基于多核学习的弥漫大B细胞淋巴瘤早期复发的精准预测*
2022-10-12余红梅张岩波阳桢寰赵艳琳李雪玲赵志强罗艳虹
邢 蒙 周 洁 余红梅 张岩波 阳桢寰 赵艳琳 李雪玲 李 琼 赵志强 罗艳虹△
【提 要】 目的 对山西省某三甲医院2011-2017年间血液科新诊断的弥漫大B细胞淋巴瘤患者(diffuse large B-cell lymphoma,DLBCL)是否实现两年无事件生存,即DLBLC患者早期复发的预测。方法 根据无事件生存期,将患者分成早期复发和非早期复发,并以此为标签构建分类模型。首先对数据进行了归一化处理,然后用LASSO进行了特征选择,因数据类别不平衡,分别采用了SMOTE(synthetic minority over-sampling technique)、Borderline-1 SMOTE、Borderline-2 SMOTE与ADASYN(adaptive synthetic sampling)四种方法平衡数据,之后构建了基于支持向量机的多核模型作为最终的分类器,并与AdaBoost、随机森林和以高斯核、多项式核为内核的单核支持向量机进行比较,最终实现对新诊断病例早期复发的预测。结果 在本文所有模型中,采用LASSO加Borderline-1 SMOTE的多核模型(accuracy=0.87,precision=0.87,recall=0.87,f1=0.87,AUC=0.87)取得了最优的分类性能。采用SMOTE的随机森林模型(accuracy=0.84,precision=0.85,recall=0.87,f1=0.79,AUC=0.83)、Borderline-2 SMOTE的随机森林(accuracy=0.84,precision=0.85,recall=0.87,f1=0.79,AUC=0.83)两种集成模型的分类性能也较好,但都低于多核支持向量机模型。两种单核支持向量机性能较差。结论 本文构建的所有模型中,经过LASSO和Borderline-1 SMOTE重采样的多核支持向量机性能最优,可为DLBCL早期复发预测提供参考。
弥漫大B细胞淋巴瘤(diffuse large B-cell lymphoma,DLBCL)是成人淋巴瘤中最常见的一种类型,其发病率占非霍奇金淋巴瘤的31%~34%,在我国约占40%~50%[1]。如果不进行及时治疗,其预后很差,中位生存期不到1年。但其具有潜在治愈的可能,传统的免疫化疗结合放疗可达到40%~50%的5年生存率[2-5]。有研究表明,DLBCL患者中复发多发生在诊断的前两年。早期复发的患者预后很差,而达到2年无事件生存期的患者,在5年内与其年龄、性别匹配的一般人群相比,有着很小的生存时间损失[6]。如果可以精准识别两年内复发的这部分群体,研究清楚他们的特点,对其实施精准化、个性化治疗,将有助于提高DLBCL患者的整体生存时间。
DLBCL患者的资料涉及基本信息、临床用药、血生化和病理等,异质性较大且可能存在冗余特征。用单一分类器如支持向量机、决策树、神经网络等处理时往往性能很差,且涉及一系列调参问题。同时,DLBCL早期复发比例低,造成了数据不平衡,不平衡率为3.41。当数据分布不均衡时,单一分类器在正类样本上的预测性能极差。集成模型虽然可以提高总体性能,但如果不处理不平衡问题仍会出现正类样本性能差的问题,且集成模型不易解释。考虑到以上问题,本文构建了一种基于LASSO特征选择和四种重采样方法平衡数据的多核支持向量机模型,其性能较好,且不涉及调参问题,结果易于解释。
资料与方法
1.数据来源与处理
参考《中国弥漫大B细胞淋巴瘤诊断与治疗指南2013版》,回顾性收集了山西省某三甲医院2011-2017年新诊断的370例在初次化疗后获得完全缓解的DLBCL患者的病例信息,包括基本信息、临床用药、血生化和病理等多个指标,共70个特征。定义无事件生存为从诊断为DLBCL到疾病进展、复发或因其他原因死亡[6]。若患者未达到两年无事件生存期即复发,将其定义为早期复发,5年内未复发定义为未早期复发。370例DLBCL患者中,早期复发(2年内)82例(22.2%),3年内复发5例,4年内1例,5年内2例,未早期复发(5年内未复发)280例(75.7%)。
首先对输入数据进行归一化,使数据范围位于0~1之间,再使用LASSO筛选有意义的变量。然后随机抽取20%作为测试集,其余80%为训练集,之后用SMOTE[7]、Borderline-1 SMOTE、Borderline-2 SMOTE[8]和ADASYN[9]四种方法平衡数据。对平衡后的数据构建基于支持向量机的多核模型,并与AdaBoost、随机森林两种集成模型、以RBF、Poly为内核的两种单核支持向量机模型进行比较。以accuracy,precision,recall,f1,AUC值为评价指标。为了减轻数据划分带来的偏倚,所有模型都执行数据划分100次,报告100次的均值。所有程序均基于Python 3.7运行。
2.方法及原理
(1)特征选择
LASSO基于L1正则项对变量原本的系数进行压缩,将原本很小的系数直接压缩至0,从而将这部分系数所对应的变量视为非显著性变量,将不显著的变量直接舍弃,以实现变量选择[10-11]。LASSOCV是在LASSO的基础上加了交叉验证,本文选用LASSOCV进行特征选择。
(2)类别不平衡
本文比较了SMOTE[7]、Borderline-1 SMOTE、Borderline-2 SMOTE[8]和ADASYN[9]4种数据平衡方法。
SMOTE算法具体步骤为:对少数类样本a,从它的K个最近邻中随机选择一个样本b,然后在两点的连线上随机生成一个新的少数类样本。ADASYN为自适应合成抽样,它利用分布来自动决定每个少数类样本所需要合成的样本数量,相当于给每个少数类样本施加了一个权重,周围的多数类样本越多则权重越高。
Borderline-SMOTE是SMOTE的改进,分为Borderline-1 SMOTE和Borderline-2 SMOTE。Borderline-SMOTE先将少数类样本分为三类:(1)噪音样本,该少数类的所有最近邻样本都来自于和a不同的其他类别;(2)危险样本,至少一半的最近邻样本来自于不同于a的类别;(3)安全样本,所有的最近邻样本都和a来自于相同的类别。这两种类型的SMOTE都使用危险样本来生成新的样本数据,Borderline-1 SMOTE 最近邻中的随机样本b与该少数类样本a来自于相同的类;Borderline-2 SMOTE 最近邻中的随机样本b可以是属于任何一个类的样本。
(3)比较模型
AdaBoost和随机森林(random forest,RF)是两种集成模型。前者是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器,即弱分类器,然后把这些弱分类器集合起来,构造一个更强的终分类器。后者是一种集成算法,该算法以对原始数据集进行有放回抽样的方式对数据集进行扩充。它的基本单元是决策树,每棵决策树是一个分类器,N棵决策树会有N个分类结果。最后指定投票次数最多的类别为最终的输出,是N棵决策树分类结果的集成。
支持向量机(support vector machine,SVM)是通过核函数将线性不可分的问题从原始低维空间映射到高维的希尔伯特空间(Hilbert space),从而实现高维空间线性可分,是常见的核学习方法之一。
(4)多核模型
多核学习(multiple kernel learning,MKL)已经被证明可以更灵活有效地刻画异构数据源,可将输入数据映射到多个核空间,使得原始信息得到了更大的保留和利用,且多核模型比单核模型更灵活多变[12-15]。现在已经广泛用于疾病风险预测[16-19]、图像识别[20]等各个方面。
根据现有的核组合形式,多核学习算法可以分成三类:线性组合[21-22]、非线性组合[23-24]、数据相关组合[25]。本文构建的多核SVM是利用线性组合的方法进行核矩阵融合。多核SVM是多核学习在监督学习中的实现,是将SVM中的单个核函数替换为核函数族(kernel family)的改进算法。首先将输入数据通过不同的核函数分别映射到各自的核特征空间,在各个核映射空间内构造对应的核矩阵,并计算每个核矩阵对应的权重系数,然后将各个核矩阵和其对应的权重系数相乘并相加,得到融合的核矩阵,利用融合后的核矩阵训练模型。本文选择了一个线性核、一个多项式核、一个Sigmoid核、两个不同参数的高斯核,共5个核函数作为内核构造多核SVM。图1为多核的流程图。
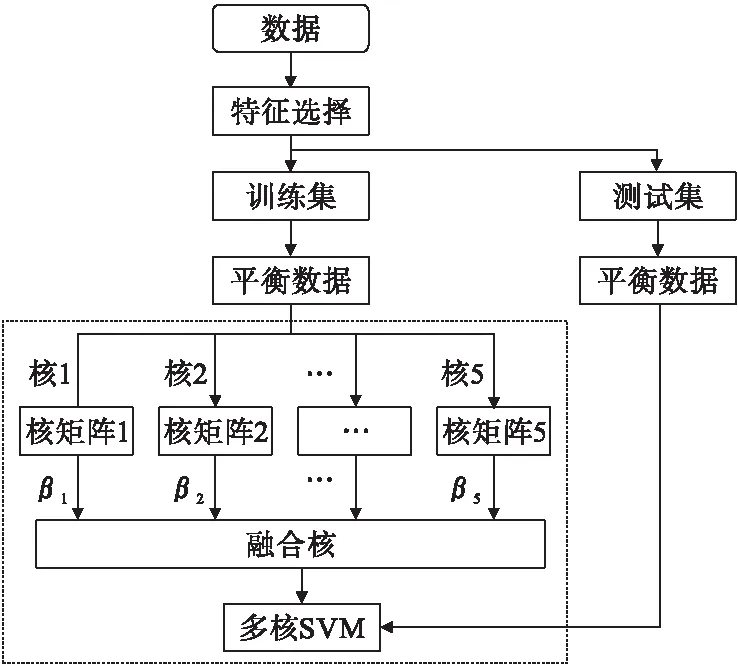
图1 流程图
(5)评价方法
本文采用accuracy,precision,recall,f1,AUC值作为性能评价指标,混淆矩阵见表1。

表1 混淆矩阵
accuracy常用来评价分类模型的性能,但是当数据不平衡时会掩盖少数类的错分率。Precision和recall是评价不平衡数据的常用指标,当将每个样本都预测为少数类时,少数类样本全部预测正确,此时recall为100%,但是Precision很低。相反,若将多数类大都预测正确,则Precision会很高,但是recall会很低。F值是两者的综合,当Precision和recall的权重一致时即为f1值,f1值高能保证Precision和recall都较高。AUC值是ROC曲线下面积,用来评价模型的泛化能力。
结 果
1.特征选择
本文采用LASSOCV共选出了12个特征,见表2。
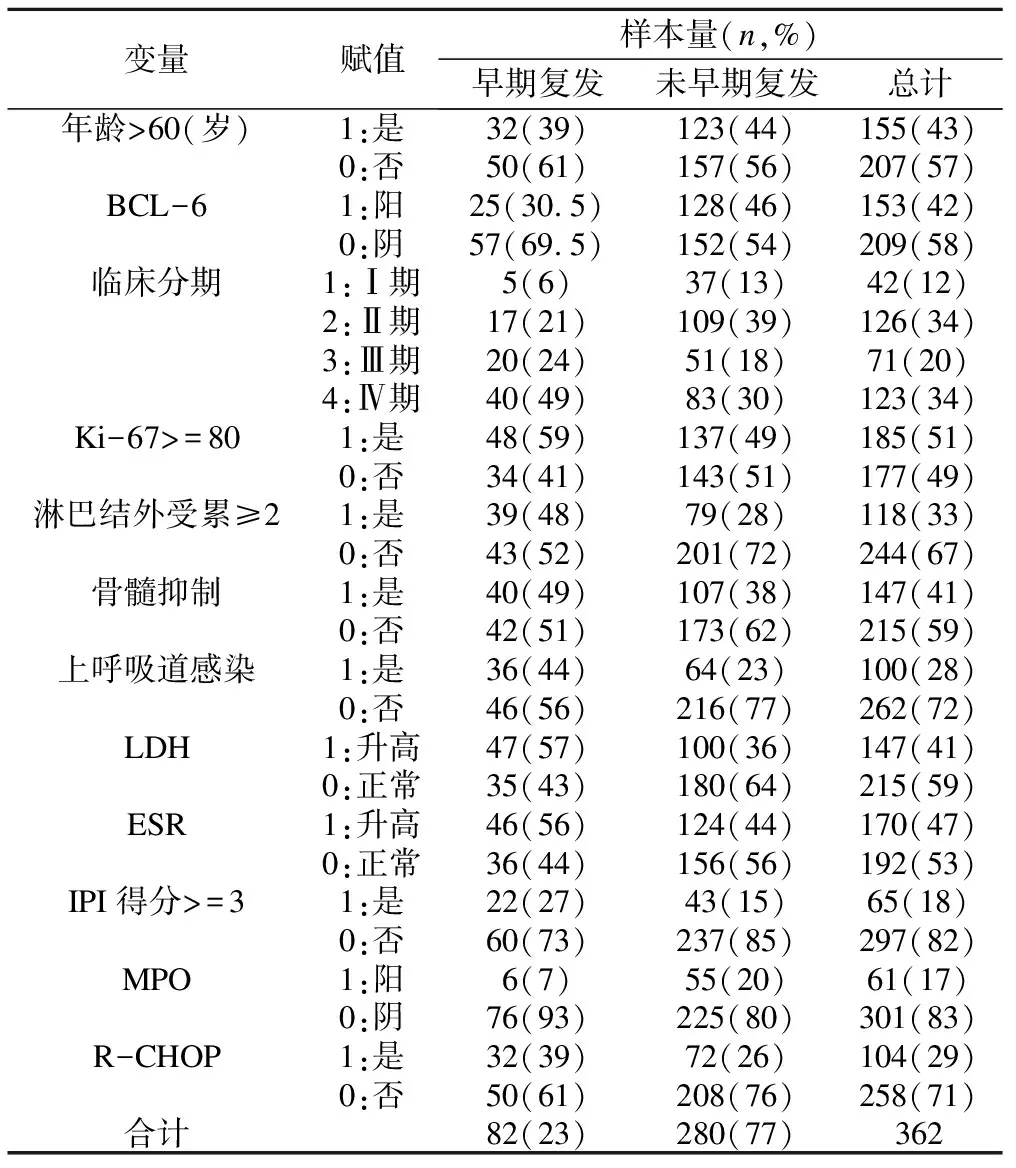
表2 LASSO特征选择的变量、赋值及描述
由表2可知,未早期复发是早期复发的3.41倍,造成了类别不平衡。早期复发患者中,除BCL-6阳性、MPO阳性的占比低于未早期复发,其他指标的阳性占比均大于未早期复发。
2.模型
由表3可知,采用LASSO加Borderline-1 SMOTE的多核模型(accuracy=0.87,precision=0.87,recall=0.87,f1=0.87,AUC=0.87)取得了最优的分类性能。采用ADASYN的ADBOOST(accuracy=0.82,precision=0.82,recall=0.81,f1=0.81,AUC=0.81)模型、采用SMOTE和Borderline-2 SMOTE的随机森林(accuracy=0.84,precision=0.85,recall=0.87,f1=0.79,AUC=0.83)三种集成模型的分类性能也较好,但都低于多核支持向量机模型。两个单核SVM性能较差,Poly核优于RBF核。两种Borderline SMOTE和ADASYN数据平衡方法优于SMOTE。综上,多核支持向量机模型性能较好,且不用进行调参的复杂过程,应用更灵活、方便,且比集成模型易于解释。

表3 各模型在测试集上的性能指标
讨 论
本文在DLBCL真实数据集上,基于重采样和多核学习方法对DLBCL患者早期复发进行预测。何强[26]等和Wang[27]等针对单视图数据构建的多核学习模型,与单核模型相比,模型性能有了很大的提高。郑建华[28]等针对不平衡数据构建了基于融合级联上采样和下采样的随机森林模型,相比传统的随机森林模型性能取得很大提升。在本文中,基于重采样平衡数据后构建的多核支持向量机模型与单核支持向量机相比,性能也有很大提升,且比集成模型更易进行结果解释。
如果训练集占原始数据集比例过大,训练出来的模型可能会更接近原始数据集,此时测试集较小,模型评估结果可能不稳定。如果测试集过大,则训练集和原始数据差别增大,此时训练集训练的模型与原始数据集训练的模型相比可能有较大差别,会降低测试集评估结果的保真性[29]。常见做法是将原始数据的2/3到4/5作为训练集,剩余样本作为测试集。当数据量级达到万或者更大时,此时测试集比例可以减小到1%。本文参考周志华[29]的《机器学习》和相关文献,结合数据量大小,随机选择了原始数据的80%作为训练集,其余20%作为测试集。
本文构建的多核模型的优势在于以下三点:(1)使用了四种重采样方法平衡数据集,解决原始数据类间不平衡问题。(2)使用多个核函数映射原始数据至不同的特征空间,实现了各特征空间信息互补,提高了原始数据信息利用。(3)将多核学习嵌入已经发展成熟的支持向量机模型,便于求解和实现。
多视图学习可以利用不同来源数据的互补信息,提高模型性能。而MKL通过其不同核函数映射构建融合矩阵可以很好地处理不同来源数据,如图像、声音、文本等,已被广泛应用于多视图学习。本文多核模型最高的准确率为0.87,虽然应用了多核学习提高了模型性能,但本质是在单一视图上进行多核学习,未收集到多视图数据,这是此次研究的不足。因此接下来的研究会收集MRI、PET-CT图像进行多视图多核学习,以进一步提高模型性能。
