云端马拉松图像的号牌识别研究
2022-10-24黎蕴玉丁小波蔡茂贞钟地秀
黎蕴玉,丁小波,蔡茂贞,钟地秀,彭 琨
(中移互联网有限公司云产品事业部,广州 510000)
0 引言
由于低门槛和轻装备的特点,马拉松已成为各城市和企业乐于举办的运动赛事。全球的马拉松赛事数量持续增长,统计显示2019年全国共举办1828场次规模赛事,覆盖了全国31个省区市,参加人次达712万。对于马拉松赛事举办方而言,将赛事期间为运动员拍摄的海量照片进行云端的精准分类、推送和管理是一项具有挑战性的赛事服务工作。相比于效率低、耗时长和成本高的传统人工分类方式,基于运动员号牌智能识别成了实现云端海量马拉松赛事图片精确分类的重要方法。马拉松运动员号牌字符主要由若干位大小写字母和数字任意组合而成,通过贴在运动员衣服上进行区分,不同场次的号牌字符字体、颜色和背景各不相同。由于马拉松号牌图片具有格式多样、光照多变和扭曲变形等特点,设计一种鲁棒性强、高效的基于号牌识别的云端图片分类方案具有一定的难度。
近年来,研究者进行了大量运动员号牌识别的工作,并广泛应用在运动员图片分类的任务上。文献[2]利用人脸检测预估号牌位置,再使用SWT精细定位分割号码,最后进行TesseractOCR文字识别。文献[3]则采用SVM人体检测模型、HOG文字检测和TesseractOCR识别模型的多模型融合方法。文献[4]首先利用可变形部件模型进行人体检测,再使用图像处理技术进行号牌检测和分割,最后输入三层BP神经网络得到单字符的识别结果。文献[5]利用迁移学习策略实现较高精度的号牌识别。文献[6]将YOLOv3人体检测模型、CTPN文字检测模型和CRNN文字识别模型进行串联,经树过滤后实现号码牌识别。文献[7]则基于YOLOv4人体检测结果进行字符级CRAFT文字检测和基于注意力机制的号码识别。
基于马拉松号牌的特殊性,现有号牌识别方法大体采用图1所示的算法流程。通用的CTPN、EAST等文字检测技术主要针对自然场景设计,会识别图片中的所有文字内容,因此通过人体/人脸检测和文字检测相结合的方法先检测出人体,过滤冗余信息,再基于人体检测结果进行号牌检测,该流程虽能有效识别出号牌,但也造成模型数量多、处理复杂度高和运行时间长的问题。

图1 常见的号牌识别流程
综上所述,本文主要提出一种基于目标检测的两阶段号牌识别云端图片分类系统,去除图1中的人体/人脸检测和文字分割两个模块,将号牌直接当成目标进行检测,有效减少冗余信息,两阶段的号牌检测识别模型在保证识别精度的情况下有效提升推理速度,实现马拉松图像的精准分类和管理。
1 提出方案
本文提出了一种基于两阶段号牌识别马拉松图片分类方法,首先将经过预处理的图片通过RetinaNet模型进行号牌检测,将裁剪的号牌检测区域输入号牌识别模型进行文字识别。本方法的具体流程如图2所示,包含举办方终端和云端服务器两部分,具体步骤为:①举办方终端批量上传马拉松赛事图片和赛事的所有号牌值至云端服务器;②在云端服务器对图片进行去重、过滤模糊无效图、获取图片的属性信息和角度矫正等预处理操作;③将预处理的图片输入基于RetinaNet的号牌检测模型定位号牌区域,裁剪出号牌区域作为号牌识别模型的输入,获得识别的号牌值;④将识别的号牌结果进行BK树过滤、号牌聚类等后处理,实现马拉松图片智能分类。

图2 基于号牌识别的马拉松云端图像分类图
1.1 RetinaNet号牌检测模型
现有的号牌检测模型主要使用人体检测和文字检测的多模型融合或直接使用文字检测模型,前者虽然能提升号牌检测准确率,但处理速度慢、计算复杂度高;而后者则会形成大量冗余文字信息,影响检测精度。基于以上分析,本文提出一种基于RetinaNet的号牌检测网络(如图3所示),主干网络为ResNet50,利用特征金字塔进行多尺度特征提取,每个特征层对接2个分支:框分支和类别分支,分别预测号牌框4点矩形坐标、是否为号牌;每个特征层对应3个锚点以提取不同尺度目标,类别分支和方向分支均使用Focal损失函数缓解类别不均衡问题。该模型仅针对号牌标注数据进行训练,能有效检测出号牌区域,避免冗余文字信息的产生。
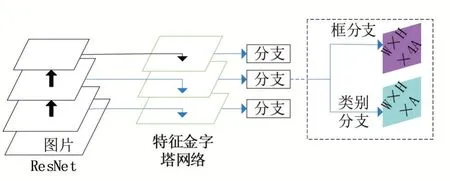
图3 RetinaNet号牌检测网络
1.2 DenceNet-CTC号牌识别模型
马拉松的号牌文字序列主要由随机的字母和数字组成,并无明显的上下文结构信息,而常用的循环神经网络和注意力机制的文字识别网络主要针对上下文序列信息进行识别。此外,卷积神经网络结构每一步计算都依赖于前一步的计算和输出结果,存在模型参数多和推理耗时的问题。
为加快推理速度和提高号牌识别准确率,本文的号牌识别模型采用DenceNe(tdense convolutional network)作为主干网络,CTC(connectionist temporal classification)作为损失函数实现非定长序列的端到端号牌识别,具体如图4所示。DenceNet网络主要由卷积神经网络、Dense模块和Transition层组成,通过相互连接所有层的密集机制减轻梯度消失和加强特征传递及重用,其中Dense模块是指第层连接前面所有层的特征作为输入,获得特征x=([,,…,x]);Transition层则是批标准化、卷积和池化层的集合。最后通过CTC损失函数,利用前向概率求解,直接预测出号牌序列值。

图4 DenceNet-CTC号牌识别模型
2 实验
2.1 数据集
(1)Racing Bib Number Recognition(RBNR)。该数据集采集了自然场景下三个不同场次的含马拉松号牌的图片,217张图片中含290个号牌,号牌均由3~6位纯数字构成。
(2)趣味运动会数据集(FUNNR)。该部分为自行采集的多个场次趣味马拉松运动会的号牌图片集,号牌由大写字母、部分特殊字符和数字组成,共有4653张图片和9118个号牌,部分为遮挡号牌。
(3)测试集(TEST)。该测试集为随机采集的马拉松号牌图片126张,共有140个号牌,用于整体识别性能测试,其中清晰号牌图片含106张,有遮挡的图片20张。
2.2 消融实验
实验基于Keras实现并使用英伟达GTX 1080TI显卡进行训练,对RBNR和FUNNR两个数据集按9∶1划分训练集和测试集,用于模型的训练和测试,并采用平移、随机裁剪、加噪声和生成样本等多种数据增强方式提升样本的丰富性。
该部分进行了号牌检测的RetinaNet和EAST两个算法对比实验,如表1所示,在RBNR和FUNNR两个测试集上,RetinaNet的检测准确率均表现良好,表明对比EAST算法,本方法能有效减少误检测情况。

表1 号牌检测算法对比
为了证明本文提出的号牌识别算法的有效性,我们将DenseNet-CTC和TesseractOCR进行实验对比。如表2所示,本文提出的号牌识别算法在两个数据集上的编辑距离和准确率指标均高于TesseractOCR。其中准确率是指字符均正确识别的号牌数占总号牌数的比例。

表2 号牌识别算法对比
针对FUNNR数据集训练的模型进行测试集(TEST)的整体识别性能测试,具体的识别结果如图5所示,对于单号牌图片图5(a),本方法能正确检测和识别出号牌内容,而对于有遮挡的多号牌图片图5(b),本文方法也表现出良好的识别效果,证明本方法的有效性和良好的泛化性。

图5 识别结果图
在本次的测试中共检测出号牌122个,其中正确识别120个,错误识别2个,漏识别20个,准确率为98.26%,召回率为85.71%。其中CPU上平均单张图片的处理时间为0.748秒,对比文献[3]中2.19秒的单幅图片处理时间,本方法的处理速度提升了3倍。
3 结语
针对日益增长的云端马拉松图片,本文设计了一种基于目标检测的两阶段号牌识别策略进行马拉松图片分类,本方法分别利用RetinaNet和DenseNet-CTC进行号牌检测和识别,在保证识别准确率的同时有效提升运行速度,对局部有遮挡的多号牌图片仍能有效识别。
