融合评论文本和评分矩阵的电影推荐算法研究
2022-10-15张蕗怡余敦辉
张蕗怡,余敦辉,2
1(湖北大学 计算机与信息工程学院,武汉 430062)
2(湖北省教育信息化工程技术中心,武汉 430062)
E-mail:201822111920042@stu.hubu.edu.cn
1 引 言
随着互联网的蓬勃发展,面对爆炸式增长的数据规模,用户如果仅依靠简单的手动搜索,将难以挑选到自己感兴趣的物品.为提升用户的消费体验,推荐系统[1,2]应运而生.由于推荐系统能够精准定位用户兴趣,实现信息产生者和信息消费者的完美匹配,所以在网络服务中的实际应用也越来越多,如网易云音乐根据用户播放和收藏为用户生成“每日推荐”列表;豆瓣根据用户打分和观看过的电影为其推荐可能感兴趣的电影等等.
在电影评论领域,有众多高质量评论网站,如IMDB,ROTTEN TOMATOES等.但是大部分电影推荐系统研究仅仅分析用户和电影的历史交互信息,没有充分发挥这些网站中优秀评论文本的内在价值.因此本文将利用电影的高质量评论文本,通过基于自注意力机制的双向门控循环单元神经网络提取评论文本中的特征,构建电影评论特征矩阵.同时,为在电影评分数据中获得用户的兴趣偏好,使用隐语义模型对用户评分矩阵进行分解,得到用户潜在兴趣矩阵和电影潜在特征矩阵.最后通过改进的DeepFM融合电影评论特征矩阵和电影潜在特征矩阵得到最终电影综合得分并形成推荐列表,以达到推荐的目的.
2 相关工作
当前,电影推荐受到了众多学者和研究人员的关注.协同过滤算法首先被应用于电影推荐之中.文献[3]将深度潜在因子模型(DLFM,Deep Latent Factor Model)用于基于协作过滤的算法推荐系统中.文献[4]根据电影推荐中的各种隐式反馈,并将这些反馈纳入协作过滤.但是,基于协同过滤的算法具有冷启动问题,且对用户的评分数据依赖性较大.为解决以上问题,基于内容的推荐算法逐渐被采用.文献[5]采用基于内容的推荐方法,使用目标编程模型来预测缺少的电影评分.文献[6]提出一种新颖的基于内容的推荐方法,即在向用户推荐商品时使用多属性网络来计算相关性,从而有效地反映多个属性.文献[7]则通过考虑用户偏好来提取隐藏在内容特征中的关系的优化模型,然后将学习到的特征关系矩阵应用于推荐,并解决冷启动问题.此类算法在一定程度上缓解了冷启动问题,但受限于新用户-新产品的限制,且具有新颖性不强的问题.
随着对深度学习的深入研究,该技术也广泛运用于电影推荐,并取得成功.文献[8]提出卷积矩阵分解模型,解决用户对项目评分数据的稀疏性问题,并额外利用了文本数据提高了推荐的准确性.文献[9]利用深度学习来学习用户和电影特征信息,以形成高维潜在空间的用户特征和电影特征的隐向量.文献[10]则通过神经网络对“灰羊用户”,即具有独特偏好和品味的用户推荐电影.基于深度学习方法进行电影推荐大大提升了推荐的精准度和效率,但其推荐结果缺乏合理的解释性的问题也深受诟病.
3 融合评论文本与评分矩阵的电影推荐算法
本文提出了一种融合评论文本与评分矩阵的电影推荐算法(CRRM,Combining Review and Rating Matrix),算法整体结构如图1所示,具体流程如下:
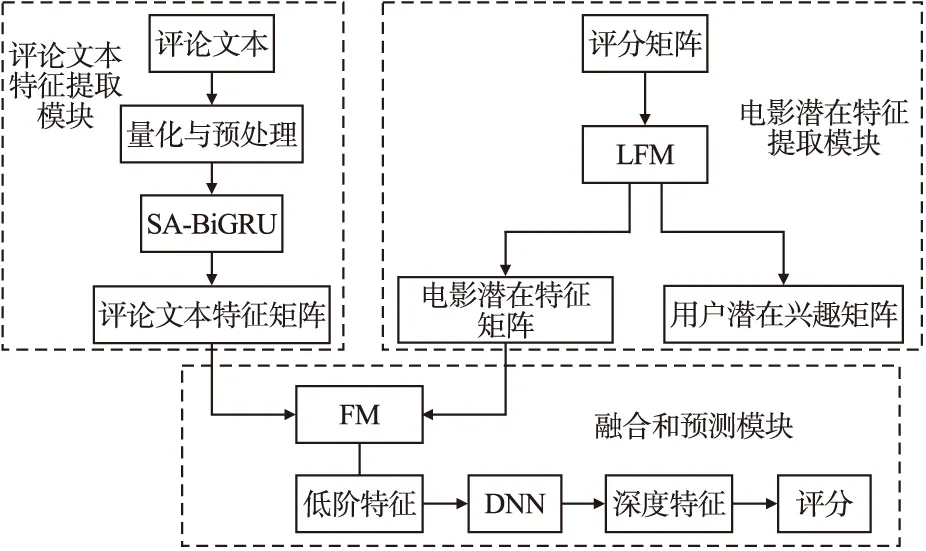
图1 CRRM算法结构图Fig.1 CRRM algorithm structure diagram
1)提出基于自注意力机制的双向门控循环单元神经网络(SA-BiGRU,Self-Attention-Bidirectional Gated Recurrent Unit)模型提取电影评论中的特征,构建电影评论特征矩阵.
2)通过隐语义模型(LFM,Latent Factor Model)分解电影评分矩阵,得到用户潜在兴趣矩阵和电影潜在特征矩阵.
3)通过改进的DeepFM融合电影评论特征矩阵与电影潜在特征矩阵并计算最终的电影得分.
此算法使SA-BiGRU模型和LFM充分发挥了各自的优势,克服了单一模型的缺陷,提高了推荐结果的可解释性和多样性.同时充分利用电影评论文本和电影评分数据,从而提升最终的推荐结果.
算法中所用重要符号及其说明如表1所示.

表1 符号对照说明表Table 1 Symbol contrast explanatory table
3.1 基于SA-BiGRU的电影评论特征提取
很多电影拥有大量的评分数据,但评分数据仅能反映用户对电影的整体满意度,而缺乏电影具体特征和用户偏好等信息.所以需要引入高质量评论文本,更好地获取用户对电影的个性化偏好,实现面对用户的精准化个性推荐.
文献[11]使用长短期记忆神经网络LSTM对评论文本数据进行建模,得到了较为满意的结果.而门控循环单元GRU作为LSTM的一个变体,在保持 LSTM 效果的同时,计算简便,结构简单,易于收敛,且因为在序列处理上具有出色表现而被广泛应用于自然语言处理任务中.因此本文结合双向门控循环单元与自注意力机制提出SA-BiGRU模型通过电影评论文本提取特征[12].
SA-BiGRU模型一共包括5层网络结构,如图2所示.
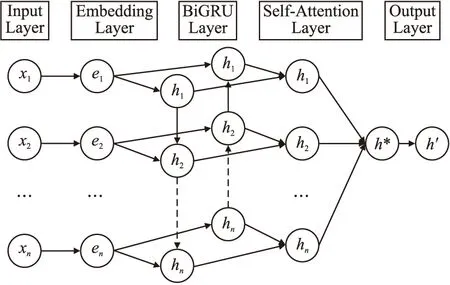
图2 SA-BiGRU网络结构图Fig.2 SA-BiGRU network structure diagram
1)输入层:将量化后的电影评论文本输入到模型中.
2)嵌入层:产生每个单词在低维空间上的映射.
3)BiGRU层:提取词汇特征.
4)Self-Attention层:将词汇特征与权重向量相乘的结果进行迭代,产生句子特征.
5)输出层:输出求得电影评论特征矩阵.
3.1.1 电影评论文本量化
为将电影评论文本转换为神经网络可以处理的数据结构,首先将评论文本转换为单词序列X={x1,x2,…,xT},并对每个单词xi进行独热编码,即将每个单词转化为实数向量.向量的每个元素代表词库中的一个单词,只有单词xi对应的元素值为1,其余均为0.为满足神经网络输入必须行列相同的要求,根据所有文本的情况设定一个合适的统一列数,列数不够的矩阵用0向量填充.通过以上转换,每个评论都可以转换成一个等行列数的单词序列矩阵X.
3.1.2 评论文本输入与预处理
将评论文本量化后得到的单词序列X作为SA-BiGRU模型的输入.这里的单词序列X将严格按照评论文本的单词顺序以保持时序关系,为后面的处理做了准备.
由于用户对电影的评论原始文本的数据集通常比较大,其单词表的数量和单词xi的维度可能有几百万维甚至更多.因此,每个单词xi需经过SA-BiGRU模型的嵌入层降维为低维实数向量ei.转化过程如下:
ei=Wwordxi
(1)
其中词向量矩阵为Wword∈dword|V|,dword是评论文本本身词向量的维度,|V|是单词xi的维度,Wword则是网络中学习到的参数.转换后的向量维度得到了大幅度的缩减,大概为几百维,减少了神经网络中的参数规模,提高了网络的学习效率.
3.1.3 电影评论特征矩阵生成
本文通过BiGRU层对经过量化和降维之后的评论文本特征进行提取,其中包含了更新门和重置门两个门限.
更新门是决定上一时刻的状态信息传递到当前时刻的程度.求得更新门控信号zt为:
zt=σ(W(z)xt+U(z)ht-1)
(2)
重置门则是控制上一时刻的状态信息被遗忘的程度.求得重置门控信号rt为:
rt=σ(W(r)xt+U(r)ht-1)
(3)
其中xt表示当前时刻输入的单词向量,ht-1表示前一时刻的单词信息,W表示输入的单词权重,U表示循环输入的单词权重.
得到门控信号zt和rt之后,再通过重置门来得到遗忘后的状态ht-1⊗rt,其中⊗表示哈达马积对应元素相乘.然后,将遗忘后的状态ht-1⊗rt与当前时刻的单词向量输入xt相加.最后通过非线性函数tanh激活得到当前时刻的候选激活状态为:
(4)
最后,通过更新门对当前节点的输入选择记忆.求得当前时刻的激活状态为:
(5)
由于评论文本具有时序关系,因此当前时刻的前向信息和后向信息都非常重要.本文采用了BiGRU模型以增强网络对时序关系的获取,在原有的正向GRU网络层的基础上增加一层反向的GRU层,以解决单向GRU不能捕获后向信息的问题.此时当前时刻的激活状态可以表示成:
(6)
为解决在电影评论文本的单词序列中不同单词对整个句子产生不同的影响的问题,本文引入了注意力机制.而自注意力机制Self-Attention[13]作为注意力机制的一个变体,更容易捕获句子中长距离的相互依赖的特征,在计算过程中将句子中任意两个单词通过一个计算步骤直接联系起来,所以远距离依赖特征的距离被极大缩短,更加有效地利用这些特征.因此在BiGRU层后添加一层Self-Attention层,对权重高的单词给予更多的关注,而不重要的单词则消耗更少的资源,以提高网络的效率,同时得到更有价值的特征表示.
将BiGRU层输出的向量集合ht表示为Ht={ht0,ht1,…,htN}.Self-Attention层通过线性变换得到3组向量序列Q、K、V:
Q=WQHt∈dq×N
K=WKHt∈dk×N
V=WVHt∈dv×N
(7)
其中Q、K、V分别为查询向量序列,键向量序列和值向量序列,WQ、WK、WV分别为学习到的查询向量序列,键向量序列和值向量序列的参数矩阵,dq、dk、dv分别为矩阵WQ、WK、WV的维度.
最终提取的语句特征矩阵h*如下所示:
(8)
a=soft max(s(kj,qi))vj
(9)
其中i,j∈[1,N]为输出和输入向量序列的位置,连接权重aij由注意力机制动态生成.
最后通过一个全连接的输出层.基于自注意力机制的门控循环单元网络输入用户对电影的评论文本,提取到特征维度为k的电影评论特征矩阵为:
h′=SA-BiGRU(ω,Review)
(10)
h′∈k×n的列表示评论文本,行表示评论特征,ω为该网络中所有权重和偏置参数,Review为原始评论文本.
对于同一电影而言会存在多条高质量评论文本,每一条评论文本经过以上过程后会生成不同的潜在特征h′.为全面得出从评论文本中提取到的电影总特征矩阵,对n个特征h′求均值得到电影的评论总特征矩阵为:
(11)
3.2 基于LFM的电影潜在特征矩阵生成
隐语义模型(LFM)作为一种有效的特征映射方法,可以精确描述用户兴趣偏好和物品本身特性,因此在推荐系统中得到了广泛应用.本文通过LFM模型分解电影的评分矩阵,得到用户潜在兴趣矩阵和电影潜在特征矩阵.具体流程如图3所示.
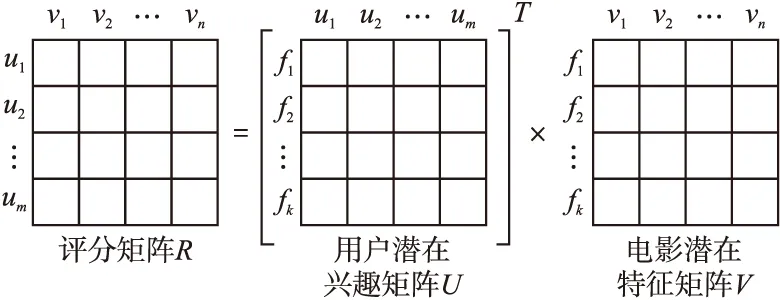
图3 LFM框架Fig.3 Latent factor model framework
假设有m个用户,用户集合为U={u1,u2,…,um},对n部电影,电影集合为V={v1,v2,…,vn}进行评分,评分矩阵R代表用户对电影的评分矩阵.而LFM的目标是通过评分矩阵R找到两个矩阵U和V,使两个矩阵的乘积近似等于评分矩阵R.
V≈UR
(12)
其中U和V分别为用户潜在兴趣矩阵和电影潜在特征矩阵.
为获得更为精确的电影潜在特征矩阵,接下来通过最小化损失函数迭代获得用户潜在兴趣矩阵和电影潜在特征矩阵.损失函数的表达式如下所示:
(13)

3.3 电影潜在特征与评论特征融合
本文改进DeepFM[14]中设计的融合层来融合电影评论特征矩阵与电影潜在特征矩阵,并求得电影综合评分,形成最终的推荐列表.具体步骤如下:
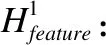
(14)
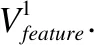
(15)
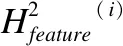
(16)
其中W表示权重矩阵,bh表示电影评论偏差,bs表示电影评分偏差,μ表示全局偏差,⊗表示特征向量相对应的元素相乘.
3.4 算法执行过程
算法. CRRM(Combining Review and Rating Matrix)算法
输入:电影评论文本的单词序列X={x1,x2,…,xT}

1.for each单词序列X:
2. for each单词xi:
3. 降维ei=Wwordxi
4. BiGRU层得评论词汇特征ht
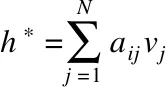
6. 全连接输出层得到电影评论特征矩阵h′=SA-BiGRU(W,Review)
8.LFM模型分解电影评分矩阵得到电影潜在特征矩阵V≈UR
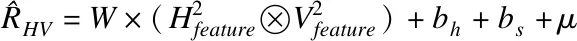
10.return 电影推荐列表.
4 实验结果分析
4.1 数据集
本文数据集来自MovieLens.该数据集是以研究为目的的数据集,包含多用户对多部电影的评级数据,也包括电影元数据信息和用户属性信息.同时,本文以数据集中包含的电影链接为入口,在IMDB上爬取电影链接的所有评论.实验前还需要对每个评论文本数据采用以下预处理的方式进行处理:
1)去除一些无意义的评论,如只包含符号的无用评论等;
2)对评论文本进行大小写转化,将所有大写字母转化为小写;
3)根据空格进行分词;
4)去停用词,删除没有意义的符号和单词;
5)将所有单词处理成原形.
由于部分电影拥有大量的评论,为节省资源,提高模型的效率,设置评论数量最大值θ,超出的部分将被删除.为同时满足保证评论文本的质量和输入序列长度相同两个条件,本文只选择评论词数在50-300之间的评论文本,一共统计了5532部电影,共计337452条评论,5675832个评分.将数据集随机以8∶1∶1切分为训练集、交叉验证集和测试集进行实验.
4.2 评价指标
4.2.1 AUC
AUC衡量了模型对样本正确排名的能力,其值越大,说明模型的排名能力越高.
(17)
其中rankinsi指第i条样本的序号,M和N分别指正样本个数和负样本个数,∑insi∈positiveclass指将正样本的数量相加.
4.2.2 F-Score
F值将准确率(Precision)和召回率(Recall)加权平均,均匀地反映了推荐效果,其中准确率反映推荐算法的推荐水平,召回率反映被推荐算法中物品占用户真正喜欢物品的比重:
(18)
(19)
(20)
其中TP指用户喜欢且推荐的电影,FN指用户不喜欢但推荐的电影,FP指用户喜欢但没推荐的电影.
4.2.3 RMSE
RMSE用于评价模型的预测精确度.其值越小,说明预测模型具有更好的精确度.
(21)
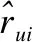
4.3 对比模型
为评估本文提出的CRRM模型有效性,将其与以下5种方法进行对比:
1)RNN[15]:递归神经网络(Recursive Neural Network)通过建模用户的历史序列行为来预测用户的下一个动作.
2)GAN[16]:生成式对抗网络(Generative Adversarial Networks)包括基于生成式的网络学习模型和基于判别式的网络学习模型两个模块,通过两个模型的相互博弈来学习用户的历史数据并排列出前k个用户感兴趣的项.
3)DeepCoNN[17]:深度协同神经网络(Deep Cooperative Neural Networks)通过两个并行的神经网络将用户评论集和项目评论集结合起来对用户和项目进行建模.
4)SA-GRU:SA-BiLSTM模型与SA-BiGRU模型属于同种类型的混合实验模型.SA-BiLSTM模型除了将SA-BiGRU模型中的 BiGRU 层换成GRU 层,其他实验设置均相同.
5)SA-BiLSTM:SA-BiLSTM模型与SA-BiGRU模型属于同种类型的混合实验模型.SA-BiLSTM模型除了将SA-BiGRU模型中的 BiGRU 层换成BiLSTM 层,其他实验设置均相同.
4.4 实验结果分析
4.4.1 实验环境
实验环境如表2所示.

表2 实验环境Table 2 Experimental environment
4.4.2 网络超参数
网络超参数如表3所示.

表3 网络超参数Table 3 Experimental environment
4.4.3 算法有效性验证
为同时融合评论文本和评分数据对算法有效性进行验证,本文从电影数量、评论文本数量和评分数量3个维度,将所提出的算法与其他该领域主流算法进行对比实验.
1)电影数量对算法性能的影响(单个电影的高质量评论文本数量设定为50,评分数量设定为1000).
从图4可以看出,算法随着电影数量的增多,在AUC和F值上变化较为平稳,且较其他5种算法的最大提升比率在8%左右.在电影数量小于2000时RMSE的相较于其他算法提升较为明显,因为SA-BiGRU中的BiGRU层相较于LSTM以及其他方法,参数少,收敛更容易,因而在数据量规模不大时,优势更为明显,提升比率在7%左右,具体如表4所示.
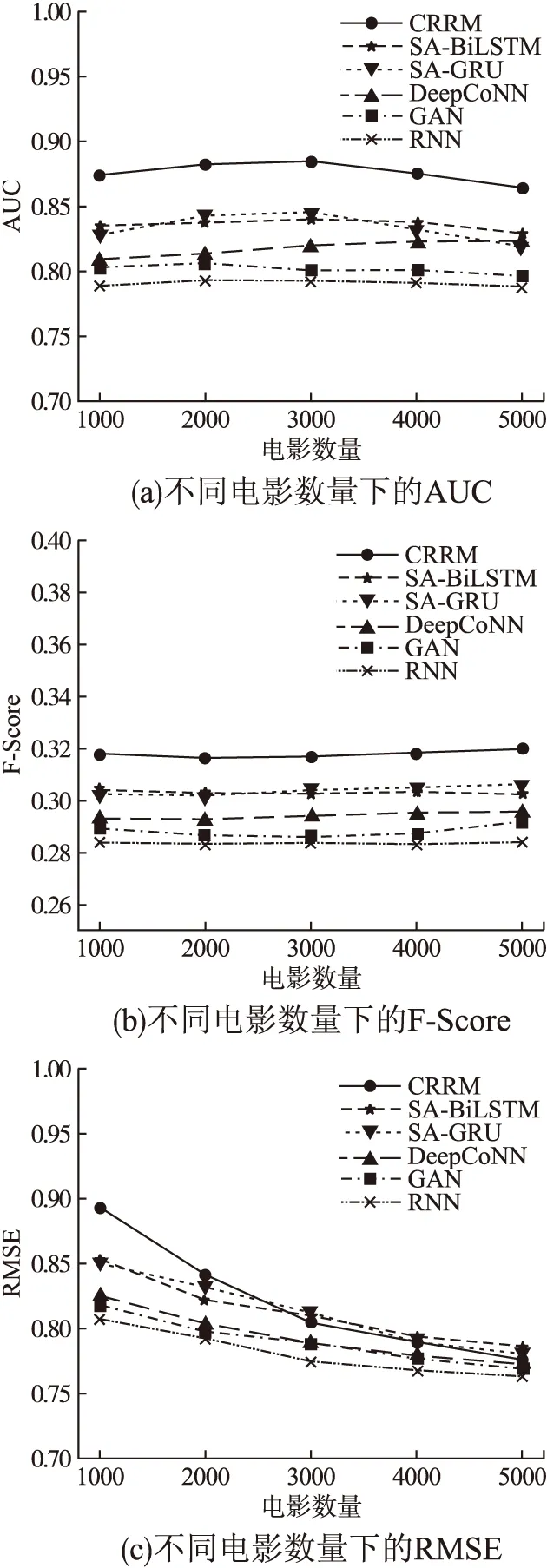
图4 不同电影数量下的实验结果Fig.4 Experimental result under different number of movies

表4 相对其他算法的性能提升比率(1)Table 4 Performance improvement ratio 1 compared with other algorithms
2)高质量评论文本数量对算法性能的影响(电影数量设定为5000,评分数量设定为1000).
从图5可以看出,算法随着评论数量的增多,在AUC和F值上有微小的上升趋势,且较其他5种算法的提升比率在7%和10%左右,RMSE呈明显上升趋势,在单个电影评论数量大于40时相对其他算法提升较为明显,提升比率在9%左右,具体如表5所示.

表5 相对其他算法的性能提升比率(2)Table 5 Performance improvement ratio 2 compared with other algorithms
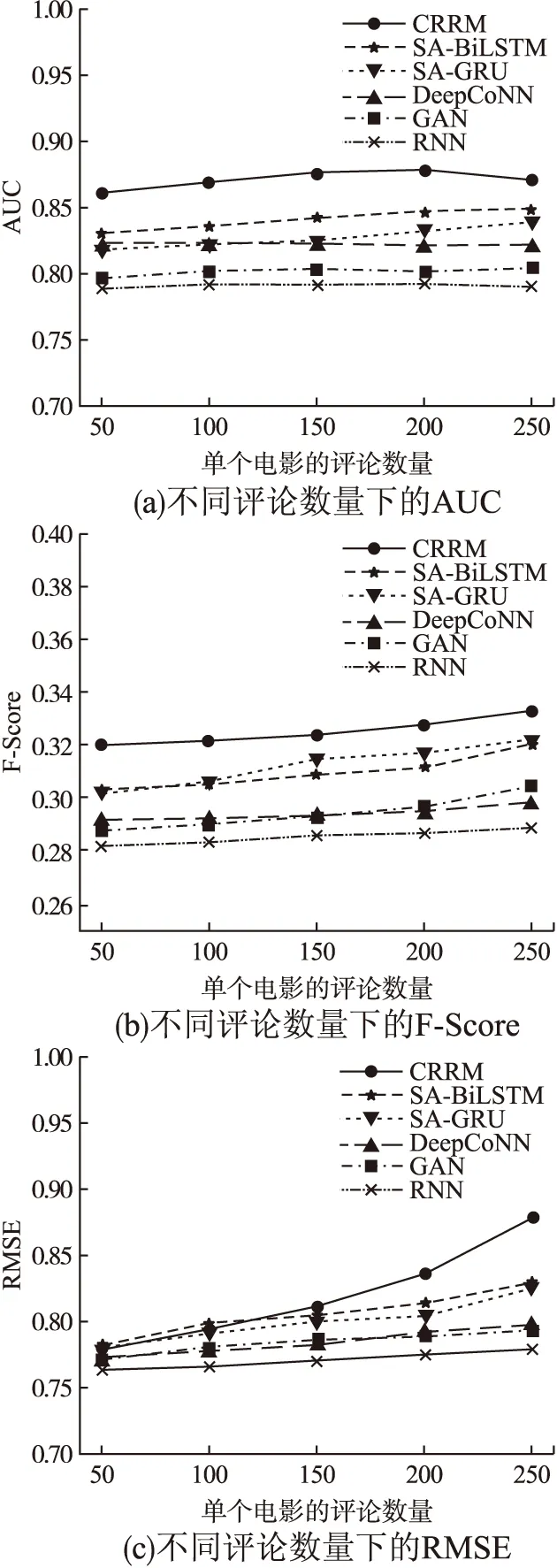
图5 不同评论数量下的实验结果Fig.5 Experimental result under different number of reviews
3)评分数量对算法性能的影响(电影数量设定为5000,单个电影的高质量评论文本数量设定为50).
从图6可以看出,算法随着评分数量的增多,在AUC和F值上变化较为平稳,在RMSE上有小幅度的提升,因为本算法融合了LFM分解评分矩阵后得到的潜在特征矩阵,算法性能更优,相对其他5种算法,提升比率分别在6%、9%和8%左右,具体如表6所示.
图6 不同评分数量下的实验结果Fig.6 Experimental result under different number of rates

表6 相对其他算法的性能提升比率(3)Table 6 Performance improvement ratio 3 compared with other algorithms
5 结 语
本文提出一种融合评论文本和评分矩阵的电影推荐算法,利用电影的高质量评论文本与评分矩阵使推荐结果更加准确全面.通过基于自注意力机制的双向门控循环单元神经网络对评论文本数据进行建模,得到电影评论特征矩阵,同时使用改进的LFM对用户评分矩阵进行分解,得出电影潜在特征矩阵.并通过改进的DeepFM将其与电影评论特征矩阵融合得到电影综合得分,形成推荐列表,以达到推荐的目的.实验结果表明,本文提出的电影推荐算法能够取得较好的推荐效果.由于电影评论更偏向于感性层面,本文未来将着重于对电影评论文本中的情感分析,以使推荐电影的准确性和完善性得到进一步提高.
