基于关联规则的老年人脂肪肝相关危险因素研究
2022-10-12常琴雪王肖萌王柯云刘媛媛李长平孙继佳
常琴雪 王肖萌 王 淳 王柯云 刘媛媛 李长平 孙继佳 崔 壮△ 马 骏
【提 要】 目的 研究上海地区老年人健康体检数据,分析与老年人脂肪肝患病相关的因素以及多个因素间潜在的交互作用。方法 选取2017年上海某社区60岁及以上老年人体检的临床健康数据作为研究对象,脂肪肝影响因素的筛选先采用LASSO回归进行降维和消除变量之间的多重共线性,再采用逐步回归法构建logistic回归模型。关联规则建模并提取与脂肪肝患病相关的规则。结果 在所有6252例研究对象中,病例组3345例,该社区老年人脂肪肝患病率为53.50%,为高患病率。性别、BMI、高脂血症、白蛋白、谷丙转氨酶、谷草转氨酶、平均红细胞体积、红细胞压积、尿素、平均血红蛋白含量、血小板、单核细胞数、血小板容积、肌酐、总胆固醇、葡萄糖含量、低密度脂蛋白、甘油三酯、尿酸为老年人患脂肪肝的独立影响因素。关联规则提示性别、BMI、高血压、低密度脂蛋白等变量关联在一起时,一定程度上增加脂肪肝发生的风险。结论 分析与脂肪肝患病相关的因素以及多个因素间潜在的交互作用,能够为脂肪肝的早期预防与控制提供信息参考,从而更好地预防脂肪肝的发生。
脂肪肝(fatty liver,FL)是指由于各种原因导致的肝细胞中脂肪过度堆积的病变,它是一种常见的肝脏病理变化,而不是一种独立的疾病[1]。脂肪肝是多种症状群的集合,它与性别、年龄、相关生理生化指标以及影像学症候间必然存在或多或少的联系,仅仅通过一个或两个指标去解释脂肪肝的发生与发展机制是不现实的。这是因为当人体某器官发生病变时,单一的生理指标常常不足以反映人体健康状况,从而无法解释病情[2]。体检数据作为医学信息的重要部分,需利用机器学习方法进行相关的挖掘分析。通过对健康体检数据的挖掘,脂肪肝相关因素之间可能存在诸多交互效应。所谓交互效应,指的是当某自变量对因变量的作用效应的大小与另一个自变量的取值有关时,则表示两个变量具有交互作用[3]。
本研究基于经典机器学习方法,利用回归算法筛选出脂肪肝相关因素,用关联规则Aprior算法建模并提取强关联条,分析与脂肪肝患病相关的因素以及多个因素间潜在的交互作用,为脂肪肝的早期预防与控制提供信息参考,从而更好地预防脂肪肝的发生。
资料与方法
1.数据来源
主要采用2017年上海某社区的60岁及以上老年人体检的临床健康数据,对6664例原始数据进行建模和分析。收集性别、年龄、体重指数(BMI)、相关生化指标与病史情况共48项内容作为自变量预测出现脂肪肝的概率,生化指标包括白蛋白、血红蛋白、白细胞、红细胞、平均红细胞体积、红细胞压积、平均血红蛋白含量、平均血红蛋白浓度、红细胞分布宽度、红细胞分布宽度变异系数、血小板、血小板分布宽度、血小板容积、大型血小板比率、平均血小板体积、谷丙转氨酶、谷草转氨酶、总胆固醇、总胆红素、肌酐、高密度脂蛋白、低密度脂蛋白、甲胎蛋白、癌胚抗原测试、甘油三酯、尿素、尿酸、葡萄糖、嗜碱性粒细胞数、嗜碱性细胞比率、嗜酸性粒细胞数、嗜酸性粒细胞比率、淋巴细胞数、淋巴细胞比率、单核细胞数、单核细胞比率、中性细胞数、中性细胞比率,病史情况包括高血压、糖尿病、心脏病、脑梗、慢阻肺、骨质疏松、高血脂。
2.数据处理
由于体检数据具有不完整性、多样性以及存在缺失值等特点,在进行数据挖掘分析前,需要对体检数据进行相应的预处理措施,如对缺失数据进行多重插补。通过数据预处理最终获得6252例原始数据,即为本文最终的研究数据。病史情况中将“患病”与“正常”分别赋值1和0。关联规则使用定性变量分类,因此,需要对定量数据进行离散化处理。将BMI按照小于18.5(体重偏瘦),介于18.5和24(体重正常),介于24和28(体重超重)和大于28(体重肥胖)划分为四个等级,其他相关生化指标依照公认的医学参考值范围划分为“异常”和“正常”,分别赋值为1和0,再进行关联规则建模。
3.统计学方法

结 果
1.脂肪肝患病情况的单因素分析
在所有6252例研究对象中,患脂肪肝3345例,患病率为53.5%。其中男性和女性的患病率分别为51.24%和55.38%,差异有统计学意义(P<0.001)。两组在年龄、BMI和白蛋白、白细胞、谷丙转氨酶、谷草转氨酶等28项生化指标数值比较差异具有统计学意义(P<0.05),见表1。病例组和对照组在高血压、糖尿病、慢阻肺和高脂血症等病史情况比较差异具有统计学意义(P<0.05),见表2。

表1 病例组与对照组的相关生化指标参数比较
2.脂肪肝患病情况的LASSO回归分析
以脂肪肝患病结局为因变量,将性别、年龄、BMI和白蛋白、白细胞、谷丙转氨酶、谷草转氨酶等28项生化指标和高血压、糖尿病等4项病史情况,共35项单因素差异具有统计学意义的变量纳入LASSO回归模型中,筛选与脂肪肝患病相关的变量。在Cp统计量(Mallows Cp统计量)取最小时,LASSO回归筛掉红细胞、中性细胞比率、血红蛋白、淋巴细胞比率和中性细胞数这5项生化指标,既消除了自变量间的多重共线性并起到了降维的作用。
3.脂肪肝患病情况的多因素logistic回归分析
将经LASSO回归筛选后的30项变量纳入到logistic回归分析中,逐步回归的结果显示:性别、BMI、白蛋白、谷丙转氨酶、谷草转氨酶、平均红细胞体积、红细胞压积、尿素、平均血红蛋白含量、葡萄糖含量、血小板、总胆固醇、单核细胞数、血小板容积、肌酐、低密度脂蛋白、甘油三酯、尿酸、高脂血症为老年人患脂肪肝的独立影响因素(P<0.05),见表3。
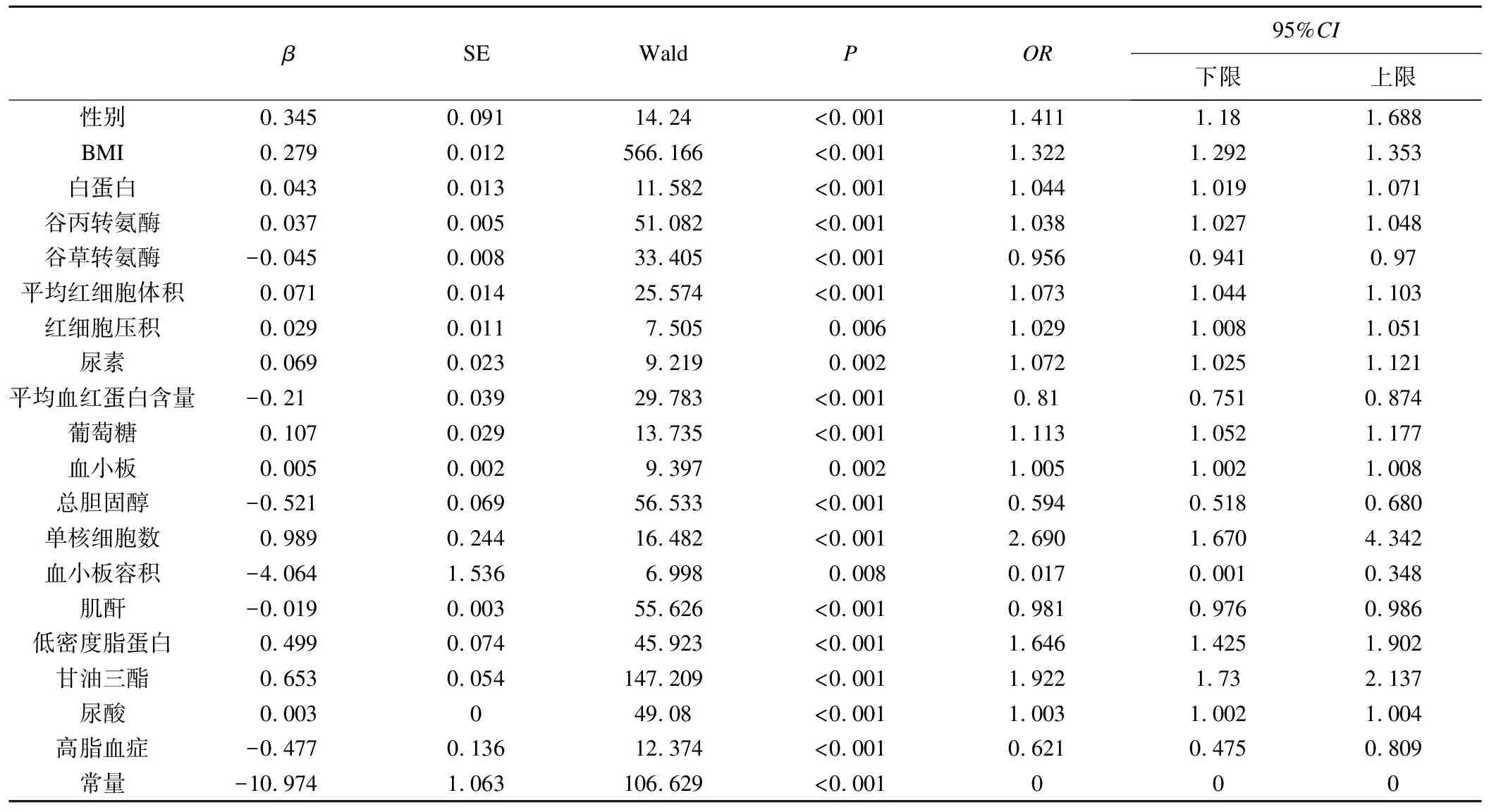
表3 老年人脂肪肝患病情况的多因素logistic回归分析
4.关联规则
在判断关联规则的可靠性时,有研究发现:当最小支持度已确定时,最小置信度>80%,提升度>1的关联规则结果较为可靠[4]。因此,本研究中首先将最小置信度设立为80%,以脂肪肝患病情况为后项,最小支持度逐渐降低,观察并筛选得出的关联规则结果。当最小支持度为2%时,挖掘出的信息较多且挖掘时间较短。最终,设立最小置信度为80%,最小支持度为2%,提升度>1作为筛选强关联规则的标准。去除冗余规则后生成的与脂肪肝有关的强关联规则见表4。

表4 脂肪肝相关因素的强关联规则
总体而言,该社区60岁及以上老年人体检数据脂肪肝相关因素以脂肪肝患病为后项的关联规则显示,脂肪肝的发生与性别、BMI、高血压患病相关,与低密度脂蛋白、总胆固醇、甘油三酯、谷丙转氨酶、葡萄糖含量、肌酐等生化指标的含量也密切相关。以关联规则1为例说明该强关联条的意义:在全部研究对象中,体重肥胖、低密度脂蛋白含量异常、患脂肪肝的人占全部对象的2.93%,患脂肪肝在已知体重肥胖、低密度脂蛋白含量异常的人群中的条件概率为86.32%。提示体重肥胖、低密度脂蛋白含量异常的老年人通常患有脂肪肝。另外,在规则6的基础上添加了一个前项变量,就得到规则2、3、4、7。规则6提示体重超重、甘油三脂含量异常的老年人通常患脂肪肝,规则2、3、4、7在这基础上分别强调了总胆固醇、性别、高血压和葡萄糖含量的影响。通过观测指标和疾病发生的关联强弱,可以把某些体检项目作为推断某疾病是否发生的指标,对疾病的防治有重要的意义。关联位点结构见图1。
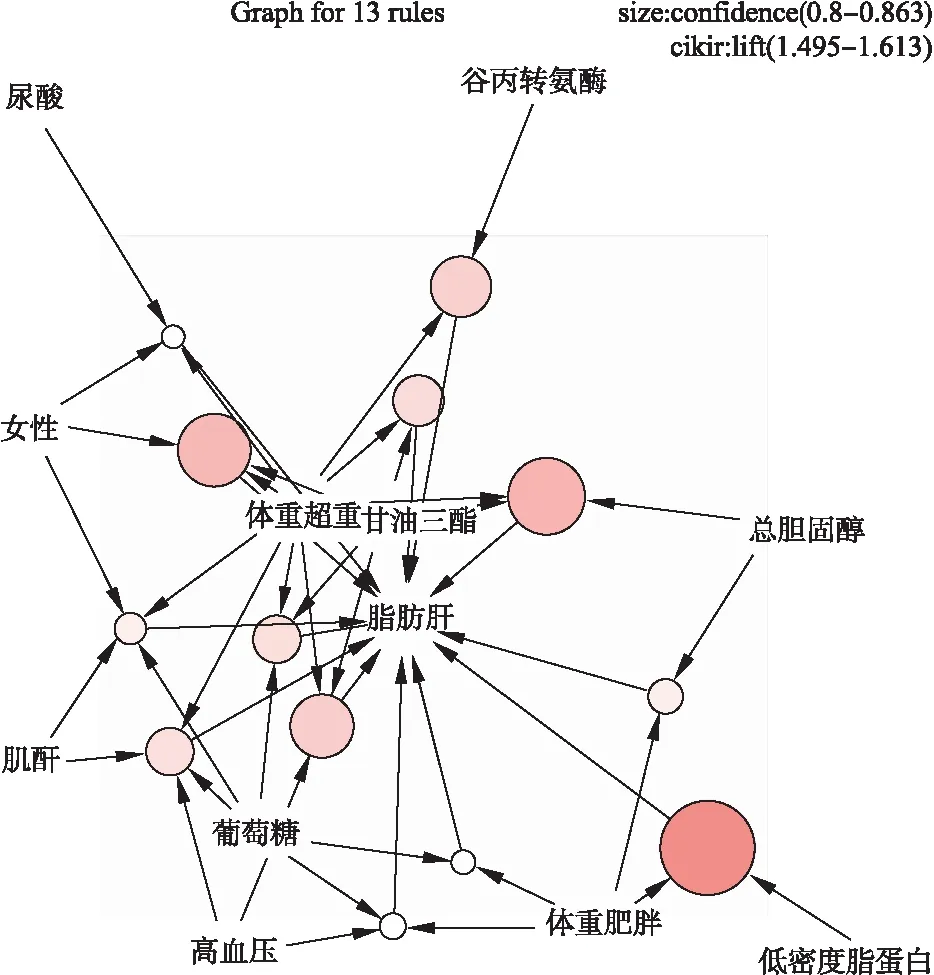
图1 关联位点结构
讨 论
通过对体检数据的研究分析,本研究发现性别、BMI、高脂血症及谷丙转氨酶、总胆固醇、葡萄糖含量、低密度脂蛋白、甘油三酯、尿酸等多项生化指标为老年人患脂肪肝的独立影响因素,这与周云庆、何陈等人的研究结果一致。在本文中,女性患病率略高于男性,与以往研究中男性患病率高于女性的结论不同[5],这可能是因为研究地区存在差异。此外,有研究发现调整了年龄和性别后,血脂异常(特别是高脂血症)和体重肥胖是脂肪肝患病的重要危险因素[6]。这也与临床情况相符合:大部分肥胖病人患有高脂血症[7],当人体内的血脂过高时,甘油三酯在肝脏附近堆积就很有可能会使肝脏慢慢的变成脂肪肝情况。我们的研究还发现了白蛋白、肌酐、单核细胞数等其他指标和脂肪肝密切相关。国外研究发现,脂肪肝患者的尿白蛋白与肌酐的比值显著高于健康人[8]。来自单核细胞的巨噬细胞是脂肪肝的驱动因素,研究表明肝脏的巨噬细胞数量与脂肪肝严重程度之间呈正相关关系[9]。
本研究关联规则的提升度在1.5左右,说明前后项具有较强的关联性。规则提示性别、BMI、高血压、低密度脂蛋白、总胆固醇、甘油三酯、谷丙转氨酶、葡萄糖含量、肌酐等变量关联在一起时,一定程度上增加脂肪肝发生的风险,补充了logistic回归的结果。提示在今后的脂肪肝预防中,当联合出现上述多种情况异常时应提高警惕。此外,甘油三酯、葡萄糖含量可作为脂肪肝较敏感的生化指标。但是本研究中得出的结果并不能提示因果关联,只在一定程度上提示是多因素间的交互作用的结果,并且疾病之间的关系强弱也需要进一步的研究。
本文在变量选择方面只采用了老年人体检数据中的生化指标数据和一些病史情况,删去许多与脂肪肝发生相关的因素,如B超检查、放射结果等,使得规则并不是十分全面与精确。在数据方面,BMI变量存在一定比例的缺失,但经过BMI缺失组和未缺失组的其他变量比较,我们认为BMI的缺失为随机缺失,对结论无影响,经多重插补后的研究结果具有可信性。此外,关联规则在实际应用中并没有明确的评价标准,常常是研究者根据研究背景以及关联规则的数量选择可能感兴趣的强关联条,具有一定的主观性。但关联规则结果能够形象直观地反映候选变量之间的关系,在结果的临床解释上也有较高的专业性。
随着信息化技术的飞速发展,医学数据越来越呈现海量、复杂多变的特点,需要更具效率和效能的方法来分析。在本文中,基于数据存在较多的变量,LASSO回归进行了降维并消除了变量间的多重共线性,有利于logistic回归模型构建。logistic回归分析了某变量是否为疾病的独立影响因素,而关联规则分析了变量间的联合与交互,补充了logistic回归提供不了的信息,更加丰富、全面、综合地分析了老年人脂肪肝发病的影响因素。关联规则的特点就是能够发现大量复杂数据之间的关联或者相关联系,在此基础上,不仅能挖掘出各个变量之间的相关关系,还能挖掘出多个变量组合之间的相关关系,直接提示变量间的交互作用。因此,在医学领域关联规则大有作为:从多维多元的医疗信息中揭示疾病发生与发展的规律,研究疾病机制,评价临床诊断、药物治疗的效果以及为疾病早期预防与控制提供科学、准确的信息参考。在近三十年的研究和发展中,前人基于Apriori算法研究出了许多改进算法和多种扩展关联规则,使得关联规则算法已成为最成熟的数据挖掘方法之一,在医学数据分析中具有广阔的应用前景。
