基于侦察学习策略的粒子群算法优化
2022-10-13刘衍民杨妹兰舒小丽
张 倩, 刘衍民, 杨妹兰, 舒小丽
(1.贵州大学 数学与统计学院, 贵阳 550025;2.遵义师范学院 数学学院, 贵州 遵义 563006; 3.贵州民族大学 数据科学与信息工程学院, 贵阳 550025)
0 引 言
群智能优化算法衍生于生物群体行为,其中,粒子群算法(PSO)[1]由于其并行性高,全局搜索性强等优点,被广泛应用于配电网输送[2]领域,但此算法在迭代过程中易出现“早熟”现象。
为消除这一弊端,研究者对PSO算法进行了多方向改进。一是结合PSO算法与其他优化算法。文献[3]将差分进化算法(DE)的突变过程与PSO算法结合,此方法保证了粒子的多样性,但其计算复杂度却大大增加。文献[4]将PSO算法、生物地理信息优化算法(BBO)[5]以及侦察学习策略三者互相融合,这样虽然满足算法对结果精度的需求,但降低了算法的收敛速率。二是对粒子间的信息交流进行改进。文献[6]提出全信息PSO算法(wFIPS)。根据群体粒子经历的最优值和其邻域中表现优异的粒子分量调整粒子速度,达到对粒子信息的“充分了解”,此算法在一定程度上提高了PSO算法的局部搜索性能,但是其局部搜索能力和全局搜索能力并未均衡。文献[7]提出了合同协作PSO算法(CPSO)。该算法利用多个群体进行不同粒子间的交叉操作,改进粒子间的信息交换过程,此算法在增加粒子间信息交流的基础上,造成了数据大量冗余。
为改善这些不足,本文提出了一种结合拓扑结构与侦察学习策略的新型PSO算法(BUPSO),通过实验对比分析,该算法可兼顾算法的局部搜索能力和全局搜索能力,在提高算法收敛速率的同时规避算法陷入“早熟”现象,提升了算法的整体性能。
1 算法基础理论
1.1 标准粒子群算法
在标准粒子群算法中,假设当前种群规模为N,维度为D,粒子的位置表示为xi={x1,x2,x3,…,xN},速度表示为vi={v1,v2,v3,…,vN},整个搜寻过程如式(1)、式(2)所示:
(1)
(2)
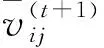
1.2 侦察学习策略
PSO算法只有粒子的学习阶段,若在此阶段对粒子的速度和位置进行多次迭代,算法搜索能力会因此降低而导致粒子群体在某一局部极值点停滞。因此,寻找一种合适的策略,使得算法跳出局部收敛显得尤为重要。文献[4]将侦察学习策略引入PSO算法。若PSO算法经过数次迭代后发现最优解的位置未被更新,则通过侦察学习策略产生新解,产生过程如式(3):

(3)
其中,xij代表粒子i在第j维产生的随机位置,xmaxj,xminj代表侯选解的范围,r为[0,1]的随机数。
2 结合拓扑结构和侦察学习策略的新型粒子群算法
2.1 基于拓扑结构的种群构建
粒子群体应用不同的拓扑结构,粒子间的信息交流方式与信息交流量也不同。以All型、Ring型为例,Ring型拓扑结构中粒子间的交流局限于相邻两粒子间,而All型拓扑结构中所有粒子可实现互相交流。两类拓扑结构如图1和图2所示。

图1 Ring型结构Fig.1 Ring-type structure

图2 All型结构Fig.2 All-type structure
依据种群粒子间信息交流量的不同,可将搜索方式分为局部版本和全局版本。若群体中所有粒子均产生信息交换,则为全局版本。PSO算法使用的即为All型全局版本搜索方式。若粒子的信息交流局限于邻居粒子中,则为局部版本。文献[8]指出Ring型拓扑结构收敛精度与收敛速率最高,因此本算法应用Ring型局部版本搜索方式。两种搜索方式的不同之处在于粒子的速度更新方式不同,局部版本速度的“社会认知”项由邻居中表现最好的粒子引导,而全局版本速度的“社会认知”项由群体中表现最好的粒子引导。式(4)、式(5)分别代表全局搜索版本以及局部搜索版本的粒子速度。具体表述如式(4)、式(5):
(4)
(5)

局部版本搜索方式有利于粒子勘探更优质解,而全局版本搜索方式有利于粒子开发新区域。为充分融合两种搜索方式,本文引入联合因子m这一指标将两种搜索方式均衡结合,既能保证粒子搜索的广度,又可满足算法的整体收敛精度。两种搜索的结合方式如式(6):
(6)
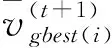
此外,为模拟生物进化算法中的突变过程,规避算法陷入局部最优的风险,本算法引入随机参数r3。文献[9]指出当r3均值为0,标准差为0.01的正态分布随机向量且m取0.1时,该算法收敛于全局最优值的效果更优。此更新过程如式(7):
(7)
2.2 侦察学习策略的引入
传统的侦察学习策略会在确定范围内随机更新粒子位置,因而无法加强粒子间的信息交流,导致算法的运算效率降低。故此,本文对侦察学习策略进行了相应改进,引入了粒子的速度公式,并在粒子位置公式中引入新变量,以确保该粒子做到绝对更新,增加粒子寻求到最优解的概率以及侦察学习策略在本文中的普适性。为了方便描述,用xi表示产生坏解的粒子,xj表示更新后的粒子。此阶段的改进思想如下:

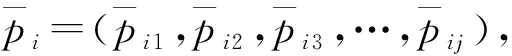
改进的侦察学习策略阶段的速度和位置公式如式(8)、式(9):
(8)
(9)
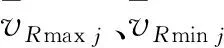
虽然如式(9)所示,新产生的粒子位置没有超出粒子的位置下界,但是不排除粒子飞出位置上界的可能。所以,为将粒子的位置限定在[Vmin,Vmax],在此公式后加入粒子的位置边界处理条件。若粒子位置超出边界,则抛弃掉此粒子,进入下一次搜寻过程,以保证运算结果的有效性和准确性。同时,为了方便记录最优解未被更新的次数,每个最优解都设一个标记参数。若参数的数值达到阈值,则通过式(8)、式(9)产生候选解,并将此参数重置为0;否则参数加1,并进入下一次迭代。此策略可有效规避算法过早收敛的问题,有助于算法寻求到更有效的解。
2.3 算法模型
环形拓扑结构可提高粒子收敛于全局最优解的效率,而侦察学习策略可扩大粒子的全局搜索范围。因此,将PSO算法与环形拓扑结构以及侦察学习策略的优点相互融合,形成一种基于拓扑结构并且结合侦察学习策略的新型PSO算法(BUPSO)。此算法以PSO算法为主框架,构建环形结构粒子群体,同时结合侦察学习策略对粒子速度和位置进行改进,以增加粒子种群的多样性,避免PSO算法陷入“早熟”问题。BUPSO算法运行流程如图3所示。
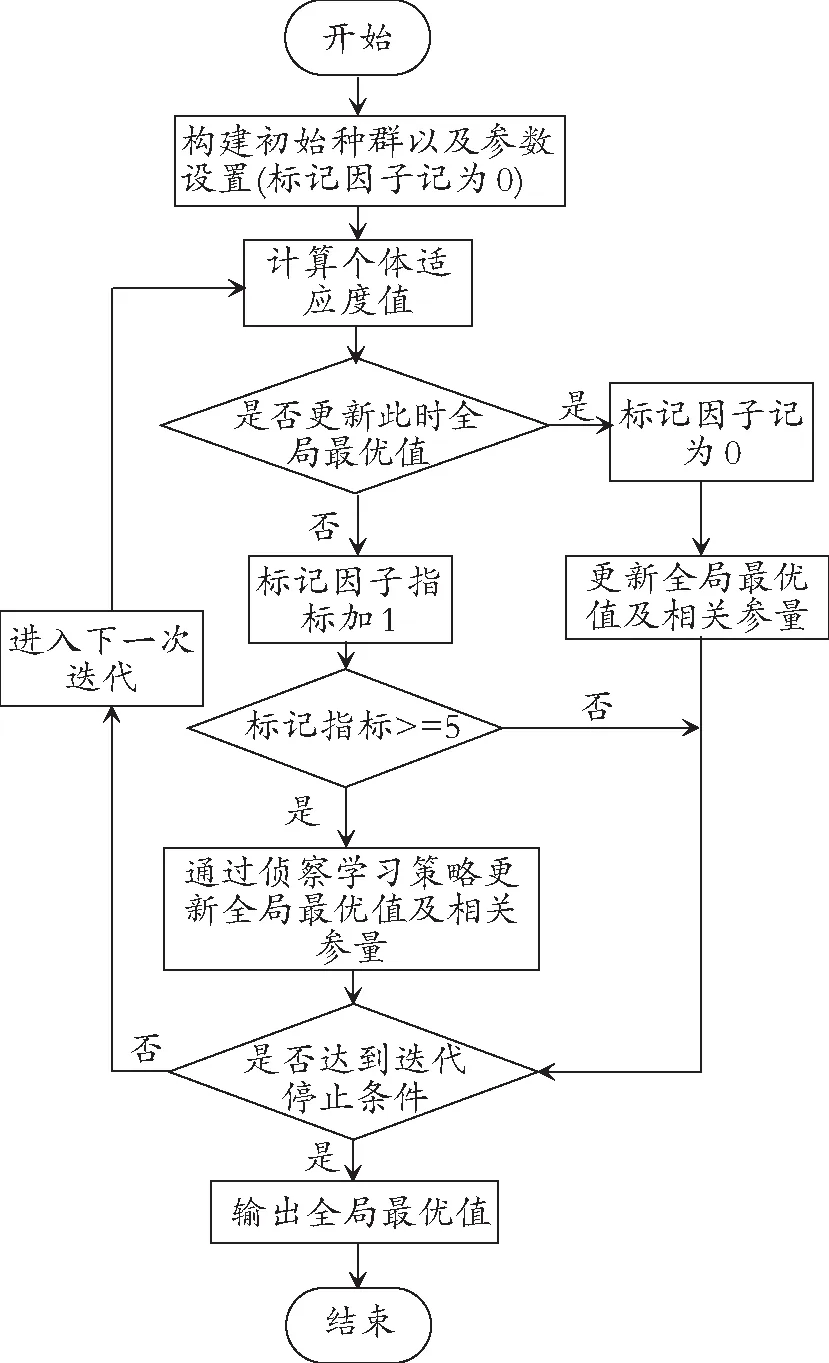
图3 BUPSO算法流程图Fig.3 Flow chart of BUPSO
其步骤可总结如下:
1) 种群初始化,包括参数设置和种群构建。参数设置包括标记因子、最大飞行速度、种群规模以及粒子边界条件,群体结构设为环形拓扑结构,标记因子阈值设为5;
2) 计算个体适应度值;
3) 判断是否更新全局最优值;
4) 若更新全局最优值,标记因子重置为0;否则加1;
5) 若标记因子重置为0,则将粒子的全局最优值以及全局最优变量更新,并转到步骤7;若标记因子加1,则判断标记因子是否超过阈值;
6) 若标记因子超过5,则粒子通过侦察学习策略更新全局最优值以及相关参量;否则,进入下一迭代过程,返回步骤2);
7) 判断是否达到迭代停止条件。若达到迭代停止条件则输出最优解并结束算法;否则,返回步骤2)。
2.4 算法复杂度分析
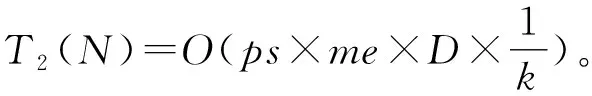
3 实验仿真分析
3.1 实验参数设置
选取BUPSO算法、CLPSO算法[9]、UPSO算法[10]、PSO算法、wFIPS算法在CEC2017检测函数[11]旋转环境和非旋转环境下进行收敛性和鲁棒性对比分析。其中,用“*”表示对检测函数进行旋转。选取的检测函数包括:Rosenbrock′s函数、Griewank′s函数、Levy函数、HappyCat函数、Expanded Griewank′s plus Rosenbrock′s函数、Zakharov函数、Rastrigin′s 函数、Expanded Schaffer′s F6函数。
5种算法均设置同一参数:种群规模为30个粒子、9×104次函数评价、独立运行20次。其他参数设置与上文描述一致。
3.2 收敛性能分析
为检验BUPSO算法的优化效果,在确定的函数评价次数下对不同算法的收敛特性进行对比。如图3和图4所示,给出了5种算法在同一检测函数下不同环境中的收敛特征图。此外,本文选用两种方式对算法性能测评比较。其一,通过不同算法在同一测试函数下的最小值(Min)、均值(Mean)以及方差(Std)进行比较分析,判定算法的稳定性和搜索精度;其二,在α=5%的显著水平下,对50次独立运算下的BUPSO算法与其他4种算法进行Wilcoxon秩和检验,判定算法在结果上的优越性。其中,p代表BUPSO算法与其他4种算法最优结果是否具有显著差异。p=0表示结果无显著差异,p=1代表结果有显著差异。以部分函数为例,非旋转环境下的实验结果见表1,旋转环境下的实验结果见表2,秩和检验结果见表3。
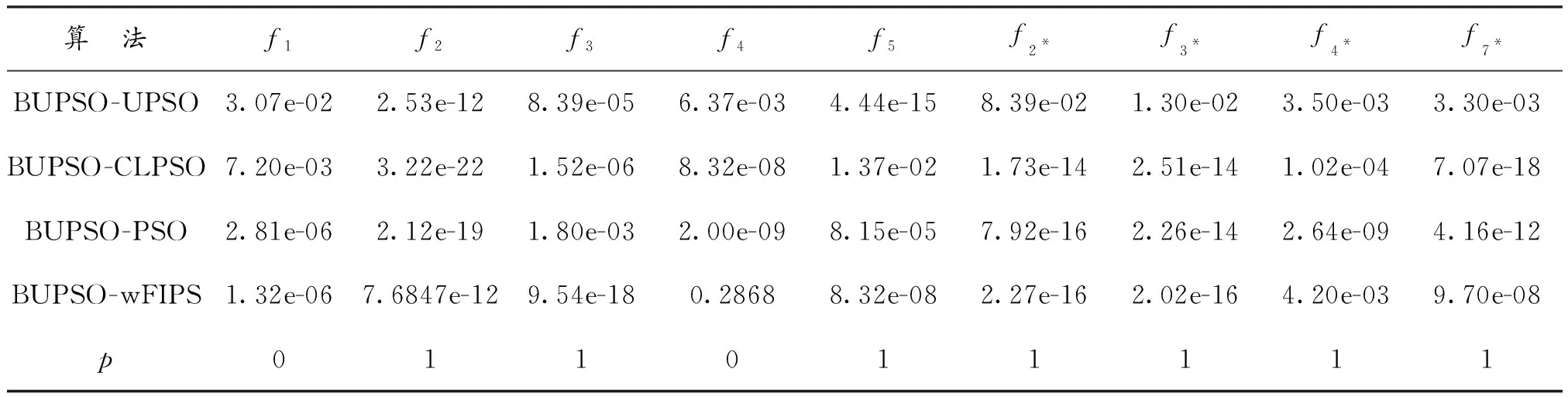
表3 Wilcoxon秩和检验p值Table 3 P values of Wilcoxon rank sum test
如表1和表2所示:数据表中加粗部分代表各算法在不同测试指标下通过对比产生的最小值。针对这些函数,该算法的值基本上达到最小,说明该算法的性能较优。无论检测函数在旋转环境还是非旋转环境下,从Min指标来看,除了旋转环境下的f4检测函数,BUPSO算法的结果更接近于最优值;从Mean指标来看,该算法相比其他算法均值更小,说明运行多次,该新型算法的求解精度更好;从Std指标来看,此算法的标准方差更小,说明算法每次运算得到的数值相对较稳定,说明该算法的收敛性能较好,且比较稳定。
如表3所示:将该新型算法与其他算法的最优结果进行Wilcoxon秩和检验,通过p值发现在对测试函数f1和f4进行秩和检验时,p值为0;在其他测试函数进行对比检验,发现其p值为1,说明除了检测函数f1和f4,BUPSO算法结果与其他4种算法最优结果的差别在95%的置信区间内有统计意义,进而表明算法的优越性在统计上是显著的。
如图4所示:BUPSO算法在求解多峰函数方面,尤其对于Rosenbrock′s 函数、Griewank′s函数、Levy 函数、HappyCat 函数、Expanded Griewank′s plus Rosenbrock′s 函数、Rastrigin′s 函数、Expanded Schaffer′s F6 函数,在收敛结果和收敛速率方面都表现突出,说明此算法对求解多峰函数具有明显优势;同样,在求解单峰函数方面,对于Zakharov 函数,发现其收敛精度与收敛速率相较于其他算法,表现更优。
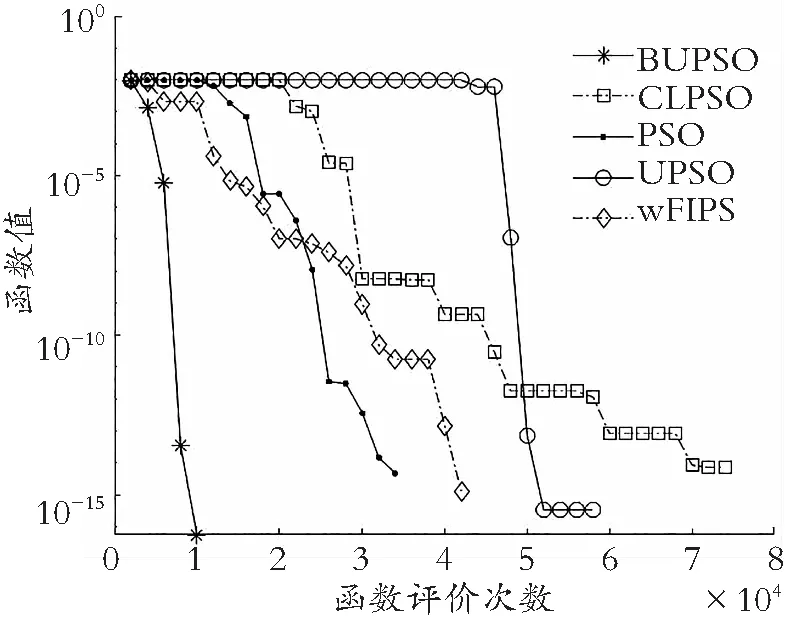
如图5所示:在旋转环境下,无论多峰函数还是单峰函数,BUPSO算法都表现出良好的收敛性能。结合图4和图5,算法在前期过程的收敛曲线明显比其他4种算法的收敛曲线下降更快,说明BUPSO算法与拓扑结构的结合提升了解的质量。此外,由收敛曲线整体趋势可得,侦察学习策略的引入,明显提高了算法的求解能力,说明BUPSO算法相较于其他算法跳出局部最优空间的能力显著。
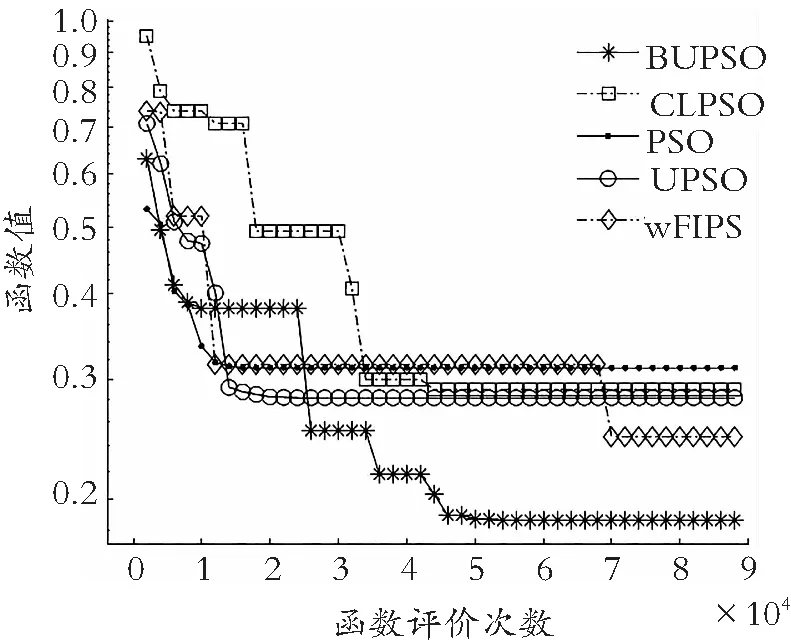
(a) Happy Cat函数
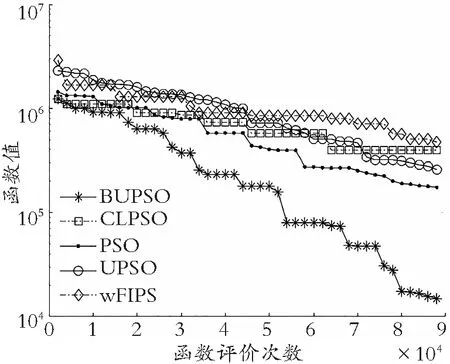
(b) Zakharov函数
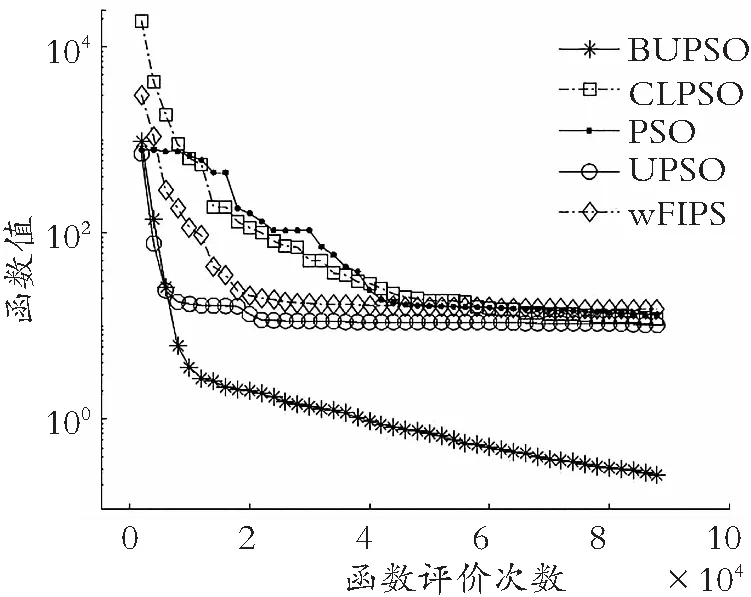
(c) Rosenbrock′s function函数
(d) Expanded Schaffer′s F6函数

(e) Levy函数

(f) Expanded Griewank′s plus Rosenbrok′s函数
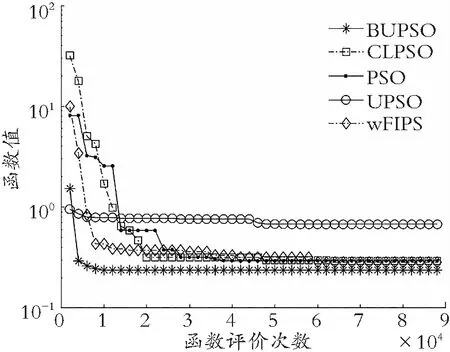
(g) HGBat函数图4 非旋转检测函数收敛特征图Fig.4 Convergence features of non-rotating detection functions
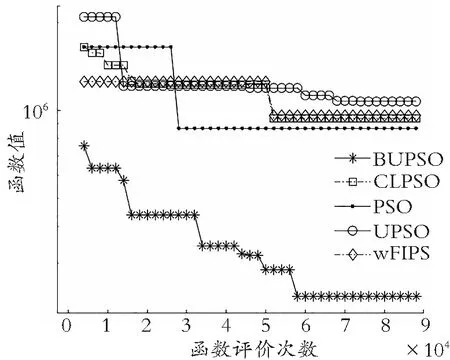
(a) Zakharov函数

(b) Non-continuous Rotated Rastrigin′s函数

(c) Grivwank′s函数
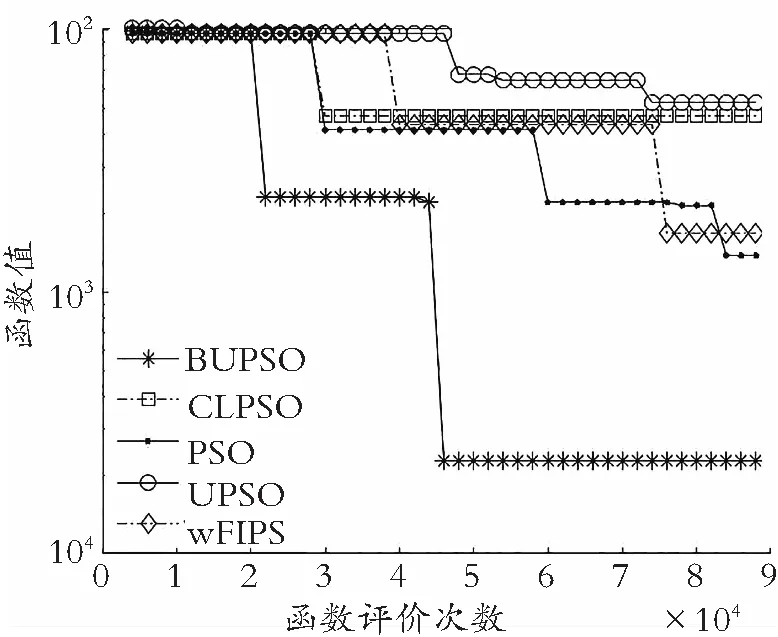
(d) Expanded Schaffer′s F6函数

(e) EXpanded Griewank′s plus Rosenbrok′s函数
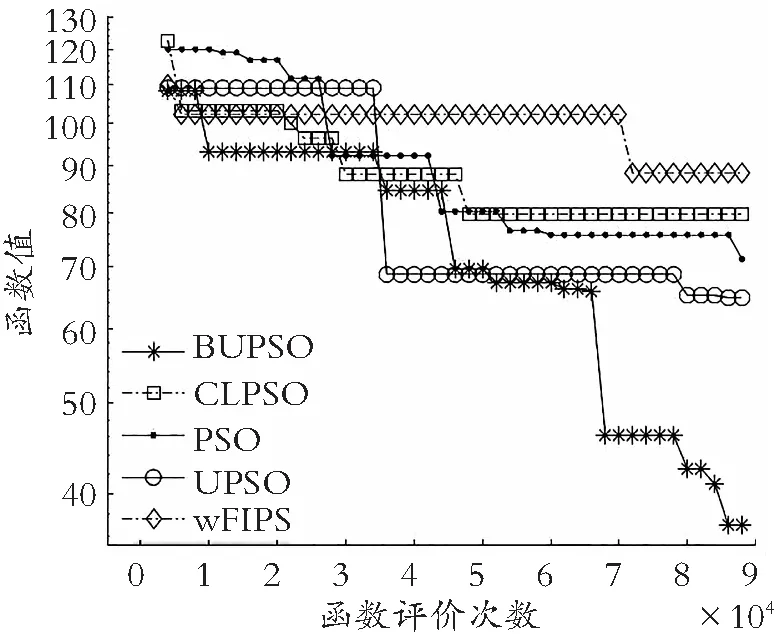
(f) Rastrigin′s函数图5 旋转检测函数收敛特征图Fig.5 Convergence features of rotation detection functions
3.3 鲁棒性分析
为探测5种算法的运行稳定性,每次运行都选用同一测试函数在不同的环境下进行测评比较。以Griewank′s 函数、Zakharov函数、Expanded Schaffer′s F6函数为例,表4给出了算法的鲁棒性分析。这里的鲁棒性分析指各算法独立运行50次,在算法评价次数内所得到的全局最小值达到给定阈值的水平。FEs代表达到给定阈值时算法的评价次数,S代表在算法评价次数内所得到的全局最小值达到给定阈值的比例,给定的阈值分别为1e-15、2.5e+04、1e-15、50、2e-04、1e+06。

表4 各种算法的鲁棒性分析Table 4 Robustness analysis of various algorithms
如表4所示:在非旋转环境下,对于Griewank′s函数,CLPSO算法和BUPSO算法都100%达到了阈值,但BUPSO算法比CLPSO算法用了较少的函数评价次数,对于Zakharov函数和Expanded Schaffer′s F6函数,仅BUPSO算法成功达到阈值且评价次数最少;在旋转环境下,对于Expanded Schaffer′s F6函数,CLPSO算法与BUPSO算法都达到了阈值,对于Zakharov函数和Griewank′s函数,只有BUPSO算法达到了阈值,且该算法对Zakharov函数的评价次数最少。
总之,不论从算法的收敛特征结果还是从算法的鲁棒性分析结果来看,BUPSO算法都表现出了较好的收敛特性和稳定性。
4 结束语
PSO算法只有单一阶段,存在收敛能力不足,粒子跳出局部最优空间动力不足,解的精度不高等弊端。为解决这些问题,提出了基于侦察学习策略的BUPSO算法。该算法利用联合因子对算法的全局搜索能力和局部搜索能力进行均衡,提高了算法的收敛能力和运算精度;当粒子陷入局部收敛时,该算法引入侦察学习策略,对该粒子的速度和位置进行更新,提高了粒子跳出局部最优解的能力。通过Wilcoxon秩和检验和基准函数寻优实验结果显示,该算法有一定的有效性和优越性,既保持了PSO算法简单、并行性高等特点,又在一定程度上提高了算法的收敛能力、局部极值逃逸能力和求解能力,具有深远的研究意义。
