Click-Through Rate Prediction Network Based on User Behavior Sequences and Feature Interactions
2022-09-29XIAXiaoling夏小玲MIAOYiwei缪艺玮ZHAICuiyan翟翠艳
XIA Xiaoling(夏小玲), MIAO Yiwei(缪艺玮), ZHAI Cuiyan(翟翠艳)
School of Computer Science and Technology, Donghua University, Shanghai 201620, China
Abstract: In recent years, deep learning has been widely applied in the fields of recommendation systems and click-through rate(CTR) prediction, and thus recommendation models incorporating deep learning have emerged. In addition, the design and implementation of recommendation models using information related to user behavior sequences is an important direction of current research in recommendation systems, and models calculate the likelihood of users clicking on target items based on their behavior sequence information. In order to explore the relationship between features, this paper improves and optimizes on the basis of deep interest network(DIN) proposed by Ali’s team. Based on the user behavioral sequences information, the attentional factorization machine(AFM) is integrated to obtain richer and more accurate behavioral sequence information. In addition, this paper designs a new way of calculating attention weights, which uses the relationship between the cosine similarity of any two vectors and the absolute value of their modal length difference to measure their relevance degree. Thus, a novel deep learning CTR prediction mode is proposed, that is, the CTR prediction network based on user behavior sequence and feature interactions deep interest and machines network (DIMN). We conduct extensive comparison experiments on three public datasets and one private music dataset, which are more recognized in the industry, and the results show that the DIMN obtains a better performance compared with the classical CTR prediction model.
Key words: click-through rate(CTR) prediction; behavior sequence; feature interaction; attention
Introduction
In recent years, researchers have started to apply deep learning to the field of recommendation systems and click-through rate(CTR) prediction, and have proposed many excellent deep learning recommendation models. For example, the deep interest network(DIN)[1]presented by Ali’s technical team at KDD2018, and the attentional factorization machine (AFM)[2],etc., and have been successful in practice.
DIN[1]is modeled based on the user behavior sequences and fully exploits the information contained in the user’s historical behavior data. Compared with traditional models, DIN takes into account two key points. (1) Users’ interests are diverse and DIN predict whether a user will click on a candidate item based on the user’s historical behavior sequences interacting with that item. (2) This paper uses local activation units to adaptively learn different interest vector representations based on the user’s historical behavior.
Unlike the neural factorization machines (NFM)[3]approach in the bi-interaction layer, the contribution of the AFM[2]model is the introduction of the attention mechanism into the feature interaction module, adaptively learning the importance of each second-order combination of features. Although both the NFM model and the AFM model introduce attention mechanisms, the main ideas and principles of their attention implementations are different.
The main contribution of the DIN model is to design a novel activation unit to dynamically extract users’ diverse and changing interest features; while the focus of the AFM model is to use the attention mechanism to learn the importance of different combinations of features, so that important combinations of features can be effectively extracted and the learning ability of the model can be enhanced. In this paper, on the basis of DIN and AFM, we propose a novel deep recommendation model, a CTR prediction network based on the interaction of user behavior sequences and features. The main work of this paper is as follows.
(1) In order to more fully explore the relationship between low-order features, this paper models the information related to user behavior sequences and introduces an attention-based factor decomposer model to achieve effective combination between features. Reinforcement learning of user’s historical behavior sequences is performed in a parallel manner, so that the model can better learn user’s interest features and obtain richer and more accurate behavior-dependent information
(2) We propose a new way of calculating attention, using the relationship between the cosine similarity among two vectors and the absolute value of the modal length difference to measure their attention, with good results.
(3) We have conducted extensive experiments on several public datasets and one private dataset, and the results prove that the proposed deep learning model is effective and has good interpretability.
1 Related Work
Whether in academia or industry, deep learning-based recommendation algorithms have become a mainstream research direction in the industry today. Compared with traditional machine learning, deep learning has powerful advantages. For example, deep learning can automatically achieve the combination of features, eliminating the cost of a large number of manual feature processing, and can dig deeper into the potential information in the data, with stronger learning ability.
Logistic regression[4]is widely used in industry because of its fast training speed and its strong interpretability. However, logistic regression models are relatively simple and cannot automatically implement combinations between features, so it is difficult to explore deeper relationships between features.
To address the problem of sparse large-scale data in practical scenarios, Rendle[5]proposed the factorization machine (FM) algorithm. The FM algorithm implements the second-order combination between features and trains the parameter matrix of the second-order combined features with the idea of matrix decomposition to improve the model’s learning capability. Subsequently, Juanetal.[6]proposed the field-aware factorization machine (FFM) model based on the concept of “domain”, which can learn different embedding vectors for the features of different domains to highlight the difference of feature interactions between different domains.
In 2016, click rate prediction models such as deep crossing[7], Wide&Deep[8], factorization machine supported neural network (FNN)[9]and vector product-based neural networks (PNN)[10]were proposed one after another, marking that the field of computational advertising and recommender systems has fully entered the era of deep learning. The Wide&Deep model consists of two main modules, the Wide part and the Deep part. Among them, the essence of the Wide part is a simple explicit model, while the essence of the Deep part is a feed-forward neural network. In Deep&Cross network (DCN)[11], the main improvement point is to use cross layer network to replace the Wide part and perform the interaction between features. While in Deep factorization machine (DeepFM)[12]model, the Wide part is replaced by LR model with FM module to achieve the second order combination between features. In the NFM model, the improvement of the Deep part is mainly to replace it with a Bi-interaction module containing a multilayer perceptron. While in AFM model, attentional mechanism is introduced to extract effective second-order combinatorial features. In 2018, Lianetal.[13]proposed the very deep factorization machine model (xDeepFM), which is capable of automatically learning higher-order feature interactions in both explicit and implicit ways, allowing feature interactions to occur at the vector level, while also having the learning capabilities of both memory and generalization.
With the depth of research, more and more researchers have started to focus their research on the user behavior sequence, so modeling based on the user behavior sequence has become a major research direction in the field of recommendation systems in recent years. For example, Ali’s technical team proposed DIN in 2018, whose main idea is to use an attention module to dynamically extract the information of items in the user behavior sequence with a higher degree of relevance in that target item when recommending a target advertisement for a user, thus generating the subsequent recommendation results. Because the attention weight between the items in the user behavior sequence and the target item changes with the target item, the DIN model can effectively extract the dynamic interest characteristics of the user. Since then, Ali’s technical team has improved and optimized on the basis of DIN, and has proposed many excellent models. For example, in the deep interest evolution network (DIEN)[14]proposed by the Ali technology team, the gated recurrent unit (GRU)[15]model is incorporated and the AUGRU model is proposed to improve the GRU, thus enhancing the effectiveness of the model. In addition, Ali’s team also proposed deep interest session network (DSIN)[16], behavioral sequence transformation network (BST)[17], and deep multiple interest network (DMIN)[18], among others.
2 Model
In order to fully exploit the low-order features and high-order features, this paper proposes a CTR prediction model deep interest and machines network (DIMN) based on the interaction between user behavior sequences and features, which mainly includes two parallel modules. The first module is the attention-based feature interaction layer, whose main role is to perform reinforcement learning for user’s historical behavior sequences and can effectively extract the information of second-order feature interactions. The second module is the user’s interest feature extraction layer. In this module, this paper proposes a new attention calculation method, which uses the relationship between the cosine similarity and the absolute value of the modal length difference between any two vectors to measure their relevance degree. Experiments demonstrate that the attention computation proposed in this paper has better performance than the attention computation in the original DIN, showing that the attention computation proposed in this paper can better explore the relationship between item vectors. Figure 1 shows the general architecture of the model in this paper.
2.1 Input layer
In the input layer, each behavioral feature consists of an item featuregand a kind featurec.
b°=(g,c).
(1)
The input user behavior sequence is
(2)
2.2 Embedding layer
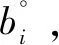
(3)
(4)
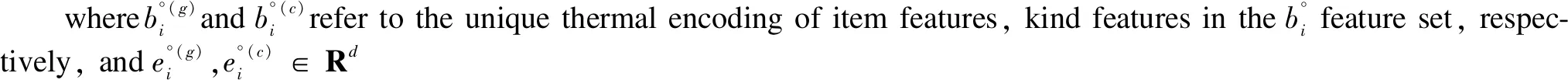

(5)
2.3 Feature interactions layer
The AFM model can be regarded as an upgraded model of the FM model. Unlike NFM in bi-interaction layer, it uses the attention network to learn the importance level of different combinatorial features when summing pooling second-order combinatorial features, and the calculated attention score corresponds to the combinatorial features for weighted summation operation, in order to extract the effective combination features. The output of the AFM model can be calculated using
(6)
(7)

The focus of the feature interaction layer lies in Eq. (7), the feature crossover part. The features are mainly crossed to the second order, thennfeatures are crossed between two features, andn(n-1)/2 second-order crossed feature vectors can be obtained. The formula is shown as
fPI(ε)={(vi⊙vj)xixj}(i,j)∈Rx,
(8)
whereεdenotes the output of the embedding layer,viandvjdenote the hidden vectors,xiandxjdenote the corresponding eigenvalues, and the operator ⊙ denotes the corresponding elements of the vectors.
2.4 Weight calculation layer
The cosine of the angle between two vectors can determine whether the two vectors point approximately in the same direction, and the smaller the angle, the higher the similarity. Thus the cosine similarity can be used as a measure of the magnitude of the difference between any two vectors. The calculation formula is shown as
(9)
At the same time, the absolute value of the modal length difference can further determine the similarity between two vectors. Therefore, this paper improves the attention calculation for the original DIN by using the relationship between the cosine similarity of two vectors and the absolute value of the modal length difference to measure their attention, which better measures the similarity between items. The calculation formula is shown as

(10)
Therefore, after the calculation of the weight calculation layer, the attention weight between two item vectors with greater similarity is greater, and the attention weight between item vectors with lower similarity is smaller. When the angle is greater than π/2, it means that the directions of the two vectors do not agree, the value of cosθis less than zero, and the similarity becomes smaller as shown in Fig. 2.
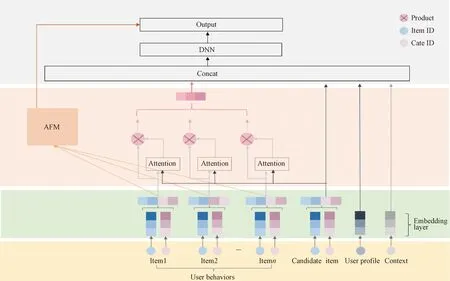
Fig. 1 Model structure diagram
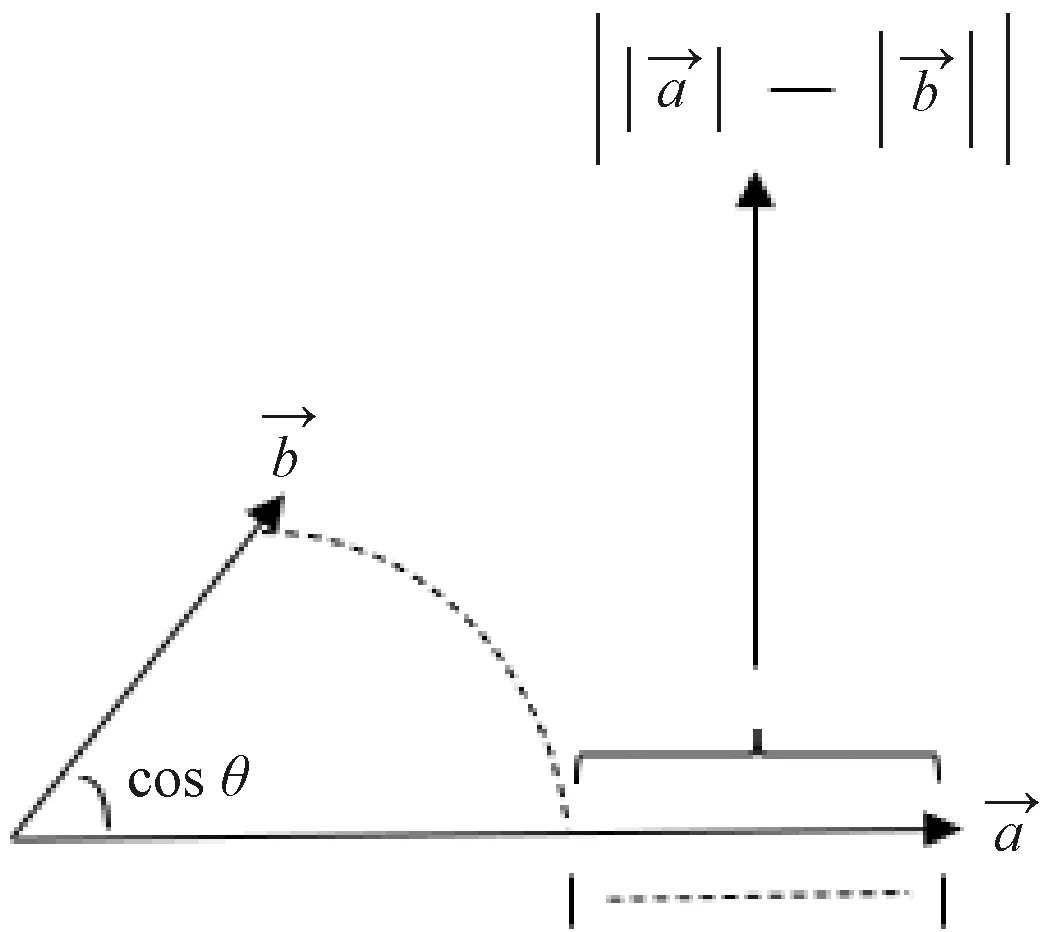
Fig. 2 Similarity graph
2.5 Loss
In this paper, the typical cross entropy is chosen as the loss function of the dichotomous task model, and its calculation formula is shown as
(11)
wherexis the input to the network,yis the label of the training set of (0,1),Sis the training set of sizeN, andp(x) is the output after the softmax layer.
3 Model Training
In this paper, three industry-recognized public datasets and a private NetEase Cloud Music dataset are selected and a large number of experiments are conducted. The deep learning area under roc (AUC) metrics are used as the criteria for model performance evaluation to demonstrate the effectiveness of the model, and the results show that the model proposed in this paper outperforms some classical models.
3.1 Datasets
3.1.1Amazonelectronicsdataset
A well-known public dataset in the field of recommendation systems——the dataset contains product reviews and metadata from Amazon, containing 192 403 users, 63 001 products, 801 categories, and 1 689 188 samples. The dataset is very rich in user behavior, with more than 5 reviews for each user and product.
3.1.2Amazondigitalmusicdataset
A public dataset is commonly used in the field of music recommendation, and this digital music dataset contains reviews and metadata from Amazon, and the version we use contains 5 541 users, 3 568 digital music tracks, 64 categories and 64 706 samples.
3.1.3Last.FMdataset
This dataset is a public dataset released at the 2nd International Workshop on Information Heterogeneity and Fusion in Recommender Systems (HetRec 2011). It contains information on social networks, hashtags, and music artists’ listening information. It contains 1 892 users, 12 523 artists, 21 categories, and 71 064 samples.
3.1.4Privatemusicdataset
The private music dataset containing user behavior contains 1 666 741 users, 65 314 music tracks, 21 categories, and 3 160 243 samples. Table 1 shows the statistics of all the above datasets.

Table 1 Dataset statistics
3.2 Experimental setup
For all models, the learning rate is set between 0.1 and 1.0, the size of the training batch is set to 32, and the maximum user view length is controlled to 100.
3.3 Contrast models
The models used in this paper for contrast experiments are: basemodel, Wide&Deep, PNN, and DIN. In this case, basemodel is a direct behavioral feature vector and input to the deep neural network.
3.4 Evaluation metric
In the field of CTR prediction, AUC is one of the widely used metrics. It indicates the probability that the predicted positive samples are ranked before the negative samples and can be a good measure of the model’s ranking ability. The value of AUC, which is the area under the ROC curve, takes a value between 0.1 and 1.0, and the closer to 1 indicate the higher the authenticity of the detection method. A variant of user-weighted AUC was introduced in Refs. [19-20], which measures the merit of intra-user orders by the average user’s AUC and was shown to be more relevant to online performance in display advertising systems. We used this metric in our experiments. For simplicity, we will still refer to it as AUC. The calculation is shown as
(12)
wherenis the number of users, and #ImpressioniandAucicorrespond to the preference andAucof theith user.
3.5 Analysis of experimental results
Through the experimental results in Table 2, it can be proved that the model proposed in this paper has achieved better performance than other classical models. Among them, DIMN is the model proposed in this paper.

Table 2 Experimental results
In addition, in order to verify the role and effectiveness of each module in the model proposed in this paper, we have conducted a large number of ablation experiments. The experimental results in Table 3 are the average values taken for the AUC after conducting training for 10 epochs, where DIN_AFM denotes the method of embedding AFM in a parallel manner, DIN_att denotes the method of measuring attention using the relationship between the cosine similarity between two vectors and the absolute value of the difference in modal length, and DIMN is the final CTR prediction model.

Table 3 Ablation experiment
From the results in the tables, we can analyze the following conclusions. (1) The use of AFM for reinforcement learning of user history behavior sequences in a parallel manner enables the model to better learn information about low-order feature interactions, thus making the model more effective than DIN itself, which can prove to be effective. (2) The results obtained by using the relationship between the cosine similarity between two vectors and the absolute value of the modal length difference to measure their attention are somewhat improved over those obtained by using the way attention is calculated in the DIN model, which has a positive impact on the prediction results and can prove that our proposed new way of calculating attention is more effective. (3) DIMN is the final CTR prediction model proposed in this paper, which is based on the DIN based on the fusion of the two improvements. Experiments prove that the fused model has some improvement over the initial DIN model, as well as DIN_AFM and DIN_att, and performs better on all four datasets. This indicates that the proposed new approach is effective and that the fusion of the two new approaches produces better results. DIMN improves the average AUC metric by about 1%-2% over DIN on the four data sets. It can be seen that the improvement is greater in electronics, digital music and music data sets than that in Last.FM. Here we believe after analysis it is due to the user sequence length. The first three datasets are richer in historical user behavior, which allow us to make more significant improvements.
4 Conclusions
Based on the DIN proposed by Ali’s team, this paper integrates the more advanced model AFM in the feature intersection direction in the CTR prediction model to mine the second-order dependencies, which we believe has the advantage of mining the comprehensive behavioral dependency information more accurately, effectively highlighting the information and suppressing the invalid information. In addition, we simultaneously use the relationship between the cosine similarity between two vectors and the absolute value of the modal length difference to measure their attention, changing the original calculation. Ultimately, it is demonstrated through a large number of experiments and ablation experiments that our model has a certain improvement over some classical models and the chosen basemodel DIN on all four data sets, and the improvement is more stable and has a better performance.
杂志排行

Journal of Donghua University(English Edition)的其它文章
- Classification of Preparation Methods and Wearability of Smart Textiles
- Computer-Based Estimation of Spine Loading during Self-Contained Breathing Apparatus Carriage
- Predictive Model of Live Shopping Interest Degree Based on Eye Movement Characteristics and Deep Factorization Machine
- Object Grasping Detection Based on Residual Convolutional Neural Network
- Time Delay Identification in Dynamical Systems Based on Interpretable Machine Learning
- Online Clothing Recommendation and Style Compatibility Learning Based on Joint Semantic Feature Fusion