FOCoR:一种基于特征选择优化的课程推荐技术
2022-10-18王扬,陈梅,李晖
王 扬,陈 梅,李 晖
(贵州大学计算机科学与技术学院,贵州 贵阳 550025)
0 引 言
课程推荐是在线教育领域解决学习者和课程快速匹配的关键。主流推荐算法通常会基于显式的课程评分反馈进行分析,但是由于用户一般很少主动地对课程进行评分,因而高质量数据通常不足且容易导致用户与推荐课程的匹配度并不高。在线教育平台的行为日志能够较真实地反映用户的课程学习偏好,而且数据也相对容易获取,因此基于用户行为日志作为隐式反馈课程推荐算法的研究越来越多。
基于行为日志的推荐系统规避了评分数据获取困难的窘境,但是在日志数据不足的情况下依然存在着严重的用户冷启动问题。本文针对在线教育平台中行为日志推荐系统存在的冷启动问题,设计一种融合高校选课数据的基于特征选择优化的课程推荐方法FOCoR (Features Optimization based Courses Recommendation)。在FOCoR的研究过程中,本文提出基于遗传算法的特征选择技术FSBGA (Feature Selection Based on Genetic Algorithm),构造出结合模型损失和特征数量的适应度函数,并在高校选课数据的特征子集空间中搜索出兼顾模型损失和特征数量的最优特征子集作为推荐模型的输入,然后基于梯度提升树LightGBM技术构建推荐模型进行课程推荐。为了验证FOCoR方法的有效性,本文在某高校的真实数据集上进行了实验分析。
1 相关工作
推荐模型所需的部分输入数据缺失是产生冷启动问题的根本原因。一些研究借助其它类型的数据来应对冷启动问题,这一类方法被称为基于辅助数据的方法[1]。常用的辅助数据包括用户人口统计学数据、社交网络数据、情景信息等。首先,简要回顾部分解决方案。Raigoza等人[2]利用人口统计学特征将用户分为不同群组,进而基于项目在相似特征用户群组中的流行程度或热度进行推荐。巫可等人[3]利用人口统计学数据的隐语义推荐模型,通过属性映射,解决了协同过滤算法的冷启动问题。Lika等人[4]在基于人口统计学特征对用户分类的基础上,设计了评分预测函数,基于同组用户的评分对新用户进行推荐。Park等人[5]关注了自适应学习环境下的冷启动问题,面向新用户提出一种基于用户背景信息的方法。此外,自适应学习系统可以根据用户学习能力为用户定制个性化学习环境,也有助于解决用户冷启动问题。
随着社交网络的广泛应用,越来越多的研究尝试利用社交网络数据改善推荐系统性能或进行推荐,这类推荐也被称为社会化推荐[6]。用户基本情况数据、用户与朋友的交互数据、用户与其所属机构的关联数据等都可以用于推荐[7]。社交网络数据也为冷启动问题的缓解提供了有力支持。Sahebi等人[8]用社区发现技术从社会化网络中识别社区,在社区内计算新用户的最近邻进行协同过滤。Nguyen等人[9]在社区发现与识别的基础上计算社区中所有用户对特定项目的偏好,这一社区偏好可用于解决协同过滤中的数据稀疏和新用户冷启动问题。Zhang等人[10]利用社交网络数据对用户静态偏好和动态偏好建模,可以缓解新用户冷启动问题。
情境信息也称为上下文信息,是任何可以用于描述一个实体情况特征的信息,例如时间、空间、设备、环境等。利用情境信息实施推荐的系统成为情境感知推荐系统信息推荐领域重要的发展方向之一[11]。引入情境信息不仅可以提高推荐模型的准确率,还有利于缓解冷启动问题。于洪等人[12]同时考虑用户、标签、项目属性、时间因子之间的关系,在基于图的模型基础上,进行个性化评分预测,以此解决项目冷启动问题。Chen等人[13]提出一种协同过滤的Web服务QoS(Quality of Service)预测方法,该方法将用户和Web服务在地理空间上近邻的数据整合到矩阵分解模型中,可以缓解评分数据的稀疏和冷启动,提高预测准确性。Viktoratos等人[14]从Foursquare收集用户的登录信息,通过关联规则挖掘建立用户登录日期、时间段、天气与POI(兴趣点)类别的关联,基于这种关联规则为用户推荐POI,新项目的推荐可以基于其所属的类别实现。Tian等人[15]在基于项目流行度推荐的基础上,引入时间和空间2种情境信息计算情境化的流行度,为新用户进行推荐。
关联开放数据(Linked Open Data, LOD)项目的发展为数据密集型任务提供了获取所需信息的便捷方式,LOD要求用户以RDF格式发布数据,并通过RDF三元组建立与其他数据集合的关联。一些研究引入LOD数据用以缓解推荐系统的冷启动问题。例如,Wang等人[16]提出一种关联数据驱动的数字图书推荐模型,把图书馆的本地数据与外部相关的关联数据相融合,根据图书馆资源信息的不同的特性,分别构建用户社会关系语义本体知识库与数字图书语义本体知识库,并根据用户对图书浏览的活跃程度,针对不同的用户,采取不同的推荐策略,缓解了图书推荐系统的冷启动问题。Srinivasan等人[17]利用LOD数据和用户评分数据构建语义关联图谱用以增强推荐的多样性。LOD也为冷启动问题的缓解提供了富含语义关联的数据。Natarajan等人[18]利用开放链路数据缓解了旅游推荐系统存在的冷启动问题。莫荔媛[19]在推荐系统中提供了LOD数据的接口,当新用户或新项目进入推荐系统时,查询在LOD数据集合中获取用户信息或项目信息,以此解决冷启动问题。
课程推荐本质上是要预测用户参与一门课程学习的概率。高校选课数据集为这种预测提供了基础。因此本文构建结合选课数据集的课程推荐算法,以解决行为日志课程推荐系统存在的冷启动问题。
2 基于特征优化的课程推荐方法FOCoR
本章主要介绍结合选课数据集的课程推荐方法FOCoR。其核心步骤分为数据预处理、特征选择和选课概率计算。在数据预处理环节中,介绍WOE编码原理以及如何应用WOE编码将选课数据集中的类别特征转变成数字特征。在特征选择环节将介绍正交表的原理,并提出基于遗传算法的特征选择方法FSBGA。FSBGA使用正交表生成遗传算法的初始种群,通过自定义的适应度函数来平衡模型损失与特征的数量,从而找到利于模型训练的最优特征子集。在选课概率计算环节介绍了LightGBM的原理并使用LightGBM在FSBGA选择的特征上训练是否选课的二分类模型。依据选课模型输出的选课概率对用户进行课程推荐。课程推荐算法FOCoR的核心流程如图1所示。
2.1 基于WOE的数据预处理
在本文中,数据预处理是指在模型训练前对模型无法处理的数据进行处理的过程。由于大多数机器学习算法不能处理类别型特征,因此模型训练前需要将其转换为数字特征,这个过程被称为特征编码。常见的特征编码方案有One-Hot编码和WOE(Weight of Evidence)编码这2种。其中One-Hot采用二进制编码,每个比特位对应特征的一个取值水平xi,该位为1表示该特征的取值为xi。WOE编码,即证据权重,也叫做自变量的一种编码,其定义如式(1)。
(1)
其中i为某个特征的取值。Badi为该特征取值为i时的Bad标签数量,BadT为该特征总共的Bad标签数量。Goodi为该特征取值为i时的Good标签数量,GoodT为该特征总共的Good标签数量。考虑到One-Hot编码容易产生高维稀疏矩阵,不利于模型训练,因此使用WOE编码对选课数据集中的类别型特征进行特征编码。
在选课数据集中有“年级”这一类别特征,下面介绍如何对其进行WOE编码。首先从选课数据集中统计出各年级学生的选课数量,如表1所示。
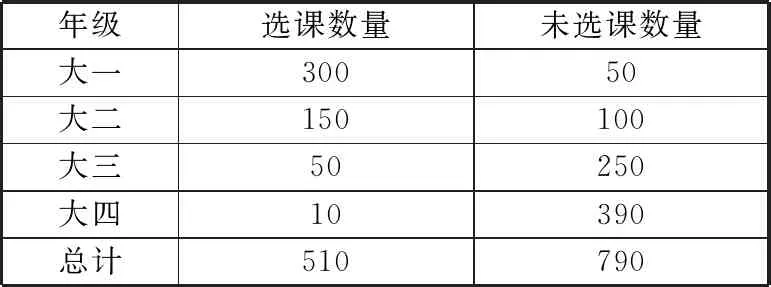
表1 不同年级学生的选课数量

2.2 特征选择
特征选择能过滤冗余特征,提高模型精确度,促进模型的构建和优化。在特征选择过程中,常采用的特征搜索策略包括全局搜索、随机搜索和启发式搜索3种。高校选课数据集的更新频率较慢,通常在某固定时间才会发生更新(例如:每学期开学时)。在特征较多但仍期望获得最优特征子集时,通常采用随机搜索策略。本文采用遗传算法作为特征选择方法并使用正交表[20]生成遗传算法的初始种群。
2.2.1 正交表技术
由于特征选择之前,人们并不知道哪些特征是对推荐模型训练有益的优质特征。因此需要使用正交表将初始种群均匀地、离散地分布在整个特征子集空间。通过这种方式,不仅缩小了初始种群的规模使得模型容易收敛,也使得初始种群更具有代表性。
正交表是经验制成的用于设计等水平正交实验的二维表格,记为Lx.y.z。其中L是正交表的记号,x为期望的样本数量,y是变量的取值个数,z是变量的数量。使用正交表生成的实验样本具有均衡搭配、综合可比的特点[14],这些特点对于其正交性具有重要的意义。
1)均衡搭配。任意特征的任意取值与其它特征的每一个取值搭配的次数均相等。
2)综合可比。任意特征的取值出现的次数相等。
关于正交表的特点比较容易理解,以3个特征、每个特征2个取值的L4.2.3正交表为例来说明,如表2所示。

表2 L4.2.3的正交表
由表2可知,各特征的取值均出现2次,各特征的取值与任意特征的取值搭配均出现1次。
2.2.2 基于遗传算法的特征选择
特征选择问题其实也是组合优化问题。本小节介绍遗传算法的原理并提出使用遗传算法求解特征选择问题的FSBGA算法。
遗传算法是一种模拟自然进化过程搜索最优解的方法,通常能够较快地获得较好的优化结果。图2是遗传算法的流程图。
使用遗传算法进行特征选择的关键在于设计出平衡特征数量于模型损失的适应度函数。本文希望特征选择算法搜索出分类能力好并且特征数量较少的特征子集。因此定义适应度函数如下:
(2)
其中L(x)为模型对于所选特征向量x的对数损失。Fn表示特征维度个数。α∈[0,1]是给定的平衡因子,当α=0时,适应度函数取决于特征维度个数,当α=1时,适应度函数取决于分类模型的对数损失。因此平衡因子α可以调节模型损失和特征数量间的权重。由于适应度函数中使用了分类模型的对数损失值,会导致适应度的计算时间较长,影响模型的收敛速度。对于这个问题本文从2个方面做出优化:
1)利用数据字典保存历史基因的适应度,在计算适应度函数时,若基因在数据字典中存在,返回对应的适应度值。
2)创建被淘汰样本的集合,当交叉、变异产生的样本在已淘汰的中时,重新选择父代产生新的后代。
2.3 基于梯度提升树的选课概率计算
本文依据选课模型输出的选课概率对用户进行课程推荐,因此选课模型的好坏与课程推荐的有效性息息相关。LightGBM[21]是一种高效的集成树算法,常被用于点击率预测、搜索排序、物品推荐等任务中。因此本文使用LightGBM在FSBGA选出的最优特征集上训练是否选课的二分类模型。本节将介绍梯度提升树[22](GBDT)的原理,以及XGBoost[23]为了提高GBDT的准确率、降低过拟合风险所做出的改进,最后介绍LightGBM为了提升计算速度、降低资源开销在XGBoost上做的优化。
2.3.1 梯度提升树
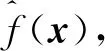
1)初始化模型:估计使式(3)取最小值的回归树C进行初始化,C是只有一个根节点的树。
(3)
2)进行模型迭代,迭代次数m=1,2,…,M:
①对i=1,2,…,n,计算残差rim,即在当前模型下的损失函数的负梯度值:
(4)
②根据rim拟合一棵回归树,得到第m棵树的叶子区域Rmj,j=1,2,…,J,J标识叶子节点个数。
③对j=1,2,…,J,利用线性搜索估计叶子节点区域的值Cmj,令损失函数极小化:
(5)
④更新回归树:其中I为示性函数,当回归树判定x∈Rmj时,I(x)=1,否则I(x)=0。
(6)
3)迭代M次后输出最终模型:
(7)
2.3.2 XGBoost算法
GBDT的高精度使它在工业界广泛应用,但GBDT方法只利用了一阶导数信息,且容易产生过拟合。XGBoost则在目标函数中加入了正则项,使得式(5)的目标函数变成了式(8)。
(8)
其中∅(fm(xi))是正则化项。利用二阶泰勒展开对其近似,使得提高了计算精度且降低了模型过拟合的风险。仔细分析XGBoost的算法逻辑,还是会发现一些不足:
首先,特征数量越多算法迭代的次数就越多,这对内存的消耗很大,也会延长模型的收敛时间。
其次,在计算特征分割点时,会遍历所有特征分割点,收益不高的分割点太多时,会降低算法的计算效率。
2.3.3 LightGBM算法
为了进一步提高计算效率,降低资源消耗,LightGBM引入了基于梯度的单边采样(GOSS)算法与互斥特征绑定(EFB)算法。
因为梯度大的样本对计算信息增益的贡献更大,因此GOSS随机丢弃部分梯度小的样本,以减少模型训练的耗时。以下是GOSS的理论部分:
(9)
其中:
(10)
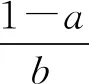
(11)
EFB算法将互斥特征绑定成一个特征,实际情况中很多的数据处理方式会产生稀疏矩阵,EFB算法可以将互斥特征变成一个特征。通过特征数量的减少,可以降低计算的复杂度,减少算法运行的内存消耗。
正是GOSS、EFB算法的引入,使得比起XGBoost, LightGBM模型训练的内存消耗更少、训练时间更短。因此本文使用LightGBM训练是否选课的二分类模型。
3 实验结果与分析
3.1 数据介绍
本文使用的数据是由某高校教务数据库中抽取出的学生选课数据集。有记录437616条,包含40个特征,详情见表3。其中授课教师特征12个、学生相关特征18个、课程相关特征10个,以及是否选课的标识。

表3 特征汇总表
3.2 基线模型
FOCoR模型通过计算学习者的选课概率进行课程推荐,选课概率计算是推荐过程的核心,表4给出了常见的用于推荐任务的二分类模型。

表4 推荐任务的常见二分类模型
3.3 评估指标
本文采用对数损失、准确率、召回率、F1分数、ROC曲线这5个指标来评估模型的性能。
对数损失描述了分类模型能正确分类的能力,二分类模型的对数损失的计算参照式(12):
(12)
对于用户u推荐N门课程的集合记为R(u),而u在平台上推荐之后参与的课程集合为T(u),准确率的计算方法参照式(13):
(13)
准确率表示用户对被推荐课程感兴趣的概率,准确率越大,说明用户对被推荐的课程越感兴趣。召回率的计算公式参照式(14):
(14)
推荐召回率表示用户感兴趣的课程被推荐的概率,召回率越大,说明越可能向用户推荐感兴趣的课程。F1分数计算参照式(15):
(15)
F1分数是精确率和召回率的调和平均,是同时考虑了准确率和召回率的一种评估方式。
ROC曲线:该曲线的评判标准是曲线越靠近对角线的左上角,模型分类效果越好。AUC值则表示ROC曲线下的面积。
3.4 实验结果
3.4.1 不同特征选择方法的结果与分析
选课数据集包含40个特征,因此根据L48.2.40的正交表生成种群规模为48的初始种群。在平衡因子α=0.7,变异系数β=0.002时,经过85轮迭代后收敛,得到最优特征20个。
为验证FSBGA进行特征选择的有效性,将FSBGA与互信息[29]、F检验[30]这2种常见的特征选择方法进行对比。不同特征选择方法下的指标数据如表5所示。

表5 不同特征集下推荐模型的指标
图3是推荐模型在不同特征选择算法选出的特征子集上的ROC曲线。
表6记录了FSBGA相较于互信息与F检验的指标提升幅度。

表6 遗传算法的指标提升幅度/%
从表6可知使用FSBGA进行特征选择的课程推荐模型在各项指标上均优于使用互信息与F检验做特征选择的推荐模型。其中相对于F检验的对数损失降低了49%,AUC指标提升了75%。可能是由于WOE编码后的数据不服从正态分布,使得F检验的效果不好导致的。
3.4.2 不同选课概率预测模型的结果与分析
在选课数据集上划分80%的数据作为训练集,20%的数据作为测试集。表7是不同的推荐方法训练的模型在测试集上的指标。

表7 推荐模型的评估指标
图4是不同推荐方法绘制的ROC曲线。
表8记录了使用FSBGA后不同推荐算法的指标提升幅度。

表8 FSBGA对不同推荐算法指标的提升幅度/%
从表8可以看出,采用FSBGA特征选择方法后,除DNN外,其余课程推荐方法的准确率、召回率、F1、AUC指标提升幅度不大,但模型的对数损失大幅降低。这表明FSBGA有助于提高这些模型的分类能力。由于DNN自身具有特征选择能力,因此FSBGA未能提升DNN的指标表现。然而DNN的准确率只有0.84,这可能是DNN在小数据集上产生了过拟合导致的。
同时在FSBGA选择出的特征集上,LightGBM所训练的选课模型在F1分数上表现最佳,因此使用其作为最终的课程推荐模型。
4 结束语
本文设计了融合高校选课数据的课程推荐方法FOCoR来解决在线教育平台行为日志推荐系统存在的冷启动问题。针对选课数据中的特征冗余问题,提出了基于遗传算法的特征选择方法FSBGA,并将其与基于互信息、F检验的特征选择方法进行对比,验证了FSBGA特征选择方法的有效性。此外,本文将FOCoR与LightGBM、XGBoost、决策树、随机森林、逻辑回归等技术在真实数据集上进行对比分析,验证了其性能优势。尽管FOCoR采用FSBGA来进行特征选择,能够有效提升推荐模型的关键性能指标,但目前只能选出较优的一阶特征。如何结合特征交叉技术筛选出高阶特征来进一步提高推荐能力,将是本文研究工作的后续优化方向。
