基于集成学习的有害垃圾自动识别方法研究
2022-10-24孟德尧吴荣海杨邓奇
孟德尧,吴荣海,杨邓奇
(1.大理大学数学与计算机学院,大理 671003;2.大理大学工程实训中心,大理 671003)
0 引言
随着全球经济的不断发展,居民的生活水平不断提高,生活垃圾的生产量也在逐年增加。由于城市人口多,环境容量有限,城市地区的生活垃圾污染问题变得更加严重。垃圾回收任务是缓解环境和改善整个国家经济的有效途径。垃圾回收工作的效率和质量在很大程度上取决于垃圾分拣的有效性。针对人工分拣垃圾存在的工作量大、易出错、分拣效率低等问题,一些学者提出了智能垃圾识别与分类方法,通过机器识别垃圾图像实现自动分类,降低人工成本,进一步提高资源的再利用率。
近年来,深度学习在图像识别领域取得了突出的成绩,被广泛应用于垃圾分类。例如,文献[8]用DenseNet169模型在自制的垃圾数据集NWNU-TRASH(废玻璃、废织物、废纸、废塑料和废金属,共18911张)上实现垃圾分类,取得了82%的准确率。文献[9]使用支持向量机(SVM)和ResNet50(SVM)模型在TrashNet标杆数据集(包括玻璃、纸张、纸板、塑料、金属和普通垃圾六个类别)上进行垃圾分类,准确率分别为63%和87%。文献[10]通过数据增强的方法,将TrashNet上的图像分别做了水平翻转、垂直翻转和随机25 °旋转,将数据集扩充了四倍,其中90%作为训练集,10%作为测试集,利用遗传算法优化DenseNet121的全连接层,取得了99.6%的准确率。现有基于深度学习的垃圾分类主要基于TrashNet数据集来实现,取得了很高的准确率。
然而,受限于垃圾图像数据集,现有垃圾分类的研究没有考虑生活垃圾的组成成分问题。生活垃圾往往包括废旧电池、过期药品等有害垃圾。有害垃圾和无害垃圾的处理方式不同,将有害垃圾误当作无害垃圾处理,对环境和生命造成严重的威胁。在实现垃圾自动识别和分拣时,如何尽可能降低有害垃圾的漏判误差(将有害垃圾误识别为无害垃圾的误差)是个亟待解决的问题。
本文采用网络爬虫和手动拍照的方式建了一个包含废旧电池、过期药品等有害垃圾的数据集,并提出了基于保守集成策略的垃圾自动识别方法,实现有害垃圾的低漏判自动分拣。本文的主要贡献:
(1)构建了一个包含有害垃圾和无害垃圾的垃圾图像数据集,包括3281张垃圾图像,分为七类:废旧电池、过期软膏、过期药物、废玻璃、废纸、废塑料和废金属。
(2)提出了基于保守集成策略的垃圾自动识别方法,降低了有害垃圾的漏判误差。
1 方法和数据集
1.1 数据集
本文通过网络爬虫和手动拍照构建了生活垃圾(Domestic Trash,DTrash)数据集,包括废旧电池(321张)、过期药物(448张)、过期软膏(387张)、废玻璃(501张)、废纸(522张)、废金属(551张)、废塑料(551张)七个类别,其中废旧电池、过期药物、过期软膏是有害垃圾,有害垃圾图像的比例为35.23%。DTrash数据集中所有图像均为RGB格式,大小不一。我们使用Python3.5.3平台的Python Imaging Library中的resize()方法调整了所有图像的大小,以满足DNN模型对输入图像大小的要求。DTrash数据集的图像示例如图1所示。

图1 DTrash数据集的图像示例
实际生活中无害垃圾往往比有害垃圾多,因此,本文对数据集的各个类别不做平衡处理。随机地将DTrash数据集按8∶1∶1的比例划分为训练集、验证集和测试集,见表1。

表1 训练集、验证集和测试集详细信息
1.2 集成学习方法
为了提高模型的性能,本文先对VGG-16、ResNet-50、ResNext-50、Vision Transformer(ViT)和Vision Transformer Hybrid(ViTHybrid)在DTrash数据集上进行了测试,结果表明,ViT模型、ViT-Hybrid模型具有更好的性能。因此,本文的集成学习方法采用了这两个模型。ViT和ViT-Hybrid模型的描述见表2。

表2 ViT和ViT-Hybrid模型的信息
本文设计了基于保守策略的垃圾图像自动识别集成学习方法,如图2所示。该方法的目的是在实现垃圾分类时,尽可能减小将有害垃圾预测为无害垃圾的概率。
图2(a)部分是将ViT、ViT-Hybrid在ImageNet上预训练的权重迁移到训练DTrash的模型上。ViT、ViT-Hybrid模型在DTrash训练集上训练后得到集成模型。将测试集输入集成模型得到预测结果。
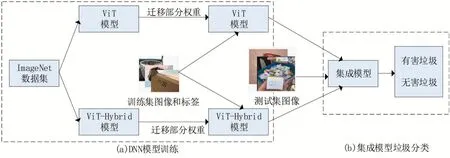
图2 集成学习方法用于自动识别垃圾图像
基于保守策略的集成学习方法使用了迁移学习,将在ImageNet数据集上预训练的ViT和ViT-Hybrid模型的权重参数迁移到DTrash数据集,对全连接层和SoftMax进行微调,再采用保守策略将两个模型集成,得到集成模型。在本文的保守策略中,如果模型ViT和ViT-Hybrid对同一输入图像的预测结果至少有一个是有害垃圾时,集成模型会将该图像预测为有害垃圾(0)。如果模型ViT和ViT-Hybrid对同一输入图像都无法识别时,集成模型会将该图像预测为不确定图像()。否则,集成模型会将图像预测为无害垃圾(1)。保守集成策略定义见式(1)。

1.3 模型评价
现有的研究将所有垃圾类别平等对待,通常使用准确率来评价模型性能。本文旨在有效分离有害垃圾和无害垃圾,尽可能地减小有害垃圾被错误地识别为无害垃圾的概率。因此,本文使用三个评价指标:有害垃圾图像的漏判误差(E)、无害垃圾图像的误判误差(E),图像总体误差(E),分别定义为公式(2)、(3)和(4)。

其中表示实际是有害垃圾,模型也将其预测为有害垃圾的照片数量。表示实际是无害垃圾,模型也将其预测为无害垃圾的照片数量。表示实际是无害垃圾,模型将其预测为有害垃圾的照片数量。表示实际是有害垃圾,模型将其预测为无害垃圾的照片数量。记有害垃圾图像集合为,无害垃圾图像集合为。定义有害垃圾标签集合L={过期药品、废旧电池、过期药品};无害垃圾标签集合L={废玻璃、废纸、废金属、废塑料}。那么,,,和可分别定义为公式(5)、(6)、(7)和(8):“::=”表示“定义为”,“()”表示集成模型为图像“”分配的预测标签。对任意一张有害垃圾图像,模型只要将其预测为集合L中的任一标签都属于;对任意一张无害垃圾图像,模型只要将其预测为集合L中的任一标签都属于;对任意一张无害垃圾图像,模型只要将其预测为集合L中的任一标签都属于;对任意一张有害垃圾图像,模型只要将其预测为集合L中的任一标签都属于。
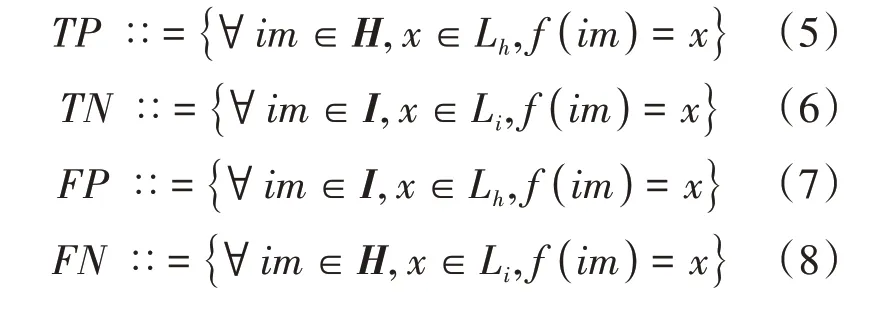
E直观地反映模型错误预测的有害垃圾图像占测试集有害垃圾图像总数的比例。E直观地反映模型自动预测为有害垃圾图像中无害垃圾图像的比例。
2 实验结果
有害垃圾图像和无害垃圾图像二分类的实验结果如表3所示,集成模型漏判误差(E)、误判误差(E)和总体误差(E)分别0%,11.63%和4.57%。实验结果表明,尽管集成模型的误判误差和总体误差都有所增加,但保守的集成策略有效地降低了有害垃圾的漏判误差,防止了将有害垃圾识别为无害垃圾。图3为集成模型和两个DNN模型对应的二分类混淆矩阵。

图3 集成模型(左)、ViT(中)、ViT-Hybrid(右)对有害垃圾、无害垃圾的预测结果
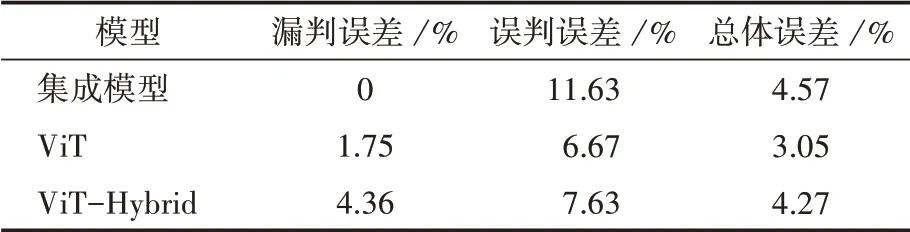
表3 单模型与集成模型各指标对比
3 讨论
基于保守策略的集成学习方法在识别垃圾时,保证了有害垃圾不会被识别为无害垃圾。但是垃圾分类的总体准确率也是值得关注的指标。图4给出了多分类实验结果的混淆矩阵。混淆矩阵左上方3×3的矩阵是有害垃圾内部的预测结果,右下方4×4的矩阵是无害垃圾内部的预测结果。

图4 多分类实验结果混淆矩阵
多分类的准确率()计算公式如(9)所示:
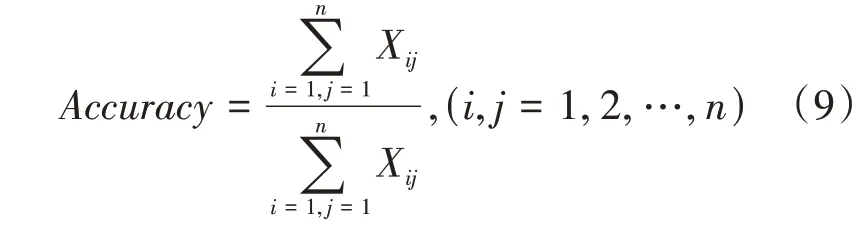
其中X表示实际为第类别,模型将其预测为第类别的标签的图像数,为类别数。
从图4可以发现,实际为有害垃圾,集成模型也将其预测为有害垃圾的图像(114张)中,其准确率为96.49%;实际为无害垃圾,模型也将其预测为无害垃圾的图像(198张)中,其准确率为91.92%。实验结果表明,集成模型在有效控制了有害垃圾漏判误差的同时,将有害和无害两类垃圾内部类别间的误识别误差控制在一个较低的水平。
4 结语
针对如何尽可能降低有害垃圾的漏判误差问题,本文设计了基于保守策略的垃圾图像自动识别集成学习方法,在自制DTrash数据集上训练集成模型,测试结果显示,集成模型获得了较低的漏判误差(0%),有效地防止了有害垃圾被误识别为无害垃圾,并将有害和无害两类垃圾内部类别间识别误差维持在一个较低的范围。
