融合对抗训练和胶囊网络的食品安全关系抽取模型
2022-09-30董哲王亚马传孝李志军
董哲, 王亚, 马传孝, 李志军
(北方工业大学电气与控制工程学院, 北京 100144)
近年来食品安全事件频发,食物中的有毒、有害物质对民众的身体健康带来急性、亚急性或者慢性危害。同时,随着互联网的快速发展,网络数据规模增长迅速,其中包括大量的有关食品安全的文本数据。但是目前对食品安全领域内现有数据资源的分析利用工作较少,因此,如何高效准确地从非结构化的食品安全文本中提取出重要信息并将其转化为知识是构建食品安全领域知识图谱的前提,也是促进食品安全工作智能化发展的关键一步,而实体关系抽取是实现信息抽取的重要环节。食品安全领域关系抽取是在已知食品安全文本中相关实体的基础上,识别出实体之间的关系,例如从“沙门菌常出现在猪肉中”提取出“沙门菌”和“猪肉”间的关系。
最早的实体关系抽取主要是基于模式规则的,该方法主要由相关领域的专家人工编写抽取规则,然后根据定义好的领域相关的抽取规则与目标文本做匹配。例如,Miller等[1]采用了对实体信息词汇化和概率分布的上下文无关的语法解析器,生成规则用于关系抽取。邓擘等[2]提出了一种将词汇语义匹配技术和模式匹配技术结合的汉语实体关系提取技术,且实验表明该模型的性能较单独的模式匹配抽取方法有明显提升。Aone等[3]通过分析语料特点,并基于相关领域专家设计规则,抽取文本中与规则相匹配的关系实例。
随着机器学习的发展,关系抽取的主流研究方向大量迁移至机器学习领域。Kambhatla等[4]综合实体上下文信息、句法分析树、依存关系等多种特征,将词汇、句法和语义特征与最大熵模型相结合进行关系分类。甘丽新等[5]提出一种基于句法语义特征的实体关系抽取方法,融入了句法关系组合特征和句法依赖动词特征特征项,并使用支持向量机(support vector machine,SVM)进行关系分类。黄卫春等[6]提出一种基于特征选择的方法对人物关系进行抽取,对比了四种特征选择方法,将特征选择后得到的特征向量进行降维,最后使用SVM进行关系抽取。Yan等[7]融合依存特征和浅层语法模板,提出了一种模式组合的聚类方法,可以在不同语料的关系抽取中实现高精度聚类。
近年来,各种深度学习方法被应用于关系抽取领域。张永真等[8]将词性、位置、上下文等传统特征和句法语义特征相结合进行专利文本三元组的抽取,并通过极端梯度增强算法(extreme gradient boosting,XGBOOST)对各特征进行有效性分析,证明了方法的有效性;Li等[9]将双向长短期记忆网络(bi-directional long short term memory network,BiLSTM)与卷积神经网络(convolutional neural network,CNN)相结合,并通过softmax函数来模拟目标实体之间的最短依赖路径,用来进行临床关系抽取。黄培馨等[10]引入对抗训练以提高模型的鲁棒性,同时采用带有偏置的损失函数增强模型提取实体对的能力。丁泽源等[11]使用BiLSTM+CRF模型进行中文生物医学实体识别,然后使用基于注意力机制的BiLSTM抽取实体间的关系。肜博辉等[12]提出了一种基于多通道卷积神经网络关系抽取的方法,各通道的输入均为不同的词向量,以此提高模型的语义表征能力。田佳来等[13]使用解决序列标注问题的方式来进行实体关系联合抽取,并进行分层序列标注,这种新型标记方式对与重叠三元组抽取的有效。
尽管这些深度学习方法在中文关系抽取任务上取得了显著的进步,但是深度学习方法通常是基于大量有标注的数据来充分学习数据的特征。食品安全领域关系抽取任务存在以下难点。
(1)食品安全领域涉及到的实体类型和关系种类较多且复杂,不仅有食品、病菌等与食品相关性强的实体类型,还涉及食物中毒导致的症状、抑制病菌的抗生素、食品中出现的化学物质等实体类型,实体间的关系交错使得关系种类也变得复杂。
(2)食品安全领域中的实体通常专业性较强,如“类志贺邻单胞菌”“椰酵假单胞菌”等,且有些实体是由多种类型字符组合而成,如“4-甲基吡唑”“维生素K3”等。
(3)食品安全领域缺乏大规模高质量的标注语料库。
因此,现有的针对通用语料库的模型和方法在实体类型和关系种类复杂且缺少标注数据的食品安全领域无法得到有效的应用。针对以上问题,本文提出了一种融合对抗训练[14](adversarial training)和胶囊网络[15](capsule network,CapsNet)的食品安全领域关系抽取模型GAL-CapsNet。该模型使用BERT进行文本向量化表示,获取具有丰富特征表达的字向量,同时在字向量上添加可能使模型产生错误判断的微小扰动生成对抗样本,提高模型的鲁棒性。然后通过BiLSTM捕获上下文信息获取全局特征,再利用CapsNet矢量神经元的特性和动态路由机制获取高层次的局部特征。多尺度的特征融合和胶囊矢量对特征的充分利用使得模型具备较强的文本序列理解能力,能够从小规模数据集中学习到有效特征,在提高模型性能的同时保证计算效率,从而准确高效地实现食品安全文本的关系抽取任务。
1 GAL-CapsNet模型
本文提出的模型主要由三大模块组成:嵌入模块、全局特征提取模块、胶囊网络模块。其整体框架如图1所示。
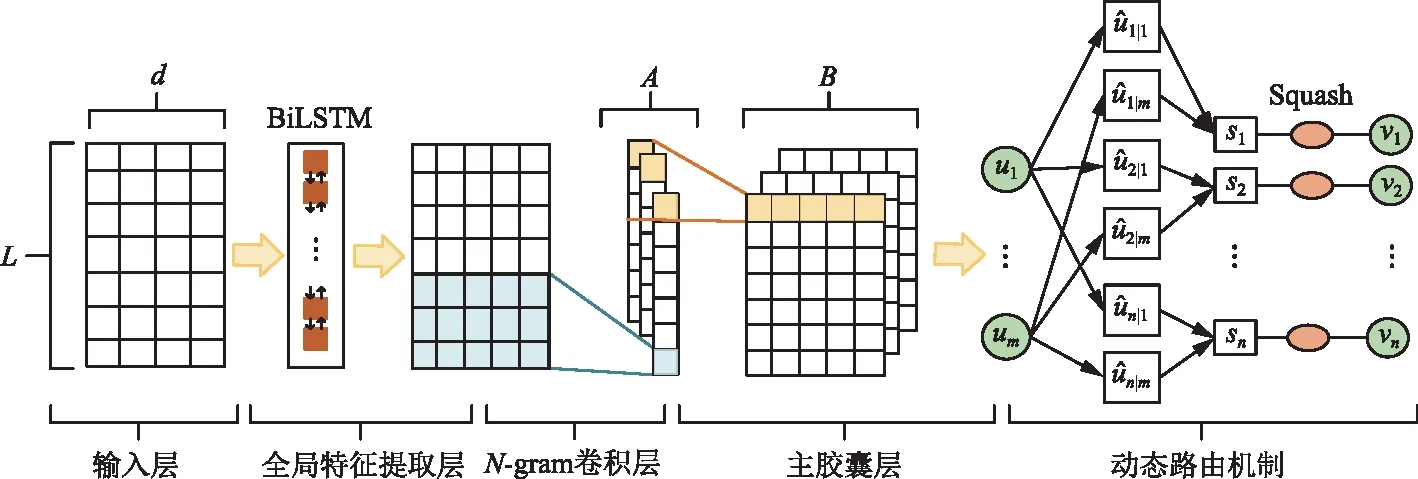
图1 GAL-CapsNet模型Fig.1 GAL-CapsNet model
1.1 嵌入模块
1.1.1 文本表示
关系抽取需要考虑语料的语义和实体的位置特征。嵌入层通过将文本序列中的每个字符转化为向量,来表示文本的语义信息。对于一条文本序列有
S=[w1,w2,…,wL]
(1)
式(1)中:L为文本序列的长度;wi为文本序列中的第i个字符。
BERT的输入层是由词向量Etoken(wi)、段向量Eseg(wi)和位置向量Epos(wi)3部分组成的,将这3部分相加作为BERT的输入Ei,即
Ei=Etoken(wi)+Eseg(wi)+Epos(wi)
(2)
再经过基于Transformer的预训练模型,将每个字符wi转化为维度为dw的向量xwordi,得到输入语句的字向量表示[xword1,xword2,…,xwordL],具体结构如图2所示。
同时,将文本序列中每个字符wi与头实体e1的相对位置p1,与尾实体e2的相对位置p2分别映射成维度为dw的距离向量xpos1i和xpos2i。
最后将字符的语义信息和位置信息进行融合,作为全局特征提取层的输入,即
X=[x1,x2,…,xL]
(3)
式(3)中:xi=xwordi+xpos1i+xpos2i。
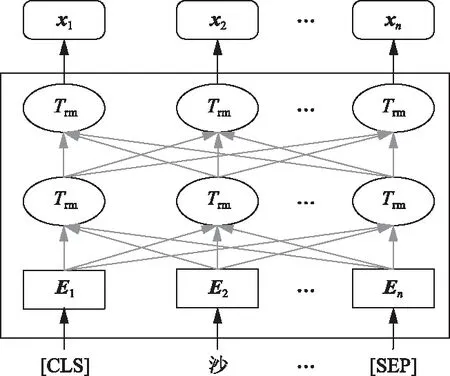
[CLS]代表输入序列的开始,[SEP]为分隔符,用来分隔同一 输入序列中的子句 图2 BERT预训练模型框架Fig.2 BERT pre-training model framework
1.1.2 对抗训练
Goodfellow等[14]在2014年首次提出了对抗训练,并将其应用于机器视觉领域。对抗训练是一种提高神经网络鲁棒性的重要方式,其在训练过程中,向样本中加入可能使模型产生错误判断的微小扰动,并且使神经网络适应这种改变,以此提高模型的鲁棒性。
为了提高文本表示的质量,在嵌入层加入对抗训练,生成对抗样本,并将对抗样本放入模型中训练,从而提升模型的抗扰动性能。
最优的对抗扰动,通常是指在最坏情况下的扰动,这个扰动能使模型的损失最大化[16],即
(4)
式(4)中:x表示长度为L的原始文本序列;y表示输入序列对应的输出;r表示对输入的扰动,对于文本序列中的每一个字符xi都存在相应的扰动ri(i∈{1,2,…,L});Loss为交叉熵损失函数;ε是一个标量,用来约束扰动的大小;θ′表示当前网络的参数,对抗损失不进行反向传播。在训练的每一步,确定当前模型最坏情况的扰动radv。并通过最小化方程来训练模型对这种扰动具有鲁棒性。然而,一般不能准确地计算这个值。Goodfellow提出通过Loss围绕x线性化来近似得到radv的值,即

(5)


(6)
式(6)中:λ为一个超参数,用来平衡两个损失函数。
1.2 全局特征提取模块
输入文本经过嵌入层得到的是独立的单个字符本身的特征信息,为了得到融合前后文信息的特征向量,采用双向长短期记忆网络(bi-directional long short term memory network,BiLSTM)进行全局特征提取。本层将嵌入层得到的特征表示分别输入到含有h个隐藏单元的前向和后向长短期记忆网络中。LSTM的单元结构如图3所示。
在t时刻,LSTM计算新状态为
ft=σ(Wf[ht-1,xt]+bf)
(7)
it=σ(Wi[ht-1,xt]+bi)
(8)
(9)

图3 LSTM内部结构图Fig.3 Internal structure diagram of LSTM
ct=ft⊗ct-1+it⊗c′t
(10)
ot=σ(Wo·[ht-1,xt]+bo)
(11)
ht=ot⊗tanh(ct)
(12)
式中:⊗为按元素乘,Wf、Wi、Wc、Wo为权重;xt为t时刻LSTM的输入,bf、bi、bc、bo为偏置项。ft为遗忘门的输出;it为输入门的输出;ot为输出门的输出;ct为t时刻的细胞状态;c′t为t时刻的候选细胞状态;ht-1为t-1时刻该单元的最终输出;ht为t时刻该单元的最终输出。
LSTM能够有效处理文本序列的长距离依赖,单向LSTM只能从前向后传递信息,但是想要充分理解文本序列,通常需要从整体上分析其语义。因此采用BiLSTM进行序列的全局特征提取,使得模型能够学习到更多的上下文信息。全局特征提取模型结构如图4所示。
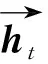
(13)

图4 BiLSTM结构图Fig.4 Structure diagram of BiLSTM
1.3 胶囊网络模块
1.3.1 N-gram卷积层

(14)
式(14)中:⊗表示卷积运算;f()表示ReLU激活函数;b0为偏置项。N-gram卷积层共有A个步长为1的滤波器,设M为通过卷积层得到的特征映射矩阵,则有M=[m1,m2,…,mA]∈R(L-K+1)×A,其中mi∈RL-K+1,i∈{1,2,…,A}。
二是完善集团化运作体制。不断完善省农垦集团-产业集团和区域集团-子公司(含农场基地公司)三级运行架构。其中,省农垦集团公司定位为战略决策中心、资本运营中心、监督控制中心和支持服务中心;产业集团定位为产业运营中心、利润中心,从事产业运营,实现经营资产的保值增值;区域集团定位为资产管理中心、利润中心;子公司(含农场基地公司)定位为经营管理中心、成本控制中心,直接从事生产经营管理。
1.3.2 主胶囊层
与传统卷积神经网络不同,胶囊网络采用矢量输出来保存实例化参数。主胶囊层滤波器Wb∈RA×d1在不同的向量Mi∈RA(i∈{1,2,…,L-K+1})上滑动生成特征映射u∈R(L-K+1)×d1,其中每一个胶囊向量ui∈Rd1,计算公式为
ui=g(Mi⊗Wb+b1)
(15)
式(15)中:g()为非线性挤压函数;b1为偏置项。主胶囊层有B个步长为1的滤波器,因此共产生(L-K+1)×B个d1维胶囊。
1.3.3 全连接胶囊层
主胶囊的输出向量通过与权重矩阵相乘得到浅层胶囊,然后通过动态路由机制传送到文本胶囊中,文本胶囊的输出向量vj计算步骤为

(16)

(17)
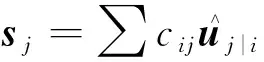
(18)

(19)

(20)

2 实验与结果分析
2.1 实验语料获取
模型训练所需数据集选用独立构建的食品安全领域关系抽取数据集(relation extraction of food data,RE-FOOD)。将收集的语料以句为单位进行人工标注得到食品安全领域数据集(RE-FOOD)并作为实验使用的数据集。在数据集中随机选取20%的语料作为测试集,70%的语料作为训练集,10%作为验证集,数据集的相关统计数据如表1所示,关系类型如表2所示。
2.2 实验参数设置
本文实验使用768维的词向量。模型中,LSTM模块隐藏层神经元个数设置为128;N-gram特征提取层使用32个(A=32)卷积滤波器,窗口大小为3(k=3),

表1 数据集情况统计Table 1 Statistics of data sets

表2 实体关系表Table 2 Entity relationship
主胶囊层使用32个滤波器(B=32)生成10维的胶囊向量(d1=10),全连接胶囊层生成12个文本胶囊(D=12)表示12个关系种类。本文取模长最大的文本胶囊向量所对应的关系种类作为最后结果。
2.3 评价指标
本文使用采用精确率P(precision)、召回率R(recall)、F1值对算法的有效性进行综合评估,三个指标的定义为

(21)

(22)

(23)
式中:TP表示正类预测正确的数量;FP表示负类预测错误的数量;FN表示正类预测错误的数量。
2.4 实验结果分析
2.4.1 对比实验分析
采用4种不同的模型进行食品安全领域关系抽取任务实验。实验1使用包括3层卷积、3层池化以及1层全连接层的CNN,其中卷积和池化的移动步长都设置为1,实验2使用双层隐藏神经元个数为128的BiLSTM,实验3使用四头注意力的Transformer,实验4使用3层GCN的GCNs,实验4是本文提出的GAL-CapsNet。表3为关系抽取实验结果。
由实验结果可以看出,GAL-CapsNet模型在食品安全文本数据集上的三个评价指标值均为最高,精确率、召回率和F1分别达到了85.91%、82.82%、84.33%。在无对抗扰动时,与CNN、BiLSTM、Transformer和GCNs相比精确率分别提高了43.84%、27.78%、34.52%、33.89%,在有对抗扰动时,与CNN、BiLSTM、Transformer和GCNs相比精确率分别提高了43.65%、25.39%、30.15%、29.36%。CNN在本文数据集上的关系抽取效果较差是因为CNN的池化操作容易丢失重要信息,且捕捉全局特征的能力较差。Transformer和GCNs则是因为没有考虑输入序列位置信息,无法捕捉顺序序列特征。GAL-CapsNet模型进行了多尺度的特征提取,利用BiLSTM提取全局特征,利用卷积核提取局部特征,具备较强的文本序列的理解能力。同时常用的词向量方法(Word2Vec)生成的是静态词向量,且词向量训练过程中难以获取大量食品安全文本进行训练,因此在食品安全领域上效果较差。而 BERT在大规模语料上进行预训练,然后在食品安全文本上对其参数进行微调,生成的动态词向量更加符合数据特征,因此在食品安全文本上采用BERT编码能获取更加丰富的特征表达。
此外,根据实验结果可以看出,在加入对抗训练后,精确率上CNN提高1.61%、BiLSTM提高3.81%、Transformer提高5.79%、GCNs提高5.95%、GAL-CapsNet提高1.42%。说明在数据集规模较小的情况下,对抗训练可以有效提高关系抽取模型的性能。其比较结果如图5、图6所示。

表3 实验结果对比Table 3 Experimental results

图5 不同模型的消融实验对比Fig.5 Comparison of ablation experiments of five models

图6 不同迭代次数实验效果比较Fig.6 Comparison of experimental effects with different iteration times
表4为五个模型在同一设备上的训练时长,平均训练时长为153.530 8 s。从表4中可以看出GAL-CapsNet模型的训练时长与BiLSTM和Transformer相比缩短了103.477 9 s和71.959 s,与CNN和GCNs相比增加了11.953 7 s和52.826 6 s,低于平均训练时长。结合表3和表4中的数据可以看出,GAL-CapsNet模型在提高关系抽取任务性能的同时保证了模型的训练效率。
2.4.2 动态路由迭代次数的选择。
胶囊网络通过囊间动态路由算法生成文本胶囊并迭代更新参数。为使模型的性能达到最优,通过设置不同的迭代次数进行实验,选择动态路由的最佳迭代次数,实验结果如图8所示。由实验结果可知,当迭代次数小于4时,胶囊网络的性能随着迭代次数的增加逐渐提升,模型对输入序列的特征学习更加充分。当迭代次数大于4时,胶囊网络的性

表4 模型训练时长Table 4 Model training time
能随着迭代次数的增加逐渐降低,这是由于模型的过度学习导致其泛化能力降低。实验结果表明,当动态路由的迭代次数设置为4时,模型的精确率、召回率以及F1均为最优。
3 结论
针对食品安全领域关系抽取数据集体量小且关系种类复杂的问题,提出了一种融合对抗训练和胶囊网络的食品安全领域关系抽取模型GAL-CapsNet。GAL-CapsNet模型通过BiLSTM捕捉文本序列上下文信息,解决了传统CapsNet在处理文本时缺乏远距离依赖关系的能力,通过CapsNet进行高层次的局部特征获取,使模型充分理解文本序列的语义,同时通过对抗训练进行数据增强,提升模型的抗干扰能力。实验结果表明,本文的方法比其他方法在食品安全领域关系抽取任务上的精确率、召回率、F1分别至少提升了25.39%、20.29%、22.82%,在模型精度提升的同时保证了模型的计算和存储效率,证明了本文模型在食品安全领域关系抽取任务中的可行性。下一步研究工作将基于本文模型进行多种特征融合,从而进一步提高关系抽取效果。
