面向微博子话题检测的BTM模型研究
2022-10-15曹春萍
曹春萍,李 瑜
(上海理工大学 光电信息与计算机工程学院,上海 200093)
E-mail:1798597074@qq.com
1 引 言
微博舆情作为新兴的网络舆情表现形式,已逐渐给国家与社会的稳定带来隐患.伴随着每一热点话题的出现,微博上都会对其产生铺天盖地的讨论与报道.而现有研究往往局限于话题检测,却忽略了话题下更深层次、更细粒度的子话题研究.通常一个话题包含不同的子话题,子话题在一定程度上反映了话题的不同侧面.例如,9·11恐怖袭击话题的发展过程产生了“袭恐发生”、“政府紧急应对”、“伤亡人员抚恤”、“遇难者哀悼”和“嫌疑人抓捕”等不同子话题.这些子话题既是话题不同方面的描述,也反映了公众所关注的舆情热点[1,2].因此,如何有效地从海量信息中挖掘微博话题中的潜在子话题,逐渐成为舆情监控等研究领域的热点问题.
2 相关研究
概率主题模型的出现为解决话题检测与追踪提供了良好的途径,其思想是根据文档中的词汇或短语从而挖掘出潜在主题.LDA(Latent Dirichlet Allocation)及其改进模型[3-5]作为简单的概率主题模型在话题检测任务中应用较多,但该模型适用于处理新闻以及科学文献等长文本,而由于短文本信息量过少易造成LDA数据稀疏性问题.为解决这一问题,Yan等人[6]提出了一种二元词对主题模型BTM(Biterm Topic Model),该模型的训练时间与主题语义性方面都优于传统的LDA及其改进模型.因此,本文采用BTM模型研究微博网络中舆情信息的子话题检测.
2.1 BTM主题模型
BTM模型基于整个语料库建立主题,通过抽取文档集合中的biterm词对获取主题信息,以弥补短文本的数据稀疏问题.词对的构建是从整个语料集中的文档提取得到,并作为BTM建模的训练集.本文将每条博文看作一个独立的文本单元,并将预处理后同一文本中的任意两个不同的词组成一个biterm词对.词对的构建弥补了短文本数据过于稀疏的问题.例如语句“上海特斯拉自燃”,对其进行分词、去停用词等预处理之后,将文档内的滑动窗口设置为2,则存在“上海-特斯拉”、“上海-自燃”、“特斯拉-自燃”3个词对.其模型结构如图1所示.
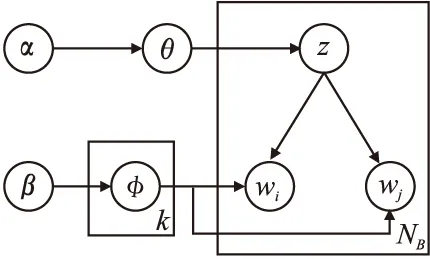
图1 BTM模型结构图Fig.1 BTM model diagram
其中,θ为语料库-子话题的主题分布矩阵,φ为子话题-词汇分布矩阵,wi,wj为二元词组中的词的标记,NB为文档集中二元词组集合,K为子话题题个数.图1中,BTM模型将整个博文信息分词之后组成词对,之后对子话题在语料库上进行描述,采用这种共现词进行建模学习不仅确保了词之间的相关性,又保证了不同子话题中不同词对的相互独立.模型的具体生成过程如图2所示.

图2 BTM模型生成过程Fig.2 Generation process of BTM
2.2 研究现状
子话题检测的关键在于将海量信息集合划分成不同的子话题簇,以达到簇内文本紧密相关,簇间文本明显分离.国内李军等人[7]首先提出并研究了子话题的概念.定义子话题是话题或新闻专题内某一特殊事件或活动的集合,并采用LDA模型对子话题进行检测.国外,Nallapati R等人[8]首次提出了新闻领域内的事件检测,并采用聚类方法检测子话题.近年来关于微博的话题检测逐渐受到了广泛关注,刘红兵等人[9]提出了一种基于LDA模型和多层聚类的微博话题检测方法,利用LDA主题模型提取文本数据特征,并采用改进的single-pass聚类方法对话题文本进行聚类.周炜翔等人[10]结合微博时间序列特征与词频特征应用LDA模型建模,提出了一种IDLDA-ITextRank的微博话题检测模型,但都由于数据稀疏性问题造成话题检测精准性降低.为此,Yan等人[6]提出了一种基于二元词组的BTM主题模型,该模型通过抽取文档的biterm词对进行建模,有效弥补了短文本的数据稀疏性问题.李雷等人[11]在BTM模型的基础上添加了用户特征信息的主题分布,提出了一种用户-词对主题模型U_BTM.随着深度学习在自然语言处理领域的发展,一些学者开始将深度神经网络引入到主题模型中以较好地表达文本主题特征.Li等人[12]使用注意力机制对连续句子之间的相关性进行建模,提出了双向循环注意话题模型,但该模型由于自身的局限性不适用于短文本话题建模.Cao等人[13]提出了一种NTM神经网络主题模型,该模型可学习文档-主题、主题-词汇的生成.Wang等人[14]在循环神经网络的基础上提出了一种双神经网络的主题模型TCNLM.该模型通过引入混合专家(MoE)语言模型来学习单词序列的局部结构.
上述研究都以话题为整体进行分析,忽略了同一话题下更深层次、更细粒度的子话题,而子话题在一定程度上更能反映话题发展过程中的不同方面.通常不同的话题之间词语特征区分度明显,易于检测.而同一话题内的文本用语差异较小,例如大量的背景词语、通用词语等信息使得研究同一话题下的子话题检测难度更高.另外,为了功能上的提升,上述模型常引入额外的变量使得模型的收敛性较低,并且忽略了语义信息问题,造成生成的话题语义连贯性较差,可读性较低.
基于上述存在的问题,为了增强模型的可扩展性、话题的语义连贯性以及针对微博特征的子话题检测的精准性,本文结合微博文本较短的显著特点,研究了双向LSTM神经网络在概率主题模型BTM中的应用,提出了ATT-BLSTM-BTM词对主题模型(Attention Mechanism Based Bidirectional Long Short Term Memory with Bitern Topic Model,简称ATT-BLSTM-BTM).该模型将融合注意力机制的BLSTM模块作为先验知识,引入到BTM模型选取主题词对的步骤中.通过BLSTM建模训练词与词之间的相互关系,同时,利用attention机制计算特征词注意力概率分布,以降低语料库中与主题无关的词汇对建模的影响,从而有效提高了从微博稀疏数据中子话题检测的精准性.
本文的主要结构如下,第2节阐述了近几年研究人员所提话题检测模型的优缺点,并结合微博特征以及词语关系提出了ATT-BLSTM-BTM子话题检测模型;第3节详细介绍了提出的ATT-BLSTM-BTM子话题检测模型;第4节进行实验,并对实验结果进行对比分析;第5节总结了本文的研究内容与不足之处.
3 ATT-BLSTM-BTM模型
BTM模型忽略了无关词汇对建模的影响,并且词对的构建没有考虑词之间的相关性导致子话题检测的可读性较低.对此,本文提出了ATT-BLSTM-BTM词对主题模型.该模型以BTM结构为基础,将左侧ATT-BLSTM模块训练得到的词对之间的关系作为先验知识融入到词汇主题分配采样中,其中BLSTM通过训练得到词与词之间的相互关系,同时,利用attention机制计算特征词注意力概率分布从而降低语料库中无关词汇对建模的影响.ATT-BLSTM-BTM的模型结构如图3所示,与BTM相比,ATT-BLSTM-BTM模型避免了引入额外的随机变量,保证了其参数推断过程的简便性.
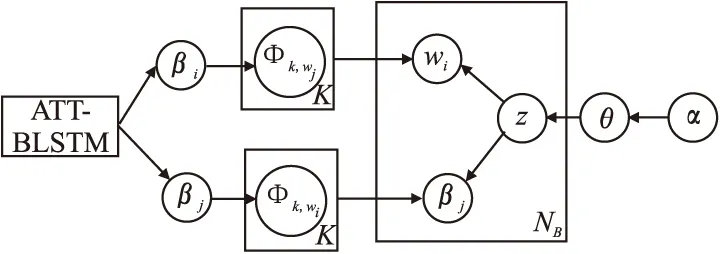
图3 ATT-BLSTM-BTM模型结构图Fig.3 ATT-BLSTM-BTM model diagram
ATT-BLSTM-BTM模型主要生成过程如图4所示.
3.1 ATT-BLSTM模块
RNN在处理长序列文本时,梯度将呈指数级衰减或者增长,最终会引起梯度消失或梯度爆炸.长短期记忆网络(LSTM)的出现有效抑制了梯度消失,而且也可自动学习长时依赖关系.但LSTM只能学习一个方向的信息,双向长短期记忆网络(BLSTM)由两个顺序相反的LSTM模型组成,可以学习两个方向的信息[15],所以本文采用BLSTM来学习词之间的相互信息,可得到包含上下文信息的语义编码,从而能有效的表达文本语义特征.

图4 ATT-BLSTM-BTM模型生成过程Fig.4 Generation process of ATT-BLSTM-BTM
Attention[16]是一种基于人脑认知事物时注意力会集中在某个焦点,而忽略其他非焦点的机制,所以本文采用该机制的主要作用是增加模型对关键词汇的关注度并降低非关键词汇的关注.将attention机制加入BLSTM模型中对输入进行针对性学习后,模型输出序列会与其概率权重进行关联,即输入序列通过模型选择的概率值来确定输出序列的每一项,可以有效突出关键词的作用,同时也考虑了文本的上下文信息.基于Attention的BLSTM模型结构如图5所示.
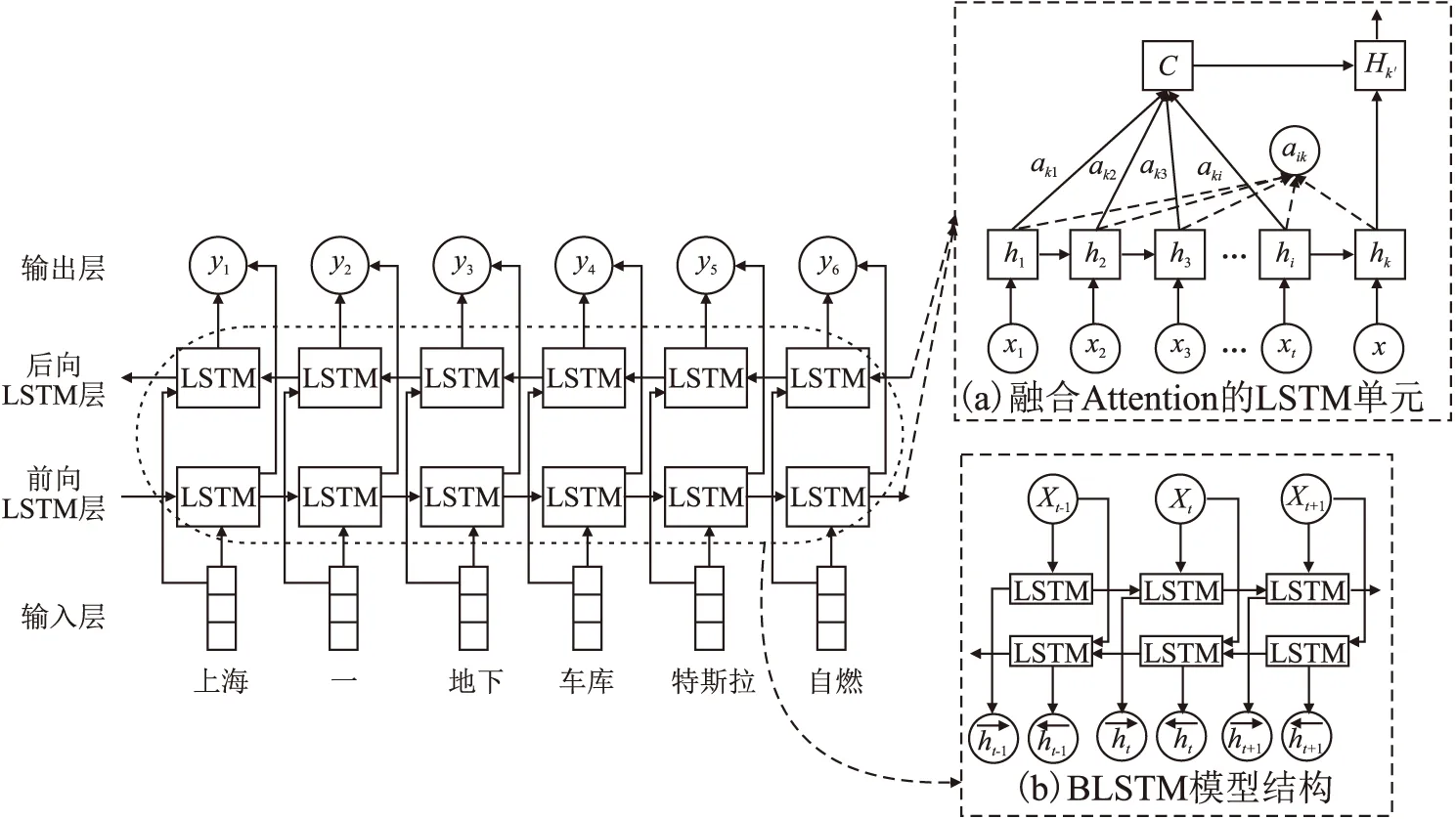
图5 ATT-BLSTM模型结构图Fig.5 ATT-BLSTM model diagram
(1)
eki=vtanh(whk+Uhi+b)
(2)
其中,T表示输入序列的元素个数,v,w,U表示概率权重矩阵,hi表示输入序列第i个节点对应的隐藏层状态.通过式(1)、式(2)可得到每一个输入的注意力概率.

(3)
Hk′=H(C,hk,x)
(4)
其中,语义编码C由αki与hi乘积的累加值得到,然后将C与博文总体向量x作为BLSTM模块的最终输入,模型的输出Hk′就是最终的特征向量,由于Hk′融合了历史节点x1,x2,…,xt的权重信息,使得关键词的语义信息得到有效突出.图中y1,y2,y3,…,yt作为模型的输出序列,包含了词汇wi和词汇wj的相关性,其计算如式(5)所示:
yi(j)=p(wj|wi,Hi-1′)
(5)
3.2 模型参数推断
ATT-BLSTM-BTM模型的关键是求得语料库—子话题分布θ以及子话题—词汇分布φ,由于子话题是未知变量,所以这两个参数值的获得往往是通过参数估计方法.常用的参数估计方法[17]有变分推理、期望传播和Gibbs采样等.其中Gibbs采样不需要已知样本分布,而且更具有记忆有效性,更适合处理大规模数据集.所以,ATT-BLSTM-BTM模型可利用Gibbs采样的共轭先验α和β推理出概率分布参数θ与φ.获得这两个分布参数后,可进一步挖掘整个语料库中的潜在子话题,以及最能代表每个子话题的主题词.当前词汇的子话题分配的Gibbs采样如式(6)所示:
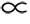
(6)
其中,n-b,z表示子话题z中去除词对b之后的其他词对总数,n-b,wi|z表示n-b,z中词汇的wi总数.由此得出子话题分布θ.
(7)
对于词汇wi,wj,可以得到子话题-词汇分布.
(8)
(9)
其中,nwi|zk和nwj|zk分别代表子话题zk中包含词汇wi和wj的次数,βi和βj分别代表词汇wi和βj的先验参数.由此可将φk=[φk,w1,φk,w2,…,φk,ww]表示为子话题zk上的单词分布.
4 实验及结果分析
4.1 数据采集与预处理
为验证所提模型的有效性本文采用两个数据集,其中数据集1来自微博API接口采集的2019年4月1日~2019年5月8日“上海特斯拉自燃”这一话题,在此舆情事件中,上海某小区一地下车库一辆特斯拉突然自燃起火殃及周边车辆,事件发生后瞬间引起大众的热议.数据集2同样是从微博API接口采集的2019年4月24日~2019年5月8日“仁济医院赵晓菁事件”,此次舆情事件主要是因医生拒绝患者插队引发医闹,而被警察戴上手铐带走.
由于得到的两个数据集存在不完整、不规范等异常情况,首先对该数据集进行预处理与清洗,即将数据集中微博发布时间或转发时间为空的记录清除.其次,去除标签为机器人的数据、大量的无关噪声数据,以及少于5个字的微博文本,例如,“转发微博”这条博文不仅对子话题检测毫无意义,而且还会降低模型性能.经过数据清洗,剔除冗余数据后,得到有效数据分别为161628与95384条博文记录,并将此作为本文模型的输入.
4.2 模型中相关参数的确定
4.2.1 确定最优子话题数
由于微博中同一话题的子话题包含较多的相似背景信息,K值的选取是模型聚类好坏的关键因素,K值选取较大将会导致属于同一子话题的文本分类到其他子话题,而K值选取过小将导致不同的博文都可被视为同一子话题,这对子话题检测的准确度造成很大影响.为了克服K值选取过大或过小所带来的影响,本实验通过计算不同K值下模型的困惑度perplexity[18]值来确定子话题数K的大小.对于一个未知分布,模型困惑度perplexity值越小,就代表模型越好.模型D的困惑度perplexity(D)计算如式(10)、式(11)所示:
(10)
p(w)=p(z|d)×p(w|z)
(11)

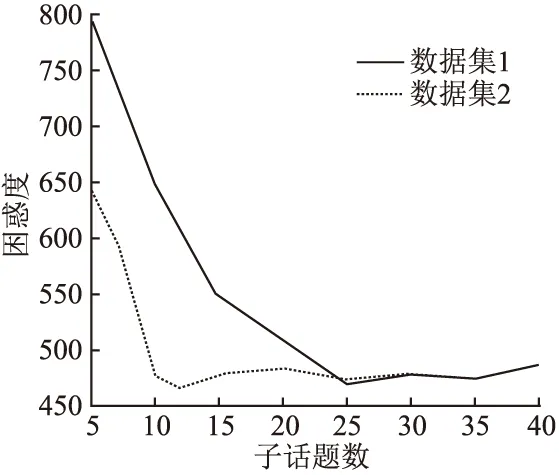
图6 确定最优子话题数Fig.6 Determine the optimal number of subtopics
由图6可看出,随着子话题数的增多,模型困惑度在逐渐减小.但当子话题数大于某一阈值时,模型困惑度开始逐渐增加,这一阈值即为模型的最佳状态.当数据集1的子话题数取25,数据集2的子话题取12时,模型困惑度开始收敛,此时模型达到最佳状态.因此,在实验中分别将两个数据集的子话题数K取值25与12.
4.2.2 模型训练参数
根据上一节对ATT-BLSTM-BTM模型的介绍,模型的超参数α、β、最优子话题数K以及Gibbs采样迭代次数的设置如表1所示.

表1 ATT-BLSTM-BTM模型训练参数Table 1 ATT-BLSTM-BTM model training parameters
4.3 实验结果与对比分析
4.3.1 ATT-BLSTM-BTM模型实验结果
ATT-BLSTM-BTM模型的部分实验结果如表2、表3所示.在本次实验中数据集1共挖掘25个子话题,并在表2展示了其中的6个子话题,每个子话题列出其中概率最大的前8个词语,同时根据生成的关键词人工表述出其子话题的语义信息.同样,数据集2共挖掘12个子话题,并在表3展示了其中的5个子话题.

表2 数据集1子话题关键词汇表Table 2 Dataset 1 subtopic key vocabularies

表3 数据集2子话题关键词汇表Table 3 Dataset 2 subtopic key vocabularies
4.3.2 对比分析
本文从定性评估与定量评估两方面对子话题检测模型的结果进行评价.并采用LDA模型、NTM模型、BTM模型与本文模型进行实验结果对比分析.
(1)定性评估
定性评估主要评价词之间的相关性与改进前后模型的性能.
1)词向量相关性
首先,从两个数据集中随机选取一些词语作为主题词,然后通过模型找到与该词语义最相近的前3个词,再使用余弦相似度来验证词之间的相关性,实验结果如表4所示.其中余弦相似度值越接近1,说明词语语义相关程度越高.从表4可以看出,本文模型在不同的数据集上训练得到的词向量均符合实际期望.
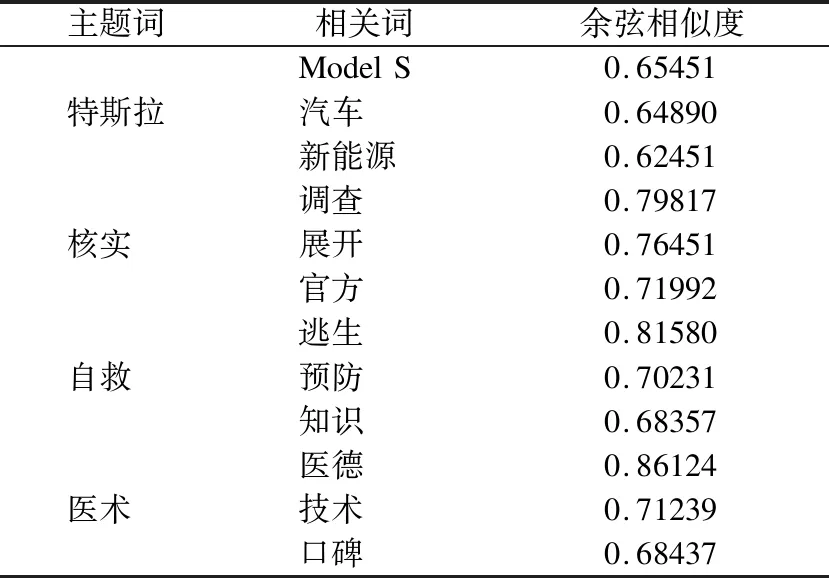
表4 模型训练得到的词向量Table 4 Word vector obtained by model training
2)子话题模型性能对比
为验证ATT-BLSTM-BTM模型从博文中提取的关键词之间的语义相关性,分别选取LDA模型、NTM模型、BTM模型在两个数据集上进行实验对比,如表5所示.
由表5可看出,LDA模型产生的子话题相关词可读性较低,模型效果最差.NTM模型与BTM模型提取的主题相关词汇中存在一些无关词语,而本文模型提取的相关词汇与主题词语义相关性最高.
表5 4种模型语义相关性对比Table 5 Semantic correlation comparison of the four models
(2)定量评估
定量评估是指使用量化指标对子话题模型的结果进行评判,本文通过KL距离与点对互信息(PMI)分别对模型所挖掘的子话题从多样性与一致性两方面进行量化评价.
1)子话题多样性
子话题的多样性反映了话题之间的差异情况,多用KL距离衡量.但KL值是不对称的,所以一般计算子话题间的平均KL距离,平均KL值越大,两个子话题间的差异性就越大,反之越小.计算公式如式(12)所示:
(12)
图7(a)、图7(b) 展示了4个模型在不同的数据集上所挖掘的子话题之间的平均KL距离.可以看出,受数据稀疏性的影响,LDA模型在两个数据集上的KL值均最低,而基于biterm的BTM模型与本文模型的KL值相较于LDA与NTM模型均有明显提高.本文模型与BTM模型相比,由于融入词性关系使得KL值进一步提升,说明本文模型所挖掘的子话题之间的主题差异性更大,子话题更具有代表性.
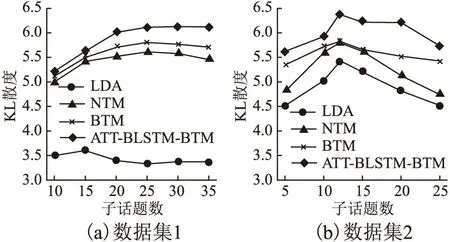
图7 各模型在不同子话题数下的平均KL距离图Fig.7 Average KL distance graph of each model under different number of subtopics
2)子话题一致性
得到语义一致、易于理解的话题词一直是主题模型所关注的焦点问题.其中评价话题词语义一致性最常用的指标是点对互信息PMI[19],该值的大小反映了主题语义连贯性的强弱.PMI值越大,代表模型产生的主题词连贯性越高,主题模型的质量就越好.对于子话题K的PMI如式(13)所示:
(13)
其中,m表示该子话题K下概率值最高的前m个单词,本文m取值8.p(wi)表示词汇wi在微博文档中的出现概率,p(wi,wj)表示词对(wi,wj)在文档中共同出现的概率.图8(a)、图8(b)展示了LDA、NTM、BTM与本文模型在两个数据集上的不同子话题数K下的PMI值.

图8 各模型在不同子话题数下的话题一致性对比图Fig.8 Comparison of topic consistency of different models under different number of subtopics
由图8(a)、图8(b)可以看出,本文模型在两个数据集中子话题数的PMI值都高于其他模型,是因为模型在词对的选取中考虑了词语的上下文信息,量化了词与词之间的相关性关系,更易于人们理解.其中BTM模型位居第2,是因为它采用单词共现模式进行建模,每个biterm中的词汇采样均来自同一主题分布,更适合微博短文本的特点.由于LDA模型缺乏词汇方面的语义强化,更适合科技文献或新闻语料等长文本建模,使得模型的PMI值最低.NTM模型在LDA模型的基础上使用神经网络建模,同样忽略了子话题的语义连贯性.
5 结束语
针对微博舆情中子话题检测问题,本文在BTM模型的基础上提出了一种ATT-BLSTM-BTM词对主题模型.该模型将融合注意力机制的BLSTM模块作为先验知识,引入到BTM模型主题词对的选取中.通过BLSTM更细粒度地量化出词与词之间的相互关系,同时,利用attention机制计算特征词注意力概率分布,削弱语料库中与主题无关的词汇对模型的影响.实验结果表明,本文所提模型与主题模型LDA、BTM和NTM模型相比,检测的子话题具有较强的区分性与语义连贯性.但是微博网络中还存在大量的图片视频等非文本信息,在下一步的工作中将引入非文本特征信息,实现基于跨模态主题模型的子话题检测研究.
