基于深度学习的多模式权重网络语音情感识别
2022-10-08张晓宇,张华熊*,高强
张 晓 宇, 张 华 熊*, 高 强
(1.浙江理工大学 信息学院,浙江 杭州 310018;2.浙江传媒学院 媒体工程学院,浙江 杭州 310018)
0 引 言
在语音情感识别技术中,相对于传统机器学习算法[1],神经网络算法为语音情感识别的突破奠定了重要基础[2].近年来,深度学习在包括图像处理、图像识别、语音识别、自然语言处理等各大领域中的应用越来越广泛和深入,并且取得了显著的成效[3].深度学习在语音情感识别中的应用主要集中在两方面:一方面,手动提取语音特征,通过深度网络从特征中学习各个类别的特点[4]或者融合不同的特征[5],从而进一步建立模型预测语音信号的情感类别;另一方面,深度网络直接从原始语音信号中学习并提取不同情感类别的特征,进而建立模型预测情感类别[6].
尽管语音情感识别已经被关注很久,但它对研究者来说仍然是一个很大的挑战.语音情感数据集的匮乏,以及选取有效的语音信号特征是语音情感识别中存在的两大问题.在日常交流中,听话者本身就可以从声音的韵律信息和文本的语义信息中获取说话者表达的情感,Li等[7]应用目前主流的双向长短时记忆(bi-directional long short-term memory,BiLSTM)和注意力机制在音频、文本上分别实现了情感识别,然而其采用的声学特征一般是低阶描述符(low level descriptors,LLD),如基频、能量、过零率、梅尔频率倒谱系数(Mel-frequency cepstrum coefficients,MFCC)等特征,虽然LLD与原始信号密切相关,并有助于提取音频的即时语音特征,但它们不提供任何关于话语的全局信息.文本语义主要是通过体现情感的单词组合来表达,但单一文本信息同样不能捕捉足够的语音情感特征.频谱图中不同情感的图像表达有明显的区别,加上当前图像分类算法已取得了显著的成绩,于是通过图像分类进而识别语音情感成为语音情感分类的一种新尝试[8].虽然频谱图中包含了频域信息,不同的情感表达中,频域信息也有明显区别,但其图像也只包含部分语音情感特征.考虑到声学特征、语音转录的文本信息以及频谱图从不同角度表达语音情感并且不同特征信息在不同层面相互之间可以作为补充的情况,同时也受到Vo等[9]将文本和图像特征结合实现图像检索的启发,本文提出一个新颖的基于深度学习的多模式权重网络模型.模型没有单一使用某一类特征完成情感分类,也没有仅仅通过将多种特征提取后进行简单的拼接融合从而识别情感,而是综合考虑语音的声学特征、文本信息以及频谱图信息,利用网络自动学习获取权重来调节各个特征信息所占比重,进而构建模型预测音频信号情感类别.最近的关于音乐情感分析的研究[10]也证明了应用多模态信息包括音频和视频数据比使用单一特征识别效果更加显著.
获得声学、文本和频谱图三者之间的关系至关重要,因此,利用三者的一级分类概率作为输入搭建权重网络分类模型,让网络自动学习,赋予三者不同的权重,从而提高语音信号情感的识别率.另外,对于语音数据分类不均衡及数据量不足的问题,引入补充交叉熵[11].在频谱图分类方面,利用数据扩容以及加权随机采样函数和损失权重来改善这两个问题.
1 研究方法
本文充分利用目标声音信号的声学信息、文本信息、梅尔频谱图信息,将三者结合推断出目标声音信号所包含的情感.其中所提到的语音编码模型(audio encoding model,AEM)如图1所示,实现了从原始语音信号中提取MFCC特征,并将其输入到门循环单元(gate recurrent unit,GRU).GRU是循环神经网络(recurrent neural network,RNN)的一种,由多个时间步GRU Cell构成,是和长短时记忆(long short-term memory,LSTM)网络一样为了解决长期记忆和反向传播中的梯度问题而提出的网络,相比LSTM,网络具有更少权重,更易于计算.编码后的特征向量与韵律特征结合送入softmax层得到一级情感分类概率分布.文本编码模型(text encoding model,TEM)的输入信息为原始语音转换后的文本[12],首先使用预训练模型Glove[13]转换词向量后,同样利用GRU和softmax实现分类,模型流程如图2所示.频谱分类模型(spectral classification model,ICM)使用原始语音转换后的梅尔频谱图作为输入,通过ResNet-50预训练模型[14]实现图像情感分类.本文提出的多模式权重网络语音情感分析方法综合了上述3个单一模型的特征信息,通过自动优化权重获取更优的分类结果.
1.1 多模式权重网络编码分类模型
多模式权重网络编码分类模型(multi-modal weighted network encoding-classification model,MWEM)的目标是从不同角度分析原始语音信号,综合考虑多种特征,利用网络自动评估单一特征的重要性从而得到更准确的情感分类结果.具体模型如图3所示.
语音信号f作为整体模型的输入,经由AEM得到一个语音情感分类的概率分布Ps=(s1s2s3s4);另一方面声音信号转录的文本信息经过TEM得到情感分类的概率分布Pt=(t1t2t3t4);同时依据声音信号转换后的梅尔频谱图通过ICM得到概率分布Pi=(i1i2i3i4).每个单一模型预测的结果都是单一特征在情感分类中的体现,动态赋予不同模型预测结果不同的权重,也就意味着动态改变单一特征在整体分类中的影响,进一步提高情感分类精确度.权重网络内部利用每个单一模型概率分布的分量通过式(1)线性回归出最终分类概率的对应分量:
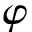
(1)
1.2 集成学习模型
集成学习模型(ensemble learning model,ENSELM)以stacking方法为基础.stacking方法是集成学习的方法之一,集成学习就是将多个弱监督模型组合起来以便得到一个更好、更全面的强监督模型.集成学习潜在的思想是即便某一个弱分类器得到了错误的预测,其他的弱分类器也可以将错误纠正回来[15].stacking是指训练一个模型用于组合其他模型.集成学习模型首先分别训练AEM、TEM、ICM,输出各个模型语音情感的概率分布.之后使用决策树作为二级分类器,将各个模型输出的分类概率作为新的输入数据,通过二级分类器得到一个最终的情感分类.具体如图4所示.
整体模型使用5折交叉验证.首先将原始数据按照4∶1的比例分成训练数据dr和测试数据de.同时将dr均分为5份,训练AEM时,从5折交叉验证数据dr中取出其中4折作为训练数据dra,其余1折作为测试数据dea.
每一次的交叉验证包含两个过程:(1)基于dra训练语音编码模型AEM;(2)利用训练好的模型AEM对dea进行预测.第1次交叉验证完成后得到关于dea的预测值a1.之后使用该模型对原始数据中的测试数据de进行预测,获取预测值b1.
5折交叉验证后,即完成对语音编码模型的整个训练及测试步骤后,可以得到预测值ak(k=1,2,3,4,5)和bk(k=1,2,3,4,5).其中ak就是对原来整个dr的预测值,将它们拼凑起来,形成一个含有m个元素的列向量,记为A1,m为dr样本总数.而对于bk这部分数据,将各部分相加取平均值,得到一个含有l个元素的列向量,记为B1,l为de样本总数.
对TEM和ICM同时进行上述步骤得到T1、I1、B2和B3.A1、T1、I1并列合并得到一个m行3列的矩阵作为二级分类器的训练数据drs,B1、B2、B3并列合并得到一个l行3列的矩阵作为二级分类器的测试数据des.最后利用drs训练决策树,得出des的预测值,即为最终的语音情感分类结果.
2 实 验
2.1 数据集
使用IEMOCAP[16]数据集来评估模型.IEMOCAP情感数据集由南加利福尼亚大学录制,共包含5个会话,每个会话由一对男女一起演绎,表演情感剧本以及即兴的场景.数据集时长近12 h,包括视频、语音和文本,共包含10 039句话语,每句话平均时长为4.5 s,由至少3个标注者使用分类标签对其进行标注.数据集一共含有9种情感,分别是生气、高兴、兴奋、悲伤、沮丧、害怕、惊讶、其他和中性.为了将实验结果与近期语音情感分类成果作对比,选择与他们实验应用同样的5种情感数据,包括生气、高兴、兴奋、悲伤和中性,并将高兴和兴奋情绪的数据都归为高兴类,故最终应用的数据集共5 531个句子,包含生气、高兴、悲伤和中性4种情感.
2.2 数据预处理
在语音识别领域中最常用的语音特征就是MFCC,该系数主要用于提取语音数据特征和降低运算维度.对连续语音数据进行预加重、分帧、加窗、快速傅里叶变换等操作后获取39维MFCC特征.为了包含更多的语音特征信息,使用了目标语音的韵律特征作为判断依据之一.韵律特征是对比性特征,因此它们的相对变化幅度为主要关注点.包含不同情感的语音在韵律特征上表现不同.选取包括谐波特征、响度轮廓、F0过零率在内的35个韵律特征.图5为含有高兴情感和悲伤情感的语音信号谐波特征,图6为二者的语音能量特征,也就是响度,使用均方根误差(root-mean-square error,RMSE)来量化此特征.上述语音特征都使用OpenSMILE工具包[17]提取.
为了将文本信息注入文本编码模型,使用自然语言工具包(natural language toolkit,NLTK)对文本信息进行标记,之后通过Glove转换词向量,每个词向量都包含上下文含义,维度为300.
频谱分类模型的输入为图像,首先利用librosa 工具将每段语音信号转换为梅尔频谱图,为了方便图像分类,去除了图像横、纵坐标轴,并为保证接下来模型训练过程图像输入数据和语音及文本保持一致,对图像按照“编号+情感类别”的规则重命名.
2.3 实施细节
由于语音数据的不均衡,整个实验使用5折交叉验证以便获得模型稳定的分类.在AEM和TEM中,采用GRU(隐藏层维度为200)作为编码神经网络.按照默认设置,以学习率0.001开始执行1×104次,为防止过拟合,设置了早停,发现基本到50次迭代时损失值趋于稳定,设置以20、30、50次迭代为界每次学习率缩小10%.为了使得模型收敛速度更快,使用WarmUp预热学习率方式,设置预热迭代次数为5.频谱图分类模型中使用ResNet-50(输出特征维度为4)预训练模型作为图像编码器.
在训练完整权重分类模型过程中为了判定实际输出与期望输出的接近程度,通常使用交叉熵函数.交叉熵刻画的是实际输出(概率)与期望输出(概率)的距离,即交叉熵的值越小,两个概率分布就越接近.普通交叉熵计算公式如下:
(2)
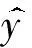
然而语音情感数据集存在分类不平衡问题,为了减少数据分类不平衡问题的影响,引入了补充交叉熵,该交叉熵不同于普通交叉熵的地方在于训练过程中均衡地抑制了不正确分类的softmax概率,该方法不需要额外增加少数类别样本.
引入补充交叉熵后交叉熵具体定义如图7所示.
补充交叉熵为
(3)
加上调节因子后
(4)
最终交叉熵形式为
(5)
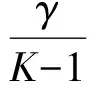
为了验证权重模型的优越性,基于AEM、TEM和ICM进行了集成学习实验,使用决策树作为二级分类器,具体实验方法见1.2.
3 实验结果
3.1 评估准则
(1)正确率(accuracy)
该指标表示语音信号情感分类中正负样本被正确分类的比例.
(2)精确率(precision)
该指标是针对语音情感预测结果而言的,表示预测为正的样本中实际为正样本所占的比例.
(3)召回率(recall)
该指标是针对语音情感原始标签而言的,表示语音信号样本中的正类有多少被预测正确了.
(4)F分数(F-score)
由于精确率和召回率往往成反比关系,也就是说提高精确率,召回率一般情况下会降低.F分数的目标就是为了平衡二者,综合考虑二者的调和值.
将权重分类模型分别与单一特征模型、应用集成学习方法模型的效果作比较,并且和近年来同样在IEMOCAP数据集上实现语音情感分类的模型进行比较.
3.2 实验结果
将所有语音、文本、图像数据按8∶0.5∶1.5的比例分为训练集、验证集和测试集.使用5折交叉验证训练模型.从表1可以看出,使用相同的数据集,多模式权重模型分类结果按照不同的评估准则,要么优于现有的文本语音特征结合的分类模型,要么与该模型结果相当.6个模型4类情感分类结果的正确率和混淆矩阵分别见图8、9.为了进一步证明实验方法的有效性,本文与现有模型CNN-LSTM+CNN[18]、CNN-BiLSTM-Attention[19]、Multi-Level Multi-Head Fusion Attention+RNN[20]进行比较,如表2所示.具体结果分析如下:
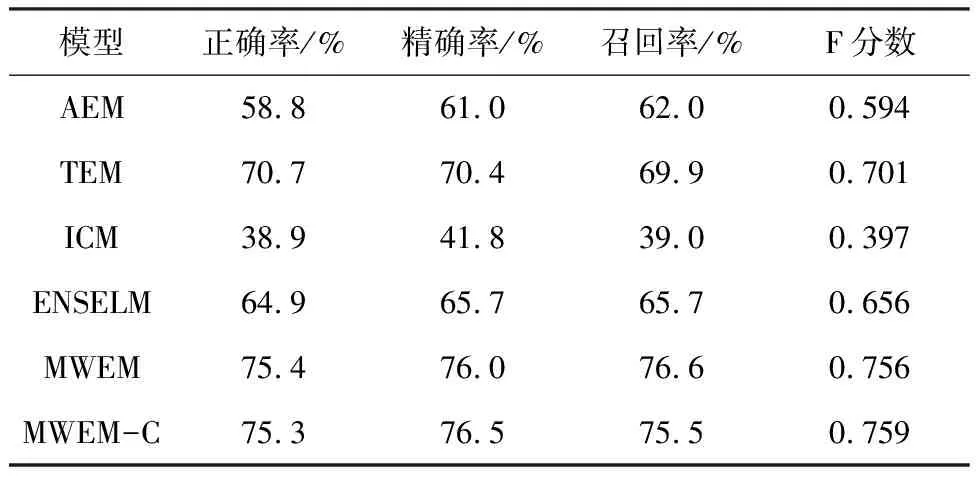
表1 6种模型识别结果
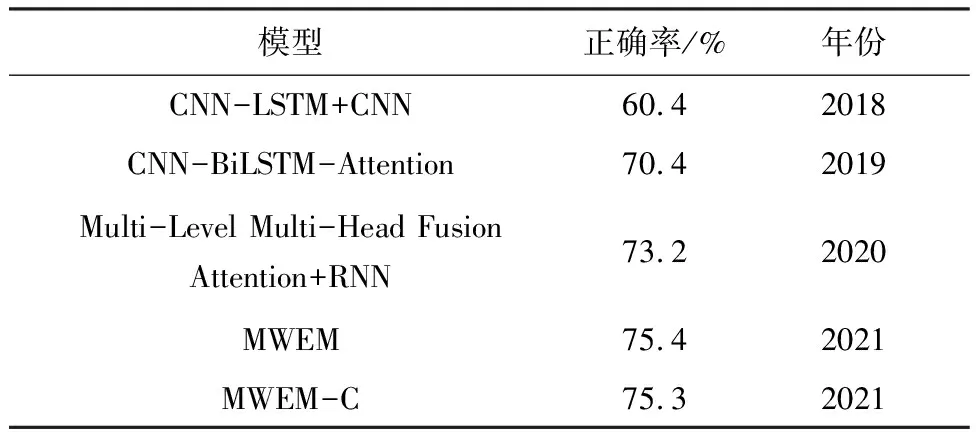
表2 与以往基于IEMOCAP结果的比较
(1)仅AEM用于语音情感分类
AEM模型整体分类正确率为58.8%,仅有过半的数据分类准确.从该模型的混淆矩阵中可以看出有29.29%含有高兴情绪的语音数据被错误地分类为中性情感,而对于悲伤情感的区分正确率高达89.44%.含悲伤情感的语音在声音特征上较其他情感辨识度更高.
(2)仅TEM用于语音情感分类
TEM模型较AEM模型分类正确率有了质的提高,正确率突破70%,并且各种情感分类正确率都超过65%,高兴情感的区分正确率也上升到79.50%,比AEM模型中高兴情感分类正确率提高了近40%,这一结果归因于表达快乐和中性情感的词语比起声学信号数据中的表达,在文本差异上更加明显,同时也证明了文本和语音在判别情感的过程中起到互补作用.出乎意料的是,有13.38%的含有悲伤情绪的语音被错误地划分在了高兴类别中,这是两种近乎完全相反表达的情感.
(3)仅ICM用于语音情感分类
或许是由于语音数据集相比纯用于图像分类的图像数据来讲数量上远远不够,ICM无法充分学习每一类语音信号的频谱图像特征,致使频谱图分类效果并未达到预期,正确率仅为38.9%,其中最易混淆的是悲伤情感和中性情感,61.50%的中性情感语音数据被错误地归为悲伤情感分类,同时71.13%的悲伤情感语音数据被错误地归为中性情感分类.
(4)使用ENSELM用于语音情感分类
利用传统的集成学习方法将单一模型输出的分类概率通过一个二级分类器重新获得分类结果,从该模型的混淆矩阵来看,含有生气情感的语音类别识别率有所提高,超过了70%,然而其他3个分类结果较文本编码分类模型偏弱,中性情感的分类正确率仅为55.66%.总体来看,该模型的分类正确率仅为64.9%.一般来讲,综合模型的分类结果应优于单一模型的结果,但由于基于集成学习方法的分类模型在初期数据处理方式有很大不同,一级分类模型各自训练时,首先将训练数据划分为训练数据和测试数据,大大减少了训练数据的数量,由此可能导致分类正确率变低.
(5)使用MWEM、MWEM-C用于语音情感分类
该模型结合了先前AEM、TEM、ICM 3个模型的特性,并且利用权重网络,自动学习三者的权重比值,弥补了各个模型的缺陷,放大了各个模型优势,使分类结果更加准确.使用普通交叉熵分类模型MWEM和使用补充交叉熵的权重分类模型MWEM-C与以往基于IEMOCAP情感识别模型结果相比,正确率有了很大提升,混淆矩阵的混乱程度大大减轻.并且MWEM-C对于每一类别情感的识别正确率都超过了74%,其中对高兴情感的识别正确率高达82.01%,这大大优于现有模型分类结果.
4 结 语
语音情感识别研究中,有效特征的选取以及使用单一特征的模型往往不能达到很好的分类效果是研究过程中两个重要挑战.本文提出了一种基于深度学习的多模式权重网络模型用于语音情感识别,该模型提取语音的声学特征、语音转化成文本后的语义特征、语音频谱特征后,不是简单地将其拼接融合,而是通过网络学习自动有效地赋予三者不同的权重,保留了全局信息和局部信息,特征更全面,识别效果更好.MWEM在4种情感分类正确率上达到75%,与单一特征分类模型以及应用集成学习方法实现情感分类模型相比分类性能显著提高,同时实验结果也证明了MWEM在IEMOCAP数据集上实现了很好的语音情感分类效果.
鉴于原模型中频谱图分类效果弱,在未来的工作中,将在频谱图分类方面进行优化,寻找更加适合的网络模型,同时对图像数据做增强处理,突出各类别频谱图的特性,从而进一步优化权重网络模型.
