ALBERT结合双向网络的文本分类
2022-10-18黄忠祥
黄忠祥,李 明
(重庆师范大学计算机与信息科学学院,重庆 401331)
0 引 言
人们通常使用计算机进行NLP领域内各项任务的处理,并利用计算机可进行高速运算的特点,对各类下游任务进行处理,这些任务可以是实时的,也可以是间断性的。文本分类是其中的基础性任务,提升文本分类的准确率,对于帮助人们在众多信息来源中,提取最有用、研究最有意义的信息是很有必要的[1]。
滕金保等人[2]提出了MLACNN模型,主要是同时使用LSTM-ATT和CNN进行特征信息的提取,最后进行特征的输出。滕金保等人[3]还提出了MCCL模型,同时使用CNN和LSTM叠加注意力机制进行特征信息的提取,并输入到全连接层进行后续的分类。田园等人[4]提出了使用BERT完成文本编码,然后输入到双向的LSTM模型训练并结合注意力机制,应用到softmax层完成分类,最后应用于电网设备缺陷数据集。同时,针对电网设备故障的文本信息,田园等人[5]还提出了使用Word2vec进行文本向量化,将字符信息转换后,输入到结合了注意力机制的,能够对重要信息进行加权突出的BiLSTM网络中,进行设备故障文本的处理。段丹丹等人[6]提出了使用BERT-base预训练模型取代常用的Word2vec模型,来进行短文本信息的向量化,并将特征向量使用softmax进行最后的分类。文献[7]使用BERT作为词嵌入层,使得向量能够有更强的语义特征表现,获得的特征在正反2层GRU网络中进行运算,用注意力机制进行重点语句的突出,形成BBGA模型,并在THUCNews数据集进行了验证。文献[8]提出了ALBERT-BiGRU模型,主要是在专利文本数据集中,使用ALBERT取代传统的Word2vec模型,并结合BiGRU神经网络训练,达到分类效果的提升。文献[9]则是采用了ALBERT-base获取更好表征特征性的动态词向量,使用结合了CNN和BiGRU优点的神经网络模型CRNN进行训练,最后再经过softmax层完成分类。文献[10]提出了结合注意力机制的双通道文本分类模型,主要利用了双向LSTM和CNN网络同时进行信息的提取,在双通道中均引入了注意力机制进行权重的分配,并在今日头条和THUCNews数据集中进行验证以及性能评估。
针对多标签分类,文献[11]提出了基于AdaBoost改进的BoosTexter算法;文献[12]提出了一个基于排序的支持向量机的学习模型(Ranking Support Vector Machine, Rank-SVM)来解决多标签问题;Zhang等人[13]提出了基于KNN算法进行改进的方法(Multi-Label k-Nearest-Neighborhood, ML-KNN),该方法利用最大后验估计确定隐藏实例的标签集。文献[14]提出了CNN-RNN模型,利用CNN得到文本序列信息,并结合使用RNN的变种——LSTM进行特征学习。文献[15]利用双向GRU结合注意力机制进行网络设计,并完成多标签文本分类。
值得注意的是,深度学习拥有着强大的特征学习能力,而如何利用深度学习技术去提升多标签文本分类方法的性能表现,这点是值得研究的[16-17]。本文针对多标签的文本分类提出运用预训练模型完成文本向量化,结合深度学习算法,并辅助以注意力机制优化输出文本对应标签。具体为,提出利用ALBERT对文本进行字符级别的向量化,以期更好地挖掘文本深层特征,增加模型的泛化性能,并输入到双向LSTM神经网络中进行信息提取后,经过注意力机制层的特定信息加权凸显,最后完成多标签的文本分类的ABAT(ALBERT-BiLSTM-Attention)模型。
1 背景知识
1.1 ALBERT预训练结构
随着BERT模型[18]及其large版本的横空出现,更多的模型改进方向是增加模型参数量,然后使用拥有巨大算力资源的计算机去完成计算。这样的方法的确是有效的,但对机器的硬件要求极高,ALBERT属于对BERT模型轻量化改进。
ALBERT改进的方向是,在BERT优秀的框架基础上,保持模型原有的性能,然后尽可能地减少模型的参数量,以便更好地利用计算资源。为此ALBERT做了以下的改进:
1)词向量矩阵分解。
ALBERT对嵌入词向量矩阵进行分解,将其分解为2个规模小一点的矩阵。假设词汇表的大小是V,词嵌入的大小是E,隐藏层的大小是H。原本BERT模型参数矩阵的维度为O(V·H),ALBERT将嵌入词向量矩阵分解后,参数矩阵的维度变成O(V·E+E·H),模型的参数量将会大大减少[19]。
2)隐藏层参数共享。
将词向量矩阵分解后,模型的参数量的确大大减少了,但是由于隐藏层需要完成更复杂的任务,隐藏层的参数量仍然是巨大的。ALBERT通过共享隐藏层各模块的参数,想要进一步缩小隐藏层的参数规模。
一般说来,可以在各层间前馈神经网络以及注意力层间进行共享层间参数,可以只共享前馈神经网络的参数,也可以只共享注意力层的层间参数,也可以两者同时共享参数。ALBERT选择将两者的参数都进行共享,这样的方法使得ALBERT保持着多层网络连接的同时,各层的参数仍保持一致,使得ALBERT隐藏层的参数量变为原来的1/12或1/24[20]。
3)句子间顺序预测。
为了提高模型在成对句子之间关系下游任务的推理能力,BERT模型是对句子对的关系进行判定NSP(Next Sentence Predict),即判定句子1是否为句子2的下一句,若结果不是,则判定句子1和句子2分别属于不同的文章。而ALBERT采用SOP(Sentence-order Prediction)的策略,对句子对的顺序进行判定,分别为判定句子1是句子2的下一句和句子2是句子1的下一句这2种情况。相比于BERT模型的NSP策略,ALBERT模型通过SOP的策略可以在学习句子间的语义关系任务上有着更好的表现
4)移除Dropout。
ALBERT的作者在实际的模型训练中发现,当ALBERT模型使用了随机关停神经元的训练策略,经过了上百万步的训练后,还是没有出现过拟合的现象。这预示着不使用Dropout,反而会让ALBERT发挥更好的性能,Dropout反而成了影响模型性能发挥的限制器。因此ALBERT预训练模型中将不设置Dropout率。
1.2 双向长短期记忆网络
LSTM是有着遗忘门、输入门和输出门3个门结构的特殊的RNN模型[21-22],相比于使用传统的RNN结构进行训练,LSTM可以很好地避免网络训练过程中的梯度消失和梯度爆炸的弊端。其中,遗忘门的主要作用是在更新LSTM细胞单元的时候,对已存储的特征信息进行有选择性的遗忘,类比于大脑对重要信息和次要信息处理;输入门的主要作用是,当LSTM细胞单元接收到新的信息时,将会有选择性地进行特征信息的存储;输出门的主要作用是,决定LSTM细胞单元的最终输出内容。LSTM的细胞单元结构如图1所示。
遗忘门的计算公式如下:
ft=σ(Wf·[ht-1,xt]+bf)
(1)
公式(1)中,ft表示t时刻的遗忘门节点的操作,σ是sigmoid函数,Wf为参数矩阵,ht-1表示上一个状态向量,xt为t时刻的输入向量,[ht-1,xt]表示把2个向量进行连接,bf为偏置项。由图1和公式(1)可以看出遗忘门主要决定在t时刻,上一个单元状态ct-1有多少可以保留在当前时刻ct中。
输入门的计算公式如下:
it=σ(Wi·[ht-1,xt]+bi)
(2)
(3)
(4)
公式(2)中,it表示t时刻的输入门节点的操作,σ是sigmoid函数,Wi为参数矩阵,bi为偏置项,主要计算当前时刻输入xt,选择保存多少到单元状态ct中。

输出门的计算公式如下:
ot=σ(Wo·[ht-1,xt]+bo)
(5)
ht=ot⊗tanh(ct)
(6)
其中,ot是t时刻输出门的节点操作,输出门控制着ct最终有多少能输出到单元输出值ht中。
单向的LSTM在处理长序列文本时只会从前向后进行信息的提取,很可能会造成深层特征信息利用得不充分。为了更好地挖掘序列的特征信息,本文将使用双向的LSTM进行模型的训练,双向的LSTM模型将会沿着正反2个方向对序列文本进行处理,最大限度地利用语料的信息[23]。
1.3 注意力机制
在模型中加入注意力机制可以使得模型处理关键信息时,去除无用信息的干扰,提取最能表达序列文本深层信息的特征。其本质还是编码器到解码器的结构模仿了人类大脑面对繁杂信息时,忽略对结果无贡献的细节,如何聚焦最主要信息的思维方式[24-27]。
2 模型构建
图2是本文构建的ABAT模型整体框架。
1)ALBERT预训练层。使用ALBERT预训练模型进行文本序列的向量化。相对于Word2vec,使用ALBERT预训练模型进行的是分字操作,可以对语料文本进行字符级别的向量化。
在本模型中,系统会提取数据集中每条数据对应的标签以及实际文本内容,作为最初的输入信息X。此时的X属于尚未进行向量化的待处理文本,其格式如公式(7),Xi代表着待处理文本中第i个字符。
X=(X1,X2,…,Xn-1,Xn)
(7)
待处理文本X经输入层输入到ALBERT预训练层后,算法将首先对于文本信息里每个单词在字典中编号位置标记出来,获得对应的编号,并进行文本内容的向量化,获得信息序列E,如公式(8)所示。其中Ei表示第i个字符对应的向量化。
E=(E1,E2,…,En-1,En)
(8)
获得信息序列E后,还要将E输入到ALBERT模型中的Transformer编码器进行深层特征信息的挖掘,转换得到序列文本最终的特征向量表示T,如公式(9)所示。其中Ti表示第i个字符对应的特征向量。
T=(T1,T2,…,Tn-1,Tn)
(9)
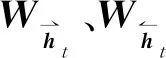
(10)
3)注意力层。将经过双向LSTM训练过的特征向量作为注意力层的输入,使得网络聚焦于深层的文本语料,最能包含文本信息的向量得到凸显,最后完成多标签文本分类。实际的计算公式如下:
ut=tanh(Wuyt+bu)
(11)
φt=softmax(s(ut,q))
(12)
(13)
其中,Wu和bu分别是注意力机制层的权重矩阵和偏置量,双向LSTM层的输出yt作为注意力机制层的输入,q为查询权重,s(ut,q)为打分函数,φt为每个字符的权重程度信息,V是最后的输出向量。
4)验证。输入待预测的语句,模型给出待判断事件的类别标签。
3 实验结果与分析
3.1 实验数据集
本文实验使用DuEE1.0数据集[28],该数据集来源于百度联合CCF、CIPSC共同开源的千言数据集(LUGE)。DuEE1.0是百度发布的中文事件抽取数据集,训练集和测试集共含有15396条数据,外加31416条混淆数据,主要包括65个事件类型的长短不一的中文句子,以及对应句子所属分类,每个句子至少归属于一个或多个标签。从中抽取15000条数据,并且将每条句子原有顺序打乱,重新进行随机分配混合,按照8:2的比例进行训练集和测试集的编排,使用12000条数据作为训练集、3000条数据作为测试集完成实验。
重新编排的数据集中,如单标签样本句子“NBA球星哈登就违反交规一事致歉称已接受处罚”,该样本对应标注的标签为:“交规-道歉”。如多标签样本句子“范思哲凌晨就问题T恤道歉:已下架产品并销毁”,该样本对应标注的标签为:“交规-道歉”和“产品行为-下架”2个事件标签。重新编排的数据集中,多标签句子有1000个,占比为6.67%。
3.2 实验环境
以谷歌的Colab平台作为实验平台,Python语言进行编程,Tensorflow1.15.0为深度学习框架进行实验。
3.3 参数设置
实验中使用的ALBERT预训练模型均为tiny版本,隐藏层尺寸为768,层数为12,注意力头数为12个,LSTM网络隐藏层尺寸为128,Dropout设置为0.4,迭代次数为10次,优化方法为Nadam。
3.4 评价指标
多标签文本分类与单标签文本分类常用的评价指标有所不同,因为前者的文本标签种类往往是不止一个的,所以多标签文本分类常用Micro-Precision、Micro-Recall、Micro-F1、汉明损失(Hamming Loss)[29-30]进行模型性能的评价。其中,一般是Micro-Precision和Micro-Recall的数值越大越好,而Micro-F1是Micro-Precision和Micro-Recall的调和平均,也是越大越好,汉明损失越小越好。后续分别使用Micro-P、Micro-R代表Micro-Precision和Micro-Recall。Micro-Precision、Micro-Recall、Micro-F1以及汉明损失计算公式分别如下:
(14)
(15)
(16)
(17)
其中,TP表示正类被正确预测出来,FP表示负类被错误预测成正类,FN表示正类被错误预测成负类,|D|指的是样本的数量,L是标签的总数,xi表示标签,yi表示真实标签,XOR指异或运算。
3.5 实验结果与分析
实验1 对比实验。设置以下几个模型作为对比组:
1)WL模型。使用Word2vec进行文本的向量化后,输入到单向LSTM神经网络进行训练,最后进行分类。
2)AB模型。使用ALBERT进行文本的向量化后,输入到双向LSTM神经网络进行训练,最后进行分类。
3)ABAT模型。使用ALBERT进行文本的向量化后,输入到双向LSTM神经网络进行训练,再经过注意力机制层的处理,最后进行分类。
4)BoosTexter模型。文献[11]提出的模型。
5)ML-KNN模型。文献[13]提出的模型,K值设定为8。
6)CNN-RNN模型。文献[14]提出的模型。
7)文献[15]模型。利用GloVe获取词向量后,经过点积自注意力层处理,并输入BiGRU网络完成分类。
实验结果如表1所示,表中“+”表示该项取值越大越好,“-”表示该项取值越小越好。

表1 不同模型对比
由表1中数据可以看出,WL模型的分类效果一般,原因可能是,使用Word2vec模型进行向量化时,对于数据集大小十分敏感,其Micro-P只有0.9029,Micro-R只有0.7399,Micro-F1只有0.8133,Hamming Loss的值达到了0.0363。BoosTexter模型与ML-KNN模型两者性能表现接近,但是汉明损失仍处于较高值。而CNN-RNN模型由于在小训练集上,容易过拟合,导致实际表现一般。文献[15]提出的模型使用GloVe获取词向量,使得模型不能更好获取深层特征,汉明损失达到0.0101。AB模型使用了ALBERT预训练模型进行向量化,相对WL模型,3项指标都得到了提升,可以看到AB模型相对WL模型,在Micro-P上提升了4.19个百分点,在Micro-R上提升了5.49个百分点,在Micro-F1上提升了5个百分点。而ABAT模型相对于AB模型又增加了注意力机制,能够帮助模型更好地利用深层信息。经过对比可以发现,注意力机制的加入,对于提升模型的综合表现是很有帮助的。本文提出的ABAT模型在实验中达到了较好的性能,相对于WL模型,在Micro-P上提高了5.96个百分点,在Micro-R上提高了11.1个百分点,在Micro-F1上提高了9个百分点,并且Hamming Loss的值为同组最小值0.0023。
实验2 不同Dropout率的影响。为了使得网络参数最优,设计了一组实验,探究在不同Dropout率下会对网络的性能有什么样的影响,结果如图3所示。
从图3中可以看出,随着Dropout率的提升,Micro-P、Micro-R、Micro-F1等指标的值也会变大,表明模型性能得到了提升。在Dropout率取值为0.4的时候,模型性能表现为整组实验中的最优。此时Micro-P、Micro-R、Micro-F1的值也达到了最大。当Dropout率的取值继续增大时,模型性能开始下降。由此可知整个实验中,伴随着Dropout率的提升,模型性能指标表现出先增大后减小的趋势。当Dropout=0.4的时候,会使得本文模型整体性能表现最好。
实验3 标签分类验证。使用训练后的模型进行文本分类验证实验,结果如表2所示。从表中可以看出,模型可以有效地识别出文本对应的标签,无论样本内容是单标签还是多标签的均可被正确识别出来。

表2 模型验证
4 结束语
在后续的工作中,将针对如何结合深度学习网络,进一步提高模型的分类准确率,加快分类速度等方面展开研究。传统的机器学习方法在处理文本时,较大程度依赖人工进行特征提取,且在特征训练阶段,容易忽略文本的深层特征信息,使得模型分类效率不够高。深度学习网络能较好地完成文本特征信息的挖掘,结合深度学习网络,对已有的分类算法进行改进,是分类方法改进的方向。在相同数据集上的实验表明,本文提出的模型相对于对比模型达到了最好的性能,并且探究了Dropout率的设置对ABAT模型的性能影响。各项实验表明,ABAT模型能较好地完成多标签文本分类任务。
