融合用户聚类与Bandits算法的微博推荐模型
2022-10-15何羽丰徐建民
何羽丰,徐建民,张 彬
1(河北大学 网络空间安全与计算机学院,河北 保定 071002)
2(河北大学 管理学院,河北 保定 071002)
E-mail:2813154215@qq.com
1 引 言
冷启动[1]和数据稀疏[2]是个性化推荐系统中的常见问题,近年来已经成为该领域研究热点之一[3].由于微博系统存在新用户数量巨大和文本信息稀疏的特点,上述问题尤为突出.
针对微博等社交网络中的新用户冷启动问题,相关学者进行了大量研究,早期的冷启动问题研究主要是通过随机推荐策略、流行度策略和均值策略等方法解决,存在覆盖率低等缺点,降低了用户个性化体验[4].后来,相关学者针对上述问题进行了相应改进,提出了利用融合辅助数据策略、动态推荐策略等方法.张瑞等[5]提出了一种基于混合粒度主题模型的微博个性化标签推荐模型,通过对微博用户在不同粒度上的分析处理,优化个人标签的添加过程,提高个人标签的使用率和实用性,利用标签辅助信息解决新用户冷启动问题;刘宇东等[6]提出了一种融合内容相似度与多特征计算的个性化微博推荐模型,模型结合用户的地理位置、年龄和性别等辅助信息导出相似用户集,从相似用户的偏好方面考虑新用户或者沉默用户的冷启动问题.陈克寒等[7]针对微博网络的冷启动问题,提出了一种基于聚类算法融合多种辅助信息的推荐算法,该算法在一定程度上解决了冷启动问题,同时提升了推荐的多样性.陈杰等[8]提出了一种基于动态用户兴趣的微博推荐模型,模型运用动态策略在一定程度上缓解了微博用户的冷启动问题.针对微博推荐系统中的数据稀疏性问题,常用方法是数据扩充、聚类方法和矩阵分解.马慧芳等[9]提出了一种基于超图随机游走标签扩充的微博推荐方法,着眼于用户-标签矩阵数据稀疏性问题的处理,通过在超图上随机游走得到一定数量的关键词对微博用户标签进行扩充,依据扩充后的标签对用户进行微博推荐;罗斌等[10]提出了一种结合幂律特性的混合微博推荐方法,通过充分使用幂律分布的头部信息并对长尾部分的数据进行有效挖掘,在处理长尾部分数据稀疏性问题方面具有一定的效果.吴湖等[11]提出了一种融合多种信息聚类的协同过滤推荐算法,将用户、项目和评分结果等信息进行联合聚类,然后在每一个类中应用协同过滤算法,为用户提供较为合理的推荐结果.杨阳等[12]提出了一种基于矩阵分解的个性化推荐算法,通过对评分矩阵进行梯度分解,减小了数据稀疏对推荐结果的影响,一定程度上提高了推荐质量.
上述模型或算法在一定程度上解决了冷启动或数据稀疏性问题,但仍存在一些局限性.当挖掘的冷启动用户辅助数据不足时,融合辅助数据策略的模型很难为用户提供有效推荐;现有基于动态推荐策略的微博推荐算法一般需要多种实时数据,当用户反馈不足时推荐效果不佳;对用户数据进行扩充来缓解数据稀疏性往往依赖一定数量的原始用户数据,当数据不足时很难为用户提供有效推荐;应用聚类算法缓解数据稀疏性常存在用户较多难以聚类的问题;基于矩阵分解算法缓解数据稀疏性只适用于协同过滤具有信息矩阵的推荐场景;现有算法往往未关注微博新用户冷启动应对方法和稀疏数据处理方法的有效结合.
Bandits算法最早由Robbins提出并应用于诊疗试验,以获得最优治疗方案[13],目前已经成功应用于个性化商品推 荐[14,15]、搜索引擎关键字最优选择[16]和5G网络信道选择[17]等.Bandits算法不要求预先给定任何数据,仅通过接收环境对动作的反馈获得学习信息和更新模型参数,在处理用户冷启动问题方面具有优势.目前Bandits算法可以大致分为随机探索类算法、置信区间类算法和概率匹配类算法.
随机探索类算法是最早提出的一类Bandits算法,该类算法每次以一定概率随机选择一个项目,否则就选择目前认为最好的项目.随机(Random)算法[18]是最简单的随机探索类算法,总是完全随机的选择一个项目,一般无法取得较好效果;先探索后利用(Expore-Then-Commit,ETC)算法[19]在Random算法的基础上进行改进,在算法的前mK个时间步以概率1随机选择一个项目,后n-mK个时间步以概率1选择回报最高的项目,关键是如何确定m,在数据量较大时很难寻找最佳的m,算法效果往往不够理想;ε-贪心(ε-Greedy)算法[18]在ETC算法的基础上将两个阶段合并成一个阶段,在整个实验过程中以ε的概率随机选择一个项目,以1-ε的概率选择历史平均收益最高的项目,但是该算法中的ε固定不变,没有利用动作获取的信息进行修正,当ε较小时需要大量用户历史反馈,反馈不足时效果不好,当ε较大时算法无法收敛到最优解,只能为用户提供较优项目;利用最小估计值选择项目(Chosen Number of Arm with Minimal Estimation,CNAME)算法[20]在ε-Greedy算法的基础上加入了平均奖赏最小的动作被次数选择以数构建探索概率计算公式,根据环境自适应地调整探索概率,但仍需要大量用户反馈且较ε-Greedy算法提升不大.
置信区间类算法是近年来新兴起的一类Bandits算法,该类算法基于某些信息设置置信区间,选择置信区间上界或下界最大的项目.置信上界1(Upper-Confidence-Bound 1,UCB1)算法[21]是经典的置信区间类算法之一,该算法仅仅基于项目选择次数构建置信区间,每次为用户提供一个项目,收敛速度较慢.置信上界2(Upper-Confidence-Bound 2,UCB2)算法[22]是UCB1算法的一种变种,该算法通过加入epoch概念,将n个时间步划分为多个epoch,每个epoch可以为用户多次选择同一个项目,一定程度上提高了算法的效率,但是该算法需要预先尝试每一个项目,在项目较多的应用场景下收敛速度较慢.MOSS算法[23]也是UCB1算法的一个变种,它将项目选择次数、算法总时间步数和项目数加入到了置信上限的计算公式中,在一定程度上提高了收敛速度,但是该算法必须提前给出总时间步数且不允许修改,应用场景较窄.
概率匹配类算法是当前较为流行的一类Bandits算法,该类算法假设每个项目产生收益的概率p符合一定分布,通过实验不断调整该分布的参数,每次选择项目时,用每个项目的分布产生一个随机数,选择产生的随机数最大的项目,根据用户的反馈更新相应项目所对应分布的参数.软最大化(SoftMax)算法[24]是一种经典的概率匹配算法,该使用Gibbs或Boltzmann分布作为描述各项目收益的分布.汤姆森采样(Thompson Sampling,TS)算法[25]也是一种经典的概率匹配算法,该算法使用Beta分布作为描述各项目收益的分布.Exp3算法及其变种[26]是当前应用最为广泛的概率匹配类算法,该算法基于Exp函数构造概率分布,较TS算法和SoftMax算法更精确的描述了项目收益分布,但是当项目数较多时该算法容易收敛到局部最优解.
在微博推荐应用场景下,多数用户兴趣数据稀疏,很难提供大量反馈信息,总时间步数不固定,待推荐项目往往较多,直接将上述3类Bandits算法用于微博推荐的效果不够理想.用户聚类是解决数据的不足的一种有效方法,使用聚类算法构建用户类,把类中用户看作一个整体,能够弥补微博推荐系统中用户反馈数据不足,缓解微博用户的兴趣数据稀疏问题[27,28],结合随机探索类Bandits算法的优势,能够为用户提供有效的个性化微博推荐.
本文将随机探索类Bandits算法解决用户冷启动方面的优势和用户聚类处理稀疏数据的机制相结合,提出一种融合用户聚类与Bandits算法的微博推荐模型(Microblog Recommendation Model Integrating User Clustering and Bandits Algorithm,MRUB).模型通过对用户聚类构建完整用户类,以用户类的兴趣表征普通用户兴趣,降低了用户数据稀疏度;用类内所有用户的历史反馈信息作为Bandits算法的反馈信息,为当前用户生成微博推荐列表,并基于用户对推荐列表的反馈更新历史反馈信息,合理应对新用户冷启动问题.
2 MRUB模型
2.1 用户聚类
在微博关系网络中,对舆论发展起关键性导向作用,并对其他用户有较大的影响力的部分用户,称为重要用户[29].相对于普通用户,重要用户能够为其他用户提供丰富的行为数据,并对普通用户的兴趣产生影响[30].由于普通用户具有数量巨大、兴趣复杂多样的特点,且多数用户个人兴趣数据稀疏,不适宜直接进行兴趣分析.大多数普通用户受网络中相邻重要用户的影响较大,通常与重要用户具有相似或相关的兴趣,因而可以通过对重要用户进行聚类,并将普通用户划分到重要用户类构建完整用户类,进而用普通用户所属类的共同兴趣代表其个体兴趣.
2.1.1 重要用户挖掘
重要用户挖掘算法主要包括HITS算法[31]和PageRank算法[32].相对HITS算法而言,PageRank算法对用户链接关系的敏感度较低,表现较为稳定[33],但传统PageRank算法假定节点的初始权重和边的权重均为1,本文根据微博网络特点对PageRank算法进行改进,用于挖掘重要用户.
1)微博网络边权重的度量
微博网络中用户通过交互行为和关注关系建立联系,交互行为包括转发、评论、点赞等.由于点赞行为具有任意性和随机性[34],可根据用户之间的转发、评论、关注度量微博网络中用户间的关系强度.
令U={ui|i=1,2,…,n}为微博用户集合,用户节点ui和uj之间有向边〈ui,uj〉的权重W(ui,uj)的计算公式如公式(1)所示:
(1)
其中,ω1、ω2、ω3为调和参数,ω1+ω2+ω3=1;TS(ui,uj)表示用户ui转发用户uj的微博数,TS(ui)表示用户ui转发的微博总数;CO(ui,uj)表示用户ui评论用户uj的微博数,CO(ui)表示用户ui评论的微博总数;AU(ui)表示用户ui关注用户数量,若用户ui关注了用户uj,则AU(ui,uj)=1,否则AU(ui,uj)=0.
2)用户PR值初始化
原PageRank算法对网页PR值采用等值初始化方法.由于微博用户间存在很大差异(包括粉丝数、关注数、是否认证等),等值方法未考虑此种差异可能造成的影响,用户影响力贡献值计算不准确,直接用于网络中重要用户的挖掘效果不够理想[35].本文基于用户粉丝数、关注数、发布微博数和是否认证等信息量化用户间差异,对用户PR值进行非等值初始化,用户ui的初始PR值计算公式如公式(2)所示:
(2)
NF(ui)、NA(ui)、NW(ui)分别为用户ui的粉丝数、关注数和发布微博数;n是用户总数;NF、NA和NW为所有用户总粉丝数、关注数和发布微博数;若ui是认证用户,则AT(ui)=1,否则AT(ui)=0;λ1、λ2、λ3、λ4为调和参数,λ1+λ2+λ3+λ4=1.
3)用户排序
基于上述公式(1)和公式(2)的过程,利用公式(3)计算微博用户ui的PR值.
(3)
其中,d是介于(0,1)区间的阻尼系数,一般取值0.85[36];S(ui)表示微博网络中指向用户ui的用户集合;W(uj,ui)为有向边〈uj,ui〉的权重.
在微博关系网络中采用改进后的PageRank算法进行迭代,计算所有用户的PR值,直到迭代前后两次差值低于一定阈值.将网络中所有用户按照迭代结束后的PR值进行排序,取前m个用户作为重要用户,构成重要用户集合V={usk|k=1,2,…,m}.
2.1.2 重要用户聚类
微博用户个人属性是用户个人基本信息或个人偏好的公开信息,通常来自用户填写的个人资料或兴趣标签.本文利用微博用户个人属性信息,采用改进的K-means算法对重要用户进行聚类,构建重要用户类.
1)微博用户个人属性的结构化表示
微博用户个人属性分为基本属性Cu和兴趣属性Ch两类,表示为Cs=
基本属性Cu包括年龄、性别、地点和职业信息4个元素,分别用Age,Gender,Location和Occupation表示,具体描述如下:
其中,Age的取值集合用A表示,由6个年龄段构成,即18岁以下、18~29岁、30~39岁、40~49岁、50~59岁、60岁及以上[37];Gender的取值集合用G表示,由0和1两个元素组成,分表代表女性和男性;Location的取值集合用L表示,由中国七大地理分区以及海外共8个元素构成;Occupation的取值集合用O表示,包含了《中华人民共和国职业分类大典》给出的8大类职业.
兴趣属性包括8个基本兴趣元素,用8元组Ch表示如下:
其中,兴趣Hobbyi取值集合用H表示,由1和0两个元素组成,分别表示有和无此兴趣.
2)改进的K-means算法
K-means算法中K的选取、初始节点的选择、簇中心的计算和用户距离计算对聚类结果影响较大.为使该算法适用于对微博网络重要用户的聚类,从以下4方面改进原始K-means算法.
①K值由实验确定.
②选取重要用户列表中PR值排名前K个重要用户为初始节点.
③簇中心各维度值由簇内成员信息相应元素的众数决定,当众数存在多值时取其中任意一个,以解决标称变量不能直接进行计算的问题,使簇中心与簇内成员具有相同的信息元素.
④在重要用户个人属性的结构化表示中,Csi中元素均为标称变量(性别和兴趣等二元变量可看做是特殊的标称变量).因此,广泛应用于聚类的传统K-means算法无法以其相似度计算方法度量不同用户个人属性之间的距离.本文利用相异度矩阵来描述用户之间的差异,用户集合V的相异度矩阵由V中两两用户间的个人属性相异度d(Csi,Csj)构成,d(Csi,Csj)的计算如公式(4)所示:
d(Csi,Csj)=(1-α)d2(Csi,Csj)+ad1(Csi,Csj)
(4)
其中,α为调和参数,用于调和基本信息和兴趣信息所占比重,α越大,基本信息所占比重越大,α越小,兴趣信息所占比重越大.d1(Csi,Csj)、d2(Csi,Csj)分别为基本信息和兴趣信息相异度,其计算如公式(5)所示:
(5)
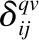
改进的K-means算法的步骤为:
a)选取重要用户列表中PR值排名前K个用户作为初始簇的簇中心点.
b)计算每个重要用户的信息与各簇中心的相异度,将用户划分到相似度最大的蔟中.
c)用簇内成员各信息元素的众数更新每个簇的中心点.
d)重复步骤b)和步骤c),直到每一个簇中心在每次迭代后变化不大为止.由簇中心的信息表示簇属性.
利用上述算法对重要用户集合V中的所有用户进行聚类,得到K个重要用户类D1,D2,…,Dk.
2.1.3 完整用户类构建
根据微博中用户关注和个人属性计算普通用户ugi与重要用户类Dj的相似度,如公式(6)所示:
S(ugi,Dj)=θd(Csi,Csj)+(1-θ)au(ugi,Dj)
(6)
其中,d(Csi,Csj)是用户ugi与类Dj的个人属性相异度,根据公式(5)计算;Csi为用户ugi的个人属性集合,Csj为类Dj中心的个人属性集合,其元素为类Dj中所有用户的个人属性集合中对应元素的众数.au(ugi,Dj)是用户ugi与类Dj中用户的关注关系,计算方法如公式(7)所示:
(7)
其中,z为用户类Dj中用户的数量,v为在类Dj中用户ugi所关注的用户数量;θ是调和参数,用于调和用户与类中用户的关注关系和用户与类的个人属性相异度所占的比重.
根据公式(6)计算普通用户与各重要用户类的相似度,得出相似度排名列表,将普通用户加入到相似度大于阈值的重要用户类中构成完整用户类.一个普通用户可能具有多种兴趣,因此可能同时属于多个完整用户类,一个完整用户类的兴趣仅代表普通用户兴趣的一个分量.每个重要用户只属于一个完整用户类.
2.2 微博推荐
2.2.1 Bandits微博推荐列表生成方法
利用2.1.3节方法产生的完整用户类,根据多个类中用户的历史数据产生推荐列表,为一个普通用户推荐微博.本文借鉴Ranked Bandits算法[38]思想提出一种Bandits微博推荐列表生成方法.
经典多臂老虎机问题中包含h个拉杆,玩家每次只能选择其中一个拉杆,每个拉杆都有一定概率获得收益,n轮尝试过后,玩家的目标是获得最大收益期望值[14].将多臂老虎机用于微博推荐,其基本思想是将待推荐给用户的h条微博定义为h臂老虎机的h个拉杆,每次推荐相当于一次拉动老虎机拉杆的动作,每次推荐后用户是否点击了所推荐的微博(用户反馈)相当于在拉动某一拉杆时是否获得了收益.Bandits算法为当前用户生成待推荐微博分数排名列表,选择分数最高的一条微博推荐给用户.每条微博的分数由其历史推荐给当前用户的次数和用户对推荐的反馈等信息决定.本次推荐和反馈又同时作为以后为用户推荐微博的参照信息,具有一定的动态性.
然而,现有Bandits算法[18-26]每次只能为用户提供一条微博,不满足实际微博推荐场景中用户对微博数量的需求.本文提出的Bandits微博推荐列表生成方法一次可为用户推荐多条微博,其核心思想如下:
1)为每个完整用户类运行一个Bandits算法实例,实例之间相互独立,实例所需信息由类内所有用户共同提供.
2)假设普通用户ugi与其所属类相似度排序为D1,D2,…,Dm,推荐列表中第k项微博由类Dk%m所运行的Bandits算法实例产生.
3)为保证推荐列表中不会出现重复的微博项目,每产生一项待推荐微博后,在所有类中暂时删除该微博及其历史反馈信息,推荐列表中所有项目全部生成后恢复所有删除的微博和信息.
4)根据用户对推荐列表中各项微博的喜好产生反馈信息,每条反馈信息记录到产生该项的算法实例所属类的历史反馈信息中.
根据对Bandits微博推荐列表生成方法的描述,可知各Bandits算法均可应用此方法为用户产生推荐列表,不同Bandits算法对推荐效果产生的影响不是本文研究重点,仅选用在实际应用中表现较好的ε-Greedy算法[24]作为模型推荐算法进行分析.
2.2.2 融合用户聚类和Bandits算法的微博推荐模型
本文提出的融合用户聚类和Bandits算法的微博推荐模型中,为用户推荐微博的过程主要包括以下3个阶段,如图1所示.
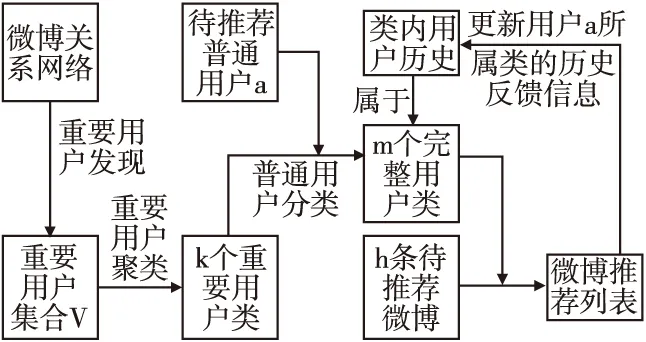
图1 基于用户聚类和Bandits算法的微博推荐模型框架Fig.1 Microblog recommendation model frameworkbased on user clustering and Bandits algorithm
1)用户类挖掘阶段.首先,利用针对微博网络改进的PageRank排序算法发现重要用户;然后,基于个人属性改进的K-means聚类算法对重要用户聚类构建重要用户类;最后,根据普通用户与各个类的相似度构建完整用户类.
2)微博推荐阶段.采用Bandits微博推荐列表生成方法,根据当前普通用户所在完整用户类内所有用户历史数据生成推荐列表.
3)反馈阶段.当前普通用户根据个人喜好对推荐列表进行信息反馈,使用反馈信息更新此用户在其所属类中的历史数据.
2.2.3 MRUB模型的改进
类兴趣往往与用户兴趣有一定偏差,一般仅可作为用户个人兴趣的补充,不能完全替代个人兴趣.综合利用类兴趣和个人兴趣进行推荐更符合实际用户需求.结合概率思想,构造概率函数模拟类兴趣与个人真实兴趣的偏差,实现对MRUB模型微博推荐方法的改进.本文构造概率函数如公式(8)所示,我们把应用这种推荐方法的模型称之为改进融合用户聚类和Bandits算法的微博推荐模型(MRUB-New).
(8)
其中,P(ugi)为利用用户自身历史数据为用户ugi推荐的概率,t为当前推荐次数,tmax为算法达到平衡的次数,tmin为与随机推荐相比有明显差异的最小次数,f(t)为单调递减函数如公式(9)所示:
(9)
其中,u为正整数,根据实验数据得出.
3 实 验
3.1 实验数据
因为目前没有统一、权威的微博数据集可供使用,本文的实验数据通过爬虫工具后羿采集器从新浪微博平台抓取.采集策略为:随机选取来自科技、艺术、健康、军事、历史、体育、财经和国际8个领域的120个微博用户作为种子节点,利用雪球采样的爬行策略,顺着种子节点的转发和评论用户链向外爬行扩展一层,最终获取207919个用户的转发和评论微博数据,共计362418条.此外,实验数据还包括这些用户的历史关注、粉丝、发布数量及用户之间的关注关系.
3.2 评价标准
3.2.1 聚类效果评价标准
本文采用误差平方和(SSE)作为聚类结果的标准.SSE值表示所有用户到其所在类的中心的距离之和,SSE值越低,类内用户相似性越高,聚类效果越好,计算公式如式(10)所示:
(10)
其中,ci表示簇Ci的聚类中心,dist(p,ci)表示簇Ci中的对象p与ci的距离.
3.2.2 推荐评价标准
为了评价微博推荐方法的性能,采用Bandtis算法性能衡量中较常使用的点击率(CTR)、累积遗憾(CumReg)和平均遗憾(AvgReg)作为评价指标.采用Kleinberg[32]提出的评价思想,在离线数据集模拟动态测试过程,不划分训练集和测试集,在整个数据集上计算点击率和累积遗憾随迭代增加的变化情况,衡量算法性能,如公式(11)~公式(13)所示:
(11)
(12)
(13)
其中ri为第i次推荐的真实反馈,mi为第i次推荐最佳微博的反馈值,N为总推荐次数.CTR表示推荐的微博得到用户反馈的次数占总推荐次数N的比值,最大值为1.CumReg表示推荐N次真实推荐反馈与最佳反馈的累积误差,AvgReg表示推荐N次真实推荐反馈与最佳反馈的平均误差.CTR越大说明推荐算法给用户推荐的微博得到用户反馈比例越高,CumReg、AvgReg越小则说明推荐的微博越接近用户最喜爱的微博.
3.3 参数确定
3.3.1 PageRank初始值权重确定
粉丝数、关注数、发布微博数和微博认证的权重采用层次分析法(AHP)[39]中成对比较矩阵和一致性检验的方法确定.对λ1,λ2,λ3,λ4进行两两比较,得到的判定矩阵如表1所示.判定矩阵的最大特征值为4.031,对应的特征向量为:wb1=0.2772,wb2=0.0954,wb3=0.4673,wb4=0.1601(0.2771, 0.0960,0.1611,0.4658),其每一维的值分别对应粉丝数、关注数、发布微博数和微博认证的权重,即λ1=0.2771,λ2=0.0960,λ3=0.1611,λ4=0.4658.

表1 判定矩阵1Table 1 Decision matrix 1
3.3.2 用户关系权重确定
转发数、评论数和关注数的权重采用层次分析法(AHP)中成对比较矩阵和一致性检验的方法确定[39].对进行两两比较,得到的判定矩阵如表2所示.判定矩阵的最大特征值3.000,对应的特征向量为:wb1=0.2772,wb2=0.0954,wb3=0.4673,wb4=0.1601(0.2857, 0.1429, 0.5714)其每一维的值分别对应转发数、评论数和关注数的权重,即ω1=0.2857,ω2=0.1429,ω3=0.5714.

表2 判定矩阵2Table 2 Decision matrix 2
3.3.3 聚类调和参数的选取
χ为调和参数,用于调和兴趣信息和基本信息所占比重.χ越大,基本信息所占的比重越大;χ越小,兴趣信息所占的比重越大.不同的数据集下,参数χ的取值应该不同,针对本文的实验数据集,通过实验来确定参数χ的取值.计算χ=0.125,0.25,0.375,…,0.875时聚类效果指标SSE,结果如图2所示.
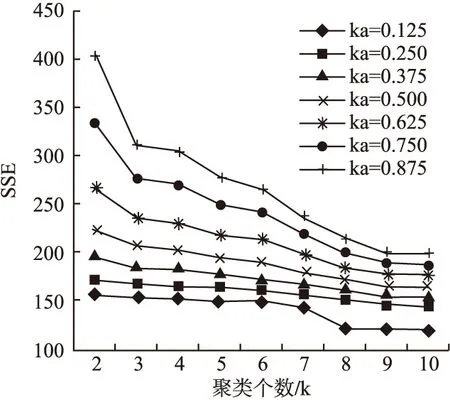
图2 不同χ下SSE值比较Fig.2 Comparison of SSE values under different conditions
从图2可以看出,当χ=0.125时在2~14聚类数条件下均取到最小值,故后续在参数χ=0.125下,确定聚类个数K的取值.
3.3.4 肘方法确定聚类数目
实验采用肘方法(Elbow Method)确定K的取值.肘方法基于以下观察:增加簇数有利于降低平均畸变程度,因为更多的簇意味着可以捕获更细的数据对象簇,使得簇中对象更加相似.因此,确定簇数的正确方法是,使用簇内距离和关于簇数曲线的拐点作为簇的数目.具体为,给定K>0绘制簇内方差和SSE关于K的曲线,曲线的第1个拐点即为正确的簇数.
针对本文数据集,从K=2开始,每次递增1计算以确定K的取值.SSE随K值的增大变化情况如图3所示.从图中可以看出,当K从7增加到8时,SSE急剧下降;当K从8以后,SSE趋于稳定,K=8为曲线的拐点,故选取K=8.
图3 肘方法确定最佳K值Fig.3 Elbow method to determine the best K value
3.3.5 模型中参数ε的影响
为确定参数ε的取值对推荐结果的影响,在本文实验数据集上,取不同的ε值,分别记录MRUB-New模型在10000个随机用户任务的CTR值和AvgReg值.
首先,在闭区间[0.001,1]以10的倍率分别取4组不同的ε值.各参数下的CTR值和AvgReg如图4所示,随着ε的增加,CTR呈现先增加后减少的趋势、AvgReg呈现先减少后增加的趋势.当参数ε=0.1时CTR值最高,AvgReg值最低,但参数ε=0.01时也取得了较高的CTR和较低的AvgReg.基于图4的数据,可以猜测,ε∈[0.01,0.1]时模型的推荐效果较好.

图4 不同ε值下MRUB-New模型的CTR和AvgRegFig.4 CTR and AvgReg of MRUB-New model in different ε values
为进一步研究参数ε∈[0.01,0.1]时,MRUB-New模型的性能,下面以0.01为间隔分别取10组不同的值展开实验.表3给出了对应的实验结果数据,黑体部分是效果最好的参数及结果.
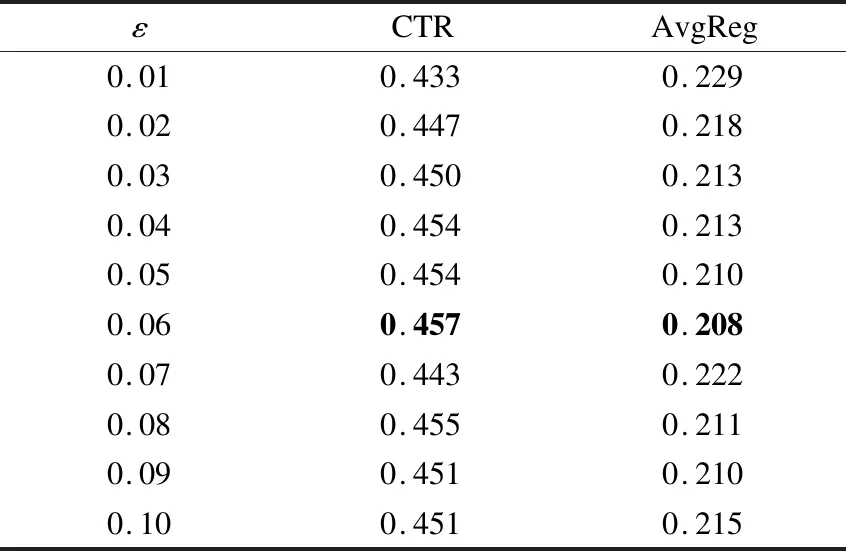
表3 模型的CTR和AvgReg(ε∈[0.01,0.1])Table 3 CTR and AvgReg of modle(ε∈[0.01,0.1])
基于图4和表3的数据,当MRUB-New中参数ε=0.06时CTR最大,且AvgReg最小,推荐效果最好,故在本文实验环境下ε取值为0.06.
3.4 对比实验
实验中涉及的算法和模型的简写、参数及解释如表4所示.
为验证微博推荐方法的有效性和准确性,首先验证推荐列表长度不同对推荐效果的影响,然后在本文数据集上进行对比实验,以CTR和CumReg为评定标准比较3类Bandits算法与本文提出的模型的算法性能.图5和图6为上述方法在 Top5推荐列表结果下的CTR和CumReg.
3.4.1 推荐长度对性能的影响
微博推荐数的不同会对推荐的性能造成影响,实验在推荐长度为1~10的情况下在不同迭代次数时观察推荐模型的性能.表4为MRUB-New模型在Top1~Top10推荐结果下的CTR值.对于微博用户来说,一次推荐往往只有前几条会被认真阅读,故推荐条数不宜过多.根据表5所示,在所有迭代次数的条件下,CTR大体随推荐长度的增加呈现出递增的趋势,但是Top5之后有明显放缓的,且有所反复,与最大值差距不超过0.003.基于本实验结果,Top5推荐较为合适,故选择一次给用户推荐5条微博.

表4 模型和算法的简写、参数及其描述Table 4 Abbreviations,parameters and descriptions of models and algorithms
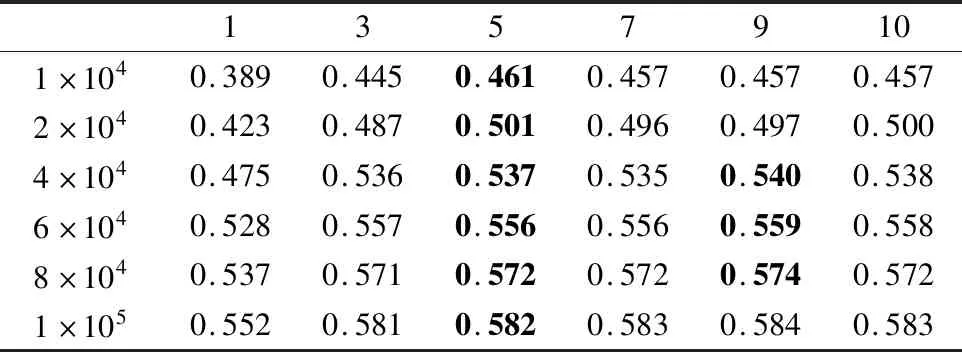
表5 MRUB模型在Top1~Top10推荐结果下的CTRTable 5 CTR of MRUB model under Top1 to Top10 recommendation
图5和图6为本文模型与3类Bandits算法在Top5推荐结果下的CTR和CumReg.
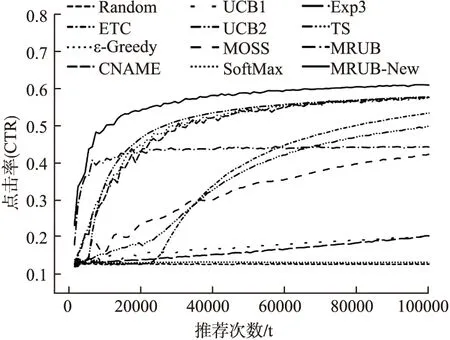
图5 MRUB、MRUB-New和3类Bandis算法在Top5推荐结果下的CTRFig.5 CTR under MRUB-New、MRUB and 3 Bandits algorithms in Top5 recommendation
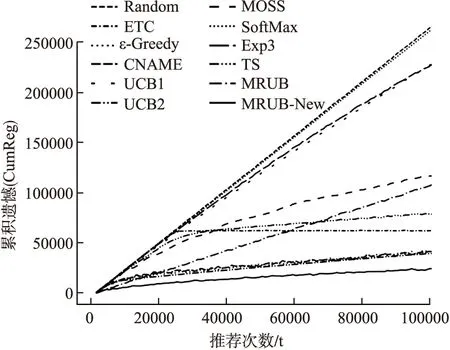
图6 MRUB、MRUB-New和3类Bandis算法在Top5推荐结果下的CumRegFig.6 CumReg under MRUB、MRUB-New and 3 Bandits algorithms in Top5 recommendation
3.4.2 MRUB模型、MRUB-New模型比较
第1项实验用于比较融合用户聚类和Bandits算法的微博推荐模型(MRUB)和改进融合用户聚类和Bandits算法的微博推荐模型(MRUB-New)的微博推荐方法的性能.
从图5中可以看出在参数ε相同的条件下MRUB-New模型收敛速度略低于MRUB模型,但MRUB-New模型的CTR值和CumReg值均高于MRUB模型推荐效果.
这是因为MRUB-New模型综合利用用户所在类用户反馈数据和用户个人反馈数据,较MRUB模型仅利用用户所在类用户的反馈数据在用户个人数据充足的情况下准确率较高,但个人反馈较类反馈速度随时间步增长较慢,故MRUB-New模型收敛速度低于MRUB模型.
3.4.3 MRUB-New模型和随机探索类算法比较
第2项实验用于比较随机探索类Bandits算法(Random、ETC、ε-Greedy和CNAME)和本文提出的改进模型(MRUB-New)的微博推荐性能.
从图5、图6中可以看出MRUB-New模型收敛速度略高于ε-Greedy算法和CNAME算法,但其CTR高于Random算法、ETC算法、ε-Greedy算法和CNAME算法,最少提升约5.62%,且CumReg低于上述算法.故MRUB-New模型的推荐效果较随机探索类Bandits算法有所提高.
这是因为MRUB-New模型在一次推荐中利用整个类用户的反馈数据或用户个人反馈数据,相比于仅利用用户个人反馈数据的ε-Greedy算法和CNAME算法有更多的数据支持,故收敛速度有所提高.同时由于MRUB-New考虑了用户所在类的反馈数据,比随机探索类算法更精确刻画了用户的兴趣,推荐效果有明显提升.
3.4.4 MRUB-New模型和置信区间类算法比较
第3项实验用于比较置信区间类Bandits算法(UCB1、UCB2和MOSS)和本文提出的改进模型(MRUB-New)的微博推荐性能.
从图5、图6中可以看出MRUB-New模型收敛速度与UCB2算法相当,但其CTR值高于UCB1算法、UCB2算法和MOSS算法,最少提升约5.43%,且CumReg较低.故MRUB-New模型的推荐效果优于上述置信区间类算法.
这是因为UCB2算法总是每次为一个用户推荐多次相同的项目以增加反馈数据,故UCB2算法可以达到与MRUB-New模型相当的收敛速度,但这也一定程度上损失了推荐项目的多样性.除此之外置信区间类算法需要在初期的前n×K次操作中,将每个用户的每个动作轮流选择一遍,这不符合微博用户的习惯,也一定程度上降低了推荐效果.
3.4.5 MRUB-New模型和概率匹配类算法比较
第4项实验用于比较概率匹配类Bandits算法(SoftMax、Exp3和TS)和本文提出的改进模型(MRUB-New)的微博推荐性能.
从图5、图6中可以看出MRUB-New模型无论从收敛速度、平衡后的CTR值,还是CumReg方面均较概率匹配算法有明显提升,其中CTR值最少提升约33.37%.故MRUB-New模型的推荐效果优于概率匹配类算法.
这是因为无论在任何情况下概率匹配类算法都会给每一个项目一定被选择概率,当项目较多且历史数据较少时较优的项目往往会被淹没在众多平庸项目中,不能获得更高的优先选择权.在微博环境下,待推荐微博数量往往较多,概率匹配类算法很难取得较好的推荐效果.
综上可知,MRUB-New模型是一种有效的Bandits微博推荐模型.
4 总 结
针对微博推荐过程中新用户冷启动和数据稀疏问题,将Bandits算法和用户聚类方法的优势相结合,提出了MRUB和MRUB-New微博推荐模型.该模型提高了推荐结果的准确性,给微博用户提供较为精准的动态微博推荐.与现有各类Bandits算法相比,该模型的推荐效果在一定程度上有所提升.但本文未考虑类兴趣在推荐过程中可能产生的变化,导致推荐结果可能存在偏差.未来将围绕兴趣动态更新、普通用户与各类的隶属度等方面开展深入的研究.
