耦合像素坐标的遥感图像分类实验
2022-10-12胡晓梅,李文楷,李佳豪,刘子越,黄伟钧
胡 晓 梅,李 文 楷,李 佳 豪,刘 子 越,黄 伟 钧
(中山大学地理科学与规划学院,广东 广州 510006)
0 引言
地理学第一定律[1]概括性地陈述了相邻地理单元的空间相关性,且地理位置越靠近其性质越相似,具体表现形式有距离衰减函数、空间自相关系数及泰森多边形等[2]。地理空间上的“远近”是对距离的表达,而地理空间信息既可是遥感影像像元的行列信息(row,col),也可是笛卡尔坐标系下的坐标信息(X,Y),或是地理坐标系下的经纬度信息(lon,lat)。遥感图像分类不仅要考虑光谱信息,空间信息也至关重要[3]。近年来,随着遥感影像应用范围越来越广泛,空谱信息耦合逐渐受到学者重视。常用的空间信息主要有纹理、数学形态和邻域等信息,多利用灰度共生矩阵[4]、Gabor滤波、小波变换[5]等方法提取。例如:段小川等[6]利用二维和三维Gabor滤波提取遥感图像的空间特征信息,并与光谱信息融合后基于堆栈式稀疏自编码器深度学习网络对图像进行分类;宋雯琦等[7]提出一种基于空谱特征的核极端学习机高光谱遥感图像分类算法,通过将光谱信息与空间信息叠加并引入核极端学习机中,使分类性能有所提升;陈杉等[8]证明小波变换方法有利于具有规则和较强方向性的纹理结构影像分类。然而传统空谱信息耦合的图像分类方法只考虑相邻单元位置的局部空间信息,忽视了图像整体空间的“远近”信息,未能充分利用地理空间信息。
将地理空间信息与光谱信息结合可产生较好的遥感图像分类效果,其中地理空间信息通常以较复杂的方式引入[9]。例如,Goovaerts[10]将空间坐标信息与最大似然分类法结合,根据邻域信息运用指示克里金方法估计每个像素的类别先验分布概率,并与通过光谱信息获取的类别分布概率值相结合进行图像分类,其中空间坐标主要用于确定中心样本的相邻样本,该方法适用于最大似然分类等生成模型,但不适用于随机森林(RF)等模型,且克里金空间插值对样本密度要求较高;Mu等[9]分别将地理空间信息和光谱信息作为特征值并利用支持向量机(SVM)分类器估算类别概率,将两种概率值作为特征值融合后再利用SVM进行最终分类,但其实现步骤仍很复杂。此外,在遥感图像场景分类、语义分割等方面,有学者提出结合地理空间信息的分类模型并取得较好的分类或分割精度[11-13]。考虑到遥感影像空间分布具有集聚性特点,Yang等提出的GeoBoost学习算法根据地理坐标划分不同的边界框,对落在特定边界框内的影像选择对应的基分类器进行语义分割[12],进一步利用地理哈希编码(geohash)将经纬度信息转换成二进制编码,并与深度神经网络模型中不同的单元进行特征耦合,虽然也可提高语义分割精度,但编码长度对模型精度有重要影响[13]。随着遥感技术的快速发展,LiDAR因能快速获取高精度的三维点云数据而被广泛应用于三维目标检测[14,15]、目标跟踪[16,17]以及三维建模[18]等领域。在三维LiDAR点云分类中,点云坐标可直接作为特征值输入监督分类器。目前流行的深度学习网络依靠点云的高精度空间坐标信息和回波强度信息可获得较高的分类精度,这不仅依赖于卷积网络[19]对空间结构信息的挖掘,更在于点云能精确反映物体的真实结构和三维尺寸,充分发挥了地理空间信息的作用,说明地理坐标信息对分类任务有一定贡献。遥感二维图像分类与三维LiDAR点云分类存在一定相似性,能否也将像素坐标信息直接作为特征值,以一种更简单通用的方式耦合坐标信息提高分类效果?为此,本文选取RF、SVM和人工神经网络(ANN)3个代表性的监督分类模型,探讨耦合像素坐标信息和空谱信息(纹理和颜色)对改善二维影像分类结果的有效性。
1 数据与研究方法
1.1 研究数据
为充分验证方法的可行性和鲁棒性,分别选择不同地区和类型的数据集进行实验:1)EI Cerrito和Richmond航空影像数据,分别为由Lecia ADS40数码相机拍摄得到的美国加利福尼亚州埃尔塞里托(EI Cerrito)和里士满(Richmond)航空影像(图1a、图1b),包含红、绿、蓝3个可见光波段,空间分辨率高达0.3 m,像元数分别为1 667×1 667、1 169×1 169。通过人工目视解译,EI Cerrito影像分为树木、绿地、裸土、不透水面(城市中的人造表面)和其他(目视解译难以识别的像元)5种类别,Richmond影像分为树木、绿地、裸土、不透水面、水体与阴影6种类别。2)Landsat8影像数据,来自Landsat8 L1T (https://earthexplorer.usgs.gov/),影像范围为广州市南部地区(图1c),原始影像包括11个波段,本文选取第7波段SWIR2、第6波段SWIR1与第4波段Red进行波段组合,空间分辨率为30 m。影像中包含不透水面、林地、草地、水体、裸土等多种地物,但由于分辨率较低,目视解译详细辨认各种地物比较困难,因此,该数据仅进行不透水面和非不透水面的二分类。

图1 数据集概况Fig.1 Overview of datasets
1.2 研究方法
本文研究技术流程(图2)为:首先利用灰度共生矩阵提取影像的纹理信息,与颜色信息和空间像素坐标信息耦合后,采用最大—最小线性归一化消除特征之间的量纲影响,形成不同样本量的随机训练数据集,为减少数据冗余,避免过拟合现象,特征选择阶段通过RF对特征值进行评估,选择具有代表性的特征;其次,为充分探讨像素坐标信息对图像分类的贡献,对基于RF、SVM和ANN的分类结果进行多次对比实验,即耦合像素坐标信息特征前后的对比,采用F1值和 Kappa系数评价不同模型分类结果的精度。
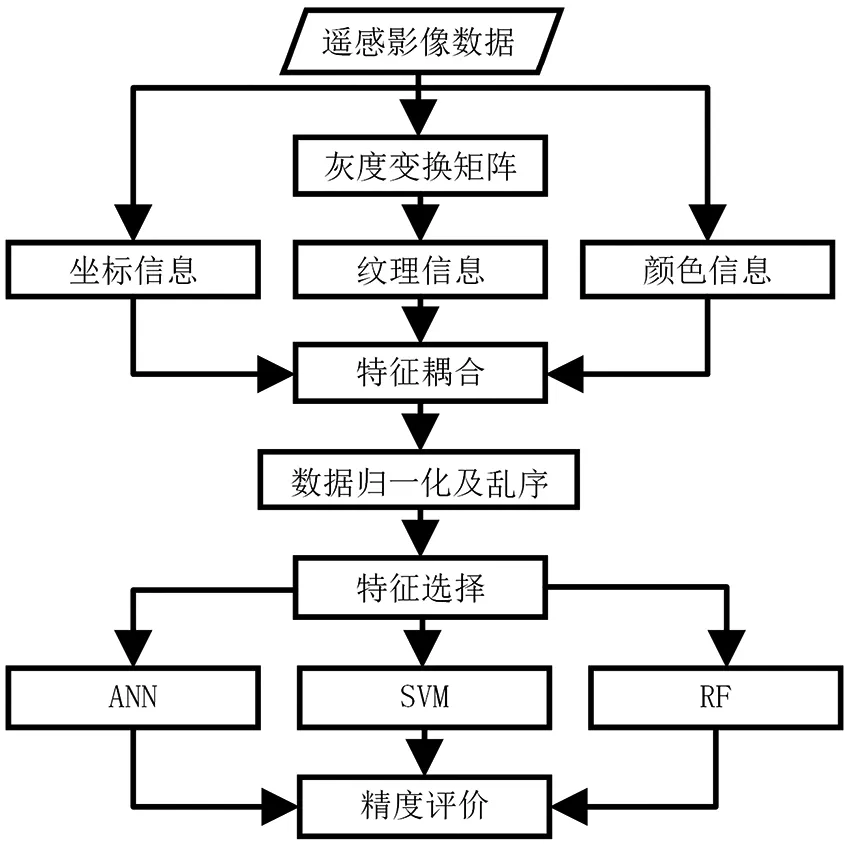
图2 耦合像素坐标遥感图像分类技术流程Fig.2 Flow chart of remote sensing image classification coupled with pixel coordinates
1.2.1 特征提取及归一化 在进行影像监督分类时,所有特征将归一化至0~1范围,是否对原始影像进行辐射定标对分类结果没有影响,因此本研究直接对3幅影像进行特征提取。1)EI Cerrito和Richmond航空影像数据的颜色信息为红、绿、蓝波段,Landsat8影像的颜色信息为SWIR2、SWIR1与红波段;2)利用灰度共生矩阵计算3×3像素窗口的均值、方差、对比度、二阶矩阵与同质性5种纹理信息,用以描述图像灰度的局部空间相关特性;3)每个像素的空间坐标信息(X,Y)由该像素的行号row_id、列号col_id、空间分辨率R和影像左下角坐标(xmin、ymin)计算(式(1)、式(2))。遥感影像的波段信息丰富且相关性较强,造成波段组合数量过大、数据冗余等问题,不仅减缓模型速度和泛化能力、占用过多的计算机资源,还易出现过拟合现象(休斯现象[20])。为减少冗余信息并尽可能保留图像高维特征中的潜在分类特征,本文采用RF对特征进行重要性排序[21],依据某特征值形成分支节点的Gini增益程度进行重要性评估[22],选取累计贡献率高于85%的特征。
X=xmin+(col_id-0.5)×R
(1)
Y=ymin+(nrows-row_id+0.5)×R
(2)
式中:nrows为总行数。
1.2.2 分类模型
(1)随机森林(RF)模型。该模型通过随机抽取并放回N组样本,建立N个分类回归树(CART),并以1∶2的比例划分袋内数据与袋外数据,袋外数据通过内部交叉验证应用于所有决策树,以估算整个随机森林的泛化能力,最终分类结果由所有决策树投票决定[23,24]。该模型对异常值和噪声具有一定的容忍度与鲁棒性,不易出现过拟合现象。EI Cerrito和Richmond航空影像数据中,随机森林决策树的数量(n_estimators)设置为10,最大分割特征数(max_features)选择默认值,内部节点最小分割样本数量(min_samples_split)设置为2;Landsat8影像数据中决策树的数量设置为5,其余参数与上述一致。
(2)支持向量机(SVM)模型。该模型的目标是寻找最大边距超平面[25],可直接通过Sequential Minimal Optimization等[26]优化算法得到全局最优解,结构化风险最小,可避免过拟合问题,具有一定的鲁棒性,比其他分类器学习效率更高,广泛应用于众多分类任务中[27]。核函数是SVM的重要组成部分,其可隐式地将样本从原始特征空间映射到高维希尔伯特空间,解决原始特征空间中的线性不可分问题,本文统一采用三阶多项式核函数,设置‘Hinge’损失函数,最大次数为1 000,可以较好拟合出复杂的分割超平面,且非线性映射能力较强。
(3)人工神经网络(ANN)模型。该模型通过逐渐改变神经元之间的连接强度学习新知识,并利用BP(Back Propagation)误差反向传播算法解决贡献度分配问题,无需人为干预[28],对非线性结构具有良好的拟合能力。本研究建立的 ANN包含输入层、3个隐含层和输出层。输入层的节点数由输入的特征数量决定,输出层的节点数由类别数量决定,隐含层节点数量过少会导致网络表达能力不足、出现欠拟合现象,数量过多又会产生过拟合现象。经过多次实验,EI Cerrito航空影像数据中神经网络隐含层和输出层节点数分别设置为50、30、15和5,Richmond航空影像数据中神经网络隐含层和输出层节点数分别设置为50、30、15和6,Landsat8影像数据中神经网络隐含层和输出层节点数分别设置为50、30、10和2。同时,为防止梯度消失或爆炸,加快网络收敛速度,本文进行逐层归一化,即每层神经网络后增加一个BN(Batch Normalization)层,并选择SELU(Scaled Exponential Linear Units)为激活函数。
1.2.3 样本数据及精度评价 本文采用目视解译和随机抽样方式采集样本数据。EI Cerrito和Richmond航空影像数据的训练样本量分别为10 000、5 000和3 000,测试样本量为3 000,EI Cerrito数据样本中各类别的比例为:不透水面22.92%、树木21.06%、绿地18.80%、裸土10.23%、其他26.99%,Richmond数据样本中各类别的比例为:不透水面42.66%、树木20.09%、绿地16.42%、阴影15.47%、水体3.26%、裸土2.09%;Landsat8影像数据的训练样本量设为3 000、2 000和1 000,测试样本量为1 000,各类别的比例为:不透水面56.07%、非不透水面43.93%。为充分验证方法的可靠性,对每组对比实验采用不同的随机样本重复10次实验,计算精度指标(F1值和Kappa系数)的平均值和标准差,并采用T检验验证耦合像素坐标与不耦合像素坐标精度差异是否显著。
2 结果分析
2.1 特征重要性排序
针对EI Cerrito航空影像数据,在耦合像素坐标情况下,累计特征贡献率高于85%的特征共有10个;仅使用颜色和纹理信息而不耦合像素坐标情况下,累计特征贡献率高于85%的特征共有9个;针对Richmond航空影像数据,在耦合与不耦合像素坐标情况下,累计特征贡献率高于85%的特征分别有11个和10个;针对Landsat8影像数据,两种情况下累计贡献率高于85%的特征分别有11个和9个。特征重要性排序结果侧面反映了像素坐标对影像分类也具有一定贡献。以EI Cerrito航空影像数据为例,像素坐标特征行号与列号重要性分别高达0.069和0.055,普遍高于一些纹理特征的重要性。
2.2 分类结果
(1)EI Cerrito航空影像数据分类。由表1可知,3个分类器在3个不同样本量上耦合像素坐标前后精度差异均具有较强的显著性,T检验的P值均小于0.01。根据图3所示,对于遥感图像中的不同地类,基于ANN模型耦合像素坐标方法下Kappa系数及F1值均有所提升,其中以树木类型的提升效果最明显。结合基于SVM和RF模型的分类结果(图略)可知:ANN、SVM和RF模型在仅使用传统空谱信息时对应的F1均值分别为80.91%、80.31%和78.92%,耦合像素坐标后F1均值分别提升为82.79%、81.66%和81.19%,说明耦合像素坐标分类方法的性能在不同实验条件下均优于传统空谱信息耦合的方法。选取局部影像分类结果进行对比(图4),发现图4两个红色方框中有部分树荫下的裸土被传统空谱信息耦合方法错分为不透水面,而耦合像素坐标方法能较好地识别这些裸土,分类效果良好。
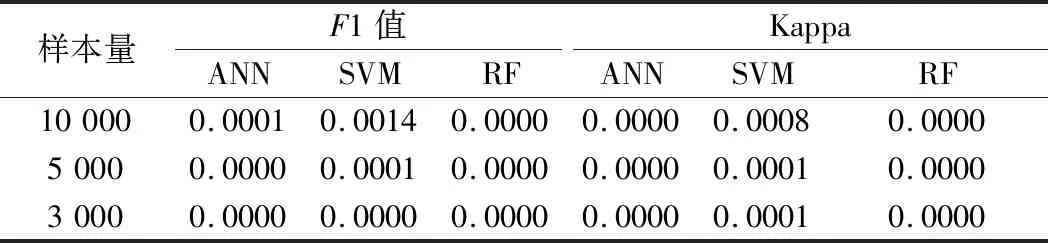
表1 EI Cerrito数据集F1值和Kappa系数的T检验P值Table 1 P values of T test of F1-score and Kappa coefficient on EI Cerrito dataset

图3 EI Cerrito数据集样本量为10 000时不同地物耦合像素坐标前后精度(平均值±2倍标准差)对比Fig.3 Comparison of accuracies (mean ± 2 times standard deviation) with and without pixel coordinates for different land types on EI Cerrito dataset with the sample size of 10 000

图4 EI Cerrito数据集局部区域放大图对比Fig.4 Comparison of enlarged images of local areas of EI Cerrito dataset with and without pixel coordinates
(2)Richmond航空影像数据分类。根据表2,3个分类器在3个不同样本量上耦合像素坐标前后精度差异均具有较强显著性,T检验的P值均小于0.01。由图5可知,对于遥感图像中不同地类,基于SVM模型耦合像素坐标方法下Kappa系数及F1值均有所提升,其中水体和裸土提升效果最明显。结合基于ANN和RF模型的分类结果(图略)可知:以样本量5 000为例,仅使用传统空谱信息时,ANN、SVM和RF 3种分类器对应的F1值分别为67.58%、64.67%和64.45%,耦合像素坐标后F1均值分别提升为77.60%、77.31%和74.83%,说明耦合像素坐标分类方法在不同实验条件下均优于传统空谱信息耦合方法。选取局部影像分类结果进行对比,发现传统空谱信息耦合方法在靠近岸边区域将很多水体像素错分为阴影,而耦合像素坐标方法在该区域仅将少量零散水体像素错分为阴影,其总体分类效果较好(图6)。

表2 Richmond数据集F1值和Kappa系数的T检验P值Table 2 P values of T test of F1-score and Kappa coefficient on Richmond dataset
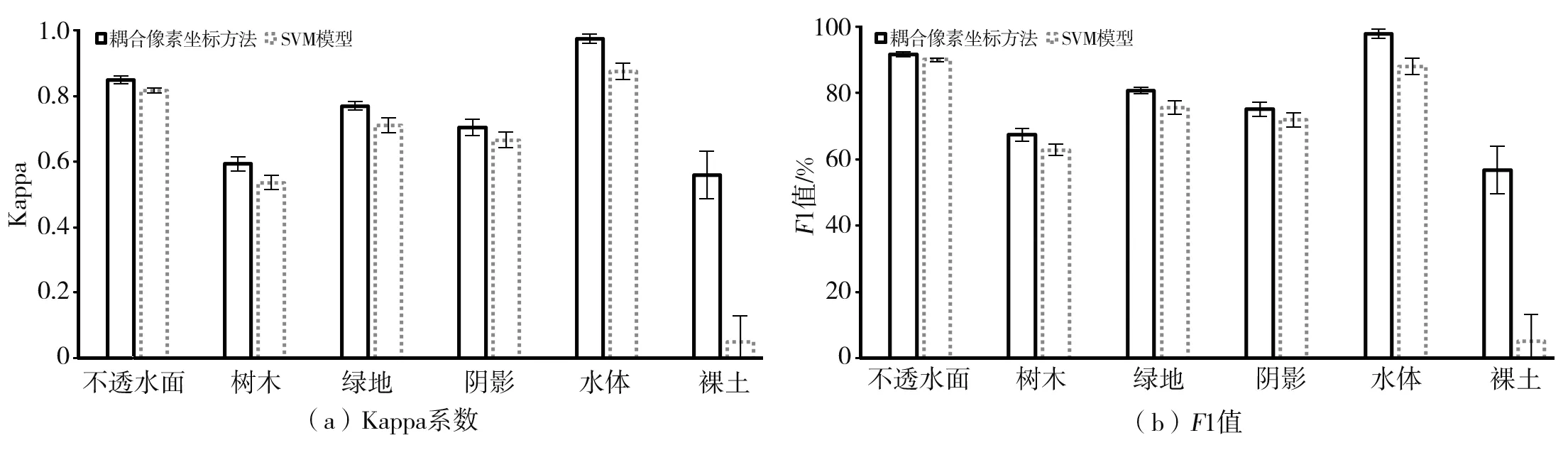
图5 Richmond数据集样本量为10 000时不同地物耦合像素坐标前后精度(平均值±2倍标准差)对比Fig.5 Comparison of accuracies (mean ±2 times standard deviation) with and without pixel coordinates for different land types on Richmond dataset with the sample size of 10 000

图6 Richmond数据集局部区域放大图对比Fig.6 Comparison of enlarged images of local areas of Richmond dataset with and without pixel coordinates
(3)Landsat8数据影像分类。根据表3,耦合像素坐标前后精度差异在不同样本量和分类器上显著性不同:ANN和SVM在样本量为2 000和3 000时显著性较强,但在样本量为1 000时不显著;RF在3个不同样本量上均不显著。根据图7可知,耦合像素坐标分类方法相较于传统无坐标分类方法,10个随机数据集的Kappa均值更高,且随着数据集样本量减小,Kappa值也有所降低。基于ANN、SVM和RF模型,耦合像素坐标分类方法在3种不同样本量中的F1值均高于传统空谱信息耦合方法。例如,当样本量为3 000时,ANN、SVM和RF的10次随机样本集F1均值分别为91.59%、91.60%和88.88%,而传统空谱信息耦合方法对应的F1均值分别为90.45%、90.58%和88.26%。由局部区域放大图(图8)可见,传统图像分类方法结果较差,有大量的不透水面被错分,而耦合像素坐标分类方法能更好识别不透水面,说明像素坐标对图像分类有一定贡献。
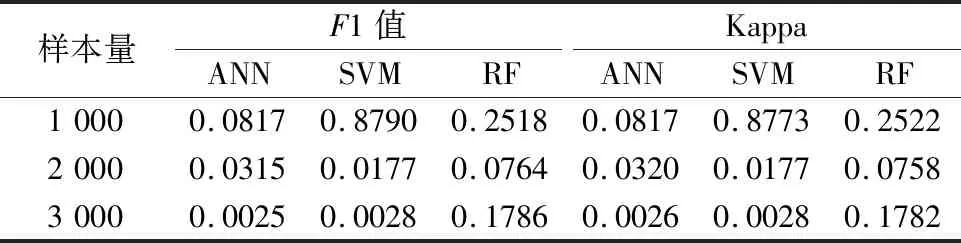
表3 Landsat8数据集F1值和Kappa系数的T检验P值Table 3 P values of T test of F1-score and Kappa coefficient on Landsat8 dataset

图7 Landsat8数据集耦合像素坐标前后Kappa系数(平均值±2倍标准差)对比Fig.7 Comparison of Kappa coefficients (mean ±2 times standard deviation) with and without pixel coordinates on Landsat8 dataset

图8 Landsat8数据集局部区域放大图对比Fig.8 Comparison of enlarged images of local areas of Landsat8 dataset with and without pixel coordinates
3 结论与讨论
本文基于3种不同分辨率卫星与航空遥感影像,利用灰度共生矩阵提取纹理信息,并与颜色信息和像素坐标耦合,进而采用RF对初始特征进行重要性排序,选取具有代表性的特征,最后使用RF、SVM和ANN 3种不同分类器进行遥感影像分类。结果显示,相较于仅使用空谱信息图像分类方法,耦合像素坐标方法分类效果更好,F1值和Kappa系数均有所提升,从定性和定量角度验证了耦合像素坐标能有效提高图像分类精度。此外,本文实验结果还验证了耦合像素坐标对Landsat8数据集的精度提升(1%左右)略低于对航空影像数据集的精度提升(2%~12%)。
一个特征是否有助于分类,取决于地物类别在该特征空间上的分布情况,如果地物在该特征空间上呈随机分布,则对分类无帮助,如果地物在该特征上呈现某种形态的集聚分布,则对分类有帮助。地理学第一定律揭示了地物集聚分布的普遍性,在遥感影像中各种地物类别的像素也是集聚分布而非随机分布,因此,将空间坐标信息作为特征时分类精度有所提升。另外,空间自相关现象会随着距离衰减,由于Landsat8的空间分辨率(30 m)远小于航空影像的空间分辨率(0.3 m),相邻像元对应的地理空间距离尺度不同,通过对比两个不同分辨率数据集的实验结果,发现耦合像素坐标对高分辨率影像分类精度提升的幅度更大,且统计检验结果的显著性更强,这从侧面验证了地理学第一定律:越相近的地理单元性质越相似,坐标信息发挥的重要性越高。
相关文献和本文实验结果表明,坐标信息可提升分类精度,然而,在传统遥感影像分类中坐标信息常被忽略[29],或者以一种较为复杂的方式与空谱信息相耦合。本文的创新性在于提出一种更简单有效的像素坐标信息耦合方式。理论上,本文方法适用于各种监督分类器,但本研究仅选择3种常用的分类器为代表。当前,深度学习方法已被广泛应用于遥感影像分类[30],今后可进一步验证该方法对其他分类器(如深度卷积语义分割模型)的适用性,并选择更多的数据集验证其有效性。
