毫米波雷达与相机两级融合的3D目标检测方法研究
2022-11-05侯志斌娄静涛
侯志斌,陆 峰,娄静涛,朱 愿
(1 陆军军事交通学院 学员五大队,天津 300161;2 陆军军事交通学院 军事交通运输研究所,天津 300161)
0 引言
感知是自动驾驶系统的重要组成模块,而3D目标检测是自动驾驶感知模块的重要内容。尤其是对自动驾驶下游任务,发挥着重要作用。由于采用单一传感器均存在一些缺陷,因此多模态融合是当前研究重点。目前来看,现有传感器融合方法大多集中在激光雷达与摄像机融合上,但在雪、雨、雾霾、沙尘暴等恶劣天气条件以及远距离目标下,激光雷达与相机融合方案的检测质量会大幅下降。在当前技术水平下,开展相机与毫米波雷达融合策略方法研究是一套低成本且应对恶劣环境下目标检测的更鲁棒方案。
国内外对毫米波雷达与相机融合的目标检测方法已经做了一定研究。如:Nabati等人提出了RRPN网络,通过仿照图像检测中的RPN网络,将毫米波雷达信息投影到图像坐标系中,提出了基于毫米波雷达点云的预设,再进行检测,减少了锚框数量,提升了检测速度,但整个过程中并未解决毫米波雷达信息投影到图像坐标系上存在噪声及高度误差问题。Meyer等人提出了将毫米波雷达点云转为鸟瞰视角,点云直接输入到CNN网络中来进行目标检测。而问题在于一帧毫米波雷达点云过于稀疏,且CNN直接作用于点云会产生较多噪点,影响检测精度。高洁等人在目标跟踪框架中,提出将上一帧图像检测结果与当前帧雷达建立图像与雷达点的关联,实现雷达预分类;再利用目标跟踪框架来实现同一雷达点关联,找出属于上一时刻目标在当前时刻的量测,利用RRPN建立候选区域,从而得到当前目标检测结果,但同样未考虑毫米波雷达高 度 信 息 不 准 的 问 题。Nabati等 人提 出 了Centerfusion网络,通过毫米波雷达与相机融合进行3D目标检测。首先由单目检测结果建立3D ROI,然后在特征层运用截锥体的毫米波雷达点云与单目初级检测结果建立关联,进行二次回归,补充图像特征,提升检测水平。而问题是,仅在特征层融合毫米波雷达点云信息,会使整体网络框架比较依赖单目3D目标检测结果,而单目进行目标检测存在固有缺陷,从而影响最终检测质量。
为此,本文在Centerfusion网络的基础上进行改进,提出了毫米波雷达相机两级融合的3D目标检测网络,将毫米波雷达信息和图像分别在数据级、特征级两级进行融合,以弥补毫米波雷达投影到图像坐标中高度信息不准以及单模态目标检测存在的不足,提升3D目标检测精度以及在复杂天气条件下或对远距离小目标检测的鲁棒性。
1 两级融合的3D目标检测网络框架
本节将主要介绍雷达和相机传感器二级融合的3D目标检测框架。首先,在输入端将毫米波点云信息进行预处理后与相机建立数据层融合,生成三通道图像附加雷达信息;采用加入注意力机制的CenterNet网络作为基于中心的目标检测网络,进行初级检测,回归出目标的属性、三维位置、方向和尺寸等初级三维检测结果,克服了相机单模态目标检测存在的固有缺陷,提升了小目标、模糊目标、以及不利气候条件下的检测精度;然后参照文献[5]中方法再进行特征层融合,使用截锥体机制将雷达检测与其对应对象的中心点相关联,并利用雷达和图像特征,进一步估计深度、速度、旋转和属性来提升初步检测精度,网络结构如图1所示。

图1 两级融合的3D目标检测网络结构图Fig.1 Structure diagram of 3D object detection network with two-level fusion
1.1 毫米波雷达与相机信息数据层融合
毫米波雷达和相机对目标的检测是相互独立的,各自的测量数据也基于不同坐标系。因此,在进行信息融合前,需将雷达和相机测量的目标数据转换到相同的坐标系中,需对不同传感器的目标数据进行空间配准。毫米波雷达与相机涉及到5个不同坐标系之间的转换,坐标系之间的关系如图2所示。 本文基于数据集开展研究,因此可通过数据集中相机内外参数,将毫米波雷达信息投影到图像坐标系上。为解决毫米波雷达投影到图像坐标系下高度信息不准的问题,改进使用文献[7]中方法,将毫米波雷达信息进行条码化改进处理。将其扩展为2.5 m红色线段,以确保在图像坐标系下,将检测物体(汽车、卡车、摩托车、自行车和行人等)进行覆盖。雷达数据以像素宽度2映射到图像平面,使相机像素与毫米波雷达信息建立基本。雷达回波的特征作为像素值投影到三通道图像中,在不存在雷达回波的图像像素位置,将投影雷达通道值设置为0。输入图像转为附加有毫米波雷达信息的三通道图像,如图3所示。同时为解决毫米波雷达稀疏的问题,本文将6个雷达周期共同融合到本文的数据格式中,来增加雷达数据的密度。

图2 坐标系关系示意图Fig.2 Diagram of coordinate system relationship

图3 毫米波雷达点云条码化处理示意图Fig.3 Schematic diagram of barcode processing of millimeter wave radar point cloud
1.2 初级检测网络
1.2.1 加入空间通道注意力机制的关键点检测网络
初级检测使用CenterNet框架作为基础网络,DLA-34网络作为骨干网络。为提取三通道雷达图像信息中雷达投影信息,本文在骨干网络末端加入空间通道注意力模块CBM和SAM,对卷积特征的通道和空间建立注意力机制。其中,通道注意力模块CBM结构如图4所示。

图4 CBM通道注意力模块Fig.4 CBM channel attention module
上述方法的数学推导见式(1):
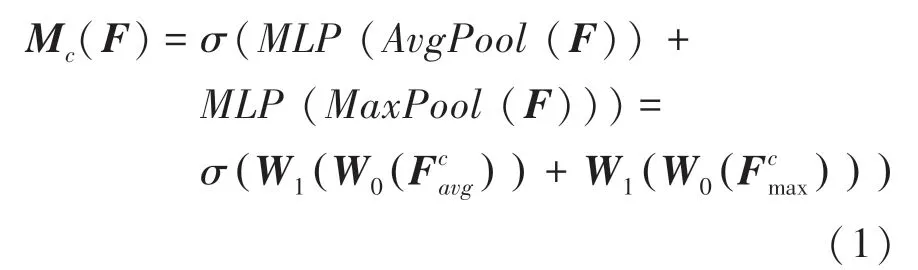
其中,为输入特征,经过并行的平均池化层和最大池化层后,得到2个多通道1×1维度特征图后,再将其分别送入一个2层MLP网络中。将MLP输出的特征进行张量内对应元素(element-wise)相加,再经过激活操作,生成通道特征M,最后将M和输入特征做张量内对应元素相乘,作为通道注意力模块。
之后,将CBM注意力模块输出作为SAM注意力模块输入,建立空间注意力机制。空间注意力模块SAM结构如图5所示。
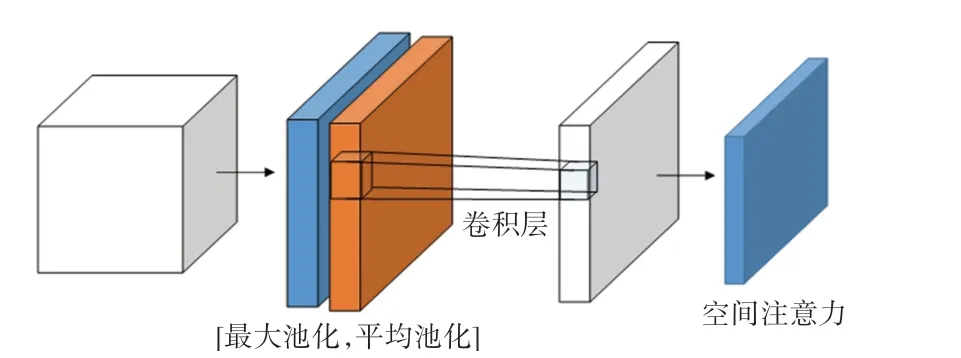
图5 SAM通道注意力模块Fig.5 SAM channel attention module
上述方法的数学推导见式(2):

其中,为输入特征图。首先做一个基于通道的全局最大池化和全局平均池化,得到2个1的特征图,将这2个特征图基于通道做通道拼接,并经过一个7×7卷积操作,降维为1个通道,即1;再经过激活函数生成空间注意力特征,最后将该特征与模块输入做乘法,得到最终生成特征。
将附加有关联条码化雷达信息的三通道图像I∈R作为输入。为防止雷达投影到三通道图像导致完全覆盖三通道信息,影响网络泛化水平,建立投影权重系数。 经过实验,当=0.6时检测结果最佳。作为超参,则三通道图像为:
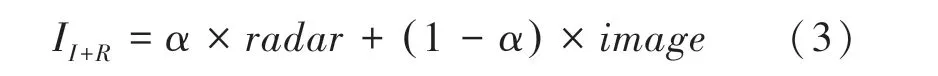
关键点热力图输出为:



图6 输出热力图Fig.6 Output heat map
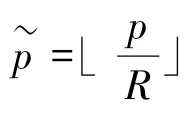
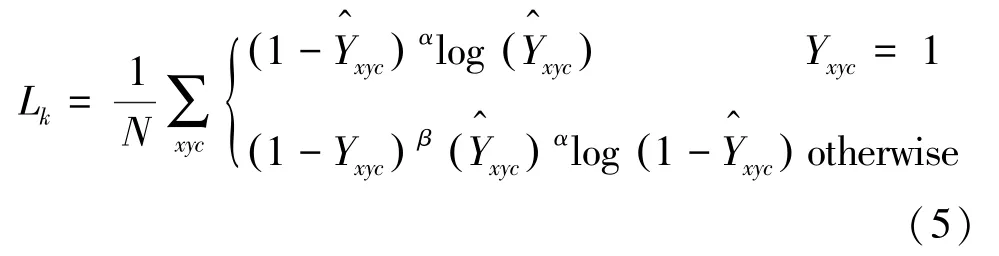




故热力图生成总的损失函数为:
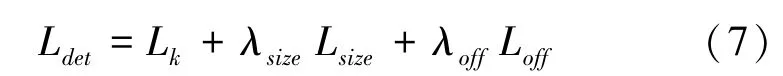
1.2.2 通过关键点进行3D目标检测
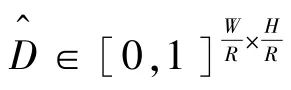
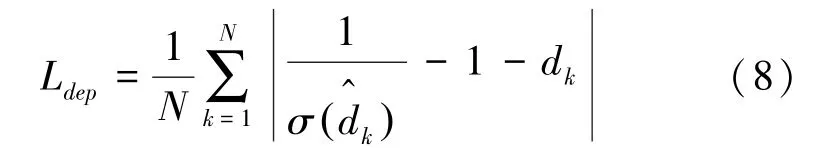
其中,d是标注信息(g)的绝对深度,以m为单位。


其中,γ是标注物体的高、宽、长,以m为单位。
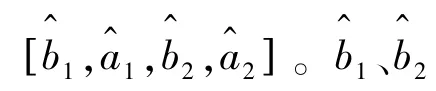

训练时建立损失函数为:

1.3 毫米波雷达与相机信息特征层融合
经过初级检测网络,生成了目标的热力图、2D目标尺寸、3D目标尺寸、深度、方向、偏差等。为进一步提升精度,需在特征层进行二次融合。
1.3.1 雷达关联
参照文献[4]中截锥体关联方法,在特征层将毫米波雷达点云扩展为垂直柱体,为解决高度不准确问题,使用初级检测中生成的边界框(bboxing)及其回归的深度和目标尺寸来创建一个3D兴趣区域(3D RoI)截锥体,并忽略截锥体之外的任何点。为消除多检测关联问题,在此RoI内有多个毫米波雷达点云,本文将最近的点作为对应于这个对象的雷达检测,如图7所示。其中,图7(a)为基于对象的3D边界框生成截锥体的兴趣区域,图7(b)为鸟瞰视角下的截锥体关联机制示意图。
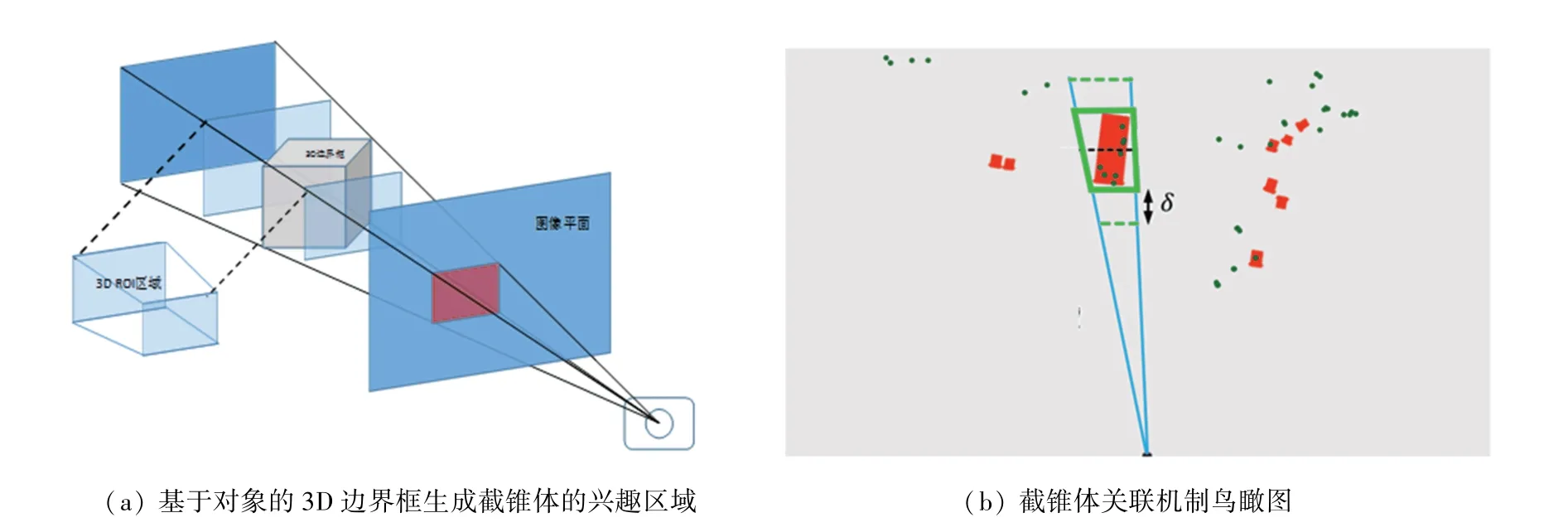
图7 截锥体关联方法示意图Fig.7 Schematic diagram of frustum correlation method
1.3.2 雷达特征提取
在雷达信号与其对应目标关联后,使用雷达信号中的深度和速度为图像,创建互补特征。其中,对于每一个与物体相关的雷达信号,都会生成(,v,v)三个以物体的2D边界框为中心的热力图通道。热力图的宽度和高度与对象的二维边界框成比例,热图值是标准化的物体深度,也是在自车坐标系中径向速度(V和V)的和分量:
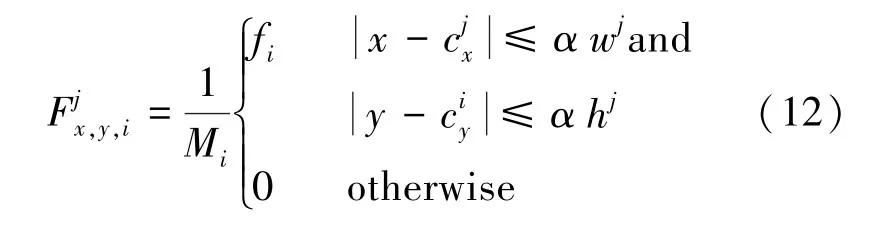
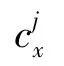
如果2个对象具有重叠的热图区域,则深度值较小的对象占主导地位,因为只有最近的对象在图像中才完全可见。
生成的热力图作为额外通道连接到图像特征,这些特征作为二次回归输入,重新估算对象的三维信息、以及速度和类别。与初级检测相比,经过特征融合后,有助于从雷达特征中学习更高层次的特征,最后将生成值解码为3D边界框。3D边界框从初级检测器获得3D尺寸,并从二次回归中得到估计的深度、速度、转角和类别。
2 实验分析与对比验证
2.1 数据集
本文使用nuScenes数据集进行模型训练及测试。该数据集是第一个携带毫米波雷达信息的自动驾驶场景数据集,其中涵盖了在波士顿和新加坡采集的1000个场景的数据,是目前最大的具有三维目标标注信息的自动驾驶汽车多传感器数据集。其传感器配置上含有6个摄像头、5个雷达和1个激光雷达,所有这些都具有全360°视野。传感器参数见表1。

表1 nuScenes数据集传感器参数表Tab.1 Sensor parameters of nuScenes dataset
2.2 实验设置
本文采取网络骨干为DLA-34的CenterNet网络进行训练。训练时采取Centerfusion提供的预训练模型进行训练,同时在不同位置加入注意力机制进行性能对比实验。实验平台的操作系统为ubuntu16.04,并带有型号为GeForce GTX 1050的GPU。
训练阶段共迭代60个,训练批次大小设置为2,初始学习率为2.4e-4,同时采用学习率衰减策略,训练50个后学习率下降10%。三通道图像输入到网络前进行随机左右翻转、随机移位等数据加强。测试阶段,采用60个的训练权重,来对本文方法进行测试。
以下实验均使用单个GPU完成。由于完整数据集较大,本文仿真主要通过nuScenes的v1.0-mini数据集进行训练,重点测试改进的网络检测精度。v1.0-mini数据集是由整个数据集中抽取出的10个场景组成,其中训练样本为14065个,测试样本为6019个,训练收敛曲线如图8所示。

图8 训练过程收敛曲线Fig.8 Convergence curve of training process
2.3 3D目标检测数据对比
以Centerfusion作为基准网络,为确保训练及测试 数 据 相 一 致,用nuScenes v1.0-mini对Centerfusion重新进行训练及测试,测试集选用数据集中的“scene-0103”、“scene-0916”两个场景作为mini-test集,并与本文方法进行比较。表2中列出了对Centernet(3d)、Centerfusion和本文方法进行3D目标检测性能的比较结果。可以看出,在mini集进行训练、在mini-test集进行测试后,检测分数()上升了近1.21%。图9展示了Centerfusion和本文方法的收敛过程。

表2 3D检测性能对比表Tab.23D detection performance comparison table

图9 NDS收敛曲线图Fig.9 NDS convergence curve
由图9中可见,随着训练迭代次数的增多,本文方法与Centerfusion均呈现抖动上升趋势,在训练60个迭代周期后,本文网络指标明显高出约0.03。
nuScenes v1.0-mini数据集中7类物体检测的平均精度结果见表3。由表3可见,在测试集中,本文方法在巴士、行人、摩托车、自行车等的检测精度均高于Centerfusion检测结果。尤其是对于自行车的检测精度上,相比提升了近40%。

表3 3D目标检测对象精度对比表Tab.3 Object accuracy comparison table of 3D target detection
2.4 通道空间注意力机制对比实验
本文采取2种注意力机制CBM、SAM的对比实验,主要对比CBM、SAM加入位置及初始网络权重等在网络中发挥的作用。实验中,分别在骨干网络中的基本模块和骨干网络末端加入空间通道注意力机制。如图10所示,在骨干网络中加入空间通道注意力机制,使用预训练模型,新增注意力机制模块默认使用kaiming初始化网络权重,在训练180个迭代周期后,实验结果检测精度()仅为0.2094,效果并不理想。

图10 骨干网络中加入注意力机制示意图Fig.10 Schematic diagram of adding attention mechanism to the backbone network
将空间通道注意力机制加入骨干网络末端,如图11所示。首先,在冻结改进的DLA-34、DLAUP上采样层、IDAUP融合网络层后,训练60个迭代周期,然后再联合训练60个周期,即上升至0.5274。实验得出结论是:注意力机制在迁移学习方法下,加入到骨干网络末端和检测头相比于骨干网络中效果更优。

图11 骨干网络末加入注意力机制示意图Fig.11 Schematic diagram of adding attention mechanism at the end of backbone network
2.5 实验结果可视化分析
本文对基础网络模型和毫米波雷达与相机两级融合的网络模型的检测效果的可视化比较结果如图12、图13所示。从可视化效果可以看出:2种方法均能实现较好的3D目标检测效果,但本文的方法对远距离小目标漏检率低,且具有更强的鲁棒性;相比来看,本文方法的3D边界框更加准确,在一些特定场景中,误检率明显降低。

图12 Centerfusion可视化效果图Fig.12 Centerfusion visualization

图13 两级融合网络可视化效果图Fig.13 Visual renderings of two-level fused network
3 结束语
本文在毫米波雷达和相机特征层融合网络Centerfusion的基础上进行改进,针对原算法在一阶段未考虑单目检测固有缺陷的问题,提出了一种毫米波雷达与相机两级融合的3D目标检测算法,将雷达点云信息进行处理后,在数据层和特征层均进行融合;同时在一阶段中心点检测网络中加入了注意力机制。实验证明,本文方法相比原算法在复杂恶劣天气条件下以及对远距离小目标的检测效果上均有提升,在大型自动驾驶数据集nuScenes3D检测基准上,评估了本文提出的方法,相比Centerfusion检测分数()有了一定提升。
