基于ANN的异构多核动态映射方法
2022-11-05李建华周义涛赵玉来胡海洋
李 阳,李建华,2,周义涛,赵玉来,胡海洋
(1 合肥工业大学 计算机与信息学院,合肥 230601;2 合肥工业大学 情感计算与先进智能机器安徽省重点实验室,合肥 230601)
0 引言
随着应用程序对计算能力需求的逐渐增长,以及半导体技术的逐步演进,多核处理器的核心数量一直在增加。异构多核架构通过在同一平台上集成多种类型的处理核,使得应用程序可以根据自身需求选择不同的核心组合来更加高能效地完成任务。因此,异构多核平台相比于同构多核平台拥有更高的灵活性,并且可以更合理地利用片上资源。目前,异构多核平台已经成为了当今嵌入式系统的主流解决方案。充分发挥异构多核系统的优势需要高效的程序映射方法。
程序映射可以分为静态映射和动态映射。其中,动态程序映射可根据程序的阶段性特征以及不同类型处理核的特点进行映射的动态调整,能更充分地发挥平台的性能优势。静态程序映射是在设计时进行的,因此可以使用计算密集型搜索方法或精确的系统级映射模拟来寻找最佳或近最佳的映射解决方案。但是,通常情况下却无法处理(未知)动态工作负载。一个程序在其生命周期中可执行数百万、数十亿条、甚至更多的指令,并且其运行时的特征也在不断地变化。一个高效的映射算法应该能够根据这些变化的特征预测程序不同时刻在不同类型的核心上运行可获得的性能,以便获得更好的能效比。
近些年来,人工神经网络(Artificial Neural Network,ANN),是人工智能领域的研究热点之一。ANN是由多个具有层次和连接关系的神经元相互连接而成,一个完整的人工神经网络是由输入层、输出层和隐藏层三部分组成。其中,输入层负责接收和传递信息,不进行任何计算。隐藏层位于输入层和输出层之间,可以与输入层和输出层相连,不同的隐藏层间也可以互相连接,这些连接都被赋予了一个数值权重,该权重与相应的输入参数相乘后,再与神经元其他传入连接的结果相加。接下去,这些总和被传递到神经元的激活函数中,通常选用的是一个线性函数。如此处理后的神经元输出将继续输入到下一层神经元或输出神经元。总地来说,ANN可以通过合理的网络结构拟合任意的非线性方程,因此ANN在数值预测和分类输出方面都有着巨大的潜力。
ANN正在被广泛地应用于各种领域,例如情感分析、预测估计、生物医学等。虽然ANN的应用受到越来越多的关注,但是到目前为止,将其应用于多核异构平台映射算法上的研究却仍处于起步阶段。为此,本文提出了一种基于ANN的异构多核动态映射方法AbDM。
AbDM的主要目标是最大化异构多核平台性能,在给定多个应用程序和一个具有多种不同类型核心的异构平台上,通过动态调整应用到核心的映射来实现目标。首先,使用基于ANN的性能预测器根据一段时间内的执行参数,预测每个应用下一阶段在不同类型核心上的性能。随后,重映射检测算法判断是否需要执行重映射。最后,若需要重映射,则由线程到核心类型匹配算法利用获得的性能值,确定应用到核心的映射。
本文的主要贡献如下:
(1)提出了一种线程到核心类型的匹配算法,在充分发挥平台性能优势的同时节省线程到核心类型绑定的时间。
(2)提出了一种重映射检测算法,当线程执行阶段发生变化时触发重映射过程,从而避免过于频繁的重映射,减少重新映射的时间和成本。
(3)提出了一种基于神经网络的性能预测器,将运行参数作为模型输入,预测性能。
实验结果证实本文提出的AbDM和轮询调度算法(RRS)相比平均每个时钟周期执行的指令条数()提高了63%左右。
本文其余部分组织如下:第一节介绍了相关研究工作;第二节阐述了本文提出的AbDM的具体实现;第三节对本文方法进行了实验验证和分析;第四节则总结了本文工作并展望了未来的研究方向。
1 相关工作
异构多核平台上的应用映射在开发计算资源的多样性方面发挥着关键作用,对此已经有数十年的研究积累。一般情况下对于异构多核映射问题大都采用一个线程映射到一个处理核心的模式。当前针对异构多核架构映射问题的研究可以分为3类:离线、在线和混合(离线分析后在线使用)方法。为了找到近似最优的映射解决方案,现有研究大多采用基于搜索的方法,结合一些分析来评估考虑的映射与设计需求之间的关系。
对于离线方法,在离线状态下充分探索这些不同场景的资源分配,从而为每个场景指定一个最优或接近最优的资源分配方案。例如,文献[7]提出了一种静态调度方法,这是一种基于种群的新算法,可以在运行时动态切换探索性和开发性搜索模式。静态调度器可以执行任务映射、调度和电压缩放。在文献[8]中,提出了一种算法来优化异构上应用程序的整体运行时间多核处理器。该算法将模拟退火和剪枝策略的组合,用于搜索应用程序和平台之间的最佳映射。上述离线方法通常使用离线分析来确定映射方案,虽然简单、但会产生额外的分析开销,并且没有充分考虑在线程序在执行过程中的动态变化。
与离线方法相比,在线资源管理缺少离线预处理阶段。一般每个应用程序占用的资源都是在运行时动态调整的。这种方法的资源分配计划是在运行时计算出来的,方法的目的则是为了在短时间内得到一个比较好的资源分配计划。例如,文献[9]中提出的方法首先根据性能要求和资源可用性选择线程到核心的映射。然后,通过调整电压频率()水平来应用在线自适应,以在不牺牲应用性能的情况下实现能量优化。研究可知,在文献[10]中已有学者提出了一种基于机器学习的方法来增加异构多核平台上的平均故障工作量,最终结果表明该方法的平均工作量增幅可以高达19.4%。在文献[11]中,还提出了一种不需要任何自身信息就能够在线对OpenCL应用进行功耗优化的一种自适应方法。
混合资源管理方法使用离线分析结果来做出运行时资源管理决策。第一步是在设计时进行全面的离线分析,并将分析结果集成到运行时控制器中,实现运行时的资源分配。例如文献[12]提出的方法,首先使用缓存分区技术来限制共享缓存的不可预测性,其次探讨核心频率的影响和缓存分区(CPs)对任务执行周期的影响及其对执行时间和能耗的影响。此外,文献[13]又提出了一种自适应映射方法。首先,使用性能监控计数器进行在线数据收集,然后使用离线训练性能预测模型来应用不同类型的数据。预测应用程序的性能,最后评估和选择资源组合(处理核心的数量和类型)。仍要提到的是,该方法还设置了一个资源管理器来监控应用程序性能、工作量,以及应用程序完成和新应用程序的到达情况,再以此来调整映射。
离线方法是设计时进行的,能够找到最优或者接近最优的映射方案,但是通常却无法处理动态工作负载问题。而在线方法能够解决动态工作负载问题,但是由于运行时计算能力有限,可能最终获得的映射方案不是最优方案或者接近最优的映射方案。混合资源管理方法结合了离线和在线的优点,可以在离线的时候对不同的应用场景进行充分的分析,也可以在运行时根据不同的执行场景动态地调整映射方案。所以目前混合资源管理方法获得了十分广泛的应用。
综上,本文采用混合资源分配方案来实现资源分配,可以充分考虑不同类型线程的运行时特性和不同内核的处理能力,从而最大限度地发挥平台的处理能力。
2 基于ANN的异构多核动态映射方法
本节主要介绍文中所提出的AbDM方案,图1给出了其总体框架。给定一组线程和一个异构多核平台,映射器首先为每个线程随机分配一个空闲核心。同时,收集必要的运行时信息,用来进行性能预测。然后,重映射检测器根据预测所得的性能判断是否需要执行重映射。在需要执行重映射的情况下,由线程到核心类型匹配算法,将线程和核心进行匹配,从而实现IPC优化。
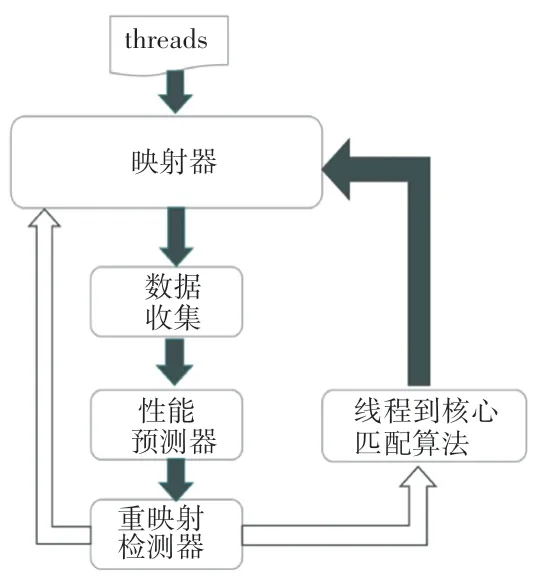
图1 AbDM总体框架Fig.1 Overview of the proposed approach,AbDM
2.1 问题定义
在本文中,通过个线程(,,,t)在的多核平台上执行,表示为{,…,C,…,C},其中C表示核心位于2网格的第行和第列。每个核C属于种核类型的一种、表示为{,,…,c},并且可以独立地执行DVFS(Dynamic Voltage and Frequency Scaling)。本文所提出的AbDM方案使用每个时钟周期所执行的指令数、即指令数/周期(Instructions Per Cycle,)作为性能指标。
由于程序运行在其生命周期中经常会发生一些阶段性的变化,并且不同的阶段有着不同的运行时的特征。所以,需要周期性地收集程序运行过程中相关特征数据。
2.2 运行时参数收集
AbDM需要周期性地收集必要的运行时参数数据,以进行动态的重映射决策。AbDM收集的参数如下:
(1)用于监视在特定内核上运行线程的性能的值。
(2)缓存缺失,包括:一级数据缓存命中缺失率、二级缓存命中缺失率、三级缓存命中缺失率,以及读内存指令、写内存指令、浮点加法指令、浮点减法指令、浮点乘法指令和浮点除法指令。
2.3 性能预测器
为了将线程分配给异构多核系统中的特定核以最大化性能,必须了解每个线程在各种类型的核上的执行情况。实现这一目标的一种方法是在所有类型的内核上在线执行线程,并相应地采取最佳分配。这显然并不适用于在线映射方法,因为需要用到复杂的运行时迁移和性能度量。另一种方法是通过只在一种核心类型上运行(参见文献[7])来获得不同类型核心的线程性能。这种方法需要在设计时或运行时构建性能预测模型。由于运行时的学习模型可能会使动态映射方法不可扩展,并且还将引入太多的开销。类似于文献[5,13]中的做法,本文选择在设计时使用机器学习技术为所有类型的核构建预测模型。
2.3.1 参数的选取
应用在某类核心上执行的不仅取决于当前执行的类型,还和硬件资源相关。因此,需要将一些应用统计信息及执行参数作为预测器的输入参数。根据文献[16-17]中的方案所选择的参数和属性,本文选取了9个与相关的参数来构建ANN学习模型。参数分别是缓存丢失率(一级数据缓存命中缺失率、二级缓存命中缺失率、三级缓存命中缺失率),以及读内存指令、写内存指令、浮点加法指令、浮点减法指令、浮点乘法指令和浮点除法指令。
2.3.2 参数的预处理
由于模拟直接收集的输入参数的统计量可能具有不同的尺度(例如,缓存失效率低于1,而指令数可达数千万),因此需要对输入参数做预处理,以确保输入参数具有相同的尺度。另一方面,为了使用统计信息作为不同核心类型的性能预测的输入,统计信息应该尽可能通用。将统计数据规范化为比率可以确保神经网络输入的一致性,当使用从小核心收集的数据进行训练的时候,但却可能是使用从大核心收集的输入统计数据进行预测的。因此,本文将不同类型的指令数转换为指令比。
2.3.3 模型结构
在本文的ANN网络的输入层是由9个神经元组成,用来接收输入参数。一般来说,随着神经网络的隐藏层和隐藏层的节点数的增加可以降低网络误差、提高精度,但也会使网络复杂化,从而增加了网络的训练时间和出现“过拟合”的倾向。通过仿真实验,最终确定了性能预测器所使用的神经网络模型隐藏层数为27,并且使用作为激活函数。在损失函数和学习率方面,本文选用了最常用的均方误差(Mean Squared Error,)损失函数来对性能预测器进行训练,同时通过观察损失函数和学习率的关系,最终将学习率确定为0.001。
2.4 重映射检测器
一个程序在其生命周期中可执行数百万甚至数十亿条指令,运行中的行为通常经历阶段变化。在不同的阶段,可以观察到不同的执行特征。因此,不能在每个信息收集阶段进行重新映射,而是只会在检测到某些阶段变化时进行重新映射,用以降低重新映射的成本。
在论文中定义一个变化率,当变化超过一定范围时就会触发重映射,从而调用后面的线程到核心类型匹配算法,反之本阶段将不进行重映射。Δ定义公式如下,
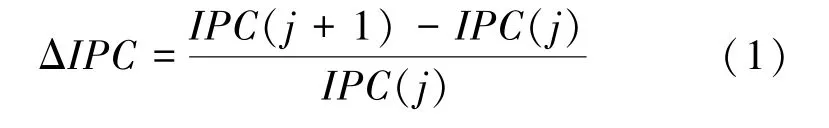
其中,()是阶段的,(1)是1阶段的预测。
2.5 线程到核心类型匹配算法
本文的目的是获得线程到核心的最佳映射,从而充分发挥异构多核平台的性能优势。本文所提出的线程到核心类型的匹配算法,以性能预测器所预测的下一阶段的各个线程到各种类型核心的值为基础,来确定线程拟将映射的具体核心类型。从而获得线程到核心的最优匹配,使得异构多核平台性能得以充分发挥,总的值达到了最大化。
本文中定义线程在核心类型上的值为(),并且类型核心的数量为。线程与核心类型的绑定表示为。是一个一维向量,其中第个位置的数表示线程映射到类型为的核心上。
线程到核心类型的匹配算法可分为4步:
初始化中的所有线程到核心类型的绑定,使得初始绑定为空(这里设为)。
对于所有类型的核心,根据性能预测器预测所得的值,将对应的线程进行排序。例如对于核心类型,预测所有线程下一阶段在此类核心上的值。然后根据预测映射所得的值,为对应的线程进行排序(值越大的线程越靠前),得到序列(_(…,t,…),_,…,_c,…)。
根据每种核心类型的处理能力,对核心类型进行排序,得到_(…c…)。
为了最大限度地提高系统性能,需要优先选择使用更强大的核心。因此,本算法的核心思想是根据线程处理能力的顺序(由_表示)将线程分配给内核。首先依据序列_中核心的顺序,依次查看该核心对应的序列中的前|c|个线程的分配情况。若当前线程未被分配,将线程分配到当前核心。反之,若已经分配,则将线程映射到所得较大的核心上。映射后获得的值较小的核心对应的序列上空出的核心位置,由对应的序列第|c|开始的第一个未被分配的线程补上。研发得到伪代码详见如下。


3 实验评估
为了评估AbDM的性能,本文基于Sniper模拟器搭建了一个异构多核平台,用来模拟不同应用在实际运行中的行为。并且,将AbDM与常见的轮询调度算法(Round Robin Scheduler,RRS)进行对比,用来分析AbDM方法的优势。
轮询调度主要是通过交换在大核上执行的线程和在小内核上执行的线程进而实现对性能的优化。之所以选择轮询调度进行对比,是因为轮询调度算法可以在Linux调度程序和公平感知调度程序上为单线程和多线程工作负载提供性能改进。
3.1 实验设置
实验使用模拟器Sniper搭建了一个4行4列的异构多核平台。该平台由2种处理能力不同的核心组成,这2种核心称为大核和小核,大核与小核各占两行,具体如图2所示。并且本文中的大核和小核的指令集架构均基于Intel Nehalem x86架构,且处理核的主频均为2.66 GHz,发射宽度均为4,2种类型的处理核具有相同的缓存架构。其中,Cache为256 KB,Cache为512 KB,共享的Cache大小设置为8 MB。大核拥有128的指令窗口大小和长度为48的读取队列,而小核的指令窗口大小为16,读取队列长度为6。频率调节的步长为0.2 GHz,对于每个频率,电压的设置参照文献[22]。

图2 Sniper模拟器布置的16个核心的系统平面图Fig.2 Floorplan of a 16-core system simulated in Sniper
从基准测试SPLASH-2中选择了10种不同的应用,并且将这些应用组成不同的分组,将分组内的所有程序在搭建的模拟平台上并发执行,用来模拟现实世界的程序执行情况。具体的程序组合见表1。

表1 应用程序组合Tab.1 Combination of programs
3.2 实验结果与分析
为了更好地评估本文提出的方法,实验分别对性能预测器、应用到核心的匹配算法以及AbDM整体进行评估。从局部和整体两个方面对本文提出的算法进行仿真测试。
3.2.1 性能预测器的评估
针对2种类型核的16核平台,实验中搭建了2种人工神经网络模型。一种是根据小核的线程执行信息来预测大核的,另一种是根据大核的线程执行信息来预测小核的。根据小核的线程执行信息来预测大核的的模型称为,根据大核的线程执行信息来预测小核的的模型称为。2种神经网络模型都是使用上述的不同应用组合所收集的数据集训练得到的,数据集的收集周期为30 ms,即每隔30 ms收集一次用以训练性能预测器的参数的数值。
为了更好地评估AbDM的性能,实验用10个splash-2基准应用作为和模型评估的测试集。图3给出了和预测不同应用的误差。从图3中可以看出,2个预测模型在应用barnes上均取得最小误差,同时在应用volread上的效果也最不理想,但是即使在最差情况也仅为031,并且和的平均仅为0.15和0.17。由实验数据还可以看出,总体上,大核性能预测器和小核性能预测器均具有较好的预测效果。
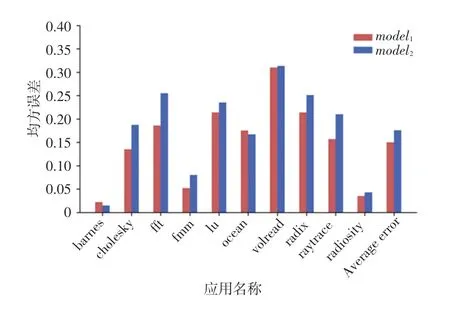
图3 预测器误差Fig.3 MSE of ANN predictor
3.2.2 线程到核心类型匹配算法的评估
本部分通过将线程到核心类型匹配算法与穷举算法进行比较,来评估算法的性能。具体的比较有2方面。一方面是线程到核心类型匹配所需的时间,另一方面是匹配后所获得的值。
通过设置不同的线程数、核心类型数以及每种核心的数量,来对比本文提出的线程到核心类型匹配算法与穷举法的性能。例如表2中,组合1表示的是4个线程运行于拥有2种不同类型核心的异构平台上,并且2种类型的核心数量都是4个。对于穷举算法来说,算法考虑了所有线程到核心类型匹配的可能性,故毋庸置疑可知,穷举算法获得的值是最大值。接下去,由表3的实验结果可知,随着测试配置越来越复杂,穷举法所耗费的时间增长速度远远高于本文提出的方法,并且在配置6的时候,穷举法没有时间结果,是由于运行时间超过了0.5 h,为此停止了实验。在总的值方面,本文提出的方法可以接近于最优值。能够非常有效地获得接近最优的解。
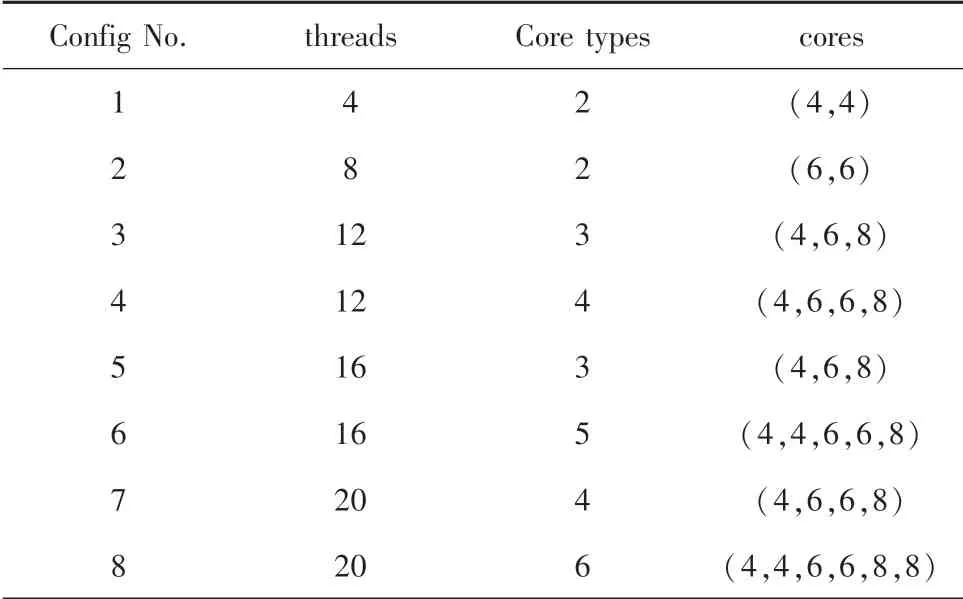
表2 异构多核配置Tab.2 Heterogeneous multi-core configuration
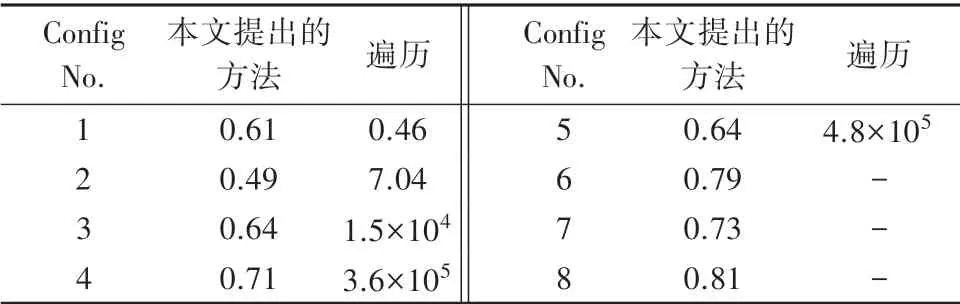
表3 本文提出的方法与遍历法的运行时间Tab.3 Running time of the method proposed in this article vs.the traversal method ms
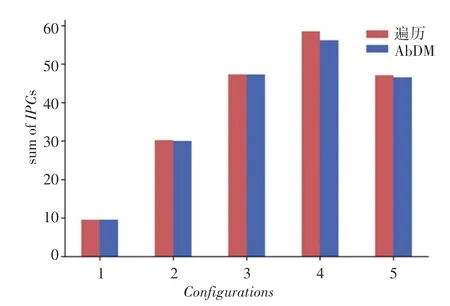
图4 AbDM与遍历法所获得的IPC对比Fig.4 Comparison of IPC obtained by AbDM vs.IPC obtained by the traversal method
3.2.3 对基于神经网络的异构多核动态映射方法的评估
为了评估AbDM与现有技术相比的优劣,实验中使用RR作为基准方法,并对8个应用程序组合进行实验,以观察本文提出的方法与RRS比较所实现的加速比。
AbDM和轮询调度的加速比如图5所示。图5中,横坐标表示不同的程序组合所对应的编号,纵坐标表示本文提出的方法与RR比较所获得的加速比。从图5中可以看到,AbDM在所有的8种实验配置下效果均优于轮询调度算法,并且平均吞吐量提高了63%。这是因为AbDM考虑到了程序生命周期中的阶段性变化,为不同阶段的程序选择适合当前阶段的核心类型,从而最大限度地发挥异构多核平台的性能优势。另一方面,AbDM执行更少的重映射计算,每隔一个特定的周期进行一次重映射检测,当且仅当满足重映射条件是触发重映射。
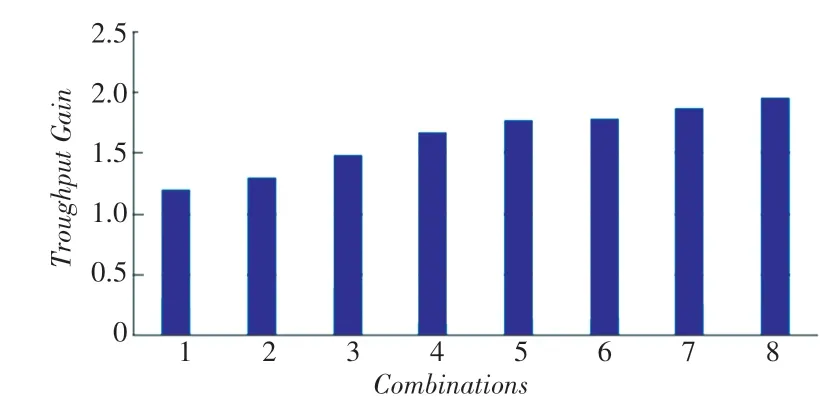
图5 AbDM和轮询调度的加速比Fig.5 Acceleration ratio of the proposed method and RRS
4 结束语
本文提出了一种基于神经网络的异构多核动态映射算法。该方法首先根据执行阶段不同线程的特点,通过人工神经网络预测不同类型核上各线程下一阶段的值。然后,重映射算法确定是否需要重映射,并在必要时执行重映射算法。反之,若无需重映射,则保持当前映射不变。仿真实验结果表明本文提出的方法相对于传统的轮询算法优势明显,平均吞吐量提高了63%。
此外随着处理核数量的增加,处理器中晶体管密度同步提高,现代多核处理器具有更高的功率密度,进而导致芯片温度也有同步升高,最终会对系统性能造成一定的负面影响。所以在未来的工作中,会考虑引入一个新的参考因素热安全。在保证热安全的前提下,最大化异构多核平台的性能。
