优化预训练模型的小语料中文文本分类方法
2022-10-24陈蓝杨帆曾桢
陈蓝,杨帆,曾桢
(贵州财经大学信息学院,贵阳 550000)
0 引言
数字信息资源是指所有以数字形式将文字、数值等多种信息存储在计算机中,通过网络通信、计算机或终端再现出来的资源。近年来,数字信息资源的快速增长,为用户带来便利的同时也导致了“信息爆炸”。数字信息资源的重要组成部分之一就是文本,针对种类繁多的文本信息资源,运用现代化的管理手段和管理方法,将资源按照一定的方式组织和存储起来,能够使用户在查找海量信息时实现高效检索。
目前,将文本信息转换为计算机能够识别的数据是自然语言处理的一个重要问题。其中最普及的解决方法是将文本转换为向量的形式,将一句文本语言转化为一个向量矩阵,通过相似词具有相近的向量,对词义进行表示。目前,由于深度学习的发展及应用,学者们通过各种神经网络对生成的多个维度的词向量进行特征提取,降低损失函数值从而对词向量进行优化,增强向量对词义的表达能力。
在现实需求以及自然语言处理技术的基础上,本文提出了一种中文文本字向量的表示模型,使用GloVe模型和BERT模型生成的字向量进行融合后,通过文本特征提取得到对应的字粒度向量。
1 研究现状
在中文自然语言处理领域,计算机无法对非结构化的文本数据进行处理,因此在对中文文本信息进行处理时,需要经过分词以及向量化的过程,也就是将文本信息转化为计算机能够识别的数值数据。其中在文本向量化方面,最早的文本转换方式为one-hot(独热)编码形式,one-hot编码虽然解决了分类器处理离散数据困难的问题,但是没有考虑词与词之间的相互关系,并且由one-hot生成的特征矩阵较为稀疏,增加了机器运算的负担。在2014年前后,主要有两种文本向量化方法,一种是矩阵分类算法,另一种是基于浅窗口的方法。基于浅窗口方法的代表模型就是Word2Vec,为了获得更多的语义信息,Mikolov等提出了基于深度表示的模型—Word2Vec,该模型为输入文本搭建一个具备上下文信息的神经网络,从而计算得到含有上下文信息的词向量,该向量也在一定程度上反映了词与词之间的相关性。虽然Word2Vec可以利用上下文信息预测词向量使得生成的词向量包含了语义信息,但由于其构建过程是单向学习,没有充分利用所有语料。而基于矩阵分解算法通过文本共现矩阵表达文本词向量,通过奇异值分解(singular value decomposion,SVD)对共现矩阵进行降维,章秀华等提出一种奇异值分解域差异性度量的低景深图像目标提取方法,其能够完整提取目标,但SVD的计算代价过大,并且难以将新的词汇或者文本合并进去。2014年Stanford NLP Group结合Word2Vec以及SVD的优点提出了GloVe(global vectors for word representation)模型,该模型基于全局词频统计将一个词语表达为一个向量,通过单词之间的相似性、类比性等,计算出两个词语之间的语义相似性。方炯焜等结合GloVe词向量与GRU模型提高了文本分类性能。石隽锋等通过并行实现统计共现矩阵和训练学习,从而在中文和英文的词语推断任务上,显著地提高了预测的准确率。FANG等以GloVe为基础建立情感分析系统,虽然GloVe能够最大限度地利用全局和局部信息进行语料库训练,但无法应对一词多义或者新词组合的情况。针对该问题,2019年Devlin等引入动态词向量BERT(bidirectional encoder representations from transformers)模 型,BERT模 型 利 用Transformer结构的encoder部分对文本进行双向学习和处理,主要包含MLM(masked language model)任务 和NSP(next sentence prediction)任务。其中,核心任务是MLM任务,通过对目标单词进行掩码来预测词语的向量,利用自注意力机制学习词与词间关系,使得词向量的表示能够融入句子级的语义信息。段丹丹等使用BERT预训练语言模型对短文本进行句子层面的特征向量表示,并将获得的特征向量输入Softmax回归模型进行训练与分类,实验证明BERT有效地表示句子层面的语义信息,具有更好的中文短文本分类效果。Chao等结合动态掩码与静态掩码,提出新的MLM任务与层间共享注意力机制,有效地提高了BERT在实体关系提取上的性能。Danilov等提出了一种基于双向编码转换(BERT)和图卷积网络的门上下文感知文本分类模型(GC-GCN),通过使用带有门控机制的GCN将图嵌入和BERT嵌入集成在一起,以实现上下文编码的获取。虽然BERT解决了词向量无法表示一词多义的问题,但通过BERT进行向量化的过程中,缺乏了整体的词和词之间的关系。综上所述,现在国内外学者在文本向量化领域做了一些相关工作,但目前的文本向量化在中文文本语料的处理上仍然存在表义不足,因此,中文文本向量化具有研究潜力与价值。
本文在上述研究的基础上提出了基于GloVe与BERT字向量模型的融合字向量模型。通过GloVe领域预训练产生的文本向量无法解决一字多义的情况,但是能够最大限度地利用全局和局部信息进行语料库训练,从而给每一个字都提供一个相对稳定的字向量,在投入的数据量较小的情况下,通过BERT领域预训练难以达到训练效果,更多的是依赖初始权重集的选择。因此,GloVe与BERT在训练时各有优劣,本文通过扩充GloVe字向量产生的维度,与BERT字向量进行向量融合,从而在预训练生成的融合字向量中,既体现了GloVe字向量的全局稳定性,也通过BERT字向量的展现解决了一字多义的问题。
本文采用今日头条发布的中文新闻数据,该数据属于短文本类型,且包含大量同义或异义字词。新闻文本数据通过GloVe及BERT模型生成的融合字向量矩阵,该矩阵通过卷积神经网络实现文本特征的提取后进行字向量训练优化,通过全连接层对新闻数据的分类结果的准确率、召回率等一系列指标进行评判,对文本词向量的词义表示能力进行评价。
2 思路与框架
2.1 融合向量模型
融合字向量模型基于GloVe字向量模型以及BERT字向量模型,主要分为四个部分:输入处理层、融合层、特征提取层以及分类输出层,其具体结构如图1所示。

图1 融合字向量模型结构
在该融合字向量模型中,以今日头条发布的条新闻数据作为输入,选取数据中的文本数据以及标签数据,提取文本数据中的中文字词后,为了使GloVe与BERT的分词结果相同以达到词向量矩阵的数据量相同,从而进行BERT_tokenize单字分字处理,得到字粒度的中文文本语料库。
将该语料库输入GloVe字向量模型中,本文以300维的中文GloVe模型作为预训练模型获取字向量,在该字向量的表示中,GloVe模型通过语料的全局信息进行训练后,相同字有相同的字向量,因此不能表达一词多义。同时,将处理好的语料库输入BERT模型,生成768维的文本字向量,将GloVe向量与BERT向量通过点加的方式获得融合字向量。
融合字向量通过文本卷积神经网络获取多层级的语义特征信息,通过训练发现该字向量的关键信息,从而对768维的向量进行特征抽取,实现词向量降维。
在进行特征提取后,经过全连接层对文本数据进行分类处理。
2.2 输入处理层

在GloVe词向量模型中,将×个字中第一次出现的字挑选出来,若共有个不重复字,这个字组成共现矩阵的坐标标签,那么共现词频矩阵可表示为式(1):
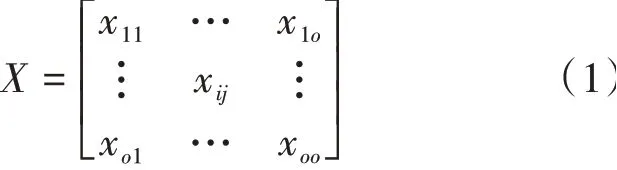


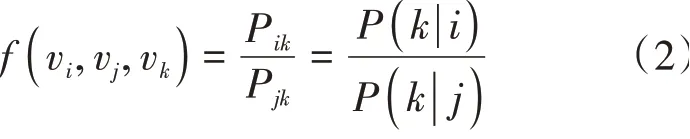

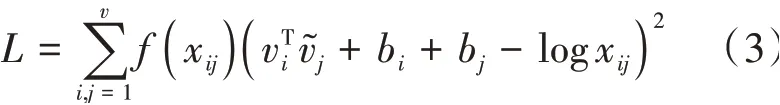


最后,通过AdaGrad的梯度下降算法对该函数进行训练,从而获取较优的词向量。GloVe词向量模型训练过程如图2所示。

图2 GloVe词向量模型结构
BERT以Transformer的encoder结构为基础,主要包含MLM掩码任务和NSP语句预测任务,BERT在输入嵌入层(input embedding)通过查询词典中每个词语对应的向量表得到句子的向量矩阵,与GloVe不同的是,BERT在输入嵌入层的基础上增加了体现词语在句子中所在位置的位置嵌入层,具体计算方式见式(5):

其中,为该词在句子中的位置,根据出现位置的单数或双数,以sin或cos方式生成的位置值交替出现,为模型需要训练的参数。BERT在位置嵌入层的基础上增添了体现句子在文本语料的位置关系的句子嵌入层,根据句子出现的位置,表示为[,,…,,,,…,,…]的形式,E表示第个句子的第个词,且E=E=…=E,用以区分该句中的词语与其它句子中的词语。这三个嵌入层共同组成encoder结构的输入层。
三个矩阵、、与相乘得到q,k,v,∈( 1,2,…,),将q与k做 点 积 得 到α,α通过全连接层后得到0~1之间的','与对应位置的v相乘且求和得到输出b,这就是多头注意力机制,具体过程如图3所示。

图3 多头注意力机制
多头注意力机制生成的b通过前馈神经网络的训练生成BERT词向量,BERT词向量模型结构如图4所示。

图4 BERT词向量模型结构
2.3 融合层
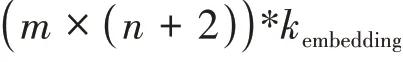

图5 融合字向量
2.4 特征提取层


图6 文本卷积神经网络结构
2.5 分类输出层

3 实证研究
3.1 实验数据
本实验以今日头条发布的开源新闻数据集作为输入数据,原数据集包含15类共382669条数据,每条数据包含文本id名、文本类别数值代号、文本类别名、文本内容、关键词五列。从15类新闻中抽取“文化”和“娱乐”两个板块的新闻,其中文化新闻共28030条,娱乐新闻共39396条,满足实验所需。从这两个类别的数据中抽取文本类别数值代号和文本内容两列内容后,分别抽取250条、500条、2500条、5000条,组成共有500条数据、1000条数据、5000条数据、10000条数据的4个不同大小的文本语料库。
将文本内容进行文本正则化处理,仅保存文本中的中文字,并且按照字粒度对文本进行分词后,将其按照类别标签存储在各自类别的文件夹里,每一条文本存储在以索引编号命名的文件里。将文本数据进行打乱顺序处理,选取其中20%的数据作为评估集,80%的数据作为训练集,并且评估集与训练集相互独立。由于单次划分得出的结果并不稳定,因此每个输入数据集进行20次实验,选取20次实验中效果最好的5次实验结果的平均值做为最终的实验结果。
3.2 评价指标
本文实验的评估指标有:评估集的准确率、评估集的查全率、评估集的查准率,评估集的值四个。
将“文化”类的数据设为负类,“娱乐”类的文本数据设为正类,得到的预测类别与实际类别的情况见表1。
(3)梁弯曲挠度分布在裂纹处存在尖点,且对于开裂纹,当载荷较小时,挠度在裂缝处的尖点现象并不明显,但随着载荷的增加,尖点现象愈加明显.同时,梁横截面转角在裂纹处发生突变,转角不连续.

表1 二分类混淆矩阵
将预测为正类且实际类别也为正类的结果记为,预测为负类但实际类别为正类的结果记为,将预测为正类但实际类别为负类的结果记为,预测为负类且实际类别也为负类的结果记为,那么有:

其中展示了分类正确的数据条数与数据总数的比值,可以在总体上衡量一个预测的性能;表示被正确分类的正类数据条数与所有应该被判断为正类的数据条数之间的比值,展示正类样本被误判的程度;展示了被正确分类的正类数据条数与所有被判断为正类的数据条数之间的比值,找到所有的正类防止漏掉正类样本。将和视为相同重要的两个评估标准,对模型的性能进行了一个综合评价。
3.3 参数设置
GloVe词向量基于全局词频统计把单词表现为一个300维的向量形式,词典大小为352221;BERT预训练模型采用bert-basechinese模型,包含12个encoder单元,768个 隐藏单元数,12个注意力机制的头数,110M参数,词典大小为21128,生成768维的词向量。在文本卷积神经网络中,选取两层卷积神经,为了查看两个字组成的词语之间的关系,将第一层卷积核的大小设为2;为了查看主谓宾之间的关系,将第二个卷积核的大小设为三;由于是二分类,在全连接层采用sigmoid激活函数,将数据特征分为正负两类。具体参数见表2。

表2 卷积层参数设置
4 结果与分析
为了验证该融合向量算法的有效性,将今日头条的4种不同大小的数据集在GloVe预训练算法、BERT预训练模型以及融合词向量预训练模型中进行训练,得到的准确率见表3。

表3 准确率
各个模型在不同数据集上的召回率见表4。
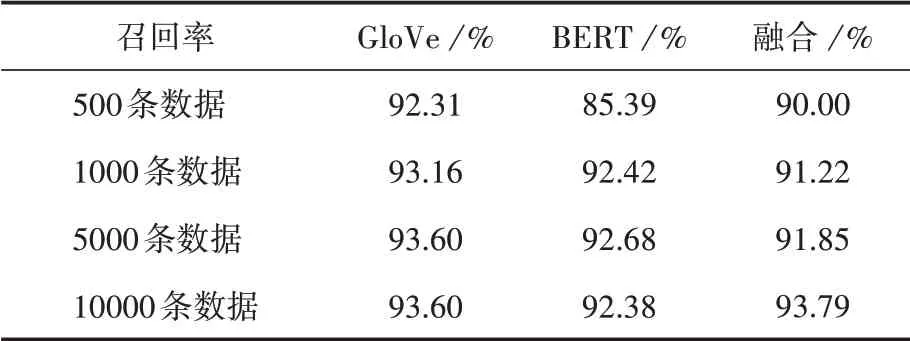
表4 召回率
模型在不同数据集上的查全率如图7所示。
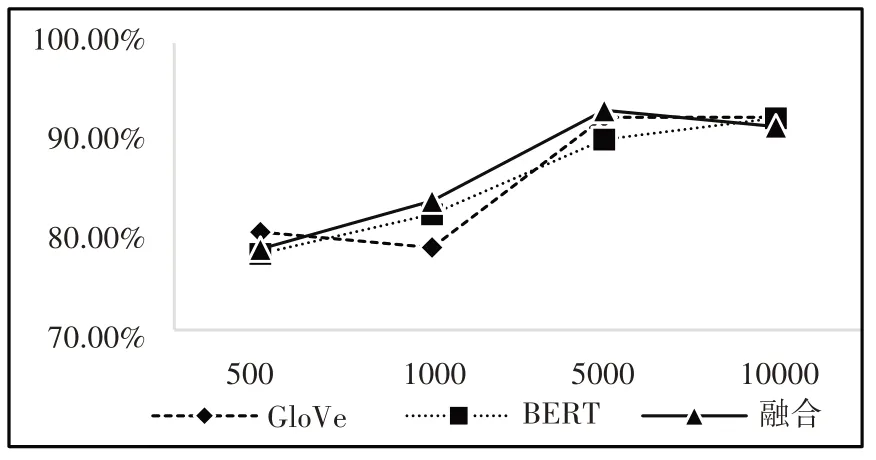
图7 查全率
模型在不同数据集上的值如图8所示。
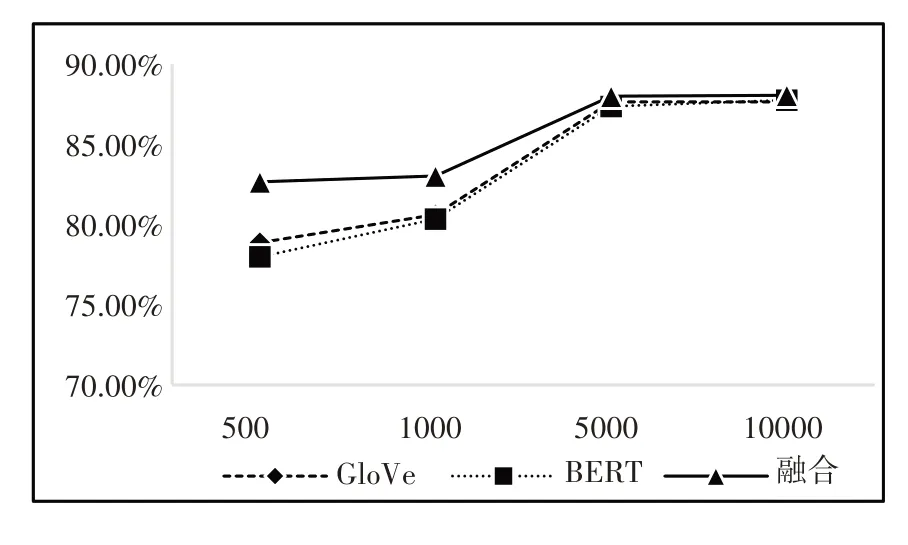
图8 F1值
由实验得出如下结论:
(2)通过表4中召回率的展示可以发现,GloVe模型的表现不比BERT模型表现差。在表2中,输入数据为500条时,GloVe模型产生的词向量最终训练后的准确率为77.00%,而BERT预训练模型产生的词向量训练后的准确率为75.80%,这是由于小数据量时的同词异义的情况出现的概率较小,采用词频统计的方法构建字典从而生成词向量,相比使用数据进行迭代优化出来的词向量,在数据量较小时能够更加准确地表达词义。
(3)在图8中,融合向量模型的值总是略高于单一模型的值,并且数据量越小,融合向量模型的优势越明显。图7显示,相较于单一模型产生的词向量,融合向量模型的查全率在1000条以及5000条数据组成的语料库中都高于单一模型的训练效果。在表3中,融合向量准确率在数据量较小时有小幅度的提升,当数据量为500时,融合词向量相较于BERT词向量提升了5个百分点,相较于GloVe词向量提升了3个百分点;当数据量为1000时,融合词向量相较于BERT词向量的精确率提升了3.1个百分点,相较于GloVe词向量提升了3.4个百分点。
(4)上述图表显示,当输入的数据量较大时,各个模型训练出来的词向量的最终准确率都在86%~88%之间,准确率相差一个百分点以内,并没有显著的区别。这是由于输入模型的数据量足够让BERT训练出一个较好的结果,同时也反映了融合词向量模型在大数据量时的训练效果,虽然没有明显优于BERT词向量模型,但也并不逊色于BERT词向量模型。
从5000条输入数据增加至10000条输入数据时,GloVe模型与融合词向量模型的准确率没有明显的变化,而BERT词向量模型的准确率提升了0.82个百分点,但BERT模型依靠增加数据量来提升准确度的收效减小,代价过大。
5 结语
本文的研究价值主要体现在:通过对BERT与GloVe模型生成的词向量进行融合,获取两种词向量的语义信息,从而在小数据量的语料库中,融合词向量的语义信息表示能力有一定的增强,采用浅层文本卷积神经网络对融合词向量进行特征提取,使得该融合词向量能够准确表达词义的同时,也降低了实验中对硬件的要求,降低了模型的部署难度。
本文详细阐述了融合词向量的整体框架、模型结构,以及相关的计算公式,并用不同大小的数据集来验证模型的有效性。实验表明,相较于传统的GloVe模型和单一的BERT预训练模型,融合词向量模型的准确率在较小数据量的情况下都能得到提升。这说明融合不同词向量方法的文本表示能够获取字词的先验知识,同时根据数据特征进行优化,从而获得词向量更好的表示方法。
在未来的研究中,可以尝试采用不同维度的文本信息,比如词粒度文本信息,在词向量融合时引入注意力机制,为BERT词向量以及GloVe词向量加一个权重之后进行词向量融合,从而进一步提升文本的表达能力。
