知识图谱的候选实体搜索与排序①
2022-01-06沈航可祁志卫张子辰
沈航可, 祁志卫, 张子辰, 岳 昆
(云南大学 信息学院, 昆明 650500)
1 引言
知识图谱(Knowledge Graph, KG)[1]作为实体关系的语义网络, 在相关实体搜索的应用中至关重要, 是搜索引擎的重要支撑技术[2].基于KG的相关实体搜索旨在根据给定的实体, 在KG中搜索与此实体相关的候选实体集合, 并按照候选实体与查询实体间的相关度对候选实体进行排序并返回结果, 以提高用户的搜索体验.事实上, 随着互联网的高速发展, Web文档快速产生, 反映了现实世界不断演化的知识, 与KG中的知识共同描述了实体间的相关关系.因此, 如何有效地表示实体在KG和Web文档中的关系信息, 进而准确地搜索与给定实体相关的候选实体, 并对候选实体进行排序, 对提升相关实体搜索的准确性具有重要意义.虽然现有方法能够有效地获取相关实体, 减少用户搜索时需要过滤的无用信息, 但仍存在如下挑战:
(1) 与实体相连的不同关系能够表示实体不同的语义[3,4], 因此, 需要一种能够有效表示不同关系中实体的语义并准确搜索候选实体的方法.
(2) 由于Web文档与KG共同描述了实体间的相关关系, 为了准确地对候选实体进行打分排序, 需要一种能够根据实体在Web文档与KG中的关系信息来计算候选实体与查询实体间相关度的方法.
针对挑战(1), 现有方法主要根据查询实体的邻居节点来搜索候选实体, 如Huang等[5]使用与查询实体直接相连的实体作为候选实体集, Reinanda等[4]获取以查询实体为中心的k阶子图, 并基于子图的路径信息搜索候选实体.上述方法在小规模KG中表现尚可,而当KG规模较大时, 需要搜索的候选实体会出现在查询实体的邻居实体集外, 导致无法正确搜索到候选实体.对此, 现有的表示学习方法[5-7]将高维、复杂的KG映射到低维的向量空间中, 进而降低在大规模KG上的计算开销.为了更加有效地搜索候选实体, 本文基于TransH模型[7]提出候选实体搜索算法, 首先去除对查询实体不重要的关系, 降低搜索的时间代价.然后通过KG的嵌入向量计算出实体在各关系对应超平面上的投影, 作为不同关系下实体的语义表示.由于候选实体与查询实体有共同的语义特征[2], 因此, 为了有效地搜索候选实体, 我们根据实体的语义相似度对各超平面中的投影进行聚类, 进而得到与查询实体有共同语义特征的候选实体.
针对挑战(2), 现有方法大多基于KG来计算实体相关度, 例如, Milne等[8]提出了WLM方法, 基于KG中实体所对应Wikipedia页面的超链接完成实体间的相关度计算.Ponza等[9]提出了TSF (Two-Stage Framework)方法, 利用KG实体间的连接关系构建带权有向图, 并基于CoSimRank算法[10]来计算实体间的相关度.这些算法能反映KG中实体间的相关性, 但由于现有KG的知识仍不完整[11], 导致计算结果不够准确.对此, Yamada等[12]通过将描述实体的词汇和KG中的实体共同映射到向量空间, 以计算实体间的相关性.该方法虽能将词汇与KG相结合来发现实体间的相关性,但在映射过程中会损失KG实体间的关系信息, 导致计算结果不够准确.因此, 为了更准确地计算查询实体与候选实体间的相关度, 我们提出实体无向带权图模型(Entity Undirected Weighted Graph, EUWG).首先,以查询实体与候选实体作为图中节点, 基于查询实体与候选实体间的相关关系来构造无向边.然后, 通过量化实体在KG向量空间和Web文档中体现出的相关性, 计算EUWG边上的权重, 得到查询实体与候选实体相互间的相关度, 并基于该模型提出一个候选实体打分函数, 通过遍历EUWG中实体间的路径计算候选实体的分数, 完成候选实体的排序.
最后, 使用Wikidata数据集, 对所提出的方法进行了实验测试和性能分析, 与现有的候选实体搜索算法和实体相关度计算模型进行比较, 验证了本文提出方法的有效性.
2 候选实体搜索
2.1 查询实体关系选择
定义1.KG是由实体和关系组成的有向图, 表示为Gkg=(E,R), 其中,E={e1,e2,…,en}为实体集合,R={r1,r2,…,rm}为关系集合, 任意一条有向边表示一个三元组(h,r,t) (h,t∈E和r∈R).Gkg也可看作三元组集合.
首先, 将给定的查询实体记为eq, 为了增加搜索候选实体的效率, 本文提出从全局重要度和局部重要度两方面来度量关系r对eq的语义表示能力, 去除对eq语义表示能力弱的关系, 减少需计算的关系数量.
(1) 全局重要度, 即关系r在KG中的重要程度.r在Gkg中出现的频率越高, 其对eq的特殊性就越小, 重要性也就越小.按以下方式计算r对eq的全局重要度:

其中,r′为r在Gkg中出现的次数.
(2) 局部重要度, 即关系r在以查询实体eq为中心的局部子图中的重要程度.将KG中与eq直接相连的边构成的集合记为R′(eq),r在R′(eq)中出现的次数越多, 说明eq通过r连接的实体越多, 进而r对eq就越重要.r在R′(eq)中出现的次数与其重要程度成反比,计算公式如下:
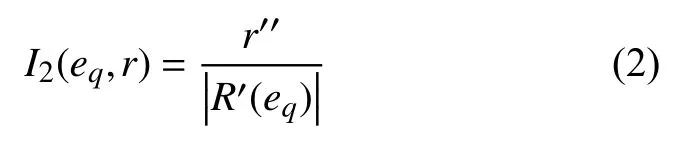
其中,r"为关系r在R′(eq)中出现的次数, |R′(eq)|为R′(eq)中三元组的个数.
然后, 使用超参数α来平衡上述因素对关系r语义表示能力的贡献.为了统一I1(eq,r)和I2(eq,r)的取值区间, 使用最大最小归一化函数(Min-Max Scaling)[13]对全局重要度和局部重要度进行处理, 计算公式如下:
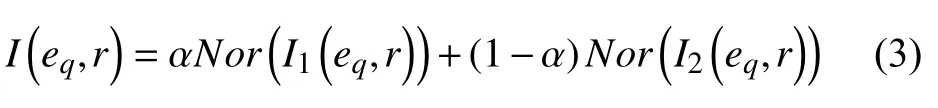
其中,α∈[0,1], 为衡量各因素贡献比重的超参数,Nor(·)为最大最小归一化函数.
最后, 为了提高候选实体搜索的效率, 通过式(3)计算KG中各关系对查询实体eq的语义表示能力并对各关系进行排序, 选择其中得分最高的前k个关系, 记为集合S.
2.2 查询实体关系选择
首先, 将KG中的实体通过训练嵌入到向量空间中, 得到对应的实体向量集E={e1,e2,…,en}, 其中,ej∈E(1≤j≤n)是实体ej的向量表示.将与关系集合S对应的超平面法向量集记为D={d1,d2,…,dk}, 将与集合D中第i个法向量对应的关系记为ri∈R(1≤i≤k).使用式(4)计算实体ej在ri对应超平面上的投影, 如图1所示.

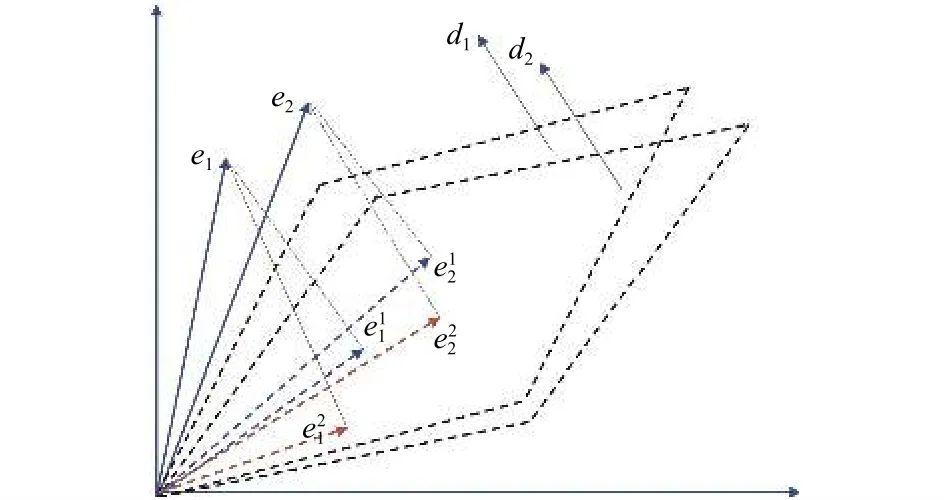
图1 实体在各超平面中的投影
然后, 为了正确地在各超平面中搜索候选实体, 将每一个实体向量ej在超平面di(1≤i≤k)上的投影作为该实体在ri对应超平面中的语义表示, 并根据实体在不同超平面中的语义表示, 将具有共同语义特征的实体划分为一类.具体而言, 由于K-means++算法[14]的效率高、能够高效地对海量实体进行划分[15], 因此, 通过投影向量间的余弦相似度表示对应实体在ri下的语义相似度, 使用K-means++对D中各超平面上的实体投影进行聚类, 将与同属一类的投影所对应的实体作为di上与eq有共同语义特征的实体.选择每个超平面中都与eq同属一类的实体, 作为候选实体搜索的结果,计算公式如下:
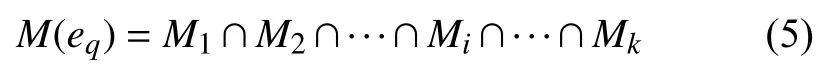
其中,M(eq)表示候选实体搜索的结果.

算法1.候选实体搜索算法输入: eq: 给定的查询实体; Gkg: KG; S: 对eq影响最大的前k种关系集合输出: M(eq): 候选实体集1.使用TransH将Gkg嵌入到向量空间中, 获得实体向量集E和与S对应的超平面法向量集D={d1, d2,…, dk}2.for i=1 to k do 3.Ni←Ø 4.for each ej in E do images/BZ_52_1390_1682_1570_1732.png5.// ej在第i个超平面的投影 images/BZ_52_1429_1737_1454_1787.png images/BZ_52_1992_1737_2017_1787.png6.将 添加到集合Ui中, 将第i个超平面中 与ej的映射关系添加到Ni中7.end for 8.K-means++(Ui) //对Ui中的实体投影进行聚类 images/BZ_52_1631_1944_1656_1994.png9.找到聚类结果中与 同属一类的投影在Ni中对应的实体, 将实体添加到集合Mi中10.end for 11.M(eq)=M1∩M2∩…∩Mi∩…∩Mk 12.return M(eq)
算法1主要的时间代价是在k个超平面中对实体投影进行聚类, 假设聚类类别数为n′, 每一次聚类的时间复杂度为O(n′n)[14], 因此, 算法1的时间复杂度为O(kn′n).
3 相关实体排序模型
3.1 EUWG模型
将需构造的无向带权图记为Geg,V是Geg中的节点, 由查询实体eq与候选实体组成, 使用V′表示V中除eq外的实体集合.由于查询实体与各候选实体相关,因此, 先在Geg中构造eq与V′各实体间的无向边, 然后, 通过计算各候选实体对应向量间的余弦相似度来构建候选实体间的无向边.将V′中任意两实体记为vi和vj, 若vi和vj对应向量间的余弦相似度为正, 则在Geg中构造一条vi到vj的无向边, 表示vi与vj相关.下面给出EUWG模型的定义:
定义2.EUWG模型是一个无向带权图, 表示为Geg=(V,L,M), 其中,V=M(eq)∪{eq}为节点集合,L={l1,l2,…,lt}为边的集合,W={w(vi,vj)|1≤i,j≤s,vi,vj∈V,i≠j}为EUWG边上的权重集合,w(vi,vj)表示vi和vj间无向边上的权重.
为了计算Geg中边上的权重, 并描述节点间的相关程度, 我们考虑以下两个方面:
(1) 向量相关度.各实体在向量空间中的语义相关度决定其向量间的相关度, 使用实体向量间的余弦相似度来度量.余弦相似度越高, 结构相关度越大.计算方法如下:
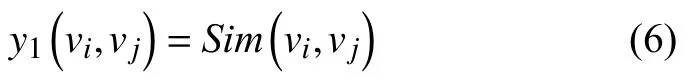
其中,Sim(·)表示实体向量间的余弦相似度.
(2) Web文档相关度, 即Geg中任意两个节点在Web文档中共现频率反映的相关度[3].我们统计Geg中任意两个节点在Web文档中共同出现的次数, 次数越多, 相关度越大.将Web文档集合记为H=(h1,h2,…,hc),计算方法如下:
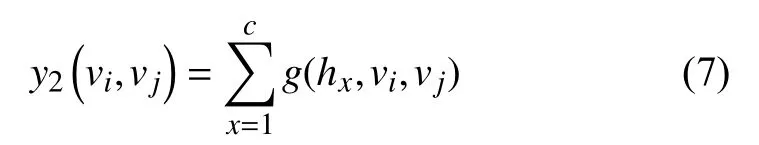
其中, 若实体vi与vj共同出现在hx(1≤x≤c)中, 则g(hx,vi,vj)为1, 否则为0.
使用超参数β来平衡上述因素对Geg边上权重的贡献.为了统一y1(vi,vj)和y2(vi,vj)的取值区间, 使用最大最小归一化函数对其进行处理:
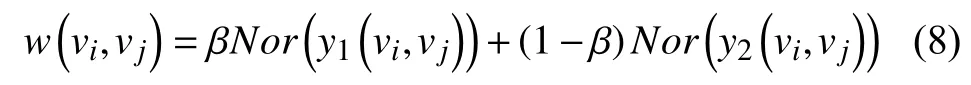
3.2 候选实体打分排序
Geg中任意两个节点间有多条路径, 不同的路径决定了节点间不同的相关程度.因此, 通过获取查询实体eq与候选实体vi∈V′在Geg中的所有路径来计算每条路径上权重的平均值, 将其中的最大值作为候选实体vi的分数, 并基于该分数对候选实体进行排序, 计算方法如下:
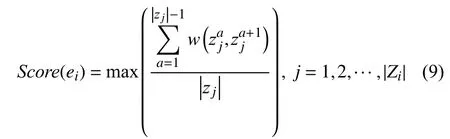
其中,Zi表示查询实体eq到候选实体vi所有的路径集合,zj表示第j条路径需要经历的所有实体集合,表示第j条路径中的第a个实体.

算法2.基于EUWG模型的候选实体排序输入: eq: 给定的查询实体; V: 候选实体集M(eq)与查询实体eq的并集; L: Geg中边的集合输出: B: 实体排序结果1.i←1, j←1, tmp_B←Ø, B←Ø 2.for each v in V-{eq} do 3.Z←BFS(L, e, eq) //使用广度优先算法获取Geg中实体eq到v的所有路径4.score←0 5.for each z in Z do 6.weight←0 7.for a=0 to |z|-1 do 8.weight←weight+w(za, za+1)9.end for 10.if weight/|z|>score then //将各路径权重平均值的最大值作为候选实体分数11.score←weight/|z|12.end for 13.tmp_B←tmp_B∪{(v, score)} //tmp_B保存候选实体v及其分数score组成的二元组(v, score)14.end for 15.根据tmp_B中候选实体的分数, 对实体进行排序, 将排序结果保存在B中16.return B
在算法2中, 假设Geg的节点数为s, 算法主要的时间代价是对s-1个候选实体进行广度优先搜索,Geg采用邻接矩阵存储, 每一次搜索的时间复杂度为O(s2).因此, 算法2的时间复杂度为O(s3).
4 实验结果
4.1 实验设置
(1) 数据集与测试环境
为了测试本文提出方法的效果, 使用Wikidata(http://dumps.wikimedia.org/wikidatawiki/entities)作为测试数据集, 并从Wikidata中分别随机抽取部分三元组, 记为KB50K和KB500K, 统计信息如表1所示.使用KORE[16]与ERT[17]数据集作为验证数据集, 这两个数据集均使用人工处理的方法给出了涉及IT、明星、游戏、电视剧、音乐与电影领域的多组查询实体与候选实体间的相关度, 统计信息如表2所示.同时, 为了构造EUWG模型, 分别使用KORE与ERT数据集中各领域的查询实体作为关键词搜索Web文档, 统计信息如表3所示.

表1 测试数据集

表2 验证数据集

表3 Web文档数据集
实验使用E5-2650v3 2.3 GHz处理器, 2080Ti GPU,128 GB内存, 用Python作为编程语言, 并使用Spark和TensorFlow框架作为编程框架.
(2) 测试指标
使用准确率(Precision,P)、召回率(Recall,R)以及F1分值来评价算法1的有效性, 计算方法如下:
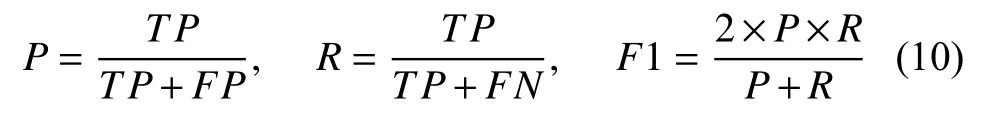
其中,TP为被正确搜索到的候选实体数,FP为被错误搜索到的候选实体数,FN为未被搜索到的候选实体数.
为了验证EUWG模型的有效性, 使用皮尔逊相关系数(Pearson Correlation Coefficient,PCC)、斯皮尔曼等级相关系数(Spearman Correlation Rank Coefficient,SCRC)以及调和均值(Harmonic Mean,HM)来评价排序结果.其中PCC表示测试结果与验证数据集中相关度分数的一致性,SCRC表示测试结果与验证数据集实体排序的一致性,HM表示测试结果与验证数据集之间的综合一致性.计算方法如下:
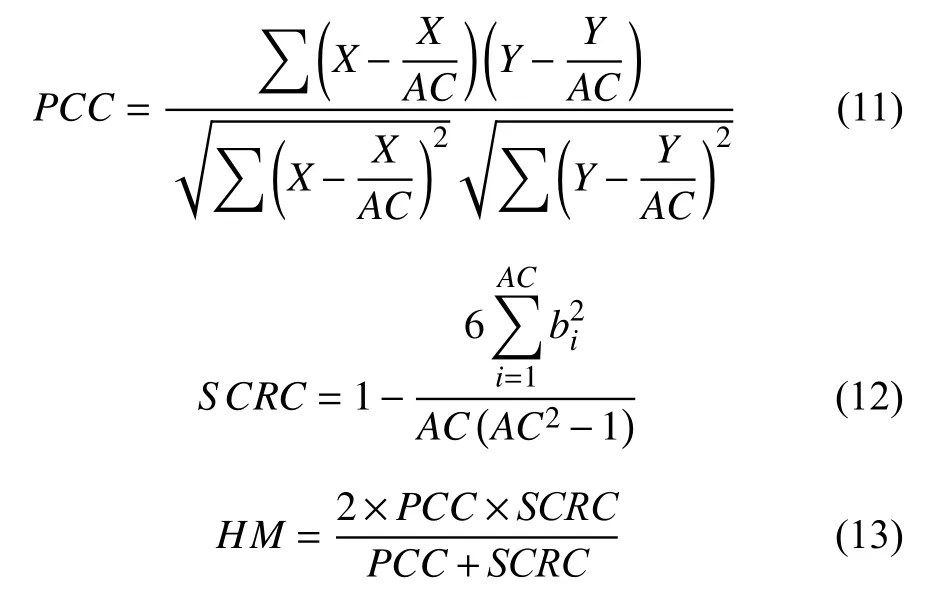
其中,X为测试结果中的候选实体分数集,Y为验证数据集中各候选实体的分数集,AC为候选实体数,bi为第i个实体在测试结果中的位置与验证数据集中位置的差值,PCC、SCRC和HM的值越接近1, 说明结果越好.
4.2 候选实体搜索有效性测试
为了测试实体数量对算法1的影响, 分别在KORE与ERT上测试了候选实体搜索的准确率、召回率和F1值, 如图2所示.可以看出, 随着实体数量的增加,各项指标都有所下降.当实体数量从1×105增加到5×105时, 实体数量增加了5倍, 但召回率仅降低了10%.原因在于, 实体数量的增加使得TransH的学习结果更加准确, 并能够更有效地表示实体的语义, 进而使算法1在大规模的KG上也表现优异.
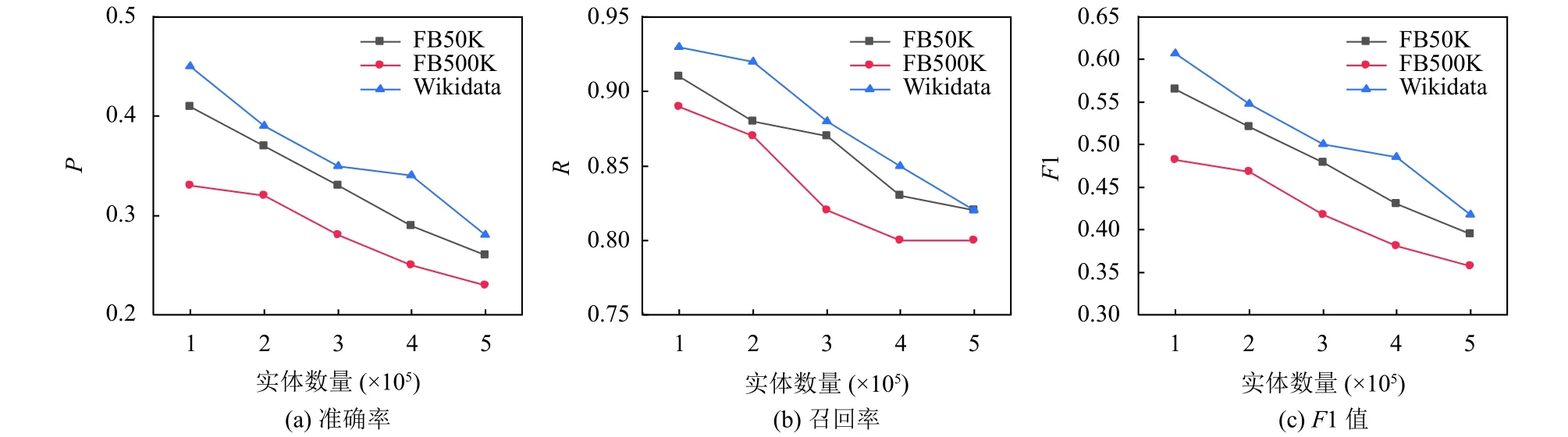
图2 实体数对候选实体搜索的影响
然后, 测试了不同聚类类别数对算法1的影响.在各KG中选择5×105个实体, 取不同的聚类类别数进行测试, 如图3所示.可以看出, 随着聚类数的增加, 准确率和F1值都有所上升, 原因在于类别数越多, 候选实体集中被错误召回的实体数量所占的比例越小, 进而候选实体搜索的准确性就越高.
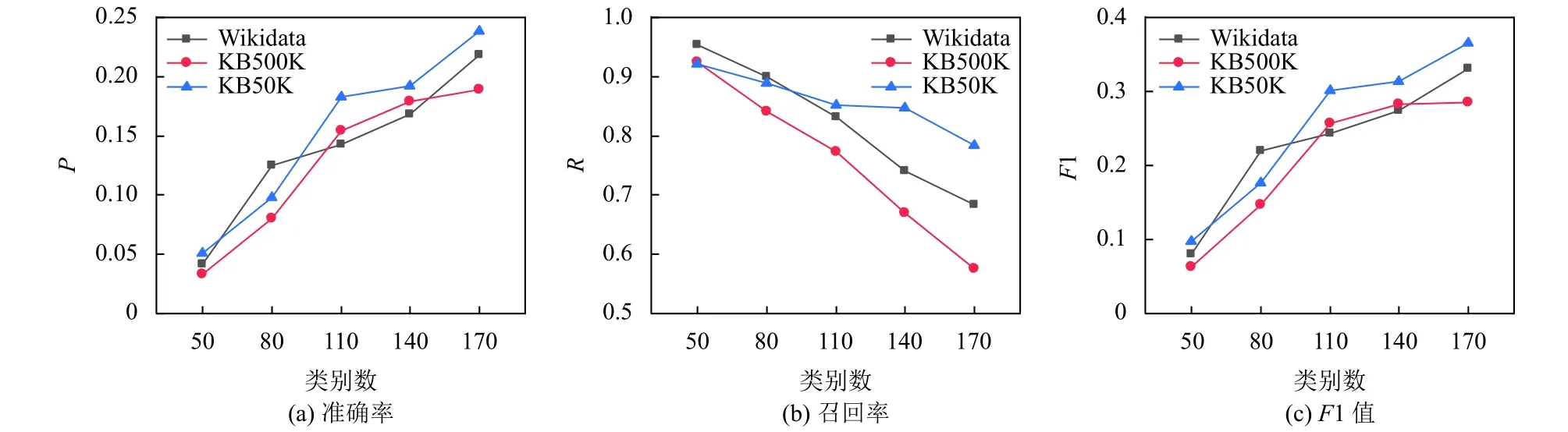
图3 聚类类别数对候选实体搜索的影响
另外, 将本文提出的候选实体搜索算法记为TCES(TransH-based Candidate Entity Search), 从各KG中选择5×105个实体, 设置聚类类别数为170, 与REFH[4]和LTRC[5]算法进行对比, 如表4所示.可以看出, 算法1在FB50K和FB500K数据集上效果更好, 且在Wikidata上准确率和F1值也高于其他两种方法.原因在于, 算法1从KG所有实体中寻找候选实体, 搜索范围更大,进而被正确召回的实体数目更多.
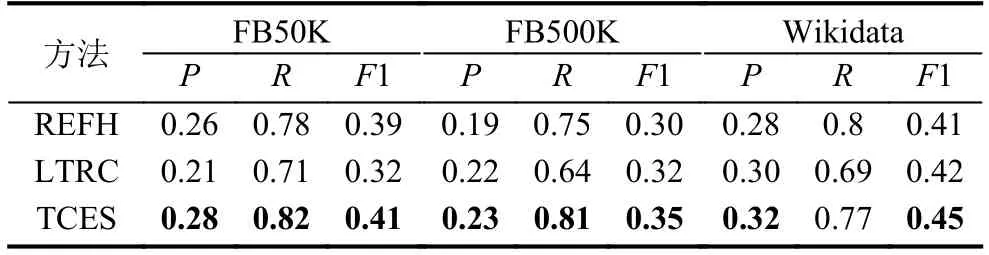
表4 不同KG的候选实体搜索结果
4.3 EUWG模型有效性测试
为了测试KG规模对候选实体排序的影响, 选择4.5×105个Web文档, 测试算法2在不同三元组数量下的PCC、SCRC和HM, 如图4所示.可以看出, 随着三元组数量增加,PCC、SCRC和HM都有所上升.当三元组数量达到5×106时, 各指标平均增加了29%、17%和25%.原因在于随着三元组数量的增加, KG中蕴含的知识更加完整, TransH能够更有效地对KG进行表示, 使得EUWG模型中向量相关度的计算更加准确,进而排序效果有所提升.
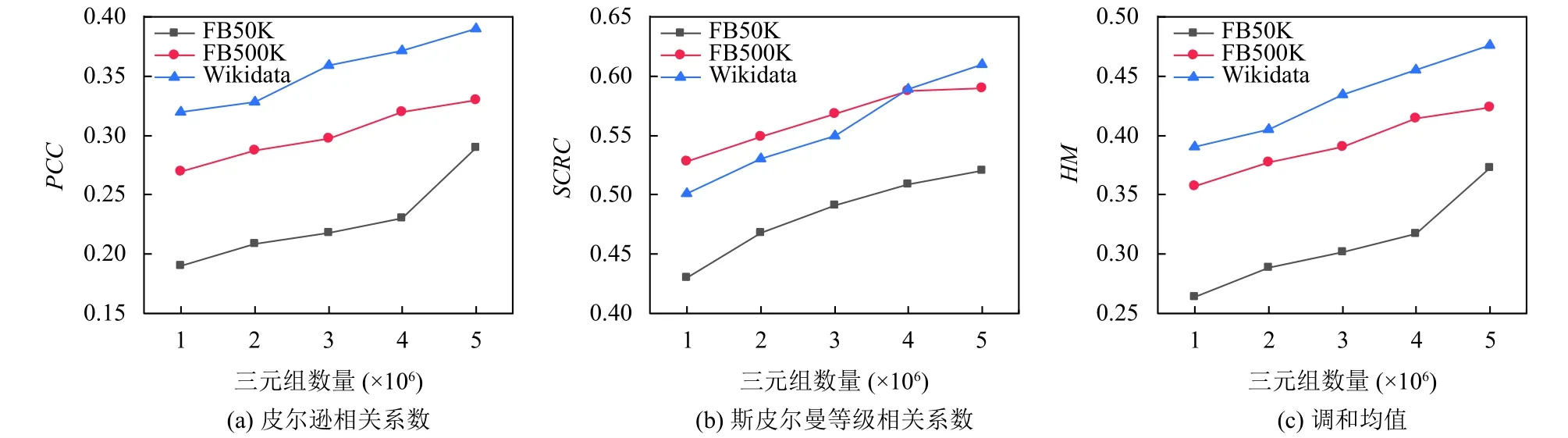
图4 KG规模对候选实体排序的影响
另外, 为了测试不同Web文档数对相关实体排序的影响, 从各KG中分别选择5×106个三元组, 测试算法2在不同Web文档数下的PCC, SCRC和HM, 如图5所示.可以看出, 随着Web文档数增加, 各指标也随之上升, 当数据量为4.5×105时, 各指标平均提升了41%、30%和34%.原因在于随着Web文档数的增加, 其中的知识也随之增加, 对实体相关性的描述信息也更加丰富, 使得EUWG模型对实体在Web文档中相关性的量化更加准确, 进而提升了排序效果.
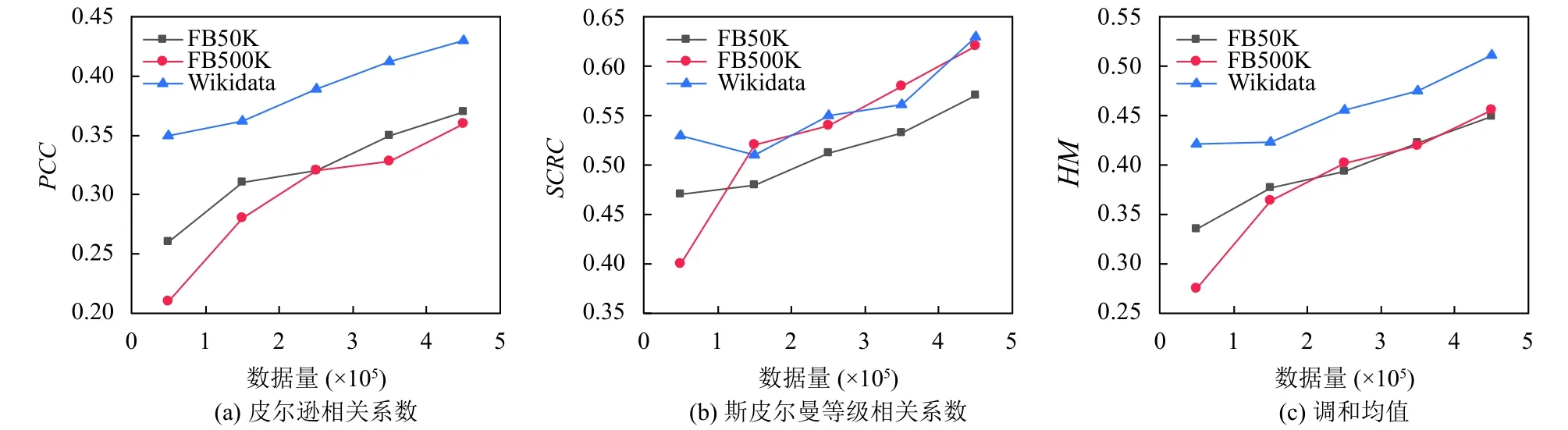
图5 Web文档数对候选实体排序的影响
最后, 我们从KG中分别选择5×106个三元组, 并使用4.5×105个Web文档和不同领域的查询实体进行测试, 与 WLM[8]、TSF[9]和 Wikipedia2Vec[12]模型进行比较, 如图6和图7所示.可以看出, 本文提出的EUWG模型在实体排序任务中表现较好, 其中, EUWG模型比其他3种方法的PCC高了18%.原因在于Wikipedia2Vec模型在将KG映射为向量时会发生实体和词汇的匹配错误.同时, WLM与TSF模型主要根据KG来计算实体间的相关度, 但KG无法及时地反映真实世界不断演化的知识, 因此计算结果不够准确, 而EUWG使用Web文档和KG共同描述实体间的相关关系, 使得计算结果更加客观, 进而候选实体的排序结果更好.
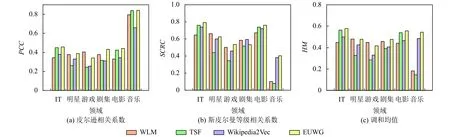
图6 基于FB50K的候选实体排序结果
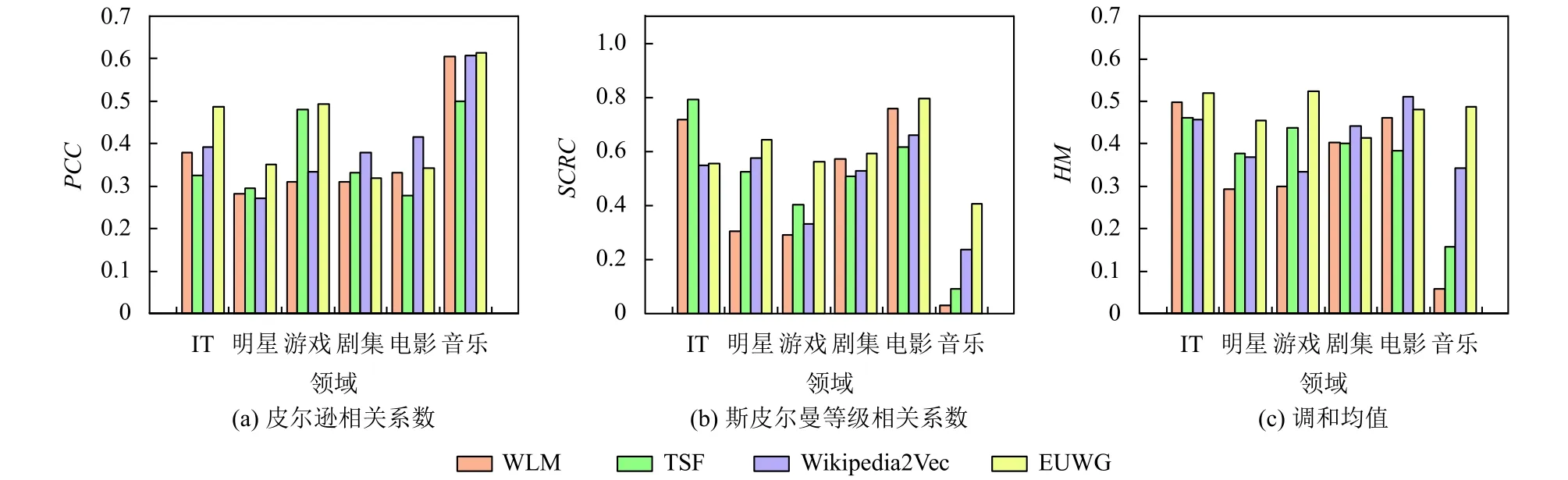
图7 基于FB500K的候选实体排序结果
5 结束语
本文提出了基于表示学习的相关实体搜索算法, 通过对向量空间中不同关系超平面上的实体投影进行聚类, 获得与查询实体相关的候选实体, 并使用实体带权无向图模型对候选实体进行排序.实验结果表明, 本文提出的方法能够正确地从KG中搜索候选实体, 同时有效地对候选实体进行排序.但在候选实体排序任务中使用的数据源仍有待进一步扩展.因此, 在未来工作中考虑加入Web应用中与实体相关的图片数据, 更加客观全面地描述实体间的关系信息, 提高相关实体搜索的准确性.
