一种分阶段的恶意域名检测算法
2022-10-15王甜甜刘雄飞
王甜甜,刘雄飞
(中国矿业大学 银川学院 信息工程学院,银川 750000)
E-mail:546211088@qq.com
1 引 言
域名系统(Domain Name System,DNS)作为一种实现网络域名与IP地址相互转换的服务,得到了广泛的应用,如流媒体、电子商务和即时通信等,几乎所有的互联网应用都需要对域名进行解析.同时,DNS缺少对攻击者攻击行为的检测能力,极易受到攻击者的关注.据360Netlab威胁检测报告指出,近年来由于恶意域名攻击导致信息泄露和资产流失的事件数不胜数.如2021年国家自然科学基金委员会信息中心遭遇钓鱼网络攻击,导致评审专家个人信息泄露;2020年葡萄牙能源公司EDP遭遇勒索攻击,经济损失达数千万美元.由此可见,恶意域名攻击问题不容忽视.
因此,如何快速和准确地检测出网络中的恶意域名攻击,提前进行封堵,阻断其进一步的危害行为,对于保障互联网的正常运行具有重要意义.
2 研究现状
2.1 字符相似度计算
通过收集不同家族的恶意域名及其攻击特征,构建恶意域名黑名单,并利用分类或聚类方法实现待测域名的判定.如Sato等[4]提出了一种双向混合域名判定方法,通过分析已知种子恶意域名与关联域名之间的特征和注册信息,建立映射关系图谱,预测关联域名的合法性.赵宏等[5]提出了一种基于词法特征的恶意域名快速检测算法,通过将待测域名按照域名长度属性值进行聚类分组,并根据聚类小组权重值优先级排序,按照优先级大小依次计算与黑名单上恶意域名之间的相似度.袁福祥等[6]提出了一种基于域名历史数据的异常域名检测方法.该方法通过提取合法域名样本集和恶意域名样本集中每一域名在注册时间、注册长度和同IP地址域名数量等特征,构造了合法域名与恶意域名检测的SVM模型.
2.2 网络流量特征分析
由于DNS的开放性使得攻击者极易利用域名生成算法或人工伪造等方式随机生成大批量恶意域名,并发起集群攻击,短时间内访问流量剧增.同时,恶意域名的访问记录会被记录到日志中,因此,可以通过分析网络流量的异常变化和DNS日志数据,实现恶意域名的判定.如Sharifnya等[7]提出一种基于DNS流量特征分析的恶意域名检测方法,根据与被攻击主机之间的关联度将关联主机划分为多个集群,通过计算流经每个集群中主机的访问时间,定位受恶意域名攻击的服务器,实现恶意域名的定位.Truong等[8]结合DNS访问流量记录,通过分析流量异常DNS服务器的DNS访问流量,实现恶意域名检测.彭成维等[9]根据域名请求的先后时间顺序对待测域名进行聚类分组,并基于嵌入学习将每一域名映射成低维空间的特性向量,训练用于合法域名与恶意域名的分类模型.
2.3 域名构造特征分析
利用机器学习算法并结合域名的构造特征检测恶意域名,成为近年来恶意域名检测的主流方法.如Zhang等[10]提出了一种基于词素特征的轻量级域名检测算法,通过分析域名自身蕴含的词根、词缀、拼音及缩写等特征,并利用C4.5决策树算法按照递归思想自上而下构造决策树,实现合法域名与恶意域名的分类.Mao等[11]提出了一种基于机器学习的DGA域名检测算法,通过提取DGA算法生成的恶意域名在语言、结构和统计等方面存在的5维特征构造分类模型,在多种数据集上进行测试验证了该算法的有效性.Cucchiarelli等[12]针对DGA算法产生的恶意域名难以精确检测的问题,提出了一种面向算法生成的恶意域名检测方法.该方法利用N-Gram将训练集域名分割成2-grams和3-grams的序列,通过计算待测域名序列与训练集域名序列之间的KL和Jaccard系数,快速给出恶意域名的判断.
以上恶意域名检测方法各有所长,相比而言,域名相似度的检测方法具有检测实时性强和简单直接的优点,但该类检测方法无法对新出现域名有效检测,导致检测准确率低,误报和漏报率高.流量特征分析的恶意域名检测方法能够较好地解决点击欺诈、钓鱼网络等组行为特征明显的家族域名,但对其他类型恶意域名的检测能力较弱,检测范围局限.域名构造特征分析的检测方法虽然具有检测准确率高和检测范围广的优点,但该类检测方法过多依赖特征的设计,对新出现的恶意域名检测效果不佳.
综上,基于当前恶意域名检测方法中存在的检测开销较大、检测范围局限和检测准确率不高等问题,结合域名黑名单、域名白名单、双向长短时记忆神经网络BiLSTM和卷积神经网络CNN的混合模型,提出一种分阶段的恶意域名检测算法.该算法首先利用域名黑名单进行快速过滤恶意域名;然后,利用域名白名单快速响应合法域名;最后,利用BiLSTM-CNN的混合模型,实现待测域名的最终阶段检测.
3 算法设计与分析
3.1 数据来源
从Alexa、Malware Domain List、DGA Domain List和Shodan、Fofa等开源数据集和官方网站中获取恶意域名和合法域名,并检测域名的完整性,清除掉重复域名和不完整域名,构造合法域名样本集和恶意域名样本集.
3.2 恶意域名黑名单过滤
恶意域名具有家族团聚攻击的特点[2],即利用相同规则或算法产生的恶意域名具有家族效应.因此,本文借鉴文献[9]中的方法,并依据域名与域名在字符组成上的相似度值,实现域名黑名单中恶意域名的聚类分组.恶意域名聚类算法描述如下,恶意域名的聚类分组示意如图1所示.
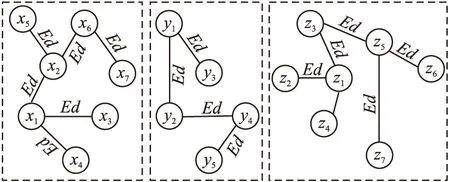
图1 恶意域名的聚类分组Fig.1 Clustering group of malicious domain names
1)在多家族恶意域名数据集中随机选择基准域名集{x1,y1,z1,…};
2)以域名之间的Ed值为半径遍历基准域名的关联域名{x1→x2}、{y1→y2,y3}、{z1→z2,z3,z4};
3)以基准域名的关联域名为基准域名,以Ed为半径查询关联域名{x2→x5,x6}、{y2→y4}、{z3→z5},直到满足条件的所有域名查询完为止;
4)将关联域名聚类为一个小组,即为一个家族域名集合;如Domain1={x1→{x2→{x5,x6→{x7}}},x3,x4}.
域名与域名之间的字符相似度值计算如公式(1)所示:
(1)
其中,Ed[strm,strn]表示域名strm和域名strn之间的编辑距离值,i表示strm中的字符序号,j表示strn中的字符序号;xi和yj分别表示strm的第i个字符和strn的第j个字符;d[i,j]表示以strm为行,以strn为列,构成的矩阵中第i行,第j列处的值.
待测域名检测时,通过计算待测域名与聚类小组中基准域名之间的编辑距离值,根据编辑距离值的大小确定待查找聚类小组范围.然后,通过计算待测域名与小组中关联域名间的编辑距离值,快速给出判断结果.并根据检测结果构造恶意域名集I和潜在恶意域名集I.
3.3 合法域名白名单响应
合法域名为了便于用户记忆与理解,具有自然语言的构词特征,本文借鉴文献[13,14]中的特征构造合法域名的随机森林分类模型.合法域名在结构、语言和统计等方面存在的构词特征如表1所示.
依据表1中整理的合法域名特征,利用公式(2)将字符特征的提取转化为具体实数计算.
Vi=Fi(domaini)
(2)
其中,Vi表示特征向量;domaini表示待提取的第i个域名,Fi表示特征转换函数,对应表1中的构词特征.
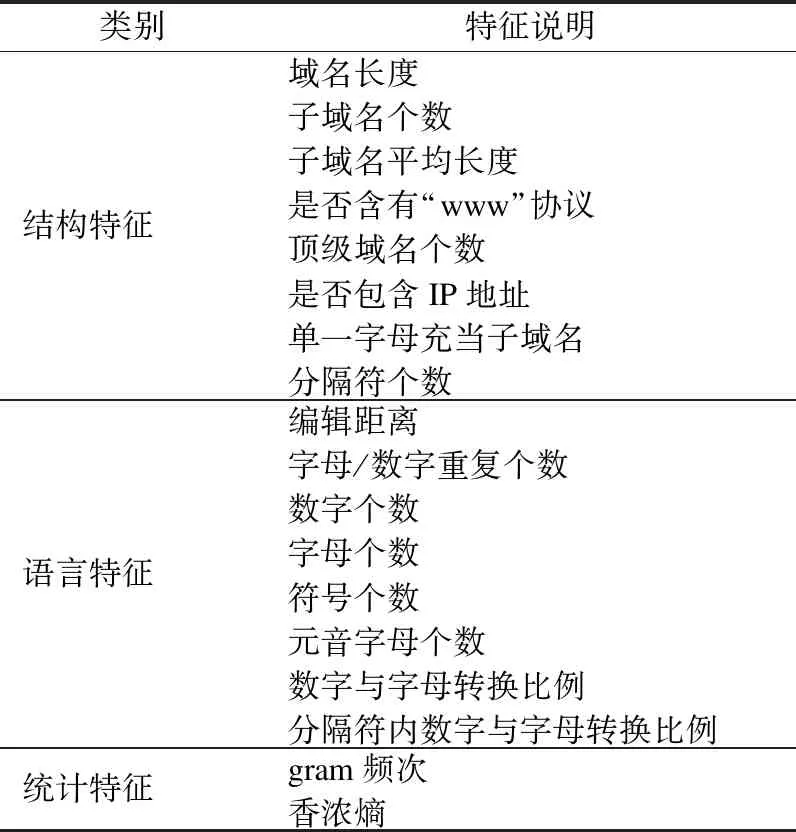
表1 合法域名构词特征Table 1 Word formation features of normal domain
随机森林分类模型[17]构造流程描述如下:
1)n表示域名训练样本中domain的总个数,m表示字符特征的总个数,记为feature_set;
2)随机从feature_set中选择m′个特征,建立决策树,其中m′≪m;
3)从域名训练样本中随机抽取n次,构造域名训练集,并将剩余域名作为测试集;
4)根据投票结果确定待测域名样本的分类.
待随机森林分类模型训练完成后,将潜在恶意域名集I中的每一域名作为输入,利用已训练好的随机森林分类模型进行决策分类,及时响应合法域名解析请求,并根据检测结果构造合法域名集II和最终待测域名集II.
3.4 BiLSTM-CNN检测
合法域名和恶意域名由于生成算法不同在形式上相对自由,但字符组成和结构上仍然存在上下文依赖关系[15].因此,本文采用双向长短时记忆神经网络BiLSTM提取域名在语言、结构和统计等方面的全局特征;然后,利用卷积神经网络CNN在学习双向长短时记忆神经网络提取域名上下文语义信息的基础上,进行局部强特征提取;最后,使用Softmax实现待测域名集中合法域名与恶意域名的分类.BiLSTM-CNN构造流程如图2所示.
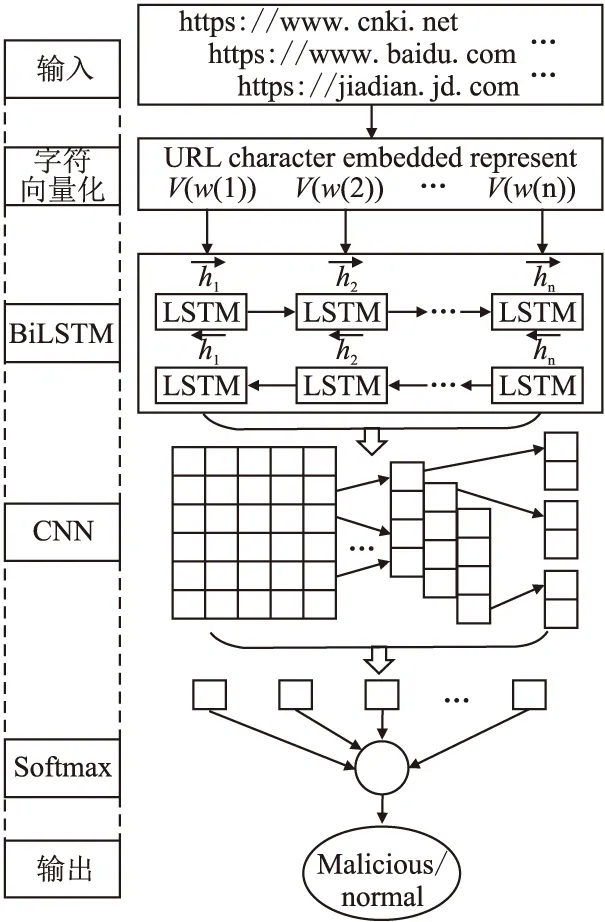
图2 BiLSTM-CNN模型Fig.2 Model of BiLSTM-CNN
3.4.1 全局特征提取
合法域名为体现个体特点和方便记忆,具有自然语言的构词特征,而恶意域名是通过域名生成算法或域名变换技术随机生成的.两者虽然都是由相同的字符集构成,但在字符组合、结构和统计等方面具有不同的特征,且字符组成和结构上存在上下文依赖关系.因此,本文利用图3中的双向长短时记忆神经网络BiLSTM提取域名的全局特征.

图3 BiLSTM网络结构Fig.3 Network structure of BiLSTM
图3中,D={d(1),d(2),…,d(n)}表示域名,首先利用word2vec将域名中的字符d(i)转换为字符向量V(d(i)),并将d(i)组成的域名映射为域名矩阵Sij,其中Sij=V(d(1)),V(d(2)),…,V(d(n));然后对域名矩阵Sij利用BiLSTM进行上下文特征提取,计算如公式(3)所示:
(3)
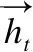
3.4.2 局部强特征提取
由于合法域名具有一定的自然语言构造特征,而不同恶意域名具有不同的生成方式和组成形式,且呈发散状态[16],提取全局特征中的局部特征是保证网络对合法域名和恶意域名进行准确分类的关键.本文利用卷积神经网络CNN实现全局特征中的局部强特征提取.CNN网络模型如图4所示.
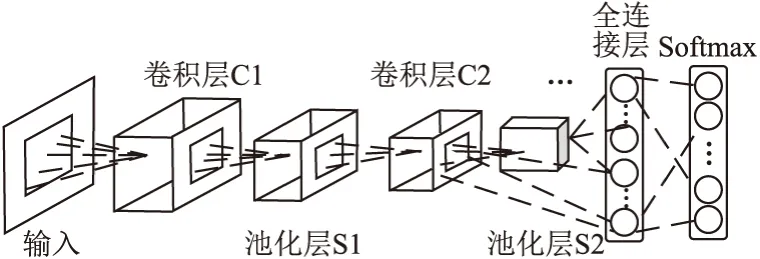
图4 CNN网络结构Fig.4 Network structure of CNN
CNN将BiLSTM的输出作为卷积层的输入,卷积层采用大小为r×k的滤波器对全局域名特征进行卷积操作,学习域名的局部语义特征,计算方法如式(4)所示:
Ci=f(L(r×k)·F(ht)+b)
(4)
其中,Ci表示CNN提取的局部语义特征;f表示非线性转换函数,L(r×k)表示滤波器,F(ht)表示BiLSTM的输出,b表示偏置.
3.4.3 恶意域名分类
在BiLSTM-CNN的最后一层连接一个具有分层特征和识别功能的多重感知器Softmax,对输入域名进行分类;将最终待测域名集II作为已训练BiLSTM-CNN网络的输入,利用公式(5)计算获得输入域名的分类值.
Oi=Softmax(widit+bi)
(5)
其中,Oi为输出类别,wi为全连接层与输出层之间的权重矩阵,dit为t时刻全连接层的输出矩阵,bi为偏置.
4 实验及结果分析
4.1 实验环境
实验环境为64位windows 10,8核i7-10875H 32G 512G 2.4GHZ CPU,开发语言为Python 3.8,开发平台为Pycharm;参数的设定决定检测结果的精度,本文利用参数固定的方法确定初始值,并通过实验对照进行迭代寻优确定最佳参数.模型参数设置如表2所示.

表2 模型超参数设置Table 2 Model hyperparameter settings
1)训练步长:为降低BiLSTM-CNN网络训练时间开销和降低模型过拟合,本文采用实验对照的方法确定训练步长.训练步长epochs与检测精度之间的关系曲线如图5所示.
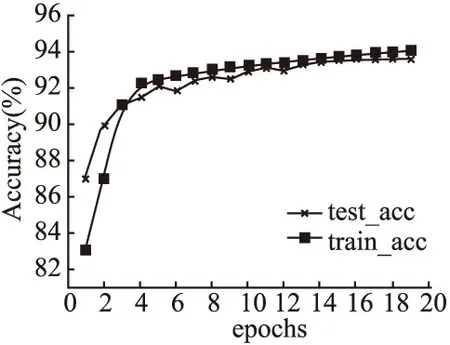
图5 BiLSTM-CNN网络平均训练曲线Fig.5 Average training curve of BiLSTM-CNN
由图5可知,当训练步长epochs为16时,测试集上的准确率趋于平稳,因此,本文设定训练步长epochs为16.
4.2 数据集及评价标准
从公开数据集DGA Domain List、Alexa和Malware Domain List等各大网站上收集与整理获得52万条域名[16-18].其中合法域名38万条,恶意域名14万条,恶意域名数据集中包含Zeus、Kraken、Symmi、Banjori、Phishing和Bot等多种类型的家族恶意域名.并将52万条域名数据划分为80%的训练集,10%的测试集和10%验证集.
选用准确率Accuracy、精确率Precision、误报率(False Positive Rate,FPR)和漏报率(False Negative Rate,FNR)作为评价指标,计算如公式(6)所示.通常准确率Accuracy和精确率Precision越高,误报率FPR和漏报率FNR越低,表明检测效果越好.
(6)
其中,TP表示被准确检测出的合法域名;FN表示将恶意域名误报为合法域名的个数;FP表示将合法域名误报为恶意域名的个数;TN表示被准确检测出的恶意域名.
4.3 性能分析
4.3.1 分阶段集成算法性能
在相同的数据集上分别构造3阶段的单一检测算法:第1阶段基于黑名单技术的恶意域名检测算法MD(Malicious Domains)、第2阶段基于域名白名单技术的恶意域名检测算法ND(Normal Domains)和最终阶段的恶意域名检测算法BiLSTM-CNN;1、2阶段的联合算法MD_ND、1、3阶段的联合算法MD_BiLSTM-CNN和2、3阶段的联合算法ND_BiLSTM-CNN;3阶段的集成算法MD_ND_BiLSTM-CNN.各模型的检测性能如表3所示.
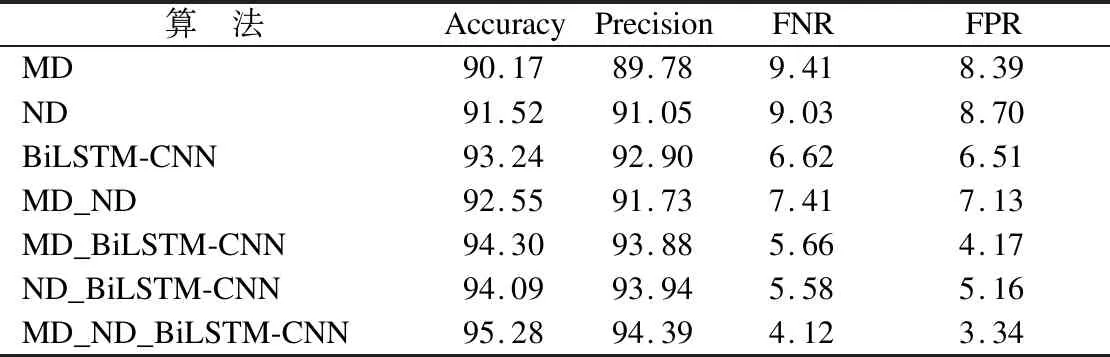
表3 单一阶段与集成算法性能对比(%)Table 3 Performance comparison between single stage and integrated algorithm (%)
由表3可知,本文集成算法MD_ND_BiLSTM-CNN与单一阶段的恶意域名检测算法MD、ND、BiLSTM-CNN和1、2阶段、1、3阶段、2、3阶段的集成算法MD_ND、MD_BiLSTM-CNN、ND_BiLSTM-CNN相比,在检测准确率和检测精确率方面平均提升了2.84%和2.36%;在漏报率和误报率方面平均降低了43.45%和49.97%,主要原因是3阶段的集成算法通过多个轮次诸阶段过滤掉符合阶段性检测的恶意域名和合法域名,提升了检测性能.此外,利用第1、2阶段检测出的恶意域名送入BiLSTM-CNN快速学习新出现的恶意域名构词特征,提高了对于新变种或新出现恶意域名实时检测的效率.
在时间开销方面,单一阶段的恶意域名检测算法MD在92s内完成12176条恶意域名的准确检测;ND算法在86s内完成35279条合法域名的准确识别;BiLSTM-CNN算法在43s时间内完成44592条合法域名与恶意域名的准确检测;3阶段的集成算法在112s时间内可完成49881条恶意域名与合法域名的准确检测,虽本文模型在时间复杂度上有所增加,但其可在最高Accuracy、Precision和最低FNR和FPR下达到445.37个/s的恶意域名检测速度,具有较高的检测效率.
4.3.2 BiLSTM-CNN集成算法检测范围
在相同的实验环境下,选用Zeus、Kraken、Symmi、Banjori、Phishing和Bot等多个家族的恶意域名进行测试验证.具体检测性能如图6所示.
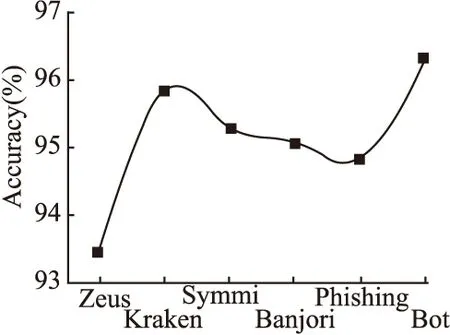
图6 多家族恶意域名检测Fig.6 Multi-family malicious domain detection
由图6可知,本文分阶段集成算法BiLSTM-CNN对于多个家族的恶意域名具有较高的检测准确率,验证了本文算法在检测范围方面的高效性.
4.3.3 同类检测算法性能对比
在相同的实验环境和相同的评价机制下,分别构造单一BiLSTM、CNN、RNN(Recurrent Neural Network)、DAE(DenoisingAuto-Encoders)、GRU(Gated Recurrent Unit)和集成算法RNN-CNN、BiLSTM-DAE、RNN-DAE等恶意域名检测算法,并进行性能评价与分析.具体性能对比结果如图7所示.

图7 同类算法性能对比Fig.7 Performance comparison of similar algorithms
由图7可知,BiLSTM-CNN模型在Accuracy和Precision等方面优势明显,究其原因,单一RNN、GRU和BiLSTM模型只考虑了上下文依赖关系;单一CNN、DAE模型只考虑了局部特征;RNN、GRU与CNN、DAE的集成模型考虑了上下文和局部特征,但本文BiLSTM双向长短时记忆神经网络充分考虑上下文双向依赖关系;此外,DAE降噪自编码网络只能提取明显特征,而域名字符少,特征提取难度大,本文采用CNN通过卷积计算,实现局部特征提取,实验也验证了BiLSTM-CNN模型的高效性.
5 结束语
恶意域名的变种随着检测手段的增多不断丰富,现有基于字符特征的恶意域名检测方法难以满足新出现恶意域名对于检测精度和检测范围的高要求.为此,本文提出了一种分阶段的恶意域名检测方法,诸阶段过滤掉符合当前阶段的恶意域名和响应合法域名的解析请求.通过在当前主流数据集上进行测试验证,本文算法具有较好的检测性能,在抵御僵尸网络、垃圾邮件、远控木马攻击等方面具有较好的实用价值.深度网络模型参数多、计算复杂度高,在实际网络环境中需考虑实时性要求.为此,后续研究在保持检测精度和域名类型的基础上,设计更加轻量化的检测模型,提高检测的实时性.
