预处理共轭梯度算法异构并行求解及优化
2022-10-15贾金芳黄建强王晓英严文昕
张 琨,贾金芳,黄建强,2,王晓英,严文昕
1(青海大学 计算机技术与应用系,西宁 810016)
2(清华大学 计算机科学与技术系,北京 100084)
E-mail:qhu_jf@163.com
1 引 言
线性方程组求解是许多科学计算和工程应用中的核心计算内容,其目前主要有直接法和迭代法两种求解方式[1-3].直接法由于计算机资源的限制难以有效求解大规模线性方程组,而迭代法具有存储需求低,系数矩阵在迭代时保持稳定等优点,所以其常用于求解大规模线性方程组.目前迭代法已经由Jacobi方法、SOR方法等经典迭代法过渡到了共轭梯度(CG)方法和广义共轭残差(GCR)方法等效率更高的Krylov子空间迭代法[4,5].同时,为了改善迭代法的收敛性,也相继产生了多种多样的预处理技术[6-8].
由于求解问题规模不断增大,单处理器已经不能满足大规模计算的需求,因此研究大规模稀疏线性方程组的快速求解方案具有重要意义.并行计算是高效求解大规模稀疏线性方程组的重要途经,其主要有多核CPU、GPGPU、集群3种类型[9,10].许多学者为探究不同平台的高性能迭代法实现方案展开了相关研究.Bohacek J等[11]针对热扩散问题在GPU上利用多项式预处理对CG法进行并行优化,与传统CFD代码相比最高能够获得16000倍的加速,同时还指出了高效的并行算法不仅要考虑硬件设备的更新,还要考虑算法本身的改进.Anzt H等[12]提出一种应用于线性系统求解的不完全稀疏近似逆(ISAI)预处理方法,该方法可以并行生成预条件子,而且与Block-Jacobi预处理方法相比可以获得更好的性能.Jiao Y Y等[13]为满足地质领域求解线性方程组的需要,在MPI、OpenMP、MPI+OpenMP 3种方案中测试可行且高效的CG法并行方案来解决球面非连续变形分析问题,在模拟隧道坍塌的实验中加速比达到7x左右.Suryanarayana P等[14]基于PETSc并行库实现了一种新的AAR迭代法,并与GMRES、Bi-CGSTAB等多种迭代法进行了对比,在相同的预处理条件下,新方法能够更快地完成求解.Bernaschi M等[15]实现了基于GPU的包含AMG预处理部分和求解部分的线性求解器,其通过一种兼容加权匹配聚合算法实现最优的核函数配置,从而有效利用了GPU的性能.Aliaga J I等[16]对ILUPACK中的GMRES算法进行了改进,优化了其中的预处理子应用部分及MGSO部分,使这两部分的加速比分别提升至3x和10x.Sanjuan G等[17]将Schwarz交替域分解技术与MPI+OpenMP混合并行技术结合,使风场计算中的CG迭代法求解速度提升至近9x.
综上所述,目前的性能优化技术大多集中在算法改进或者单一并行方式领域,而基于异构平台的多机并行优化相对较少.本文在CPU+GPU异构平台上实现了基于MPI+CUDA混合并行的预处理共轭梯度算法,并对实验结果进行了对比分析,发现MPI+CUDA混合并行的预处理共轭梯度算法能够更高效地求解大规模对称正定线性系统.
2 线性方程组与预处理共轭梯度算法
2.1 线性方程组
线性方程组的求解广泛存在于工程问题中.就大规模数值计算而言,使用迭代法求解线性方程组时涉及到的矩阵及向量运算会占据大量的计算时间和硬件资源.随着求解问题规模的不断增大,如何加快大规模稀疏线性方程组的求解过程显得愈加重要.一个n元线性方程组如公式(1)所示,其中m为方程组个数,am,n为方程系数、x为方程解、b为常数项.
(1)
将线性方程组转换为线性代数中的概念则可以表示为Ax=b的形式,如公式(2)所示,其中A是m×n的系数矩阵,x是解向量,b是右端向量.
(2)
2.2 预处理共轭梯度算法及性能分析
2.2.1 预处理共轭梯度算法
共轭梯度算法是解决对称正定线性系统问题最有效的迭代方法之一,具有存储量要求少、不必事先估计某些参数、编程简单等优点[18].为改善迭代法的收敛性,目前主要利用预处理技术将原方程Ax=b替换为M(-1)Ax=M(-1)b等形式进行求解,其中较为常用的预条件子有不完全分解预条件子、稀疏近似逆预条件子等[19-21].预处理共轭梯度算法的具体内容如算法1所示.
算法1. 预处理共轭梯度算法
输入:系数矩阵A,预条件子M,初始解x0,右端向量b.
输出:近似解x.
1.r0=b-Ax0,z0=M-1r0,p1=z0
2.fori= 1: Maximum number of iterationsdo
3.αi= (ri-1,zi-1)/(Api,pi)
4.xi=xi-1+αipi
5.ri=ri-1-αiApi
6.ifconvergedthenexit
7.zi=M-1ri
8.βi= (ri,zi)/(ri-1,zi-1)
9.pi+1=zi+βipi
10.endfor
2.2.2 预处理共轭梯度算法性能分析
每次迭代过程中,预处理共轭梯度算法需要进行1次稀疏矩阵向量乘,5次向量内积(包括1次残差计算),1次预条件子应用,3次向量数乘.在预处理共轭梯度算法的主要计算量分布测试中,预处理部分使用ILU预条件子进行测试,占比55.51%,稀疏矩阵向量乘占比40.01%,向量内积占比2.36%,向量数乘占比2.12%.由于使用不同的预条件子的计算开销会有较大差异,本文主要针对其余计算部分进行性能优化.单机设备的计算性能有限,而且还有可能无法满足大规模数据的存储需求,所以目前通常采用并行的方式对预处理共轭梯度算法进行求解及优化.
3 预处理共轭梯度算法并行优化
3.1 优化框架
并行算法在优化过程中为保证稀疏矩阵存储性能一致,统一使用CSR(Compressed Sparse Row)格式保存稀疏矩阵[22,23].实验在异构平台上进行测试,CPU端并行技术使用MPI,GPU端并行技术使用CUDA.异构并行的预处理共轭梯度算法执行步骤为:
1)MPI进程读取数据并初始化CPU和GPU内存空间;
2)CUDA核函数计算r,然后MPI进程进行数据通信;
3)MPI进程进行预条件子应用,计算z和p;
4)CUDA核函数计算稀疏矩阵向量乘和向量内积,然后MPI进程进行通信得到α;
5)CUDA核函数计算向量数乘,更新x和r;
6)CUDA核函数计算残差Res,然后MPI进程进行数据通信及迭代退出判断;
7)MPI进程进行预条件子应用,计算z;
8)CUDA核函数计算向量内积,然后MPI进程进行数据通信得到β;
9)CUDA核函数计算向量数乘,更新p,然后MPI进程进行数据通信并返回步骤4.
实验方案分为3个部分,首先在预处理优化部分,方案对ILU预条件子和Jacobi预条件子的加速性能进行对比分析;然后在MPI并行部分,方案将可以重叠的部分计算操作和通信操作进行了整合;最后在MPI+CUDA混合并行部分,方案针对异构并行中存在的数据传输问题、访存问题等,分别通过使用页锁定内存、改变线程任务分配方式及利用共享存储器的措施进行优化.
3.2 预处理优化
本文所测试的预条件子为ILU预条件子和Jacobi预条件子.Jacobi预条件子的构造过程相对简单,最后生成的预条件子M即为DIA(A).ILU预条件子将系数矩阵A分解为LU-R的形式,分解之后的预条件子可以满足不同的条件P.ILU预条件子的构造过程如算法2所示.
算法2. ILU分解
输入:系数矩阵A,条件P.
输出:预条件子M.
1.fori= 2,3,…,ndo
2.fork= 1,2,…,i-1and(i,k)∉Pdo
3.Aik=Aik/Akk
4.forj=k+1,…,nand(i,j)∉Pdo
5.Aij=Aij-Aik×Akj
6.endfor
7.endfor
8.endfor
3.3 MPI并行通信优化
MPI并行方式中各个进程间的通信开销会随着进程规模的增大而增大[24].在预处理共轭梯度算法中,并行任务主要在每一个迭代步内执行,其中MPI主要负责任务的粗粒度划分、进程间数据通信、进程内部数据拷贝及非并行部分的计算.
在MPI并行算法中,每次迭代都会进行数据通信,但是除计算Ap所进行的稀疏矩阵向量乘(SpMV)通信之外,其他向量内积(Dot)的部分通信结果可以延迟参与计算.为减少算法的通信开销,每次迭代步内将部分计算操作与通信操作进行重叠.由于计算Ap的SpMV操作需要保证p向量在各个进程中是完整的,而且也不存在可以与通信进行重叠的计算任务,所以在SpMV操作之前使用阻塞的Allgather函数进行数据通信.在后续3组需要通信的Dot操作中,通信结果存在可以延迟计算的部分,同时有相应的计算任务可以与通信进行重叠,所以使用非阻塞的Iallreduce函数进行数据通信.在将计算操作和通信操作进行重叠之后,通信优化算法可以减少使用阻塞通信函数带来的额外开销.
3.4 GPU并行优化
3.4.1 数据传输优化
CPU与GPU协同计算时最主要的开销在于两者之间的数据传输,并行程序只对部分必须进行全局更新的向量进行数据传输.在每次迭代过程中无法避免的数据传输内容包括向量p、向量r、向量z、残差Res以及向量内积的中间结果subDot.对于这些需要在CPU与GPU间频繁传输的数据在开辟内存空间时采用页锁定内存(pinned memory),因为操作系统不会对页锁定内存执行分页和交换操作,使得该内存能够始终驻留在物理内存中,而GPU可以通过直接内存访问方式直接在CPU和GPU间拷贝数据,从而提高数据传输效率.
3.4.2 访存优化
将算法主要计算操作移植到GPU上之后,全局存储器的合并访存(coalesced access)特性也会对程序性能造成一定影响.CUDA模型的最小执行单位为线程束(warp),当同一线程束内的线程访问连续的存储空间时,能够减少访存操作的次数.向量计算中的一维数据能够保证线程束中的线程访存是连续的,但在矩阵计算中则需要根据使用的稀疏矩阵存储格式调整线程计算任务的分配策略.实验采用的稀疏矩阵存储格式为CSR,该格式使用3个数组分别保存稀疏矩阵每行的偏移量、列索引及非零元素值.计算任务以线程为最小单位分配时,会出现同一线程束内的线程访问不连续内存空间的情况,从而造成访存性能下降.为保证矩阵计算过程中的访存连续性,计算任务以线程束为最小单位进行分配.以线程束为最小单位调度任务之后,同一线程束内的线程访问连续的内存空间,从而可以利用全局存储器的合并访存特性提高访存性能.
3.4.3 多级存储器优化
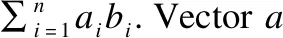

图1 内积并行Fig.1 Dot parallel mode
4 实验与分析
4.1 实验环境和数据
实验在4个高性能节点上进行测试,每个节点两块CPU,型号为Intel(R) Xeon(R) CPU E5-2692 v2 @ 2.20GHz,内存为64GB;节点配备GPU为Tesla T4,显存为16GB;CUDA模型版本为v10.1.实验所测试的数据来自SuiteSparse Matrix Collection数据集[25],该数据集包含大量来自实际工程中的稀疏矩阵数据.如表1所示,实验选用了计算流体力学问题、电路仿真问题、结构性问题等8个领域共11个测试数据,同时测试数据的元素量从3087898到117406044不等,具有一定数据规模跨度.
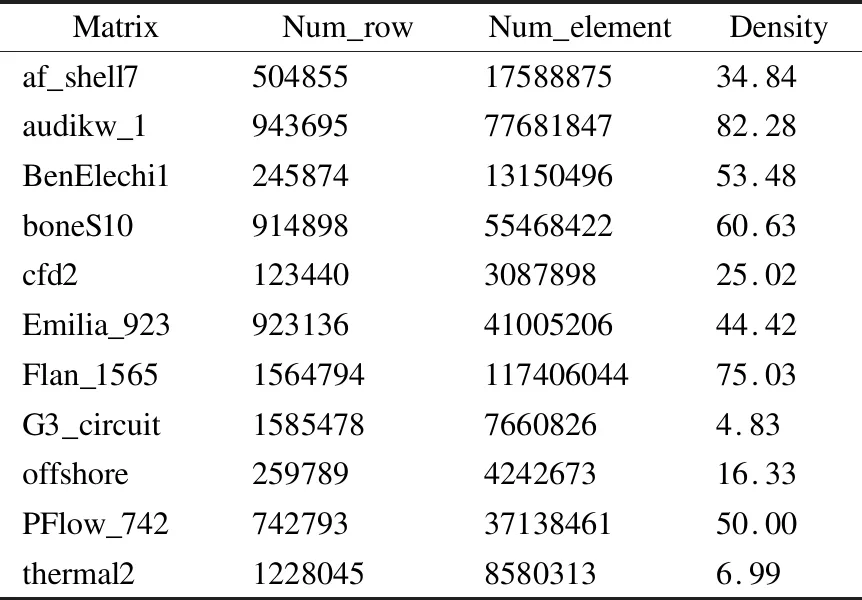
表1 矩阵数据Table 1 Matrix data
4.2 实验结果与分析
4.2.1 预处理结果
对于条件数过大的系数矩阵,使用迭代法进行求解时通常会出现收敛速度慢甚至不收敛的情况.虽然使用预处理技术会增加部分计算开销,但为了提高迭代法的求解效率,利用预处理技术来改善迭代法的收敛性是有必要的.
实验测试了ILU预条件子和Jacobi预条件子两种方式对CG算法收敛性的影响.由于不同领域问题对误差精度要求不一致,将问题精度设置为统一标准会出现不同测试数据差异过大的情况,因此实验对相同迭代次数下的误差变化进行对比.在迭代200次的条件下,无预处理算法和两种预处理算法的最终残差如图2所示.从图中可以看出,在加速迭代法收敛的方面ILU预条件子比Jacobi预条件子效果更好.ILU预条件子构造和使用的成本都比Jacobi预条件子更高,而且ILU预条件子在应用时也没有与Jacobi预条件子相当的并行性.因此对于预处理子的选择需要综合考虑应用成本和误差精度要求两个方面,当误差精度要求较低且需要控制应用成本时可以选择使用Jacobi预条件子,当对误差精度要求较高时则需要使用ILU预条件子.
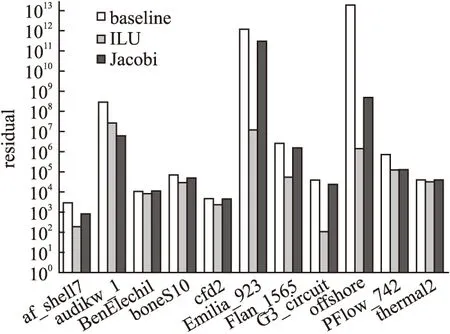
图2 预条件子对比Fig.2 Comparison of preconditioner
4.2.2 无预处理算法并行结果
无预处理算法中的主要计算内容为向量数乘、向量内积、稀疏矩阵向量乘.串行算法和3种并行算法的运行性能对比如图3所示.为与MPI+CUDA混合并行进程数量保持一致,MPI并行一共使用4个节点,每个节点启动一个进程.由于使用MPI并行会存在部分额外的开销,实验所测试的矩阵数据平均加速比为2.99x(最高3.41x).MPI并行的开销主要来自于各进程间的数据通信,不同算例的通信次数是一致的,通信开销有差异主要是因为测试算例的数据规模不同.当测试矩阵非零元素数量不多而阶数较大时,会出现矩阵每行计算量(Density)过小的情况,最后导致MPI并行性能提升不明显.MPI并行中矩阵每行计算量较小的算例如G3_circuit(4.83)和thermal2(6.99)加速比只有2.5x左右,而矩阵每行计算量较大的算例如Emilia_023(44.42)、BenElechi1(53.48)加速比能达到3x以上.
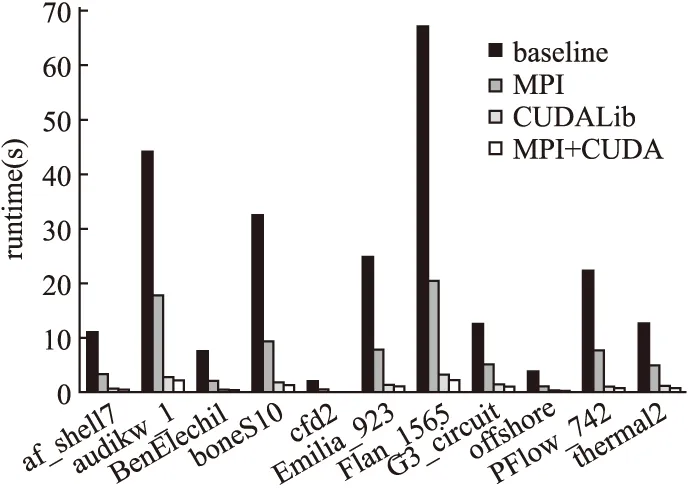
图3 无预处理算法性能对比Fig.3 Performance comparison of original algorithm
MPI+CUDA混合并行在MPI并行的基础上将计算任务移植到GPU上执行,该方式并没有更改MPI并行各进程间的通信模式,但是可以提高各进程计算部分的性能.MPI+CUDA混合并行将计算任务进行GPU移植之后充分发挥了GPU的多线程能力,在测试数据上的平均加速比为17.25x(最高27.12x).MPI+CUDA混合并行的性能变化趋势与MPI并行基本一致,但有一点区别是总的计算量不能过小,否则不能发挥GPU的多线程优势,甚至可能由于CPU与GPU之间数据传输开销造成性能下降的情况.如测试数据cfd2(25.02),虽然矩阵每行都有一定的数据量,但由于总的计算量过小,最后MPI+CUDA混合并行的加速比不足10x.CUDALib并行算法使用Nvidia并行计算库中的cuSPARSE和cuBLAS提供的代数计算接口函数进行实现,在各个测试数据上的平均加速比为13.13x(最高19.42x).
4.2.3 ILU预处理算法并行结果
ILU预处理算法在无预处理算法的基础上增加了预条件子应用的计算内容.ILU预条件子应用需要在每次迭代过程中增加两次三角方程求解.因为三角方程求解计算具有明显的串行性质,实验将这一部分计算内容按照串行的方式执行.由于存在一部分串行计算内容,ILU预处理算法与无预处理算法相比整体性能出现下降的现象.串行算法、MPI并行算法、CUDALib并行算法及MPI+CUDA混合并行算法的性能对比如图4所示.在实验测试的矩阵数据上MPI并行算法性能平均提升47%(最高54%),CUDALIB并行算法性能平均提升71%(最高92%),MPI+CUDA混合并行算法性能平均提升84%(最高97%).ILU预处理算法在应用预条件子时的计算量与SpMV相当,而且由于预条件子应用没有进行并行处理,所以当算法中其他部分如SpMV、Dot、AXPY等通过并行方式提高计算性能时,预条件子应用会占据程序执行的主要时间.
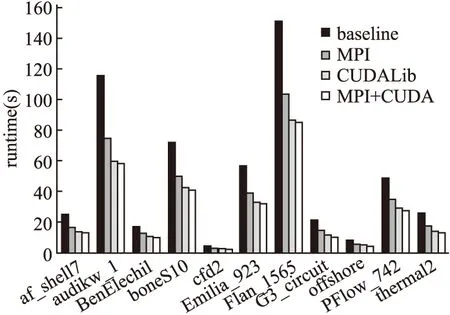
图4 ILU预处理算法性能对比Fig.4 Performance comparison of ILU preconditioned algorithm
4.2.4 Jacobi预处理算法并行结果
Jacobi预条件子的应用比ILU预条件子的应用计算量更少,每次迭代过程中应用Jacobi预条件子的计算量与一次向量数乘相当,所以在Jacobi预处理并行算法中主要的计算开销还是集中在稀疏矩阵向量乘部分.因为串行任务所占据的计算量较少,Jacobi预处理算法在各矩阵数据上的运行时间与无预处理算法整体接近,能获得较好的加速效果.串行算法、MPI并行算法、CUDALib并行算法及MPI+CUDA混合并行算法的性能对比如图5所示.在实验测试的矩阵数据上MPI并行算法平均加速比为2.92x(最高3.46x),CUDALib并行算法平均加速比为9.56x(最高14.3x),MPI+CUDA混合并行算法平均加速比为12.76x(最高19.45x).
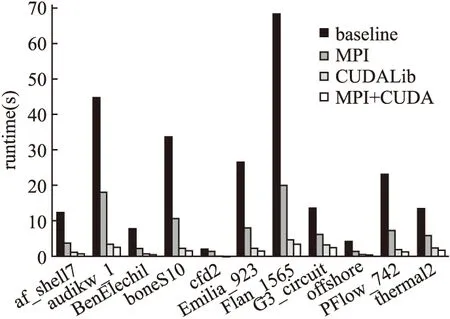
图5 Jacobi预处理算法性能对比Fig.5 Performance comparison of Jacobi preconditioned algorithm
4.2.5 可扩展性分析
如图6所示,实验测试了不同并行算法加速比随着节点数目增加的变化趋势.在使用MPI并行方式的算法中,随着节点数目的增加,无预处理算法和Jacobi预处理算法的加速比保持上升趋势,但ILU预处理算法的加速比提升并不明显,这是由于ILU预处理算法中的预条件子应用会增加较多额外的开销,从而限制了整体加速比的提升.在使用MPI+CUDA混合并行方式的算法中,随着节点数目的增加,无预处理算法和Jacobi预处理算法的加速比同样保持上升趋势,并且与MPI并行方式的对应算法加速比相比还有大幅度的提升,这得益于GPU的多线程优势,而ILU预处理算法的加速比由于预条件子应用开销的存在依然没有明显提升.
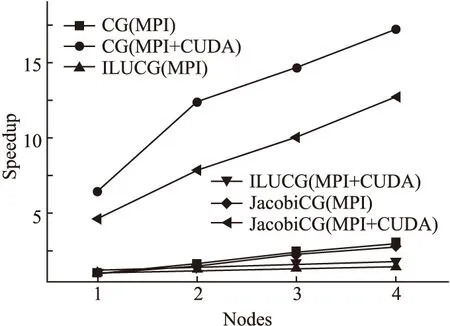
图6 可扩展性对比Fig.6 Comparison of scalability
5 结 语
大规模稀疏线性方程组的求解问题一直都是人们研究的重点方向.随着各种工程问题的求解规模增加,单机设备已经难以高效完成大规模计算任务.本文首先实现了3种不同的预处理共轭梯度并行算法,然后对结果进行了对比分析.实验结果表明,在MPI并行、CUDALib并行和MPI+CUDA混合并行3种方式中,MPI+CUDA混合并行方式能够充分发挥多机异构设备的性能,达到更高的计算效率.在下一步工作中,我们将进行更多预条件子异构性能优化的研究.
