标签敏感的多重集正交相关特征融合方法
2022-10-29赵前进平昕瑞苏树智
赵前进 平昕瑞 苏树智 谢 军
①(安徽理工大学数学与大数据学院 淮南 232001)
②(安徽理工大学计算机科学与工程学院 淮南 232001)
1 引言
近年来,随着大数据技术的发展,人们对不同属性不同种信息的有效融合有很大的需求。特征融合[1]是一类重要信息融合方法,受到了广泛的关注。从同一样本中提取的多重特征能反映出该样本的不同特性。特征融合目的是对不同的特征进行优化和组合,以达到更好的分类性能。特征融合方法的优点在于能够组合不同特征,既保留多特征的有效判别信息,又在一定程度上消除冗余信息。在特征融合中,直接连接或集成不同类型的特征是早期主要的特征融合方法。后来一种新的融合策略是将两组特征向量重构为一个新的向量,分别称为串行融合方法和并行融合方法。这两种特征融合方法都能在特定范围内提高识别能力。但是上述方法都忽略了两特征集之间的内在相关性,无法实现有效的特征融合。为了获取能反映两组特征内在相关性的特征对,典型相关分析(Canonical Correlation Analysis,CCA)[2]同时学习了两组特征向量的相关投影方向,使投影后的典型特征组之间具有最大的相关性。
基于CCA的方法首先从同一模式下提取两个不同的特征向量,然后建立相关准则函数,从两组特征向量中提取典型相关特征,最后形成有效的判别特征向量,用于模式识别。CCA方法早期是用于多元数理统计分析。目前已经广泛用于神经科学[3]、情感识别[4]、故障检测[5,6]、过程监控[7]、遥感图像[8]等领域。CCA方法能很好地获取两样本之间的相关性,但是这种相关性并不能体现样本类的关系,即没有使用样本的类标签信息。通过引入类标签信息,Gao等人[9]又提出一种新的多模态融合方法称为鉴别典型相关分析,该方法同时最大化类内相关性及最小化类间相关性,使用鉴别信息进行特征融合,更适合于图像识别任务。
CCA作为一种线性的特征融合子空间方法,难以发现两组特征间的非线性关系。目前处理非线性关系的方法主要有基于核函数的方法和基于深度准则的方法。核典型相关分析[10]运用核技巧将数据非线性地转换到一个更高维的核空间,在核空间中原始的非线性数据具有高维线性可分的性质,在盲源分离[11]中核典型相关分析已经被广泛应用。类似核典型相关分析,深度典型相关分析方法[12]是一种两视图非线性数据转换到高度线性相关的方法,在前馈神经网络[13]中普遍使用,同样能够实现非线性数据的融合。在模式识别领域,正交性[14]是一种常用的投影方向的冗余判别标准。正交投影方法的优势在于对数据分布和噪声的影响不敏感,在特征提取融合过程中尽量保持样本间的欧氏距离。Wang等人[15]在CCA中加入正交约束,提出一种新的正交典型相关分析方法。这是一种通过双特征分解获取正交典型投影向量的方法,在训练样本较小且维数高的情况下会有更高的识别率和鲁棒性。
经典CCA局限于描述双重特征数据集合间的一般线性关系,通常情况下,一组目标如果用多重特征数据集来表示,能更加全面展现出这组目标的特征关系,多重集典型相关分析[16]是CCA由两组特征数据向多组特征数据的自然推广,能够同时融合两组或两组以上的特征数据,具有更广泛的应用基础。通过多重集典型相关分析能够实现多组数据的特征融合,用来分析多变量间的线性关系。结合标签信息,Gao等人[17]提出基于标签的多重集典型相关分析方法,该方法利用训练样本的类内散布矩阵和多变量相关矩阵来提取鉴别信息,提高了最终识别能力。结合图结构信息,Chen等人[18]提出图多视角典型相关分析(Graph Multiview Canonical Correlation Analysis, GMCCA)方法,通过图嵌入方法捕捉每个视角的低维表示,分析数据间的内在关系。
本文结合正交约束准则和监督散布结构提出一种标签敏感的多重集正交相关特征融合方法,即多重集鉴别正交典型相关分析(Multi-set Discriminant Orthogonal Canonical Correlation Analysis,MDOCCA)。本方法在典型相关分析理论基础上,将监督散布结构和正交投影约束嵌入到相关特征融合框架,实现了两组或两组以上特征的鉴别融合,并且融合后的特征不仅拥有更好的的鉴别力,而且又能一定程度上减少信息的冗余。为了验证提出算法的有效性,在佐治亚理工大学(Georgia Tech, GT)图像数据集、英国剑桥奥利维蒂研究实验室(Olivetti Research Laboratory, ORL)图像数据集、西班牙计算机视觉中心(Aleix martinez, Robert benavente,AR)图像数据集和美国卡耐基梅隆大学 (Pose, Illumination, Expression, PIE)图像数据集上的良好实验结果表明提出的方法是有效的特征融合方法。
本文其余内容分布如下:第2节是对CCA的方法进行回顾;第3节是详细描述MDOCCA方法的模型构建和优化求解;实验和总结分别在第4节和第5节。
2 CCA方法回顾
CCA的目的是找到两组变量的成对基向量,这两组变量在这些基向量方向上的投影最大相关。因此,所有的有效信息都通过投影得到最大限度的保留。
3 多重集鉴别正交典型相关分析
CCA方法本质上是一种线性无监督的特征融合方法。能够实现两组特征的线性融合,然而由于CCA忽略了样本的类信息,导致了识别性能的局限性,并且CCA方法构造的子空间是共轭正交的,受样本个数和维数的影响较大,对数据分布和噪声的影响较为敏感。为了使融合后的特征具有更好的鉴别力,本文将监督散布结构和正交投影约束嵌入到相关特征融合框架,以提取更多的判别特征和降低数据分布和噪声的影响,从而提出一种新的MDOCCA方法,实现了两组或两组以上特征的鉴别融合。MDOCCA的优势在于:(1)降低数据分布和噪声的影响,受个体和维数的影响较小;(2)保持样本间的欧氏距离,消除冗余信息;(3)加入样本类信息,提高判别力;(4)能够同时融合两组或两组以上的特征,提高方法的适用范围。
该优化模型最大化不同组间变量间的相关差异,最小化同组变量内的相互差异。下一步对上述模型加入正交准则,正交性可以更好地保留特征空间的度量结构,使提取的投影方向尽可能不相关,减少特征中存在的冗余。可以将该模型重写为
式(6)的模型不仅可以保留其中最大化不同组间关系,最小化组内关系的性质,还具有正交性,能减少数据分布和噪声的影响,保持样本间的欧氏距离。
类标签信息可以反映样本类之间的关系,如果忽略这种关系,则会导致得到的特征不是最优分类,损失识别性能。本文模型为了增强鉴别力,通过构建视图内类内散布矩阵,将类标签嵌入模型中。具体模型为
此模型既包含样本组间相关关系,又含有类标签信息和正交约束,有助于提高鉴别力。式(7)是一个典型的带有约束的多元函数极值问题,拉格朗日乘数法是解决这类问题的常用方法。
利用拉格朗日法对方程式(7)进行求解得到
4 实验结果和分析
为了验证所提方法的有效性,在GT图像数据集、ORL图像数据集、AR图像数据集和PIE图像数据集上设计了一些针对性实验来评估本文所提方法的图像识别性能。对每幅图像经过模态策略处理获取不同的模态数据。使用Coiflets, Daubechies和Symlets正交小波变换分解技术获取每幅图像的3个低频子图像,并且为了减轻小样本问题影响,采用主成分分析(Principal Component Analysis, PCA)[21]方法将子图像的维数约简到100维。对于两变量集方法,本文将前两个低频子图像数据首尾相连组合在一起构成一个新的图像数据,与第3个低频子图像数据组合成两组变量。在实验部分,MDOCCA分别和图正则化多集典型相关(Graph regularized Multiset Canonical Correlations, GrMCC)[22]、判别多重典型相关分析(Discriminative Multiple Canonical Correlation Analysis, DMCCA)[9]、GMCCA, CCA进行对比分析。
4.1 在GT图像数据集上的实验
GT图像数据集采集共50个人的图像,每人15张不同角度、不同表情的正面照片,像素为640×480,图像表示格式为JPG。本实验分析方法如下,在图像数据集中每人分别选择n(n=5,6,7,8)幅图像作为训练样本,其余作为测试样本,总共进行10次随机试验。表1展示了在此数据集下不同训练样本在不同方法下对应的平均识别率。本文方法在不同训练样本数下对测试样本的平均识别率均是最高的,这体现了本文所提方法在人脸图像识别任务中表现更佳。
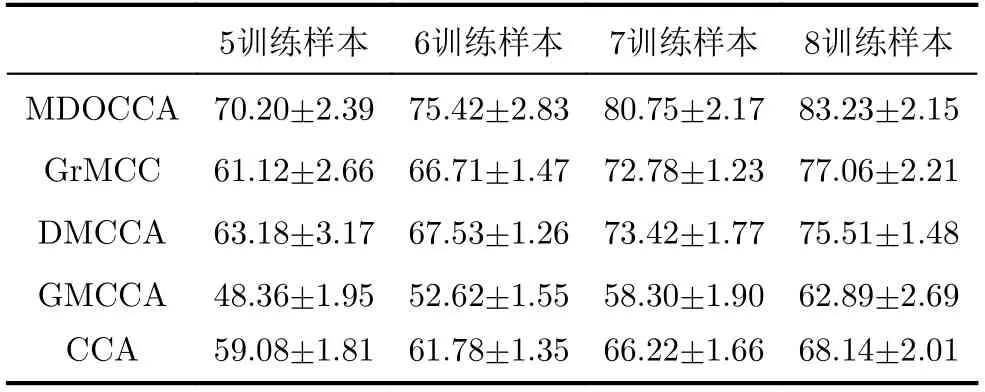
表1 在GT图像数据集上的识别率变化结果(%)
CCA对所有数据进行同等考虑,只是将投影结果相关性最大化,没有掌握数据中结构信息和类别信息,在图像识别中表现一般。DMCCA将监督信息加入到在相关性分析框架中进行特征学习,具有较好的识别率。GrMCC不仅最大化数据集间累积相关性,而且通过在集内数据上使用最近邻图来最小化局部类内分散,同时最大化局部类间可分离性,在一定程度上优于CCA。MDOCCA在引入类信息的同时加入正交约束,既能增加鉴别力,又能减少信息冗余,从而使融合的相关特征更具鉴别力。从图1不难看出,在不同训练样本数下,MDOCCA方法在10次随机实验中均展示出最佳识别率,与其他方法相比均保持稳定的优越性,说明MDOCCA方法提取的特征鉴别力更强。
4.2 在ORL图像数据集上的实验
ORL图像数据集共有400幅灰度图像,分别是在40个不同的对象里,每人采集10幅不同图像,像素为92×112。这些图像是在不同时间、光照遮挡、表情特征和面部细节条件下获取的。如表2所示,ORL数据集上的实验结果与GT数据集上的结果类似,CCA显示了较差的识别率, DMCCA在一定程度上有所提升,而本文所提MDOCCA算法仍然保持了最高的识别率,并且随着训练次数的增加,识别率变化平缓,这说明了本文所提方法具有良好的鲁棒性,同时也证明了正交性能的优势。这进一步表明,类信息的嵌入,能够有效提高低训练样本数下的识别率。
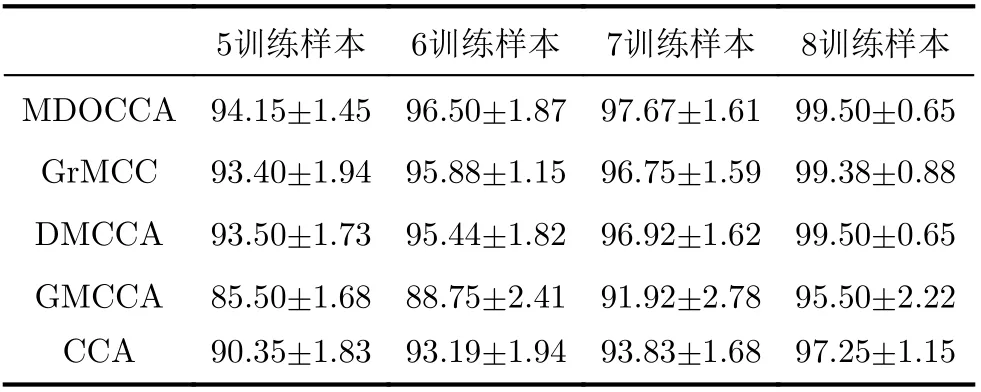
表2 在ORL图像数据集上的识别率变化结果(%)
4.3 在AR图像数据集上的实验
AR数据集包含120个不同人的一些图像,每个人14幅图像。表3中,本文所提MDOCCA方法仍然保持了最高的识别率。与GT和ORL类似,MDOCCA的识别率随训练样本数的变化更加顺滑平缓,同时拥有较小的标准差,正交约束带来的鲁棒性优势更加明显。
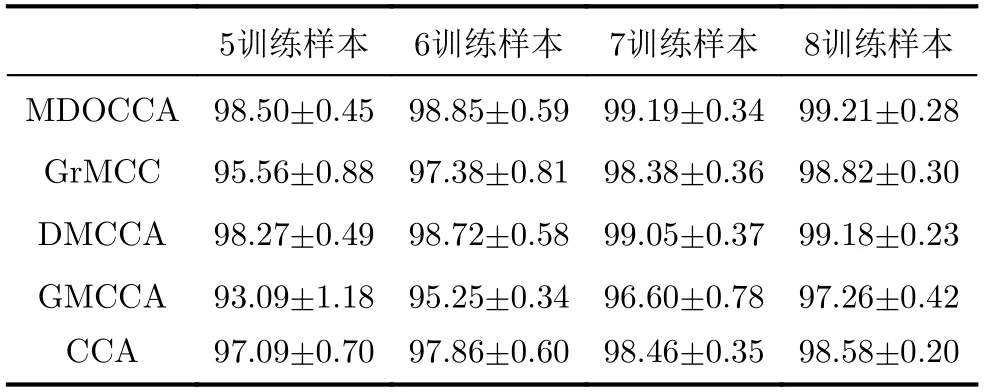
表3 在AR图像数据集上的识别率变化结果(%)
4.4 在PIE图像数据集上的实验
CMU PIE数据集包含68人在不同姿势、光照条件和面部表情下的41368张图像,在实验中选择了每人前70张图像,最终共有4760张图像。在图像数据集中每人分别选择n(n=10,15,20,25,30)幅图像作为训练样本,其余作为测试样本,进行10次随机试验。从表4可以看出,MDOCCA方法的识别率总是高于其他方法。MDOCCA和DMCCA将标签结构信息加入到相关性分析框架中进行特征学习,具有较好识别率,均在一定程度上优于其他方法,这说明标签结构的引入可以有效提高鉴别力。另外,MDOCCA在不同训练样本下均好于DMCCA,MDOCCA在引入类信息的同时加入正交约束,既能增加鉴别力,又能减少信息冗余,从而使融合的相关特征更具鉴别力。从表4不难看出,在不同训练样本数下,MDOCCA方法均展示出最佳平均识别率,说明MDOCCA方法提取的特征鉴别力更强。

表4 在PIE图像数据集上的识别率变化结果(%)
5 结论
CCA作为一种经典的多模态特征融合方法,没有考虑样本的类信息,无法发现嵌入在数据样本中判别信息,同时它构建的共轭正交投影系统,难以剔除隐藏在样本特征中的冗余信息,受样本个数和维数的影响较大。为此,本文在将经典CCA方法从两组数据扩展到多重数据基础上,提出了一种新的MDOCCA方法。本方法通过在目标函数加入类标签敏感信息,同时构造正交约束,嵌入到CCA的相关理论中去,进而得到了MDOCCA的优化模型。正交性可以保证融合的特征尽可能不相关,更具鉴别力。在GT图像数据集、ORL图像数据集、AR图像数据集和PIE图像数据集上设计针对性实验,良好的实验结果表明MDOCCA是一种有效的特征融合方法。
