一种基于图嵌入模型的关联感知真值发现
2022-11-05XiuSusieFang司苏新
吕 航,Xiu Susie Fang,司苏新,王 康
(东华大学 计算机科学与技术学院,上海 201620)
0 引言
在过去的几十年里,从搜索引擎、社交媒体平台、众包平台等各种网络渠道收集的数据量急剧增加。人们往往可以从不同的数据源收集同一实体的声明信息,然而由于记录错误、机器故障、噪音、恶意攻击等原因,这些信息可能会相互冲突。如果不解决这些冲突,从网络上检索到的信息将毫无用处。为了得到可靠的信息(即真实的事实),就需要研究多源数据的聚合技术。
近些年来,许多研究提出了多源数据聚合的方法。这些方法可以分为3类:
(1)迭代法。迭代计算来源的可靠性和声明值的可信度。
(2)基于最优化的方法。使每个声明值与真实值之间的源加权距离最小。
(3)概率法。对源和声明值的联合分布进行建模,使联合分布可能性最大化。
虽然现有方法已取得了不错的效果,但大部分方法都忽视了实体属性之间存在的各种关联。研究可知,充分利用实体属性之间的关联能提升真值发现结果的准确性。
这里通过表1中的实例来阐述这一点。由表1看到,实体具有年龄、出生日期、居住城市和邮编等属性。这些属性中存在如下关联:年龄取决于出生日期,城市和邮编具有一一对应关系。如果采用多数投票的方法,可能会在实体1的年龄属性上得到错误的结果为18岁。然而,通过考虑年龄和出生日期之间的依赖关系,就可以先获得出生日期的真值,即2004年1月1日,从而得到正确的年龄为19岁。这说明如果在本文的方法中,能够捕捉属性间的关系,可以获得更准确的结果。

表1 实体的信息表Tab.1 Entity information table
考虑实体属性相关性的真值发现研究仍处于起步阶段,仅有的一些方法对实体属性关系的捕捉还不全面,比如现有的研究集中于属性的几种特定关系,如时间关系、空间关系或常识,或将属性之间的关系采用数据间约束来表示。本文提出的异构网络模型不仅捕捉了数据源间的相似关系、数据源对声明值的偏好选择关系,还考虑了实体属性的一般化关系来推断实体属性的真实值。接下来将基于2个真实世界数据集的实验结果证明了本文的算法优于现有方法。
1 图嵌入模型
1.1 问题定义

1.2 异构网络
本节将创建4个网络,这4个网络一起构建了一个大型的异构网络,如图1所示,用于处理存在实体属性关联的真值发现问题。
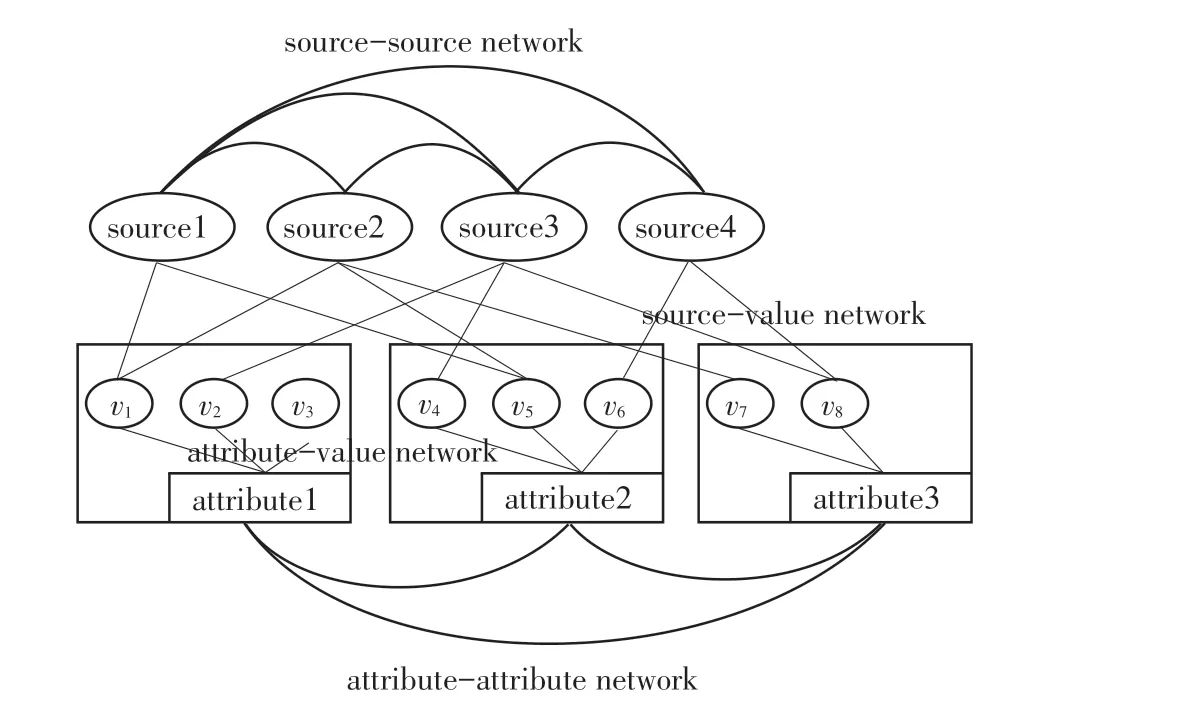
图1 异构网络Fig.1 Heterogeneous network
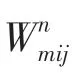
通过定义源与属性值之间的网络,能够对源声明一个属性值的过程建模,这种建模可以将源的可靠性体现在其对声明值的偏好选择上。
源与源之间的网络定义为G=(∪,E),这里是源的集合,E是源与源之间的边,边上定义了2种不同权重。第一种W为源S和源S对给定的同一实体的同一属性做出相同的声明值的数量,第二种D为这2个源对给定的同一实体的同一属性做出不同的声明值数量。
通过定义源与源之间的网络,能够挖掘源与源之间的相似性。如果相同声明值权重W越大于不同声明值权重D,则说明2个源越相似。同时结合源-属性值网络中捕捉的关系,源之间的关系表明了源提供可信声明的偏好。
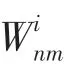
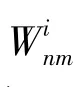
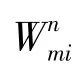
4种异构网络中捕捉的各种连接关系为规范化真值发现建模提供了更多的证据。
1.3 网络的嵌入
在本节中,提出将4种异构网络嵌入到低维空间的处理方法。由于这个异构的网络由4个子网络组成,这里采用的是对每个子网络进行嵌入,再嵌入整个异构网络的方法。


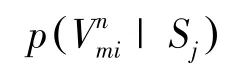

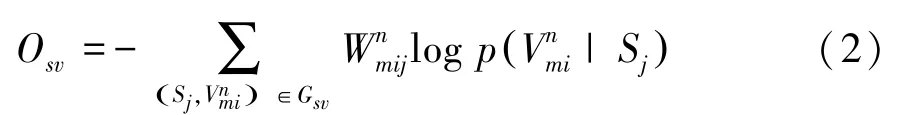
对于图G的每一条边,定义了源S和源S的联合概率:
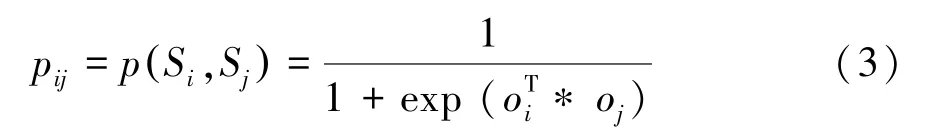
越高的条件概率p表明源S和源S具有越高的相似性。即源S和源S在同一实体属性上做出相同声明值的概率为p。
图G对于每一条边定义了2种不同的权重,在已知p的条件下,可以得到2种权重的条件概率:

研究用分布去解决数据稀疏问题。此处需用到的数学公式为:

其中,是函数,,是2个超参数。
通过最大化由源-源网络得到的概率,能使具有相似可靠性的源在嵌入空间内的距离相近。即最小化损失函数O:
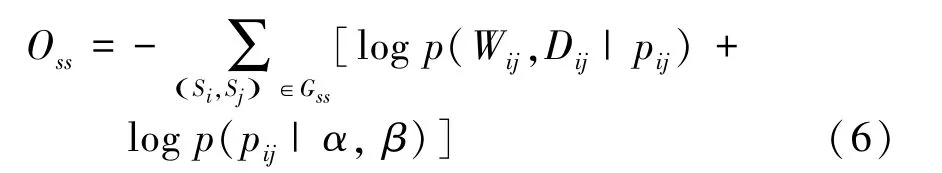



图G对于每一条边定义了2种不同的权重,在已知p的条件下,可以得到2种权重的条件概率为:
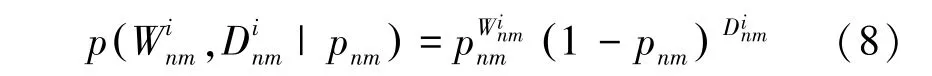
接着提出用分布去解决数据稀疏问题。推理得出的数学公式为:

其中,是函数,,是2个超参数。
通过最大化属性-属性网络得到的概率,能使具有关系的属性在嵌入空间内的距离相近。即最小化损失函数O:

通过定义实体属性-实体属性值之间的网络,能将建模的实体属性之间的关系体现在属性值层面上。定义图G上的2条边上的属性值成对出现的概率为:

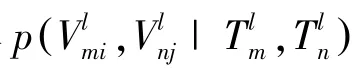

本次研究的目标是使源、实体属性、实体属性值的联合概率最大化,等价于最小化损失函数O、O、O、O,即最小化O:
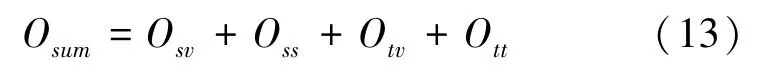
1.4 模型的学习
一种直观的解法:可以同时使用所有子网络来学习并更新各种嵌入的表示。即公式(13)的优化,也就是通过合并所有子网络的边,并对边抽样,抽样的概率与其在网络中的权重成正比,再根据抽样的边对参数的嵌入表示进行更新。但由于不同子网络的权重是不可比的,因此迭代采样每个子网络的边,基于偏导对每个子网络的嵌入表示进行更新。




紧接着,计算O关于源S的偏导:

通过式(14)~(16)对源,属性值的嵌入表示的更新,能使可靠的源和可信度较高的属性值在嵌入空间距离相近。
对于源-源网络,同样计算源S关于O的偏导:

通过对源的嵌入表示的更新,能使具有相似可靠性的源在嵌入空间相近。
对于实体属性-实体属性网络,同样计算实体属性T关于O的偏导:
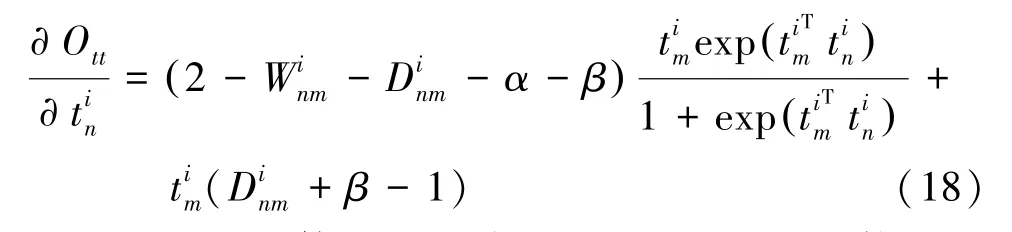
通过对实体属性的嵌入表示的更新,能使具有关联的实体属性在嵌入空间相近。
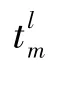

计算O关于t的偏导:

计算O关于a的偏导:

计算O关于an的偏导:

通过式(19)~(22)对实体属性、属性值的嵌入表示更新让满足实体属性之间关联的属性值在嵌入空间靠近实体属性。
综上所述,就可使用随机梯度下降(SGD)方法去更新实体属性、源、属性的嵌入表示。
1.5 真值的推断
在模型学习中,得到了属性值嵌入、源嵌入和属性嵌入,同时对于各种嵌入的优化让真值嵌入和真实属性值嵌入在嵌入空间中接近。因此通过计算集合V中每个属性值和真值之间的相似性,相似性最高的属性值即为属性的真实值。
但是由于本文算法是无监督的,并没有真值的嵌入。为了构造真值嵌入,文中采用对所有属性多数投票来找到真实值,对得到的真实值的集合按照真实值的可信度进行排序,从排序的真实值集合选取前个真实值并取其平均值作为真值的嵌入。
2 实验
研究采用Python(3.6)实现了所有的基线方法和本文提出的模型(GETD),所有的实验都是在Intel Core i5-7200U CPU@2.50 GHz的电脑上运行的。
2.1 数据集
(1)Restaurant:该数据集包括来自5个源提供的信息。每个餐厅是一个实体,每个实体有5个分类属性:餐厅名称、建筑编号、街道名称、邮政编码和电话号码。
(2)Weather:该数据集包含9个来源提供的信息,每个城市是一个实体,每个实体具有30个分类属性,即一个月内的天气情况。
真实数据集的统计结果见表2。

表2 真实数据集的统计Tab.2 The statistics of real-world datasets
2.2 评价指标
错误率():推断的实体属性真实值与中不同的数量占的百分比,越小的错误率表明实验结果越好。
2.3 对比算法
(1)Majority Voting:该方法认为在所有源中出现次数最多的声明值为真值。
(2)TruthFinder:通过给定源的可靠性,去推断真值,再根据真值去推断源的可靠性,迭代更新源的可靠性和真值至收敛。
(3)CRH:将真值发现视为一个最优化问题,采取两步迭代更新,一步更新源权重,一步更新值的可信度。
(4)CATD:采用最优化的方法解决真值发现问题,将源的权重采用置信区间的方式建模,以解决数据稀疏问题。
(5)CASE:通过使用一种嵌入方法,解决真值发现问题,但不考虑属性之间的关系。
(6)CTD:将真值发现视为一个最优化问题,同时使用数据库约束来捕捉属性关联的方法。
2.4 实验设置
为了确保公平的对比,研究运行了一系列的实验来为每个基线方法设定最优的参数。对于本文的方法,设置嵌入维度为12。对于SGD方法,设置学习率为0.1。设置函数中和为1.1。对于真值的推断步骤中值设为3%。
2.5 实验结果
在表3和表4中列出了不同真值发现算法在Restaurant数据集和Weather数据集上实验3次的运行结果及平均的错误率。从实验结果中,可以看到本文提出的GETD方法在2个真实世界数据集上都优于其他方法,这是因为这些基线方法大多都没有考虑属性之间的关系,只是单纯地考虑数据源的可靠性或相似性,并不能捕捉属性之间的关系,导致实验精度不够。CTD算法虽然考虑了属性之间的关系,但是算法的reduction部分并未考虑迭代,导致了精度的丢失。本文提出的GETD模型在考虑源的可靠性与源的相似性的基础上,全面捕捉了一般化的属性关系,能够更加精准地挖掘底层数据之间的关联。

表3 基于Restaurant数据集的对比结果Tab.3 Comparison results based on Restaurant dataset

表4 基于Weather数据集的对比结果Tab.4 Comparison results based on Weather dataset
2.6 不同L值对实验结果的影响
通过在Restaurant数据集上采用不同值,研究该参数对实验结果准确性的影响。在这个实验中采用实验效果最好的CTD作为对比算法。实验结果如图2所示,当值低于2%时,GETD的错误率较高,效果不如CTD,但当值较大时,本文的方法始终优于CTD算法。根据实验结果,文中将设置3%。

图2 Restaurant数据集上不同L值对错误率的影响Fig.2 Influence of different L on error rate in Restaurant dataset
3 结束语
本文采用基于异构网络的图嵌入方法解决了存在属性关联的真值发现问题。提出的模型构建了4个异构网络,包括源-属性值、源-源、实体属性-实体属性和实体属性-实体属性值网络。同时,通过源-属性值网络捕捉源可靠性与属性值可信度的关系、源-源网络捕捉源之间的相似性关系、实体属性-实体属性网络捕捉属性之间的关系,实体属性-实体属性值网络将建模的实体属性之间的关系体现在属性值层面上,对每个子网络采取随机梯度下降的方法来更新嵌入表示,最后根据嵌入表示来推断真值。在2个真实世界数据集上的实验证明了该模型的有效性。
