Time Delay Identification in Dynamical Systems Based on Interpretable Machine Learning
2022-09-29XIAMengWUYuzhe吴毓哲WANGZhijie王直杰
XIA Meng(夏 梦), WU Yuzhe(吴毓哲), WANG Zhijie(王直杰)
College of Information Science and Technology, Donghua University, Shanghai 201620, China
Abstract: The existence of time delay in complex industrial processes or dynamical systems is a common phenomenon and is a difficult problem to deal with in industrial control systems, as well as in the textile field. Accurate identification of the time delay can greatly improve the efficiency of the design of industrial process control systems. The time delay identification methods based on mathematical modeling require prior knowledge of the structural information of the model, especially for nonlinear systems. The neural network-based identification method can predict the time delay of the system, but cannot accurately obtain the specific parameters of the time delay. Benefit from the interpretability of machine learning, a novel method for delay identification based on an interpretable regression decision tree is proposed. Utilizing the self-explanatory analysis of the decision tree model, the parameters with the highest feature importance are obtained to identify the time delay of the system. Excellent results are gained by the simulation data of linear and nonlinear control systems, and the time delay of the systems can be accurately identified.
Key words: time delay; dynamical system; interpretability; regression tree; feature importance
Introduction
When modeling the process of many systems in the industry, time delay is frequently encountered. Time delay in industrial processes comes from many sources. There are two main factors that contribute to the occurrence of time delay in the production process. One is the characteristics of medium transfer and energy exchange in the system. The other is related with automatic control systems, such as measurement sensing equipment, information transmission equipment, control equipment, and actuators. When time delay exists, it becomes more difficult to govern the corresponding system, and the stability of the system suffers significantly, resulting in a decline in the quality of productions. Therefore, there are many models aiming to figure out the exact time delay of the control systems[1-2]. The accurate identification of the time delay is also strongly tied to other performances besides stability of many controllers, such as the Smith controller[3]. It is imperative to develop an accurate model for the delay system to precisely identify the value of the delay. There are now two kinds of the time delay modeling researches: mathematical identification[4-5]and machine learning model[6-7].
Initially, the traditional time delay identification methods were studied based on mathematical statistics. Yang and Gao[8]used the expectation-maximization (EM) algorithm to identify the time delay of a linear system. SASSIetal.[9]considered a method which consisted in minimizing a quadratic criterion using either the gradient method or the Levenberg-Marquardt method in dynamical time delay systems. Meanwhile, to improve the performance of the algorithm, they proposed quasi-Newton approach based on the Broyden-Fletcher-Goldfarb-Shanno (BFGS) algorithm. Lietal.[10]put forward a time delay identification algorithm for perturbed closed-loop dynamic processes based on maximum correlation analysis and verified the effectiveness of the algorithm in the actual industrial production process. However, the above methods need to know the prior knowledge of the system, and need to involve different mathematical and statistical algorithms to identify the time delay for different systems. With the rapid development of computer technology, machine learning algorithms have begun to shine in time delay identification. Karouietal.[11]conducted a new algebraic technique and constructed an online delay identification approach based on a distributional algebraic technique and a convolution way that could identify different time delays of different systems. However, most machine learning models are black-box models, which cannot accurately obtain some key information of the system (such as delay). Li and Yan[12]built a multidimensional Taylor network to simulate nonlinear time delay systems, and introduced a particle swarm optimization algorithm to adjust the weights of the Taylor network. Later, the authors replaced the particle swarm optimization algorithm with a modified conjugate gradient method to train multidimensional Taylor networks. Dingetal.[13]constructed a grey-box model combining discrete bayesian optimization (DBO) and controlled recurrent neural network (CRNN), namely the CRNN-DBO model, to model and identify time delay systems. This method provided a combination of back-propagation algorithm and DBO method to find the minimum loss value of the model, as well as the correct time delay. Some researchers have attempted to use neural networks for system modeling and time delay identification, but their applications are limited to single-input or linear systems.
The time delay identification algorithm mentioned above can identify the time delay of the dynamic system well in practice. The models based on the mathematical statistics method can be understood, but these methods require prior knowledge of the structural information and nonlinear parts of the system, which is often inaccessible. Machine learning-based modeling techniques are not concerned with the structure of the model, but rather with the mapping relationship between input and output, unable to obtain the precise value of the time delay, which is detrimental when constructing the control strategy. The time delay identification method based on the neural network belongs to the black-box model after all, which lacks interpretability. At the same time, as machine learning technology improves, more and more researches care about how rationally the model predicts things. Tree-based interpretability models[14-15]are developing rapidly. The application of the tree model in financial[16], medical[17]and other issues fully demonstrates the outstanding interpretability of the tree model.
To address the problems of the time delay identification, a method inspired by the development of the interpretable machine learning is established. And this paper establishes an interpretable machine learning model based on regression tree to identify the time delay. Experiments are conducted for linear and nonlinear control systems, and the experimental results verify the accuracy of the interpretable model in time delay identification, showing that the interpretable algorithm can be developed as a new method to identify the time delay of the system. Meanwhile, the experimental results also show that the interpretable model can be applied to both linear and nonlinear systems, and can deal with short and long delay.
1 Methodology
1.1 Discrete system
Three different discrete systems are considered in this paper. They are linear first-order (LFO) time delay systems, linear second-order (LSO) time delay systems, and nonlinear time delay systems.
1.1.1LFOtimedelaysystem
Consider the following system:
y(k)=Ay(k-1)+x(k-i),
(1)
wherei∈{1, 2,…,N} represents the time delay,xis the input of the time delay system,yis the system output, andAis the parameter of the system.
Meanwhile, the system with noise is
y(k)=Ay(k-1)+x(k-i)+ε(k),
(2)
whereε(k) is the white noise with zero mean and varianceδ.
1.1.2LSOtimedelaysystem
The system is
y(k)=Ay(k-1)+By(k-2)+x(k-i),
(3)
whereAandBare the parameters of the system. The system with noise is
y(k)=Ay(k-1)+By(k-2)+x(k-i)+ε(k).
(4)
1.1.3Nonlineartimedelaysystem
The expression of nonlinear time delay system is
y(k)=Ays(k-1)+x(k-i),
(5)
wheresstands for power. Add noise to the system
y(k)=Ays(k-1)+x(k-i)+ε(k).
(6)
1.2 Time delay identification with explainable algorithm based on regression decision tree
In this paper, the regression decision tree model is employed as the discrete time delay recognition model. Through the interpretability analysis of the tree model, it is convenient for readers to understand the interpretability principle of time delay identification.
1.2.1Structureofalgorithmfortimedelayidentification
The structure of the algorithm for time delay identification is shown in Fig. 1. The whole algorithm includes datasets construction, regression analysis and interpretability analysis. Matlab is used to simulate each system and generate the data needed for training. In the process of regression analysis, the simulation data are preprocessed, and the regression decision tree model is used for training. With coefficient of determination as the evaluation index of regression model performance, the optimal decision tree model is selected as the final regression model. Then, interpretability analysis is carried out to determine the time delay of the system. Specifically, based on the interpretability of the decision tree model, it is further to summarize and sort out the interpretability of the decision path of the decision tree, and finally identify the time delay of the system from the perspective of interpretability.
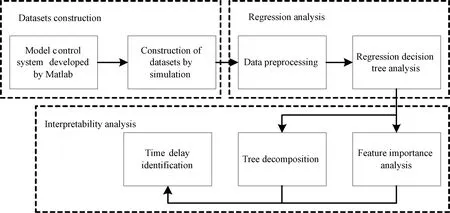
Fig. 1 Structure of algorithm for time delay identification
1.2.2Regressiondecisiontree
Regression decision tree is a basic regression method. The decision tree consists of nodes and directed edges. There are two types of nodes: internal nodes and leaf nodes. An internal node represents a feature or attribute, and a leaf represents a category or value.
Given a datasetD={(x1,y1),(x2,y2),…,(xn,yn)},xiis at-dimensional vector and hastfeatures. The goal of the regression problem is to create a functionf(x) to fit the elements in datasetD, and then get the smallest mean square error (MSE) shown as
(7)
Figure 2 presents the algorithm of the regression decision tree. In Fig. 1, it is assumed that a regression tree withMleaves needs to be constructed, which means that the feature spacexneeds to be divided intoMunitsR1,R2, …,Rm, and there is a predicted value for each feature space. Then the minimum MSE of the regression tree was calculated as

Fig. 2 Regression decision tree algorithm
(8)
wherecmis on behalf of the predicted values of themth leaf.
To get the minimum MSE, just need to minimize the MSE for each leaf, that is, set the predicted value to the mean of the leaves containing the training dataset labels.
1.2.3Interpretabilityofregressiondecisiontree
The interpretability of regression tree model is demonstrated through the analysis of feature importance[18]and tree decomposition[19].
Feature importance traverses all partition points using this feature and calculates how much (in proportion) it reduces the variance or Gini index of the result compared to the parent node. The importance of each feature can be understood as an explanatory part of the whole model. Tree decomposition is to restore the path of the instance and add up the contributions of the passing nodes.
2 Experimental Verification
2.1 Datasets
According to different discrete time delay systems, different datasets are constructed for training and testing the model. The training data can be listed as a matrix, shown as
(9)
whereqrepresents the start time of discrete system data,wrepresents the number of discrete system continuous data to be extracted, andurepresents size of data.
In this study, datasets used in the experiment are collected by different systems in Matlab simulation. According to the three systems mentioned in section 1.1, Matlab is used to simulate them respectively. For each system, two kinds of datasets are generated, one with white noise and the other without white noise.
In the LFO system without noise, the output of the previous moment of the current moment of the system output is taken as a feature, and the input including the current moment as well as the previous nine moments is taken as features. These features form a feature set. The label is the output of the current moment. The dataset with noise is constructed in the same way.
In the LSO system dataset, the output of the first two moments of the current moment are taken, and the input including the current moment and the first nine moments are obtained as features. The datasets of the nonlinear system are the same operation as the LFO system. The relevant information of the dataset is shown in Table 1.
In order to enrich the variety of experiments, different time delays are set. Time delays of different systems are shown in Table 2. Time delay identification of first-order, second-order and nonlinear systems is carried out.
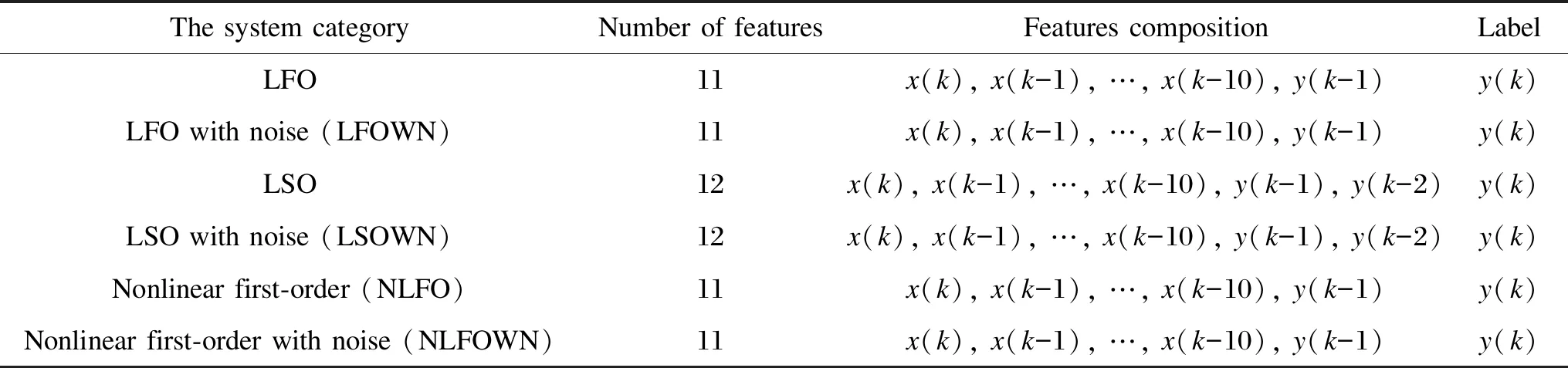
Table 1 Details of datasets

Table 2 Time delay of each dataset
In the industrial process, the discrete system is obtained by sampling the continuous system, and the time delay of the system is related to the delay of the continuous system and the sampling interval. Therefore, many datasets need to be obtained after a series of steps such as analysis and simulation from a specific system, and for different systems, many models are independent and do not have universal applicability. However, in this paper, different datasets can be established for different discrete time delay systems. The steps of establishing datasets are the same as those in this paper that just need to determine the size ofn, and the algorithm proposed in this paper is generally applicable. Therefore, the algorithm in this paper is scalable and greatly improves the efficiency of system time delay identification.
2.2 Evaluation metrics for time delay identification
The tree depth of regression decision tree has a certain influence on the interpretability, in the process of regression decision tree training, and it is necessary to determine the tree depth it can accurately fit the datasets.
This paper uses the coefficient of determination referred to asR2to evaluate regression tree models performance. Its calculation formula is:
(10)
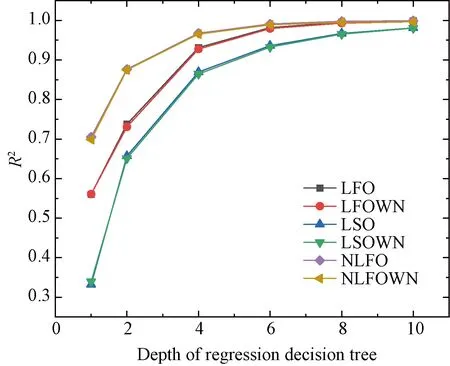
Fig. 3 R2 curves of different tree depths in different datasets
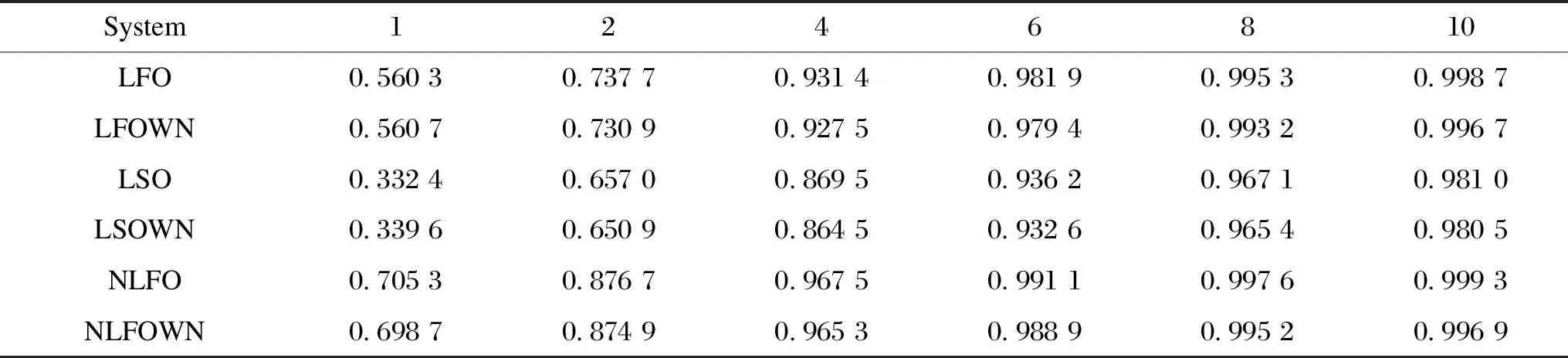
Table 3 R2 scores of regression decision tree with different depths for each dataset

Table 4 Optimal tree depth of each dataset
2.3 Interpretability analysis
2.3.1Featureimportanceanalysis(FIA)
FIA commonly is used to detect a contribution to the prediction results. The basic idea is that FIA disrupts the feature column data, the other features are unchanged, then observe the change of model prediction accuracy or loss. FIA iterates over all features.
The feature importance was analyzed for the dataset with fixed tree depth, and the result was shown in Fig.4. In Fig. 4,X1,X2, …,X10representx(k-10),x(k-9), …,x(k-1),x(k), respectively;X11andX12denotey(k-2) andy(k-1), respectively.
It can be seen from the FIA in Fig. 4 that the regression tree model can fit the control system well, and the FIA can find the time delay of the system. As shown in Fig. 4(a), what can be clearly seen in this figure is the high score ofX5. And the corresponding time delay of the LFO system is 5. Time delay of the LFO system can be accurately identified by the FIA. The conclusion of FIA for the system with noise are almost the same as that without noise in Fig. 4(b).
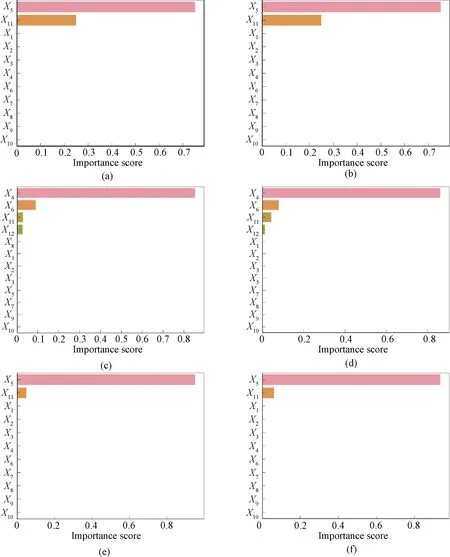
Fig. 4 FIA of different datasets: (a) LFO; (b) LFOWN; (c) LSO; (d) LSOWN; (e)NLFO; (F) NLFOWN
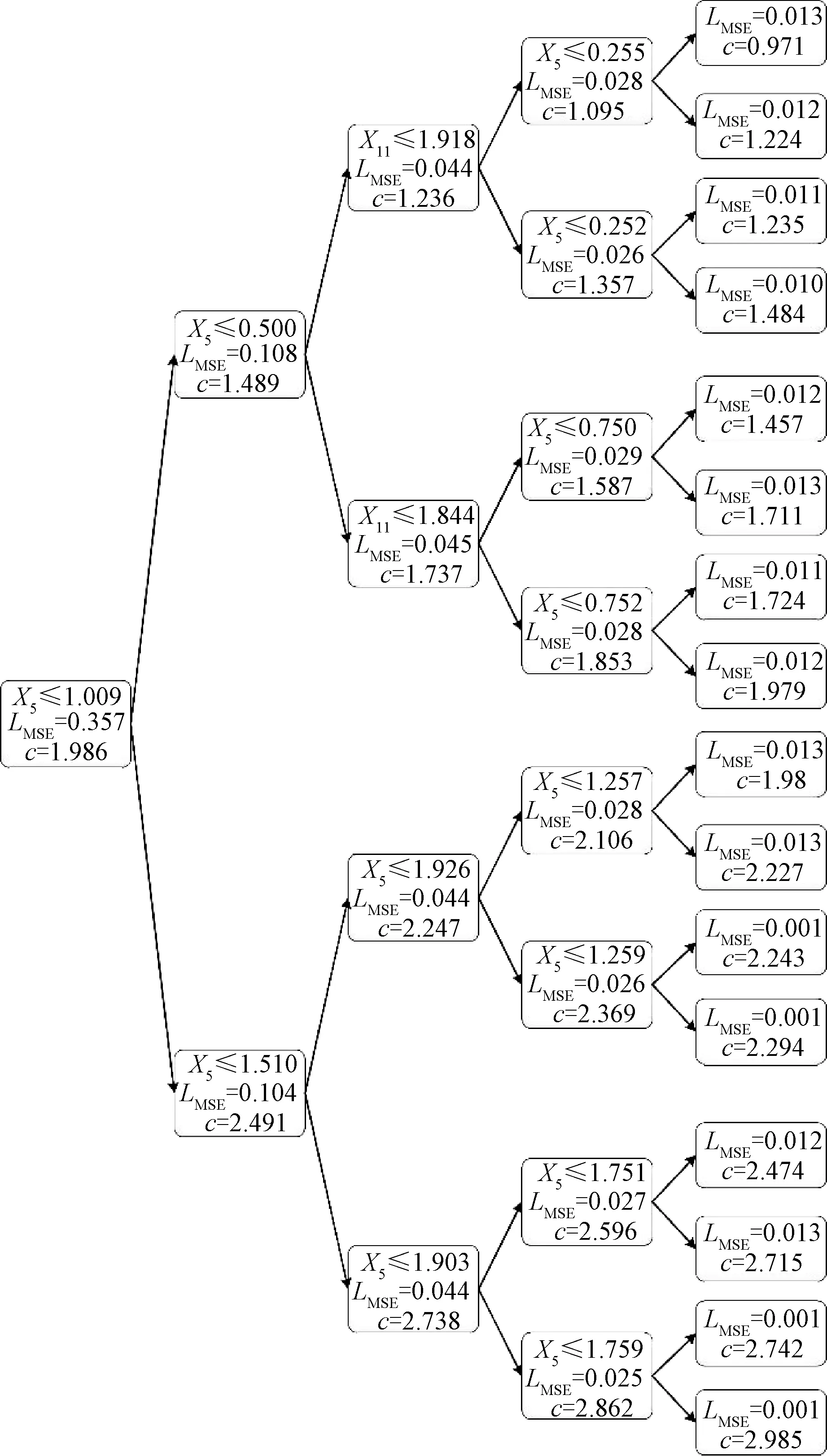
Fig. 5 Visualization of regression decision tree for interpreting LFO dataset
In Figs. 4(c) and 4(d), the results of FIA show that the model has redundant characteristics in the training process, leading to a little deviation in the results of FIA and partial over-fitting of the model, but it is still obviously observed thatX4has the highest score in feature importance score of the LSO system.
Figures 4(e) and 4(f) show that FIA well identifies the time delay of nonlinear system, that is, the feature that has the greatest impact on the system. We can see from Figs. 4(e) and 4(f) that this feature isX5, meaning that the time delay is 5. This is consistent with the time delay set by simulation. Therefore, the time delay of the system is well identified by the interpretability analysis of the regression decision tree, and this paper provides an effective identification method for the system time delay identification.
2.3.2Treedecomposition
In order to see the decision-making process of the regression decision tree more intuitively, the decision-making process of the LFO system is visualized in Fig. 5, wherecis on behalf of the predicted values of themth leaf. As shown in Fig. 5, it is clear that each decision path in the decision tree represents a rule in the decision process.
According to the rule of node selection in the decision tree, the structure of the decision tree is almost split based on the featureX5, which is the most important feature affecting the whole decision tree, and also echoes the feature importance analysis.
3 Conclusions
In this paper, a novel method is proposed for time delay identification by using the interpretability of machine learning. Experimental results show that the method based on the interpretable regression decision tree model can accurately identify the time delay of control systems, and thus provides a new algorithm for time delay identification of dynamical systems.
杂志排行

Journal of Donghua University(English Edition)的其它文章
- Classification of Preparation Methods and Wearability of Smart Textiles
- Computer-Based Estimation of Spine Loading during Self-Contained Breathing Apparatus Carriage
- Click-Through Rate Prediction Network Based on User Behavior Sequences and Feature Interactions
- Predictive Model of Live Shopping Interest Degree Based on Eye Movement Characteristics and Deep Factorization Machine
- Object Grasping Detection Based on Residual Convolutional Neural Network
- Online Clothing Recommendation and Style Compatibility Learning Based on Joint Semantic Feature Fusion