改进Deeplab V3+网络在视觉SLAM三维地图构建应用
2022-10-15嵇启春段中兴
屈 航,嵇启春,段中兴
(西安建筑科技大学 信息与控制工程学院,西安710055)
E-mail:651092232@qq.com
1 引 言
环境地图辅助移动机器人完成定位、导航、路径规划等任务,利用视觉SLAM[1-3](Simultaneously Localization And Mapping)算法,估计移动机器人运动路径同时,实现对外部环境模型构建.随着移动机器人应用于更多场景,仅获得环境空间几何信息难以满足机器人完成更复杂任务,如人机交互、环境理解等.通过构造语义地图,实现机器人其所处的空间几何信息与周围物体语义信息相联系,提高机器人智能化水平,使机器人完成更高层次任务成为可能.将高层次语义信息包含进视觉SLAM中,实现语义地图构造方面,较早研究是Andreas等人[4],他们首次提出语义地图概念,首先利用室外机器人构建场景3D点云,再对场景进行解析.随后,Sunando等人[5]利用条件随机场,将视觉传感器拍摄图像中每个像素都赋予一个物体类别,实现稠密语义标注的3D场景重建.Salas-Moreno等人[6]提出SLAM++系统,利用已有的预先设定的物体对象数据库,对实际场景的3D物体识别提供对象约束,从而生成面向对象的场景描述.
近年来,深度学习算法研究取得巨大进展,被广泛应用于图像分类[7]、目标检测[8]、语义分割[9,10]等领域,结合基于深度学习的深度神经网络与SLAM成为语义地图构建新的研究方向[11-13].语义地图构建,重点在于对环境中目标物体的语义识别和对其位置的精确计算,利用基于卷积神经网络的学习方法,可实现对目标物体高精度语义识别与标注.本文在现有视觉SLAM系统基础上,融合Deeplab V3+[14]语义分割模型,实现三维稠密语义地图精确构建.对Deeplab V3+模型融合视觉SLAM难以满足语义地图构建实时性问题,改进Deeplab V3+网络模型,网络模型主干网络选用轻量级卷积网络MobileNetV3[15]实现特征提取,减少参数量,对空洞空间金字塔池化(Atrous Spatial Pyramid Pooling,ASPP)模块采用非对称卷积进一步减少卷积运算量.最后利用基于贝叶斯更新方法[16],将二维语义信息融合进三维地图,实现三维稠密语义地图构建.
2 语义地图构建框架
语义地图构建框架如图1所示,使用Kinect相机作为输入设备对室内环境进行移动拍摄,采用基于视觉SLAM算法对输入RGB-D图像进行实时三维地图构建,同时采用改进Deeplab V3+网络模型对RGB图像进行语义分割,得到语义标签,利用基于贝叶斯更新方法渐进式将语义标签与三维地图融合,实现二维语义信息到三维空间映射,最终完成三维稠密语义地图构建.本文视觉SLAM采用ElasticFusion[17]系统,ElasticFusion联合深度信息和彩色信息计算相机运动轨迹,使用面元(Surfel)模型表示三维场景,通过随机蕨方法进行全局闭环检测,在闭环产生的情况下通过变形图的方法对场景进行更新,实现高精度三维稠密地图构建.
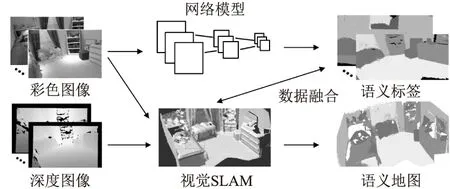
图1 语义地图构建框架Fig.1 Framework of the semantic mapping
3 图像语义分割
3.1 DeeplabV3+语义分割模型
自2015年全卷积神经网络[18](FCN)的提出,语义分割技术在精确度和实时性上得到快速发展.对比当前主流语义分割网络模型,本文采用基于Deeplab V3+网络模型实现语义信息获取.Deeplab V3+是谷歌于2018年开发的一种用于语义分割典型网络框架.网络模型使用编码-解码器结构,结构如图2所示.针对DeeplabV3池化和带步长卷积会造成一些物体边界细节信息的丢失问题,Deeplab V3+在V3模型基础上进行改进,将DeeplabV3作为网络的编码器,并在此基础上增加了解码器模块用于恢复目标边界细节.编码器由骨干网络Resnet101和ASPP模块组成,Resnet101提取图像特征生成高级语义特征图,ASPP模块利用Resnet101得到的高级语义特征图采用不同空洞率进行多尺度采样,生成多尺度的特征图,再通过1 × 1卷积进行通道压缩.解码器部分对编码器的输出进行上采样,并与前半层的输出特征图融合,最终实现图像语义分割.
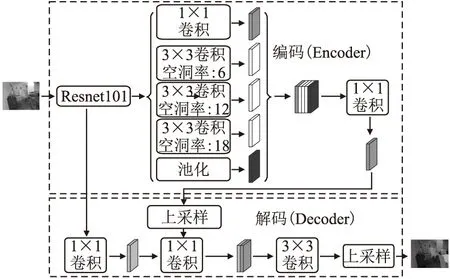
图2 DeeplabV3+模型图Fig.2 Deeplab V3+ model diagram
3.2 主干网络改进
对于语义分割,Deeplab V3+满足高精度输出结果要求,将算法运用于视觉SLAM系统,相机追踪与建图对模型分割速率提出更高要求,在Deeplab V3+基础上,采用轻量级卷积网络MobileNetV3代替Resnet101实现特征提取,减少参数量,加快算法分割速率.MobileNetV3是Google在2019年提出的新型轻量化卷积网络模型,在MobileNetV2的具有线性瓶颈的逆残差结构基数上进行改进,典型卷积块结构如图3所示.

图3 MobileNetV3卷积块结构Fig.3 MobileNetV3 convolutional block architecture
MobileNetV3在V2逆残差结构上引入注意力机制模块(Squeeze and Excitation,SE),使用SE可以更好地调整每个通道的权重,通过训练过程在特征图上自行分配权重,使网络从全局信息出发选择性地放大有价值的特征通道,并且抑制无用的特征通道;同时使用激活函数H-Swish对Relu函数进行替换,函数表达式如公式(1)所示:
(1)
H-Swish函数是Swish激活函数的改进型,能够减少计算量同时保持与使用Swish激活函数相同的精度,实现精度和运算速度上的兼容.MobileNetV3同样使用深度可分离卷积构建深度神经网络,该网络可以在保持相似准确度的情况下有效减少网络中的参数量与计算量.深度可分离卷积的计算量与标准卷积计算量的比值如公式(2)所示:
(2)
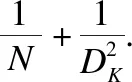
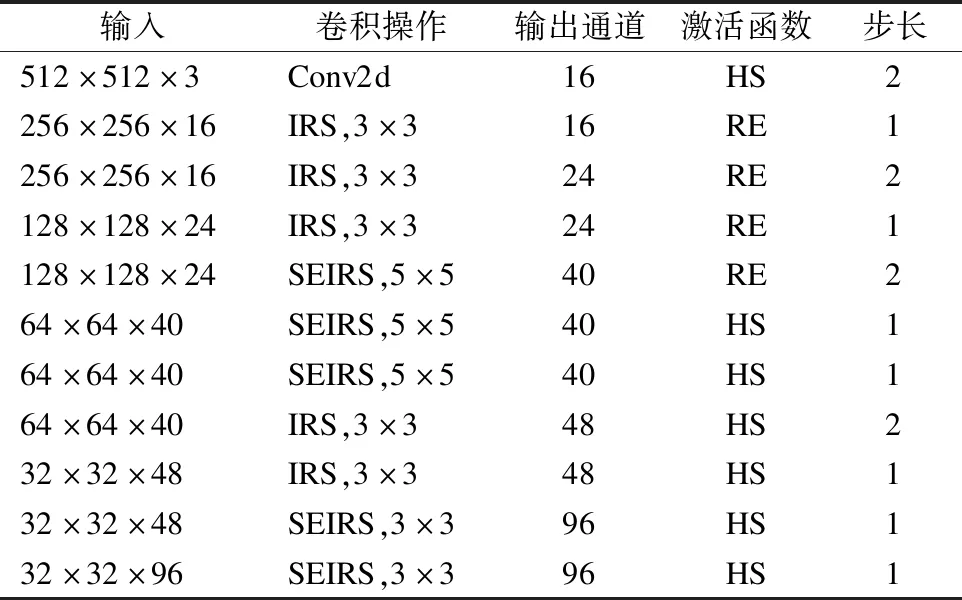
表1 MobileNetV3 网络模型结构
3.3 ASPP模块改进
ASPP由多个不同空洞率卷积核以并联方式组成,空洞率大,卷积核尺度大,有利于算法分割大目标,空洞率小,卷积核尺度小,利于算法分割小目标,空洞卷积算法定义如式(3)所示:
(3)
其中,x为输入特征图,y为输出特征图,w表示卷积核,k表示卷积核尺寸,表示大小为k×k的卷积核;r代表扩展率,描述卷积核处理数据时采样的步幅,调整扩展率可自适应的调整感受野大小.
ASPP利用不同卷积核扩张率实现多尺度语义信息提取,进而提高分割精确度.采用3×1和1×3卷积对3×3空洞卷积进行分解,对比常规卷积,利用非对称卷积可减少33%计算量.改进后ASPP模型如图4所示.
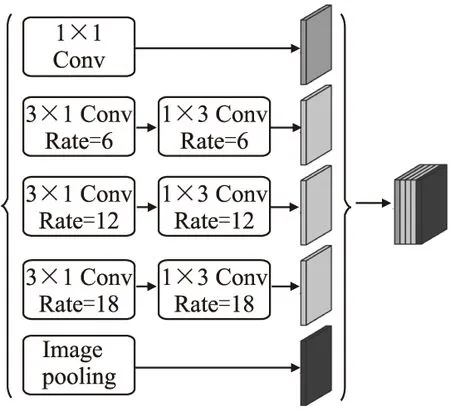
图4 改进后ASPP模型Fig. 4 Improved ASPP model
4 语义标签增量融合
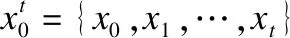
(4)
(5)
再次运用贝叶斯公式得到:
(6)
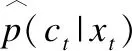
(7)
5 实验与分析
5.1 图像分割
实验首先采用Pascal VOC2012数据集进行语义分割测试,为验证改进后图像语义分割模型实时性与精确度,使用分割速度与平均交并比(mIoU)作为评价指标,mIoU是真实值、预测值集合的交集和并集之比,是目前图像语义分割领域最常用的评价指标.mIoU表达式如式(8)所示,其中,其中,k表示类别数量,TP表示预测为真正数量,FN表示预测为假负数量,FP表示预测为假正数量.
(8)
模型训练平台基于Ubuntu16.04操作系统,处理器和显卡分别为Inter Core i7-9750H和NVIDIA GeForce GTX1660TI,8G内存.采用基于TensorFlow 深度学习框架,设置批处理大小为8,初始学习率为0.001,权重衰减率设为0.0005,优化器为随机梯度下降,动量为0.9.损失函数采用交叉熵损失,如公式(9)所示:
(9)
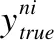
表2为Deeplab V3+与改进后模型性能测试对比,部分分割可视化结果如图5所示.
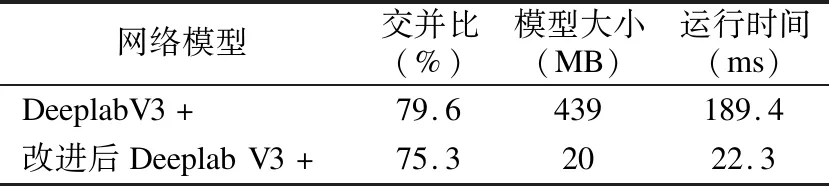
表2 模型分割性能对比

图5 基于VOC2012分割结果Fig. 5 Based on VOC2012 segmentation results
由结果可知,改进后的Deeplab V3+模型在大致轮廓的分割效果与原模型相同,特别是在图像中只有单一目标或目标轮廓明显情况下.对比原模型,改进后模型对于目标细节分割有细微差距,如图5第1幅图马尾以及第2幅图飞机尾翼部分.主干网络采用轻量级卷积网络MobileNetV3以及对ASPP卷积操作更改后,改进后模型所占内存大小和单张图片处理速度上提升效果明显,模型大小减少约95%,单张图片运行时间减少约88%,模型的综合性能达到最优,满足图像分割实时性要求.
5.2 三维稠密语义地图构建
本文采用NYUv2数据集进行三维稠密语义地图构建实验.NYUv2数据集由Microsoft Kinect的RGB和Depth摄像机记录的各种室内场景的视频序列组成,包括原始RGB图像,深度图像以及相机加速度数据,数据集包含多种不同场景,如Bedroom,Bathroom、Diningroom等,RGB相机和深度相机的采样率介于20~30fps之间.进行三维地图构建前,首先对NYUv2数据进行预处理,包括深度图像与RGB图像对齐,原始深度图像转换.
利用改进后Deeplab V3+在NYUv2数据集上重新训练网络,实现在NYUv2数据集下语义分割.图6所示为NYUv2数据集下语义分割结果,由结果可知,针对室内场景,本文使用的语义分割算法仍然表现良好.将改进后Deeplab V3+分割模型结合ElasticFusion系统,实现语义地图构建,结果如图7所示.

图6 NYUv2下语义分割结果Fig. 6 Semantic segmentation results under NYUv2

图7 不同场景下三维地图构建Fig.7 3D map construction under different scenes
表3为NYUv2数据集下,不同场景下三维稠密语义地图构建程序运行时间,由表得,使用ElasticFusion进行三维稠密地图构建,算法平均以29帧/秒速度运行,结合语义分割模型后,语义地图构建平均以22帧/s速度进行,结果表明,利用改进后的轻量级Deeplab V3+语义分割模型,满足实时三维稠密语义地图构建.将本文语义地图构建方法与文献[19]进行对比,结果如表4所示,得出在平均像素精度相似情况下,本文算法在构图实时性上有明显提升.
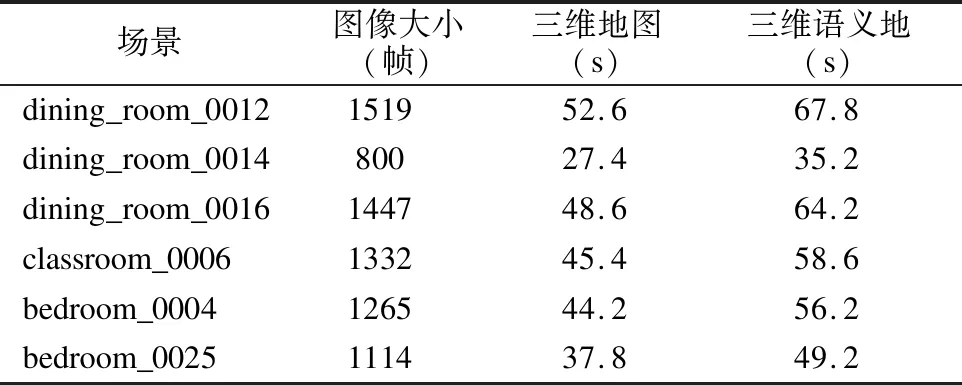
表3 不同场景下三维地图构建时间Table 3 3D map construction time under different scenes

表4 语义地图构建性能对比
6 结束语
本文将基于卷积神经网络的Deeplab V3+语义分割算法应用于视觉SLAM,实现三维稠密语义地图构建.对Deeplab V3+可实现高精度分割,但模型运算量大,影响三维稠密语义地图实时构造问题,采用轻量级卷积网络MobileNetV3代替ResNet101进行特征提取,减少计算参数量,加快分割速度,同时对ASPP模块中卷积层采用非对称卷积进行替换,进一步减少运算量,实现分割速率提升.实验表明,改进后的的Deeplab V3+应用于视觉SLAM可满足实时高精度三维稠密语义地图构建.在后续的研究中,利用神经网络优化视觉SLAM是需进一步解决的问题.
