面向空间应用的视觉位姿估计技术综述
2022-10-28刘延芳齐乃明佘佳宇
周 芮,刘延芳,齐乃明,佘佳宇
(哈尔滨工业大学 航天学院,黑龙江 哈尔滨 150090)
1 引言
随着世界各国对太空资源探索的深入,航天任务范围不断拓展,空间任务应用逐渐多元化,不再局限于通信、遥感、导航等传统领域,而是面向在轨服务、编队飞行、深空探测等新型任务,这些空间任务涉及非合作目标检测识别、绕飞接近、交会对接等过程。传统星地回路控制方法的地面测控站由于定姿定轨精度和通讯响应速度等的影响而不利于航天器自主任务完成。为保障新型空间任务的顺利完成,急需开展航天器对空间目标自主检测跟踪、轨迹规划、自主控制等方法的研究,目标位姿估计技术是其中的重点技术之一。
目标位姿估计技术是非接触测量技术领域的 重 点 研 究 方 向[1],在 空 间 操 作[2-5]、自 主 导航[6-12]、工业检测[13-15]、辅助医疗[16-17]等领域发挥着重要作用。精确位姿测量是完成空间任务诸如交会对接[18-19]、在轨装配[20-22]、在轨维修[23]等在轨服务任务[24-26]的关键环节。
空间任务[27-28]中常用的传感器技术有微波雷达技术[29]、激光雷达技术[30]、视觉测量技术[31]。微波雷达和激光雷达是目前常用来测量空间物体之间相对运动状态的有源主动式传感器,但由于功耗高、体积大和造价昂贵等因素,使得它们在实际工程应用中受到了很大的限制,难以应用在微小卫星平台上。视觉传感器因具有体积小、质量轻、功耗低、传感信息丰富等特点,使得基于视觉的测量技术在近距离高精度空间目标位姿估计任务中具有较大潜在优势[32]。特别是,随着处理器算力的大幅提高、图像处理技术的不断发展、深度学习算法的日新月异,航天器在轨装配、故障或失效卫星维修、太空垃圾清理等空间任务对空间目标位姿测量提出迫切需求,基于计算机视觉的空间目标位姿估计技术逐步成为研究热点[33]。
本文主要针对面向空间任务的视觉位姿估计技术进行综述。首先,归纳总结在空间任务中视觉位姿估计技术及应用,然后对视觉位姿估计技术进行概述,以深度学习算法作为切入点,系统地归纳了各种目标识别及位姿估计算法;最后,针对空间任务的特殊性,在任务需求和研究现状分析的基础上,对视觉位姿估计技术的发展趋势和应用进行展望。
2 空间任务中视觉系统的应用情况
随着空间对抗技术与装备的迅猛发展,构建空间态势感知系统已成为关系国家安全的重大战略问题。视觉系统在自动交会对接、主动碎片清除、在轨装配服务等空间任务中成为不可或缺的关键技术。
空间目标近距离位姿估计任务中一般涉及目标飞行器和追踪飞行器,目标飞行器按照三维模型是否已知或是否预先安装合作靶标分为合作目标[34]和非合作目标[35]。针对合作目标的近距离视觉位姿估计技术较为成熟[36],已经在轨应用。但对于空间垃圾、失效卫星等非合作目标,因其无法获取先验信息,也没有预先布设的合作靶标,其视觉位姿估计面临着许多技术挑战,仍有待深入研究[37]。稳定可靠的非合作目标的位姿估计对未来空间任务有重大意义[38]。视觉系统在空间任务中的发展如表1和图1所示。

图1 视觉空间任务发展Fig.1 Vision-based space mission development
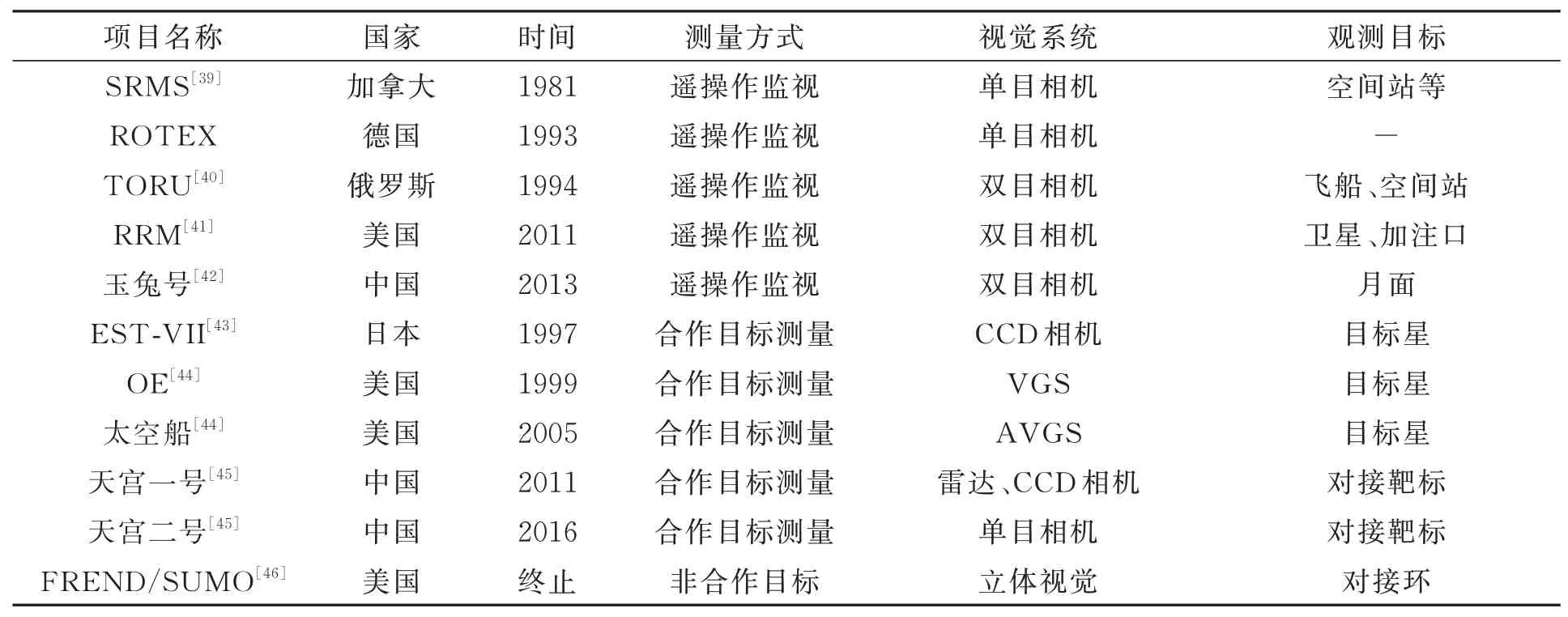
表1 视觉技术在空间任务中的应用Tab.1 Applications based on visual technology in space missions
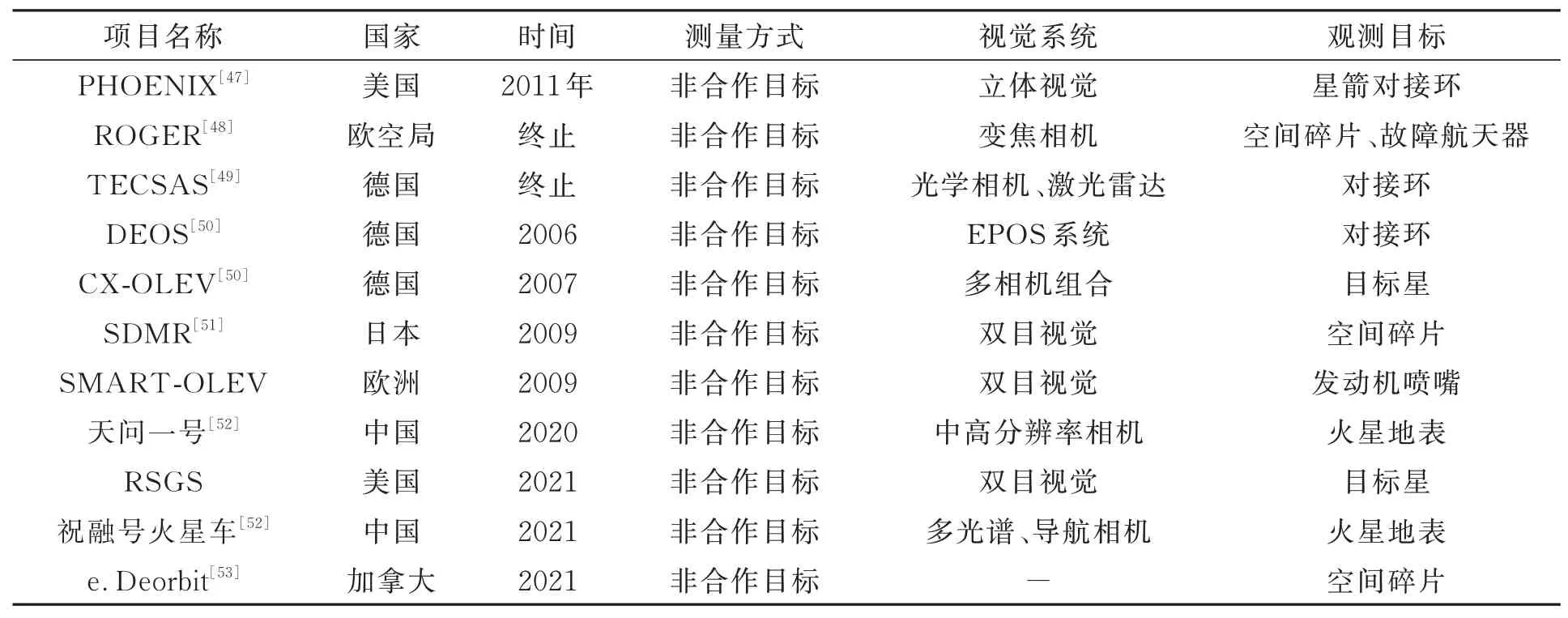
续表1视觉技术在空间任务中的应用Tab.1 Applications based on visual technology in space missions
2.1 空间遥操作
空间遥操作是最早应用视觉系统的空间任务,宇航员通过视觉远程操作完成空间任务,能避免出舱操作的风险,有明显优势。
1981年,加拿大研制出第一个航天飞机机械臂系统SRMS(Space Shuttle Remote Manipulator System),其具备遥操作功能,用来部署和回收卫星、勘探及抓获目标,在国际空间站装配任务中起到关键作用[39]。俄罗斯研制的遥操作交会对接系统TORU(Teleoperatornity Maneuvering Vehicle)成功应用于“和平号”空间站与国际空间站的交会对接任务;1994年,欧空局应用TORU遥操作系统实现了无人货运飞船ATV与国际空间站的交会对接[40]。此外,美国机器人燃料加注任务RRM(Robotic Refueling Mission)使用机械臂在两个相机监控下为服役卫星加注推进剂燃料[41]。2013年,我国“玉兔号”巡视器也采用了双目相机进行遥操作[42]。
2.2 合作目标位姿估计
空间遥操作方式受通信速率的影响,图像质量较差,通讯延迟较大,不能满足所有任务需求。因此,空间任务需要航天器自主完成。合作目标位姿估计技术能够根据已知信息自主完成位姿估计,得到测量信息。
1997年,日本川崎重工业公司研发出邻近敏感器用于ETS-VII上,采用100个红色二极管作为靶标,由CCD相机获取图像,得到相对位姿[43]。
1999年,美国开展轨道快车OE计划(Orbital Express),采 用NASA研 发 的VGS(Video Guidance Sensor)系统,对合作目标进行抓捕,过程中应用合作目标位姿估计技术。VGS系统经过 多 次 升 级,2005年,AVGS(Advanced Video Guidance Sensor)系统应用于DART太空船计划[44]。我国也开展了相关研究,2011年,利用合作靶标完成天宫一号和神舟八号交会对接任务[45]。
2.3 非合作目标位姿估计
随着航天技术的发展,空间任务不断升级,对空间碎片清理、失效卫星回收等非合作目标任务有更多的需求,非合作目标位姿估计尤为必要,越来越多的非合作目标位姿估计计划被提出。
美国DAPRA资助的前端机器人使能近期演示验证计划FREND(Fronted Robotics Enabling Near-term Demonstration)利用通用轨道修正器SUMO(Spacecraft for the Universal Modification of Orbits)平台,采用基于多目视觉的位姿估计方案,当航天器接近至100米处,选择最优角度的三个相机对目标成像,估计位姿[46]。2011年,在FREND计划的基础上,美国提出了凤凰计划(PHOENIX),该计划主要实现废旧卫星的维修及回收[47]。2002年,欧空局针对故障航天器及空间碎片等非合作目标,开展地球静止轨道清理机器人ROGER计划(Robotic Geostationary Orbit Restorer),采用变焦相机对非合作目标进行监视和抓捕,该项目于2003年终止[48]。2005年,德国开展空间系统演示验证技术卫星计划TECSAS(Technology Satellite for Demonstration and Verification of Space Systems),该计划于2006年终止[49]。在此基础上开展德国在轨服务DEOS(Deutsche Orbitale Servicing)项目,采用光学相机和激光雷达进行交会对接和重返大气层等近地轨道技术演示任务,利用欧洲接近操作模拟器
EPOS(European Proximity Operations Simulator)完成半物理仿真试验。此外,德国宇航局开发的静止轨道延寿系统(CX-OLEV)采用多相机组合的测量方式,使两个远场相机测量距离由2 km到100 m,两个中场相机测量距离由100 m到5 m,2007年,应用SMART-1卫星平台进行验证[50]。2009年,日本宇航探索局(JAXA)开展的空间碎片清理者项目SDMR(Space Debris Micro Remover)采用双目立体视觉系统,对非合作目标进行位姿估计,完成对目标的绕飞、接近及抓取[51]。2016年,美国DARPA提出地球同步轨道卫星机器人服务(RSGS),2021年进行试验验证,采用立体视觉系统对非合作目标进行机械排故、辅助变轨等。2012年,欧洲航天局启动e.Deorbit任务,于2021年进行相关试验验证,目的为清除800 km~1 000 km太阳同步轨道和极轨道上的大质量非合作目标[53]。此外,我国火星探测器“天问一号”及着陆器“祝融号”均搭载不同的相机载荷,用于导航及火星表面情况探测[52]。
综上所述,空间任务中的近距离目标位姿估计大多采用视觉测量系统。目前,针对合作目标位姿估计较为成熟,对非合作目标的位姿估计仍存在许多技术挑战。
3 视觉位姿估计方法
如图2所示,视觉位姿估计方法可分为传统测量方法[54]和深度学习方法[55]。传统测量方法包含目标识别和位姿估计两方面,其中目标识别分为基于特征匹配[56]和模板匹配方法[57],位姿估计分为基于点特征、线特征和边缘特征方法[58]。深度学习方法[59]分为基于目标识别网络的测量方法[60]和基于位姿估计网络的测量方法[61-64]。前者先采用目标识别网络得到关键点位置,再采用传统位姿解算方式得到位姿估计信息。目标识别网络又可分为一阶回归网络[65]和二阶区域候选网络[66]。而基于位姿估计网络的测量方法以图像为输入,直接由网络输出位姿估计结果。位姿估计网络按结构可以分为整体回归[67]和分类投票[68]。
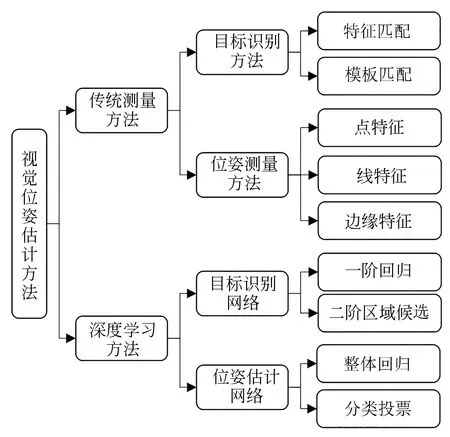
图2 视觉位姿估计方法分类Fig.2 Classification of visual pose estimation methods
3.1 传统视觉位姿估计方法
传统视觉位姿估计技术始于上世纪八十年代,目前在实际工程任务中已得到大量应用,其基本估计的算法流程如图3所示,包括图像预处理、目标识别和位姿解算等环节。
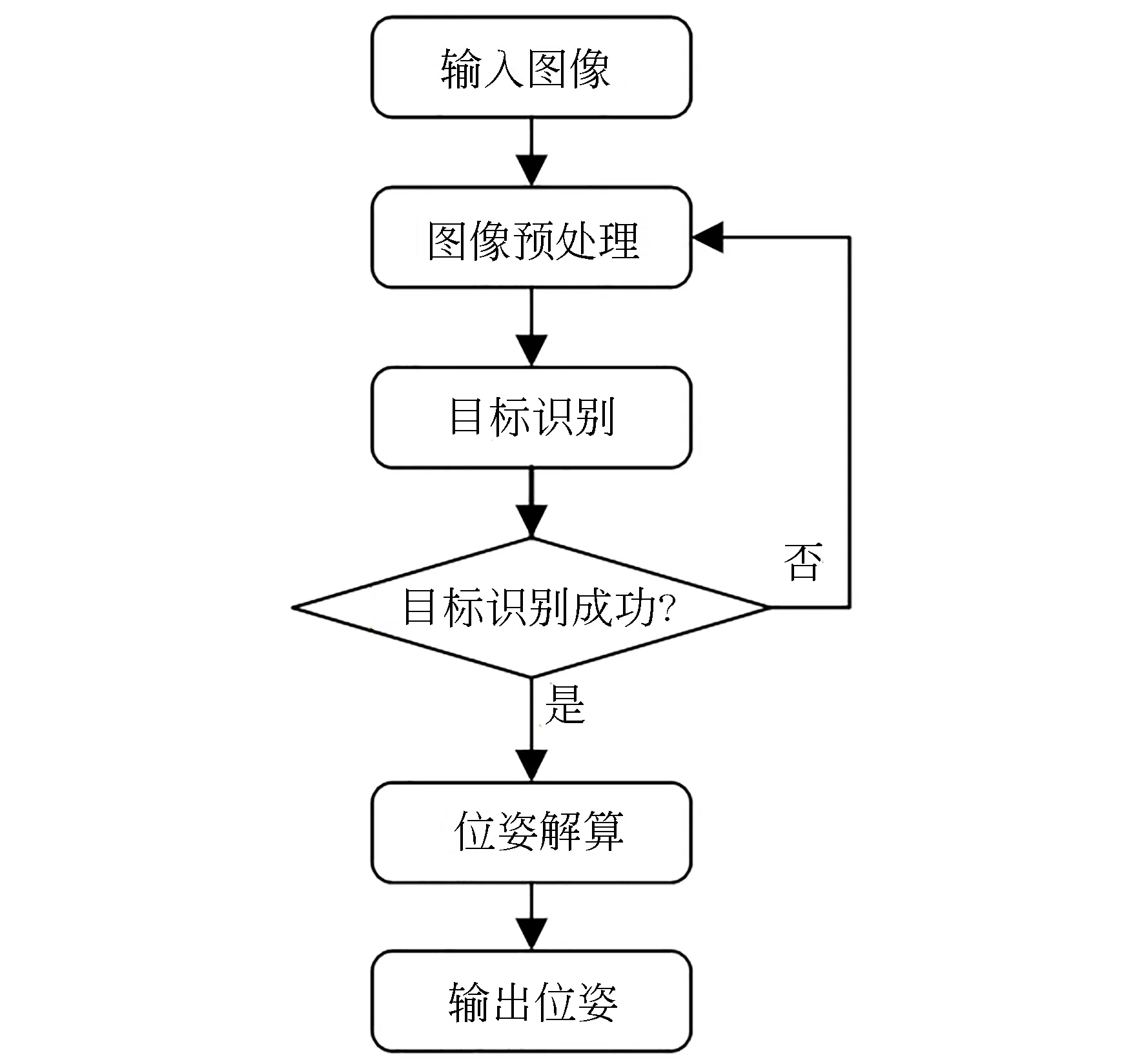
图3 传统视觉测量方法流程图Fig.3 Flowchart of traditional pose estimation method
传统视觉位姿估计方法需要依据先验知识设计特征,特定的场景下能够达到较高的检测速度和精度。但是,由于对先验知识的特别依赖,导致其自适应性及泛化性较差。
传统位姿估计方法比较成熟,文献[54]进行了较为详细的论述。但传统视觉方法需要手工设计特征,在背景复杂、高自主性的空间任务应用中存在自适应性差、鲁棒性低的问题。随着计算机视觉技术及人工智能的发展,基于深度学习的视觉位姿估计方法研究发展迅猛。
3.2 深度学习视觉位姿估计方法
基于学习方式的智能算法能够自适应地提取目标特征,有效地提高检测精度及泛化性,成为目前的研究热点。基于深度学习的视觉位姿估计方法主要可分为基于目标识别网络和基于位姿估计网络两类位姿估计算法,如图4所示。
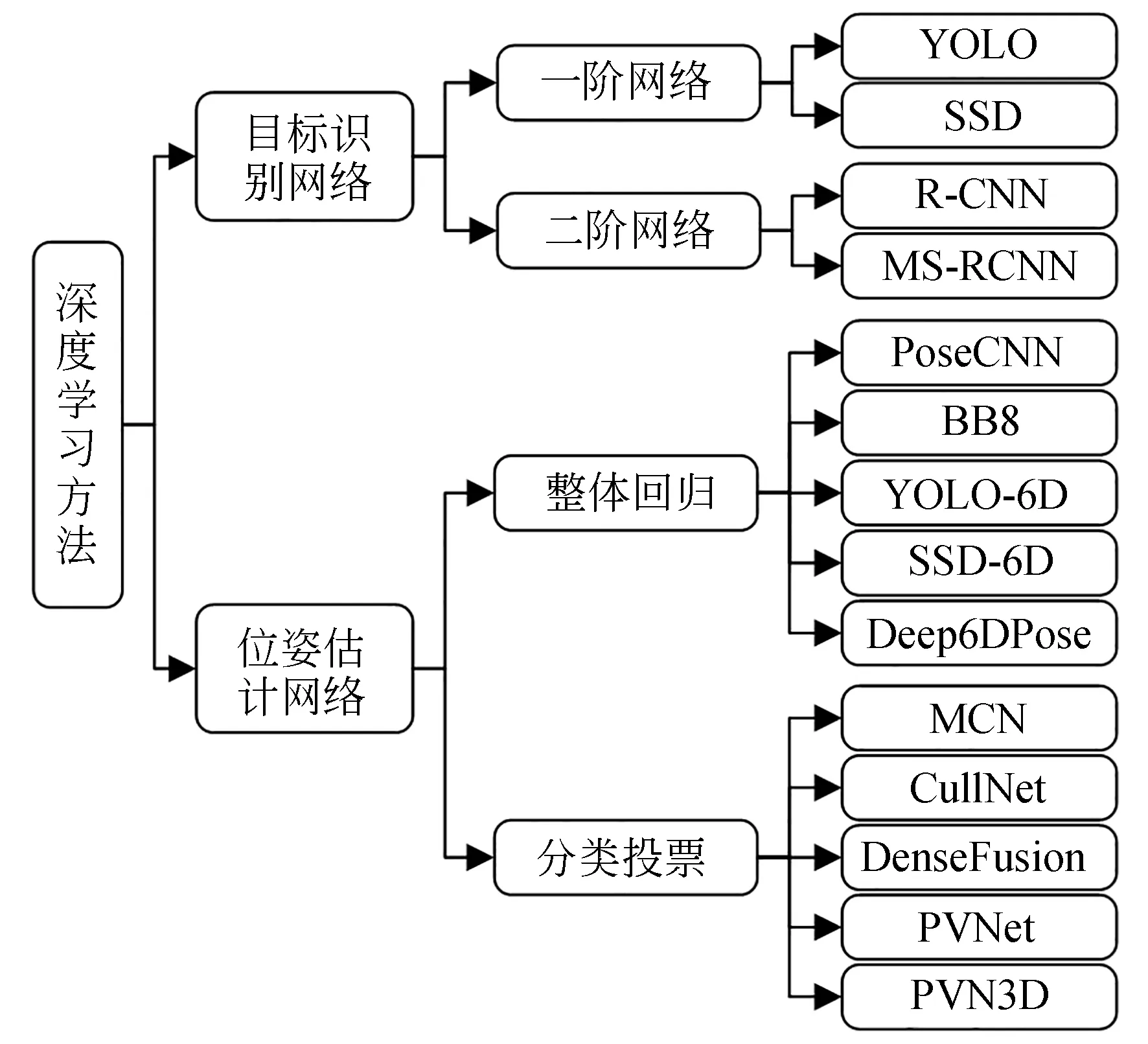
图4 深度学习视觉位姿估计方法分类Fig.4 Classification of visual pose estimation methods based on deep learning
基于目标识别网络的位姿估计算法先采用目标识别网络进行特征提取,得到关键点位置信息,再采用传统方式进行位姿估计。基于位姿估计网络的位姿估计算法直接由图像得到六自由度位姿估计结果,下面对目标识别网络和位姿估计网络展开论述。
3.2.1 目标识别网络
目标识别网络大多利用卷积神经网络进行特征提取、特征匹配、目标识别及关键点检测,主要可分为基于回归的单阶目标识别网络和基于区域候选的两阶目标识别网络。单阶网络通过卷积层、特征图、预测层直接输出目标识别结果;两阶网络在单阶网络的基础上增加区域候选网络,先筛选感兴趣区域,后进行目标识别,目标识别网络结构对比图如图5所示。图5中阴影部分为单阶网络,包含区域候选网络在内的总体网络为两阶网络。目标识别网络对比见表2。
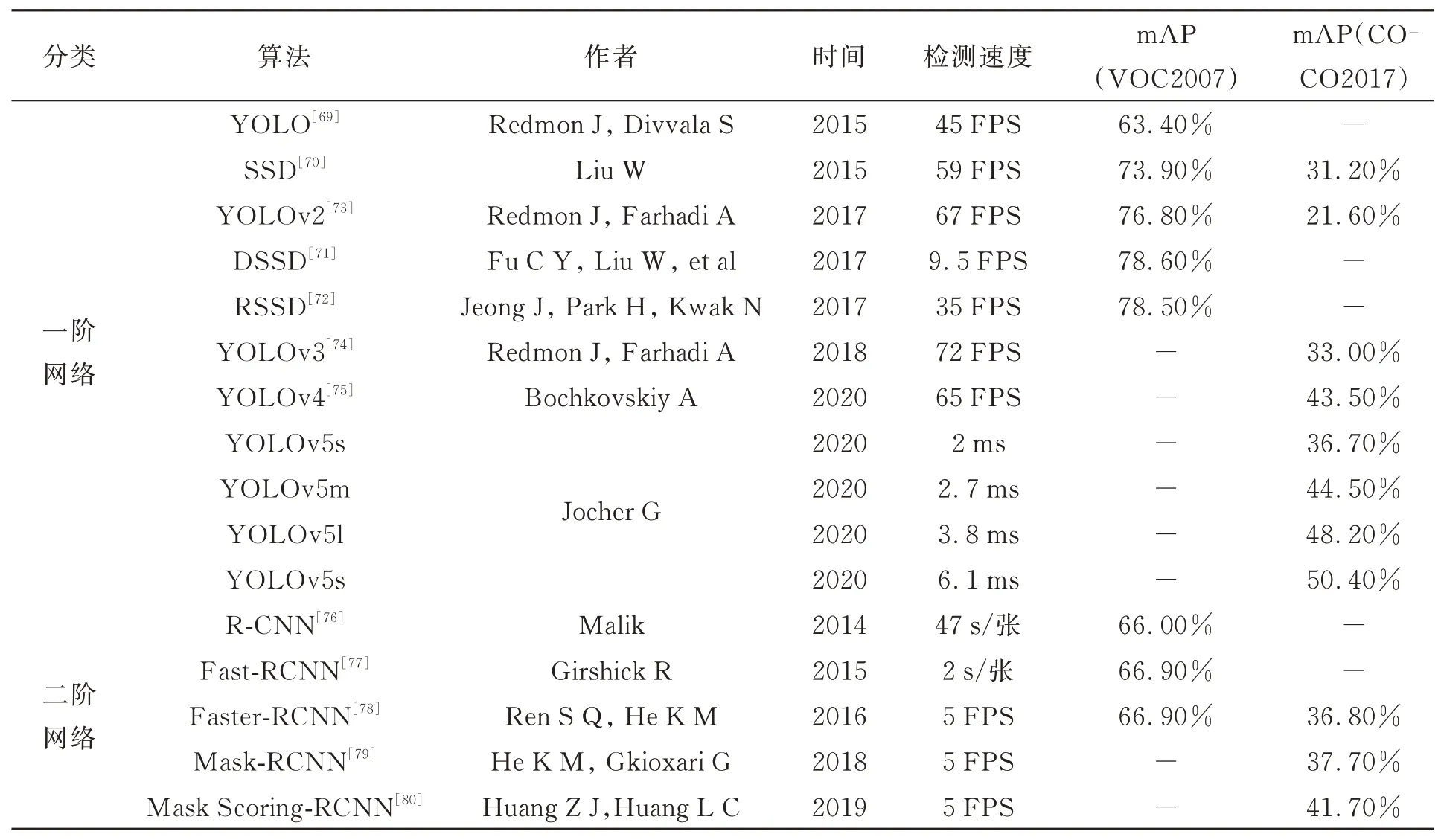
表2 目标识别网络对比Tab.2 Comparison of target recognition networks
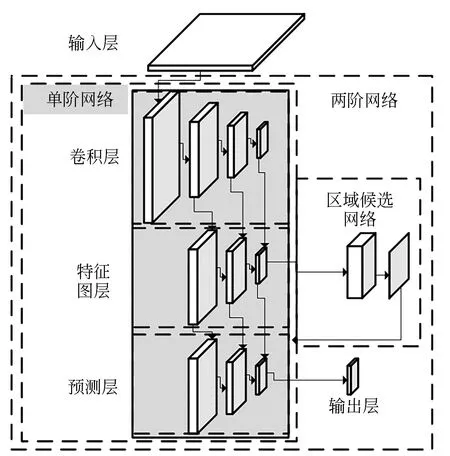
图5 目标识别网络结构对比图Fig.5 Comparison of target recognition network structure
3.2.1.1 回归网络
基于回归的单阶目标识别网络代表有YOLO(You Only Look Once)[69]和SSD(Single Shot Multi-box Detector)[70]等。
YOLO网络是2015年Redmond首次提出的基于GoogleNet的分类回归网络,计算速度快,能够应用在实时任务中。SSD网络同年被提出,其检测精度和计算速度均优于YOLO。SSD的相关 改 进 算 法 有DSSD[71]和RSSD[72]等。而 后,YOLOv2[73]、YOLOv3[74]、YOLOv4[75]相 继 问 世,检测精度和计算速度逐步提升。YOLOv3,YOLOv4因计算量小、计算速度快,被应用在多种领域。2020年6月,Glenn J开源YOLOv5算法,其准确度与YOLOv4相当,但更加轻量级、速度更快。
3.2.1.2区域候选网络
基于区域候选的两阶目标识别网络代表有R-CNN[76]、Fast R-CNN[77]、Faster R-CNN[78]、Mask R-CNN[79]、Mask Scoring R-CNN[80]等。
2014年提出的R-CNN是区域候选网络的开山之作,Fast R-CNN在其基础上将整张图像送入卷积网络计算,大大提高计算效率。Faster RCNN提出目标有效定位方法,按区域在特征图上进行索引,降低卷积计算消耗的时间。相较于Faster R-CNN,Mask R-CNN在速度上没有提升,但通过改进区域池化部分,目标检测精度得到提升。Mask Scoring R-CNN于2019年被提出,在Mask R-CNN的基础上增加了掩码区域打分机制,精度进一步提升。
3.2.2 位姿估计网络
位姿估计网络直接通过输入图像进行位姿估计,可分为整体回归和分类投票网络,详见表3。
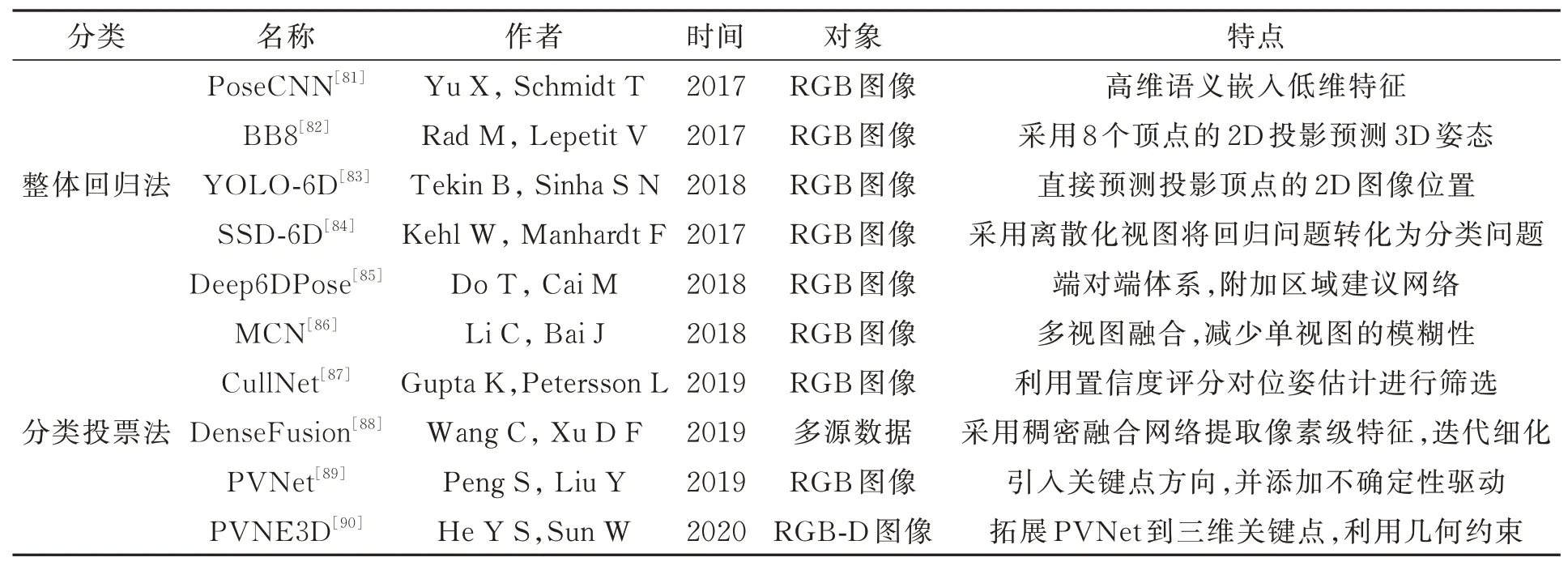
表3 位姿估计网络对比Tab.3 Comparison of pose estimation networks
3.2.2.1 整体回归网络
整体回归网络通常采用端对端网络,以图像作为输入,直接输出目标位姿结果。典型的整体回归法网络结构有PoseCNN[81]、BB8[82]、YOLO-6D[83]、SSD-6D[84]、Deep6DPose[85]等。
PoseCNN采用卷积网络实现平移和旋转解耦估计。该网络通过图像定位物体中心并预测其与摄像机的距离来估计物体的三维平移向量,再采用回归方式估计物体的三维旋转向量。该网络包含13个卷积层和4个池化层,同时提取不同分辨率特征图,并输出高维特征图,利用高维特征输出语义标签,并将高维语义标签嵌入低维特征,与中心点建立联系,输出位姿估计结果。
BB8直接检测目标对象,再通过对象边界框角点2D投影来预测3D姿态。BB8以单帧RGB图像为输入,采用卷积网络完成图像定位、分割、分类以及优化估计,利用3D边界盒8个顶点的2D投影结合N点透视法PnP算法来预测目标3D姿态,并通过限制训练图像的旋转范围解决各类旋转对称的姿态估计不确定问题。该网络可同时针对多个目标对象训练。
YOLO-6D采用YOLOv2网络结构,通过9个控制点参数化目标的3D模型,相比BB8网络增加了形心点,在投影预测2D坐标点过程中优先考虑形心点,再改进8个角点位置,加快运算速度,而后采用PnP方法估计六自由度位姿结果。YOLO-6D运行时间与目标数量关联不大,较为稳定且不考虑微调环节,速度加快。
SSD-6D将SSD网络用于位姿估计任务,采用离散化视图而非直接回归预测姿态,将姿态估计问题转化为分类问题,加快了估计速度。SSD-6D基础网络采用InceptionV4,经过不同尺寸模块产生6个特征图;将特征图分别与预测卷积核卷积,得到不同尺寸和形状的预测边界框;最后给出离散视图上的得分并进行分类,得到位姿结果。
Deep6DPose是一种端对端的多任务网络,能够进行目标检测、实例分割、以及位姿估计。在输入RGB图像后,首先采用深层卷积网络进行图像特征提取;再利用附加区域建议网络输出感兴趣区域;最后,针对感兴趣区域分别完成目标检测、实例分割和位姿估计任务。
3.2.2.2 分类投票法网络
分类投票法可分为两个阶段,先对输入图像进行区域预选,然后根据预选区域估计目标姿态。典型的分类投票法网络有MCN[86]、Cull-Net[87]、DenseFusion[88]、PVNet[89]、PVN3D[90]等。
MCN是基于投票方法的多视图融合网络,采用单个姿态预测分支,分支可由多类共享,同时进行多类训练。此外,该网络将类别图与卷积层拼接,嵌入对象类别标签,并利用物体掩膜进行进一步检测。MCN为大规模对象类和无约束的混乱背景提供可拓展的位姿估计学习网络,减少单视图的模糊性。
CullNet利用置信度评分对位姿估计结果进行筛选,剔除假阳性结果,选择最优位姿估计结果。该网络分两个阶段操作:(1)提取阶段:基于YOLOv3输出3个不同比例的关键点提取结果;(2)筛选阶段:将提取阶段得到k组2D关键点经E-PnP算法得到k个位姿估计结果同裁剪后紧密匹配的原始图像和姿态渲染模板作为输入,传递到CullNet网络中,输出位姿估计结果校准后的置信度,挑选置信度最好的位姿估计结果输出。
DenseFusion可以单独处理两个数据源,采用稠密融合网络来提取像素级的稠密特征,并据此进行位姿估计。此外,该网络集成了端到端迭代位姿细化步骤,进一步改善了位姿估计结果。该网络包含两个阶段。第一个阶段根据已知对象种类进行语义分割,针对每个对象分别提取深度信息和彩色信息。第二个阶段处理分割的结果并进行位姿估计。
PVNet通过学习对物体2D关键点的方向向量场,能够较好地处理遮挡效应,并使用不确定性驱动的PNP算法来估计位姿。该网络首先输出语义分割结果和关键点的方向向量场;然后根据一致性投票从方向向量场中计算出物体的关键点,同时生成关键点的概率分布;随后利用关键点的不确定性在PnP解算中进一步提高位姿估计的鲁棒性。
PVN3D将基于二维关键点的PVNet扩展到三维关键点,充分利用刚性物体的几何约束信息,显著提高六自由度估计的精度。该网络采用单一的RGB-D图像作为输入,首先,进行特征提取,分别输入到三个模块中预测关键点、语义标签和中心偏移;接着,应用聚类算法来区分具有相同语义标签的不同实例;然后,利用深度霍夫投票网络来检测物体的三维关键点;最后,使用最小二乘法拟合位姿参数。
综上所述,应用在位姿估计任务上的深度学习网络,有以下特点:
(1)引入关键点不确定性或者置信度机制对位姿估计结果进行筛选,例如CullNet与PVNet;
(2)划分多个子网络,将高维特征语义标签与低维特征中心点建立联系,例如PoseCNN与PVN3D;
(3)采用不同类型的卷积网络分别进行特征提取,使用融合网络融合不同类型特征结果,例如Deep6DPose和DenseFusion。
4 深度学习在空间任务中的应用
随着片上系统的发展,诸如视觉、雷达的自主测量手段具有一定的应用。同时,深度学习在不同领域,特别是计算机视觉领域,都取得了巨大的成功,吸引了很多空间研究者的注意。然而,空间应用不同于地面任务,可靠性需求高且缺少真实数据集[91]。
4.1 空间视觉测量任务的特殊性
相比地面视觉应用,空间视觉测量任务具有以下几点特殊性:
(1)空间视觉的任务场景范围更大,大多视觉任务包含远距离接近、近距离环绕和抵近距离交会对接等,测量距离变化较大,需要适应低纹理、低分辨率的目标识别需求;
(2)空间环境存在较多恒星、人造天体等的杂散光背景、测量目标表面包覆层反射及视线角变化带来的光照变化剧烈问题,使得目标在图像中呈亮点状且光照复杂多变,对目标检测带来巨大挑战。
4.2 典型网络
4.2.1 SPN网络
Sharma等 人[92]提 出 了Spacecraft Pose Network(SPN)网络,该网络是第一个基于单目视觉的已知非合作航天器位姿估计方法,采用海马8号气象卫星拍摄地球实际图像和OpenGL生成SPEED数据集。该网络使用五层CNN基本网络,并连接到三个不同的分支:(1)使用R-CNN结构进行2D边界框提取;(2)使用全连接网络进行相对姿态分类;(3)通过分支2得到N个候选项,使用另一交叉熵损失最小化,获得每个候选项的相对权重,采用四元数平均计算得到最终精细姿态。SPN网络利用Gauss-Newton方法解决了估计相对位姿的最小化问题,相对位置误差为厘米级、姿态误差为度级。
4.2.2 基于ResNET方法
Proenca等 人[93]在Unreal Engine 4虚幻引 擎上构建了面向已知非合作航天器的URSO数据集,提出基于ResNet网络的位姿估计深度学习框架,直接回归输出位置,以最小化相对误差为损失函数。此外,该框架赢得了欧洲航天局位姿估算挑战赛第二名,并给出在太空真实图像上的执行方法。
4.2.3 基于LSTM方法
Kechagias等人[94]提出深度循环卷积神经网络,输入多投影点云图像,利用CNN架构提取底层特征,采用LSTM进行建模,得到位姿估计结果。试验中采用斯阿莱尼亚航天公司开发的卫星模型用于非合作相对机器人空间应用导航任务,仅针对模拟数据进行训练,多种情景下的评估结果表明网络结构有很强的适应性,能够在较低的运算需求下提供较优的里程精度。
4.2.4 二阶网络方法
为了实现快速准确的位姿估计,Huo等人[95]提出了基于深度神经网络方法并结合PnP算法和几何优化方法的网络。该网络在SPEED数据集实现,首先设计了轻量级的YOLOv3网络用于预测关键点位置,接着回归生成热图,最后利用PnP和EKF方法得到位姿结果并优化,该方法实现了较低的计算消耗。
综上所述,深度学习在空间位姿估计领域已有部分成果,理论研究表明位姿估计结果可在厘米级和度级,能够满足空间应用的需求。但由于缺乏真实数据集,能否满足空间任务对鲁棒性的高要求,尚未在实际空间任务中验证。
5 结论
本文对视觉位姿估计技术的发展及其在空间任务中的应用展开综述,得到了如下几点结论:
(1)传统视觉位姿估计技术较为成熟,有大量工程应用,但受环境因素影响较大,需要针对任务设计特征,通用性和适应性较差。
(2)利用深度学习方法进行视觉位姿估计的理论研究发展迅猛,但现仍存在训练需求数据集庞大,且运算量大等问题,尚未广泛应用。
(3)各国广泛开展视觉位姿估计技术在空间任务中的应用,其中,对于合作目标的位姿估计较为成熟,非合作目标位姿估计仍处于探索阶段。
针对空间任务,相对位姿估计技术尚存在较大不足,需要针对以下特定问题展开研究:
(1)低纹理、低分辨率目标识别。相比传统任务,空间任务视场范围大,目标距离远,运动速度较快,目标纹理和分辨率较低,需要对目标快速定位跟踪。
(2)退化视觉环境成像。太空是典型的退化视觉环境,存在空间杂散光背景、目标包覆层反射、光照变化剧烈等问题。要完成空间目标的位姿估计任务,视觉位姿估计算法需要对环境有较好的适应性。