基于启发式候选区域推荐的目标孪生跟踪
2022-10-15覃瑞国张灿龙李志欣韦沛佚
覃瑞国,张灿龙,2,黄 玲,2,李志欣,2,韦沛佚
1(广西师范大学 广西多源信息挖掘与安全重点实验室,广西 桂林 541004)
2(广西区域多源信息集成与智能处理协同创新中心,广西 桂林 541004)
E-mail:zcltyp@163.com
1 引 言
在计算机视觉领域中视频目标跟踪是一个重要的研究方向,能被广泛应用于视频监控、自动驾驶、军事指导等方面.目标跟踪旨在给出目标在每一帧图像中的所处位置和状态.目标跟踪面临诸多挑战,如光照变化、目标遮挡、尺度变化、快速运动和形变等.
目标跟踪方法主要有两大类:非深度学习和深度学习,前者主要使用手工提取特征,典型的有基于相关滤波的单模态跟踪方法[1,2],和基于压缩感知[3]和空间直方图[4]的多模态跟踪方法,此外融合深度信息[5]的跟踪方法也是其中的亮点.后者进行提取目标特征方法主要通过特征学习来完成目标跟踪.MDNet[6]是最早的深度目标跟踪模型[7],以此网络为基础,发展了很多网络模型.受孪生网络[8]启发,Bertinetto等人提出了SiamFC[9]模型,该模型主要两个分支构成,分别为检测分支和模版分支,两个分支均用同一个网络来提取特征的.模版分支用于提取第一帧或者前一帧目标图片的特征,检测分支用于提取当前帧图的特征.最后,将模板分支特征与检测分支特征进行相关运算,相关度最高区即为目标.此后Li[10]等人在SiamFC的基础上提出了一种基于候选区域推荐网络的孪生跟踪器SiamRPN,该模型主要是在检测分支添加了一个候选区域推荐网络,以此选出图片中的候选目标,其推荐网络所预设的锚点数量和尺寸种类固定不变,并在特征图上的每个位置进行滑动.这种做法会导致以下问题:1)因为不同目标需要制定不同尺寸和比例的锚点,而固定不变的锚点框尺寸和比例会无法适应这种需求,从而会导致模型的精度和跟踪速度严重地下降;2)对于候选区域有一个很高的召回率,这就产生了大量的锚点,其中有大量的锚点是包含了非目标区域,在计算这些锚点的时候,就会占用大量的计算资源.
针对以上问题,受Guided Anchor[11]的启发,本文提出了一种基于启发式候选区域推荐的目标孪生跟踪模型.该模型仍由模版分支和检测分支组成,在检测分支中,为了判定目标可能出现的位置本文通过学习一个概率图,以此来确定锚点的位置,并预测锚点可能的尺寸,这样使得产生的候选区域能够更准确地定位到图像中的目标物体,自动适应目标的大小,并且大大降低了推荐区域的数量.
2 基于启发式候选区域推荐生成网络
2.1 网络结构
本文所提出的基于SiamFC的引导锚点生成网络如图1所示.该模型网络主要分为两个分支,第1个为模板分支,另一个为检测分支.
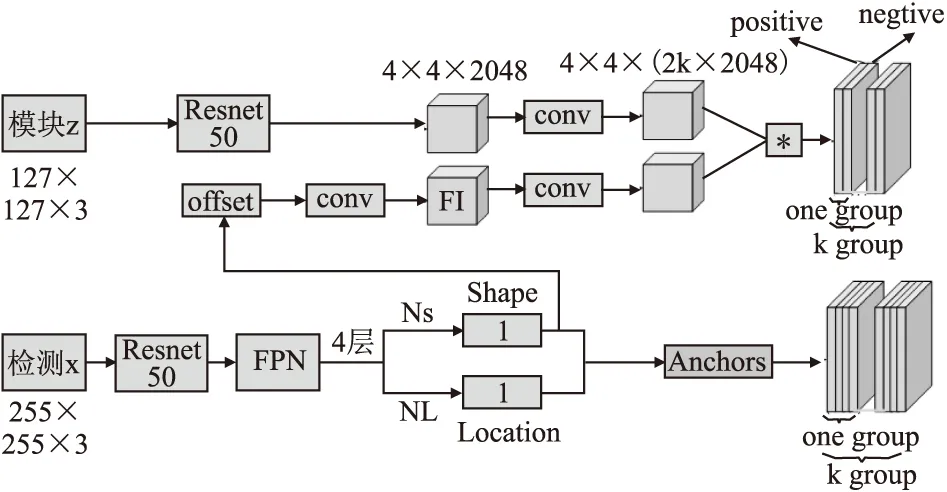
图1 模型结构图Fig.1 Model structure
模板分支主要处理视频的第一帧或者前一帧的目标图片信息,该分支的输入为一张大小为127×127、通道数为3的图片,为了提取该图片中的目标特征本文使用ResNet50[12]网络,最后输出特征图为4×4×2048.
检测分支的输入是一张大小为255×255,通道数为3的图片,该分支主要用于提取所要检测图片的特征信息.检测分支主干网络输入一张255×255×3的图片之后,将其送入ResNet+FPN[13]网络进行提取特征,之后输出4张特征图.每一张都要学习其锚点的位置与大小.以ResNet+FPN第1层输出的特征图为例子,设其为p(i,j|FI),p(i,j|FI)里的i,j分别对应FI的坐标((i+1/2)s,(j+1/2)s),((i+1/2)s,(j+1/2)s)1×1其中s为锚点之间的距离.在模型中,FI通过一个的卷积NL得到目标位置分数的映射,为了得到对应的概率值,sigmoid[14]函数对其进行转化.根据这个概率图,得到图片中目标物体可能出现位置的概率分布.
在获得特征图中物体位置的概率分布图之后,再通过一个卷积网络NS学习出锚点的形状大小.传统的边界盒回归的方法和本文使用的学习锚点形状的方法有很大的不同,因为本文使用的学习锚点形状的方法在不改变锚点的位置同时,也不会使锚点对应的特征与锚点之间的错位.为了获得锚点的形状,用以下公式转换网络NL学习到的参数dw、dh.
w=σ·s·edwh=σ·s·edh
(1)
我们可以通过学习到的参数dw、dh转化为锚点的长和宽.公式中的σ为经验尺度因子(实验中σ=8),s为Ns网络的步长.通过上述的非线性变换,可以将输出空间[0,1000]近似投影到[-1,1],这样使得学习锚点变得更加容易且稳定.Ns网络是由一个1×1的卷积核构成,输出两个值dw、dh.
在传统的候选区域网络[15]中,整个特征图上所有的锚点都是一致的,也就是说每个锚点的形状和比例都是共享的,但是在这个模型中,锚点在不同的位置是具有不同的形状.因此我们使用了一个3×3大小的可变形卷积网络NT处理这个问题.它可以根据锚点的形状在每个单独的位置改变特征,公式定义如下:
f′=NT(fi)f′=NT(fi,wi,hi)
(2)
其中,fi为特征在第i个位置,(wi,hi)为锚对应的形状.因此在NS网络确定锚点形状之后,我们从NS的输出中预测一个偏移,然后根据这个偏移对原始的特征图进行可变形卷积,得到Fi.
之后Fi经过一个大小为3×3的卷积,最后得到大小为12×12×2的特征图.模板分支此时也经过一个3×3的卷积,输出大小为2×2(2k×2048)的特征图.之后,模板分支与检测分支输出的特征图进行互相关数据运算,公式如下:
(3)
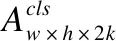
2.2 损失函数
模型的损失函数有两部分网络构成,一部分为孪生主干网络中的检测分支,另一部分为候选区域推荐网络.
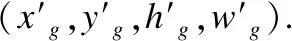
2.3 生成锚点
确定锚点最佳形状主要由两个步骤,首先把真实框和锚点进行匹配,然后再学习锚点形状,即与真实框匹配度最高.选定锚点的模型在训练之前为真实边界框分配了一个候选的锚点,该锚点产生的IOU最大.因为锚点的长和宽是一个变量,因此我们要采取另一种策略.给定一个变量锚点awh={(x0,y0,hg,wg)|w>0,h>0},它与实际边界框gt=(xg,yg,hg,wg)之间的IOU为:
(4)
上述公式中,vIOU、w和h都是变量.因为对于vIOU解析相对于复杂,难以在端对端的训练实现.于是我们采取其他方法进行模拟.为了去模拟锚点的所有值,本文在给定的anchor(x0,y0)中,对它的长和宽的一些公共值进行抽样.实验中采用了9对不同的长宽比和大小缩放比例的锚点.再用实际边缘框计算这些锚点的IOU,采用最大的近似值vIOU,损失函数采用的是Bounded iou loss[17],损失函数定义为:
(5)
其中,L1为smoothL1损失,(w,h)表示锚点的大小,(wg,hg)表示锚点的大小.
本模型中的候选区域推荐网络部分,使用的损失函数和SiamRPN一致,均是采用Faster R-CNN[15]中的损失函数.分类损失使用的是交叉熵损失函数,回归损失采用的是归一化坐标的smoothL1损失函数.将Ax,Ay,Aw,Ah定义为锚点中心和锚点框的长宽.定义Tx,Ty,Tw,Th为目标真实位置中心和其长宽,则正则化后的距离为:
(6)
定义候选区域推荐网络的分类损失为Lcls,回归损失为Lreg损失函数定义如下:
(7)
因此模型的损失为:
loss=λ1Lloc+λ2Lshape+Lloc+Lreg
(8)
其中λ1=1,λ2=0.1.Lloc和Lshape为Guided Anchor中的损失,Lcls和Lreg分别为分类损失、回归损失.
3 实 验
本次实验在几个常用的数据集上进行,并使用几个典型的目标跟踪算法与本文模型进行性能对比.
3.1 数据集
本实验采用6个数据集,其中,训练集为4个,分别为COCO[18]数据集,ILSVRC2017_DET数据集YOUTUBEBB数据集以及ILSVRC2015_VID数据集,测试集有两个,分别为OTB2015[19]数据集和VOT2016[20]数据集.COCO数据集是由微软团队制作的,其数据集中的数据图片主要从日常场景中拍摄,数据集中图像包含91类目标,328000影像以及2500000个标签.ILSVRC2015_VID数据集有30个类别目标,并且包含3826个片段用于训练,555个片段用于实验验证,937个片段用于对实验的测试,每一个片段包含56-458帧图像.
3.2 训 练
本文实验实验环境为Intel Xeon(R)CPU E5-2620 v4,显卡GTX-1080TI,64G RAM,Pytorch版本为0.4.1,python版本为3.7.本文模型的模板分支是采用ResNet50作为主干网络,检测分支是采用ResNet50+FPN作为主干网络.在实验中,我们检测分支的输入图片改为255×255大小,将σ1=0.2,σ2=0.6.为了平衡位置和形状分支,将λ1=1,λ2=0.1.实验中,实验批次设置为50批次,批次大小为28,学习率从10-2~10-6降低.
3.3 锚点生成比较
SiamRPN使用预选定义的锚点框进行初始化,之后在候选区域网络中,生成对应的锚点组.很容易的发现,在生成区域锚点时,会产生众多无效的锚点,且部分非目标锚点也会被加入计算.本文提出的网络模型,很巧妙地避过了这个缺点.本文模型在进行网络提取特征之后,经过GuidedRPN模块学习锚点的位置,无须使用预定义的锚点框,生成锚点之后,不用再和SiamRPN一样使用其他的策略来选取锚点.
经过实验,图2左边为SiamRPN所生成的锚点,图2右边为本文模型生成的锚点.可以很明显地看出,生成的锚点数量,要少于本文模型生成的数量,并且锚点数量减少的同时,锚点地质量也明显提高.

图2 候选区域对比图Fig.2 Comparison of region proposal
3.4 在OTB2015数据集上实验
OTB2015数据集中含有100个视频序列.在该数据集上采用两种一次性通过的评价指标,第1种是计算实际目标和跟踪结果之间的重叠率,称为success plots of OPE,定义重叠率为OS.当某个指定的阈值低于某一帧图像的重叠率时,那么该帧图像被记为跟踪成功,反之为失败,跟踪成功的帧数的总和占所有帧的百分比,记为成功率.另一种指标为precision plots of OPE,其首先计算跟踪结果和目标真实框的目标中心距离,然后设定一个阈值,当某一帧计算出来的距离小于该阈值,那么该帧跟踪成功.最后计算所有跟踪成功的帧数占所有帧数的百分比.
本文并与SiamRPN,PTAV[21],CREST[22],SRDCF[23],SINT[24]目标跟踪模型进行比较.经过实验评估,得到如表1所示的结果.本文模型在OTB2015数据集上评估,成功率达到了0.64,精确值达到了0.857,性能均超过这5个跟踪模型.

表1 在OTB2015数据集上的评估结果Table 1 Experimental results on OTB2015
3.5 在VOT2016数据集上实验
VOT2016包含60个视频.我们采用3个测量指标来评估本次实验,分别为EAO(平均重叠期望),Accuracy(精确度),Robustness(鲁棒性).平均重叠期望是用于衡量跟踪过程中模型的鲁棒性与准确性的指标.精确度表示跟踪器跟踪目标的准确度,数值越大,则跟踪器准确度越高,性能越好.鲁棒性是评价一个跟踪器的稳定性,其数值越小稳定性越强.与当前主要的目标跟踪模型进行比较,实验结果如表2所示,其中,EAO指平均重叠期望,A指平均精确度,R指平均鲁棒性.SiamFC-R指在SiamFC中的主干网络采用的是ResNet[12].不难看出,本文模型与其他跟踪器比较,其平均重叠期望,精确度以及鲁棒性均达到了一个不错的效果.
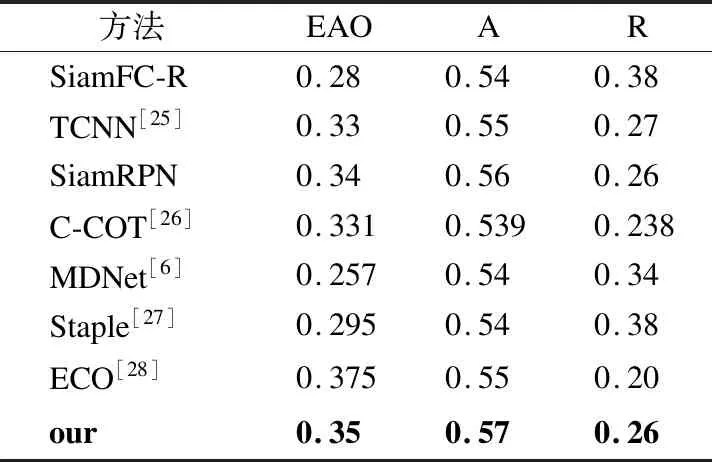
表2 在VOT2016数据集上的评估结果Table 2 Experimental results on VOT2016
图3展示了本文方法与SiamRPN在VOT数据集上部分跟踪结果的截图,其中白色矩形框为本文模型的跟踪结果,黑色矩形框为SiamRPN跟踪结果.可以看出本文方法目标在快速移动、光照阴暗和不同摄像头之间的跟踪性能,都表现极佳,且整体定位精度要比SiamRPN好.

图3 本文方法与SiamRPN在VOT2016上的跟踪结果Fig.3 Tracking results of our method and SiamRPN on VOT2016
4 结 论
本文借鉴了GuidedRPN,并将其融入孪生网络当中,改变了孪生网络中生成锚点的方法.在学习锚点的时候,不再需要预定义锚点框,使得学习锚点的过程变得灵活多变.本文的跟踪模型,检测分支通过学习一个概率图,来确定图像中目标可能出现的位置,之后再预测锚点的形状,得到锚点之后,将特征图与锚点映射,最后再将特征图与模板分支进行互相关操作,通过阈值对比,确定该锚点的目标是正样本或负样本.本文模型在提升了锚点的质量的同时,跟踪性能也能够提高,且鲁棒性与SiamRPN保持稳定.本文下一步工作,计划在目标模板更新上进行改进.
