基于注意力机制BiLSTM-CharCNN的药物不良反应监测方法
2022-10-24葸娟霞叶思维
葸娟霞,徐 鹏,叶思维
(广东东软学院信息管理与工程学院,佛山 528225)
0 引言
药物不良反应(adverse drug reactions,简称ADR)是指患者在使用某种药物治疗疾病时所引发的有害反应。及时地知道药物不良反应对医药公司和监管机构非常重要。获得药物不良反应的传统方式具有时效低、更新慢的特点,因此需要找到一个具有时效性高,更新快的方法。人们在社交媒体上发表健康情况的推文满足以上两个特点,因此社交媒体也就成为药物不良反应的研究数据来源。社交媒体的数据是用户用药的第一手资料,时效性高,覆盖率广,但如何在海量的数据里找到与ADR相关的推文,这对ADR研究是一项巨大的挑战。
Sarker等对多种社交媒体资源进行全面挖掘,实现了多种特征的结合分析,这些特征包括n-gram特征、词典特征、极性特征、情感分数特征和主题模型特征,通过实验发现SVM算法的性能最好。Korkonteelos等关注到了情绪分析在药物不良反应识别任务中的作用,他们利用一个新颖的情感分析算法并结合支持向量机(SVM)分类器,来实现对推特数据集上的药物不良反应任务的识别及提取,其在推特数据上的1值达到了69.16%。Cocos等利用双向长短时记忆网络(BiLSTM)训练推特数据集,其推文数量为844,最后的1值为0.755。Xia等利用迁移学习结合LSTM模型,在迁移学习的实例、特征表示、参数、关系知识4个方面进行了实验,取得了良好的效果,使用迁移学习解决了数据稀缺的重要难题。Rezaei等使用推特的数据集,通过CNN、HNN和FastText三类深度学习网络对其进行分类,这三种模型的输入都采用word2Vec向量,最后证明了其方法的有效性。
本文提出基于注意力机制的BiLSTMCharCNN药物不良反应推文识别方法。通过将字符级向量与词向量相结合的方法来对推文进行识别。以社交媒体上人们讨论健康情况的推文为实验数据,并将实验结果与BiLSTM,CharCNN,BiLSTM+Attention,BiLSTM+CharCNN的结果进行对比,以召回率()、精确率()、1值为评价指标,验证了本文所提出的基于注意力机制的BiLSTM-CharCNN药物不良反应识别的有效性。
1 模型方法
1.1 词向量表示
词向量指的是将高维度离散的文本数据转化为低维度密集向量,本文方法中的词嵌入部分能够准确地抓取词语的语义。接着应用词嵌入模型Word2vec,它可以通过机器学习模型将原来不同的词转化为不同的实数向量。Word2vec可以在大量文本数据集中进行局部训练,训练得到的结果—词向量,可以很好地拟出度量词与词之间的相关性。
1.2 长短时记忆网络LSTM
长短时记忆网络(LSTM)是一种特殊的RNNs,能有效地解决传统RNN在处理时间序列长期依赖中的梯度消失和梯度爆炸的问题。LSTM通过在RNN传输状态后加入细胞状态(C)来控制传输状态,由于在传输过程中细胞状态变化较慢,误差相对稳定,可以在多个时间步上持续学习且在一定程度上加强LSTM的记忆能力。
LSTM的细胞结构如图1所示。

图1 LSTM单元结构
LSTM结构中的核心部分是图1中最上边的线-C,叫做细胞状态(cell state),它一直存在于LSTM的整个系统之中,其中:

式(1)中f叫做遗忘门,表示C的需要用作计算C的特征。f是一个向量,向量中的每个元素的范围均介于[0,1]之间。通常使用sigmoid函数作为激活函数。上图中的⊗代表LSTM中最重要的门机制,遗忘门表示的是h和x之间的单位乘关系,可由公式(2)表示:
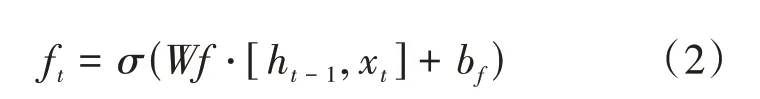
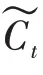

i叫做输入门,由x和h经由sigmoid激活函数计算而来,如下所示:


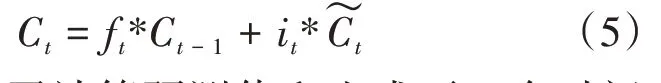
最后,为了计算预测值和生成下一个时间片完整的输入,需要计算隐节点输出,如下式所示:

由式(6)和式(7)可知,隐节点输出h取决于输出门O和细胞状态C,且O的计算方式与f及i类似。
LSTM是一个信息单向传播的模型,无法编码从后到前的信息。但是对于一些文本分类任务来说,后边的信息依然可以影响前边的词句。为了解决这个问题,提出了BiLSTM模型,其主要思路是将后向关系和前向关系链接到同一个输出层,且在其中共享权值。其网络结构如图2所示。

图2 BiLSTM结构图
在前向层从1时刻到时刻正向计算一遍,然后将结果保存;同时,从时刻到1时刻,逆向计算一遍,同样将计算结果保存;最后将正向计算和逆向计算的结果相加,得到整个BiLSTM的计算结果,其具体计算过程见下式:

1.3 注意力机制
注意力机制(attention mechanism)是一种模仿人类注意力的网络构架。在注意力资源有限的情况下,能够有效筛选和提炼大量复杂冗余信息中的高质量内容,可以同时聚焦多个细节部分。注意力机制可以弥补信息的长距依赖性这一缺陷。
1.4 注意力机制的BiLSTM-CharCNN模型
本文的模型结构如图3所示:主要包括输入层、特征提取层和输出层。

图3 模型框架图
输入层主要对原始的数据进行清洗、分词等操作,转化为较规范的文本形式;接下来,在特征提取阶段,使用了两种特征提取方法。
(1)字符级特征提取:使用CharCNN模型提取字符级特征。首先对文本进行字符数字化,然后对其做卷积操作,对卷积的结果做Max-pooling池化操作,这样的卷积池化操作共执行3次。最后将其输入全连接层,得到字符级特征向量。
(2)使用BiLSTM-Attention模型提取特征向量。首先,使用word2vec算法得到文本的词向量,接下来将词向量输入到BiLSTM模型中,最后将得到的特征向量做Attention操作,这样就能通过调整权重参数去除冗余信息,提取关键部分的信息,对文本进行优化。再使用两种不同的方法进行特征提取,并将提取到的特征信息进行连接,然后输入到输出层。输出层包含一个全连接层和一个softmax层,使用全连接层调整特征向量的维数,然后使用softmax分类器对文本进行分类操作。
1.5 算法描述
输入:原始数据集;类别标记;
输出:分类模型;模型的评价指标;
(1)数据预处理:p=(),函数主要包含数据清洗和分词;
(2)特征提取:
①BiLSTM+Attention:=(p)函数包含多个步骤,具体如下:

②CharCNN:函数包含多个步骤,具体如下:

③=⊕F
(3)输出层:softmax:=(),最后得到分类结果。
2 实验与结果分析
2.1 实验数据
本文所采用的数据集是SMM4H共享任务评测的数据集。该数据集主要提供了推特用户发表推文的ID号和用户的ID号。由于存在用户删帖等因素的存在,最后一共收集到7168条推文。在实验之前,首先统计本研究的数据集,结果见表1。

表1 数据集统计
由于本研究数据集的样本数较小,为了充分训练,本文采用8∶2的数据集划分方式,最后测试集的数据集是在训练结束后在整个数据集上随机采样得到的。
表2给出了推文的示例。由表2可以看到,社交媒体的文本是不规范的,充斥着各种符号和URL等信息,所以需在实验前对数据进行文本预处理。

表2 推文示意表
2.2 数据处理
因为推文数据都是不规则的、较口语化的文本内容,所以首先需对推文数据进行文本预处理。表3显示了文本预处理的实例。

表3 推文预处理示意表
文本具体的处理方法为:统一单词的大小写,将所有单词转化为小写;将所有出现的URL、电子邮件地址以及提及的其他用户名分别替换为“url”“email”“atSign”;推文中有一类标签文本,表示推文的类型,在本文的研究模型中未使用到,所以将标签类型删掉;将推文中的数字部分修改为一个代表性的数字。
2.3 超参数选择
本实验采用正则化和Dropout的方法来降低模型的复杂度,避免过拟合。在CharCNN阶段和BiLSTM阶段均使用Dropout的方法来避免过拟合,在损失函数中引入了L2正则化,既能提升准确度,又能增加模型的鲁棒性。本文使用Adam梯度下降法来加速模型的收敛速度。
在神经网络中隐藏层数、单元个数、批量大小或迭代次数等参数也被称为超参数,它们决定了特定神经网络结构的总体设置。本实验使用网格搜索的方法进行超参数选择,即用预定义的超参数搜索空间的不同超参数组合来训练神经网络结构的多个不同版本,并评估这些参数组合,选择在验证集上评估性能最佳的配置作为最终的参数组合。
相关超参数设置:词向量的维度设置为200维;CharCNN阶段字符序列长度为1014;CharCNN卷积层层数设置为3;LSTM的时间步设置为128,LSTM输出神经元个数设置为12;训练batch大小设置为64;迭代epoch设置为5;学习率设置为0.001;dropout值设置为0.9(这是dropKeepProb的值)。
2.4 评价指标
本文研究内容是社交媒体上药物不良反应检测任务,是自然语言处理中常见的分类任务。与药物不良反应有关,标记为1;否则标记为0。预测结果的混淆矩阵如表4所示。其中,表示预测为与药物不良反应有关,实际也与药物不良反应有关;表示预测与药物不良反应有关,而实际无关;表示预测与药物反应无关,而实际有关;表示预测与药物不良反应无关,实际也无关。
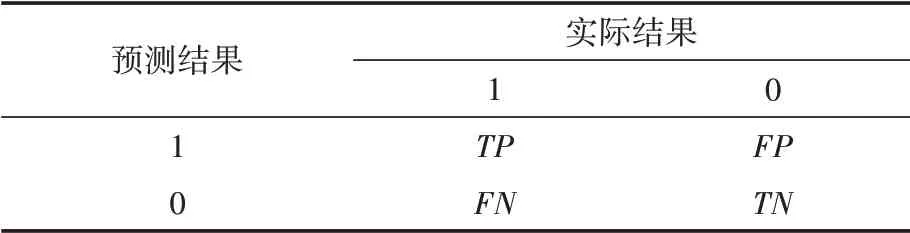
表4 混淆矩阵
召回率表示模型实际为1的样本,预测仍为1的样本概率,其计算公式为:

精准率是指在所有预测为1的样本中,实际为1的样本比例,其计算公式为:

值是对召回率和精准率的综合评价指标,是对其进行加权平均的结果,其计算公式为:

2.5 实验结果及分析
为了验证本研究提出模型的有效性,本文选取BiLSTM、CharCNN、BiLSTM+Attention算法做对比实验,通过与经典模型的对比分析,能够准确地反映本模型的优越性,其实验结果如表5所示。

表5 药物不良反应的二分类结果
表5中所有的数据都是在相同的实验参数和相同数据集中训练得到的结果,其中单独的BiLSTM模型或者CharCNN模型在这个任务上的效果都欠佳,可以看到召回率都在0.5以下。其精准率很高,而召回率很低,这是因为精准率和召回率是两个相互矛盾的指标。由公式(11)和(12)可得,精准率的大小与假正例成反比,召回率的大小与真正例成反比。这样就导致精准率和召回率相互矛盾,类似于处于拔河比赛的两端。而值能够平衡这两个指标,衡量模型性能的指标,但是这两个模型的值也都处于一个较低的水准。
比较BiLSTM+Attention模型和单纯使用BiLSTM模型的值和精准率,会发现值提高了约16%,召回率提高了约29%。同样比较BiLSTM和BiLSTM+CharCNN,发现后者的值提高了约19%,召回率提高了约33%。比较BiLSTM+Attention和BiLSTM+CharCNN模型,发现相对于前者,后者召回率提高了4%,值提高了约3%,精准率提高了约2%。最后,本文用到的模型与前几个模型相比,在精准率几乎不变的情况下,召回率提高了约3%,值也提高了约1%。对于药物不良反应的监测问题,该模型在一定程度上提高有不良反应用户被检测出的概率。
3 结语
本文模型主要是对社交媒体上的药物不良反应进行分类。使用了双向长短时记忆网络LSTM和CharCNN模型进行特征提取,同时结合注意力机制对特征向量进行优化。使用双向长短时记忆网络,能够完美保留LSTM处理文本的优势,处理长距离的依赖特征,并能保证更全面地考虑上下文信息。注意力机制能够通过调整双向长短时记忆网络中各节点的权重,使得模型能够识别文本中更加关键的部分,这样能最大程度地削弱冗余部分对文本的影响,进而优化特征向量。CharCNN从字符信息出发,提取文本在字符粒度上的特征向量。与传统的人为设计的文本特征和基于单一的神经网络提取的特征向量相比,能够从不同层次更全面地描述推文中的文本特征,且能识别文本中的关键信息,进而在药物不良反应的分类任务中取得更好的效果。下一步的研究重点就是如何确定推文中的不良反应所对应的相关药物。
