倍一致。除了在Yahoo 数据集上,由于内存不足复现的GraphABCD 无法完成,在其余数据集上,相较于复现的GraphABCD,BCDG 性能平均提升了3.86 倍(PageRank)和2.61 倍(CC)。由于BCDG 的调度策略为选择更多的数据块而非一个,所以相比于GraphABCD,每轮计算重新选择块提升了计算性能。
对比GridGraph 和Lumos。在不限制内存的情况下,BCDG 相比GridGraph 性能平均提升了10.30 倍(PageRank)和3.61 倍(CC),相比Lumos 提升了平均8.72 倍(PageRank)。由于GridGraph 在每轮迭代中需要加载全量数据,并且每个数据块在每轮计算中只计算一次,外存I/O 时间为主要开销。虽然Lumos 中使用了异步的计算逻辑,但是其载入的每个数据块只计算2 次,在一定程度上缓解了加载开销,但这仍然是瓶颈。BCDG 相比于GridGraph 的提升主要体现在两方面,一方面优先加载策略节省了计算中的外存加载总量,从而节省了外存开销;另一方面基于分片的划分方式更加均衡了计算负载。
表3 报告了限制内存时,BCDG 与GridGraph、Lumos 在数据集LJ 和TW 上运行PageRank 的时间对比,第1 列和第4 列表示在LJ 和TW 上限制内存的大小,单位为字节,“-”表示不限制内存,“/”表示无法运行。当限制内存时,GridGraph 和Lumos 的性能没有明显变化。BCDG 性能损失较大,因为内存较小时,BCDG 会选择更小的BCD 块放入内存中计算;另外,内存较小时预取策略几乎失效。但当限制更小的内存上限时,只有BCDG 能够正常运行,这是因为BCDG 的分片策略使得调度计算能够以分片作为最小粒度,其相对于GridGraph 的二维划分而言粒度更细。当内存充足时,BCDG 的预取策略可以有更大的空间存储对下一个超步计算的数据块的预测。

表3 限制内存时运行时间(s)对比
6.3 调度策略
图5 描述了BCD 算法中选择不同的BCD 块数时,块选择个数τ对于收敛时间的影响,左右图分别为数据集LJ 和TW 上的结果,图中横轴为选择块的个数τ,每条曲线表示总BCD 块数。注意,块大小σ与BCD 块数的积约等于图的点数。从图中可得,在2 个数据集上,每种块大小的选择下,相比于原始BCD 算法中只选择一个块,增加选择块数都可使收敛时间显著减少。其原因为选择多个块使得加载和计算能够重叠起来,而其预测块的性能损失远小于重叠带来的性能提升。当选择块数τ >5 时,收敛时间的降低速度有所放缓。其原因为当选择块数增加到一定程度时,流水线重叠趋于稳定,选择更多的块不会更显著地降低CPU 等待时间。当选择块数τ>10 时,收敛时间普遍出现波动。其原因为选择更多的块意味着预测正确率下降,所以出现了较多的冗余计算。根据实验结果,推荐选取能够保障预测准确率90%的块选择数τ为5~10。

图5 不同BCD 数据块大小下PageRank 收敛时间统计
6.4 预取策略
图6描述了当选择块数为5时,预取的块数对运行时间与消耗内存的影响,左右图分别为数据集LJ 和TW 上的结果,横轴表示预取的块数,左纵轴表示内存消耗,右纵轴表示归一化的运行时间。其中测试应用为PageRank,运行时间按照关闭预取策略的对照组(预取块数为0)进行归一化。从图中得出结论:预取更多的块几乎不会造成更多的内存消耗,但是却可以显著降低整体的运行时间,当预取块数与选择块数一致时,运行时间总体降低10%。这得益于预取策略能够更好地利用加载线程,消除其在图3中t1~t3时间内的空闲。
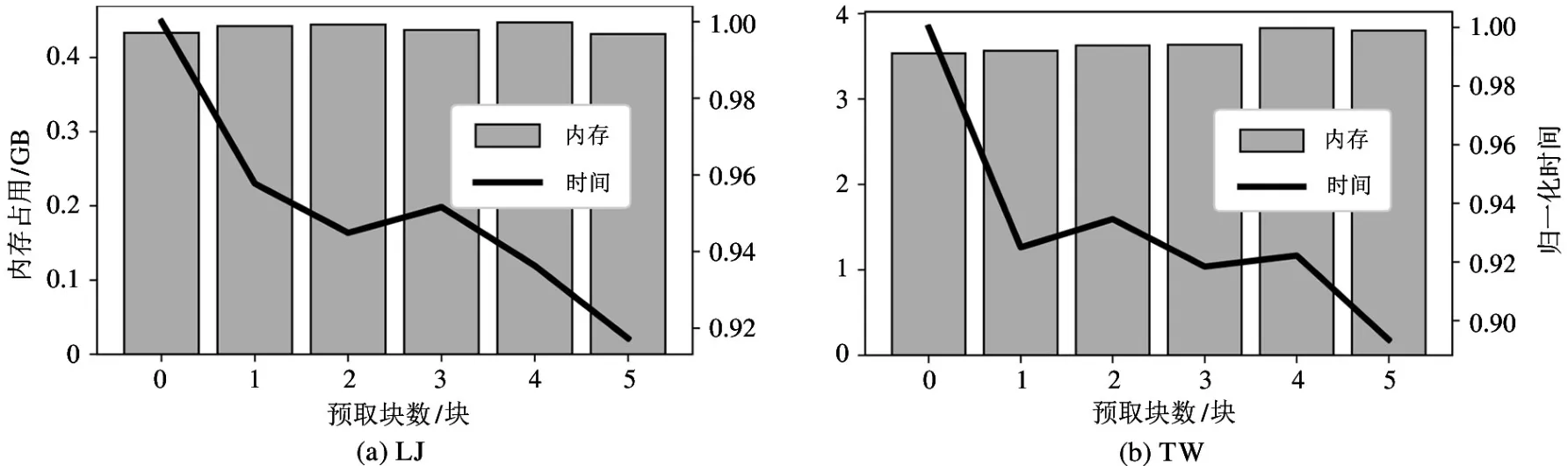
图6 预取块数对运行时间和消耗内存的影响
6.5 运行时间分析
图7 描述了BCDG 的运行时间分析。其中测试应用为PageRank,图7 给出了不同数据集在不限制内存和限制内存情况下的运行时间分析,在数据集PO、LJ、TW 和RM 上的内存限制分别为256 MB、512 MB、4 GB 和6 GB,运行时间按照每个例子的总运行时间进行归一化。从图中可以得出,相比于GridGraph 中外存I/O 占总计算时间的70%~80%、占Lumos 的50%~60%[3],BCDG 从外存读入的时间在总计算时间的占比仅为10%~30%。限制内存时,BCDG 的性能一方面受到BCD 选块大小的影响,另一方面也需要消耗更多的时间在加载数据上。这是因为预取策略受到内存限制,优化性能有限。另外也说明了相比于其他外存图计算系统,BCDG 能够更加高效地利用内存减少外存I/O。

图7 不同数据集上运行PageRank 的运行时间分析
7 结论
本文针对外存图计算系统存在的计算冗余问题以及外存I/O 瓶颈,在基于优先选择的外存异步图计算系统上作了深入研究。计算数据块优先级本身引入的性能开销不可忽略,并且优先选择策略会破坏加载计算的流水线以及会引入计算的负载不均衡。为此本文提出了基于块坐标下降法的外存异步图计算系统。首先,观察并验证可得,BCD 算法在每轮中赋予每个数据块的优先级能够预测后续轮次的选择,由此设计了一次选择多轮优先调度策略;其次,继续利用此性质设计了预取策略,并构建加载计算流水线;最后,发现面向计算的按边划分策略不影响按点调度,因此设计了计算调度分离的划分策略,同时实现了计算的负载均衡和优先调度。实验结果表明,相比于目前最先进的外存图计算系统Grid-Graph 和Lumos,BCOG 平均性能分别提升10.30 倍与8.72倍。整体计算过程中,CPU 等待外存I/O 的时间仅占10%~30%。本文更多关注基于推拉计算模型中的拉操作,后续工作将对推操作进一步探索。
