Online Clothing Recommendation and Style Compatibility Learning Based on Joint Semantic Feature Fusion
2022-09-29FEIYuzhe费煜哲SHANGKeke尚科科ZHAOMingbo赵鸣博ZHANGYue
FEI Yuzhe(费煜哲), SHANG Keke(尚科科), ZHAO Mingbo(赵鸣博), 2*, ZHANG Yue(张 悦)
1 College of Information Science and Technology, Donghua University, Shanghai 201620, China
2 Engineering Research Center of Digitalized Textile & Fashion Technology, Donghua University, Shanghai 201620, China
Abstract: Clothing plays an important role in humans’ social life as it can enhance people’s personal quality, and it is a practical problem by answering the question “which item should be chosen to match current fashion items in a set to form collocational and compatible outfits”. Motivated by this target an end-to-end clothing collocation learning framework is developed for handling the above task. In detail, the proposed framework firstly conducts feature extraction by fusing the features of deep layer from Inception-V3 and classification branch of mask regional convolutional neural network (Mask-RCNN), respectively, so that the low-level texture information and high-level semantic information can be both preserved. Then, the proposed framework treats the collocation outfits as a set of sequences and adopts bidirectional long short-term memory (Bi-LSTM) for the prediction. Extensive simulations are conducted based on DeepFashion2 datasets. Simulation results verify the effectiveness of the proposed method compared with other state-of-the-art clothing collocation methods.
Key words: clothing recommendation; style compatibility learning; deep learning; fashion analysis; feature extraction
Introduction
In model society, clothing plays an important role in human’s daily life, as proper outfit can enhance people’s beauty and personal quality. In addition, huge amounts of clothing data emerge in the internet or social media during the past few years due to the development of the clothing e-commerce platform and the coming era of big data. Therefore, how to satisfy the demands of users and improve the user’s purchase desire, is an important means to improve the user experience and sales for clothing electric business platform. From this view of point, clothing collocation technique is of vital significance for both electric business platform and the users.
In general, clothing recommendation needs to explore the compatibility between clothing items. A feasible solution for clothing collocation is to label attribute tags on clothing images, and reasonably collocate clothing category and style information in the attribute tags. For example, the work in Refs.[1-2]. adopted Siamese convolutional neural network (CNN) to transform clothing items from the image space to the style space. Mcauleyetal.[3]utilized a low-rank Mahalanobis transformation to map clothing items into the style space. Afterwards, some works proposed to model the compatibility of items by mapping items into several style spaces[4-5]. However, these methods are time-consuming and labor-costly, which cannot be used on large-scale data. To solve these problems, Lietal.[6]proposed an approach to represent an outfit as a sequence and adopted recurrent neural network (RNN) to model the compatibility. The work in Refs.[7-8] shared similar idea and developed a multimedia-fashion (MM-fashion) method by further representing an outfit as a bidirectional sequence with a certain order (from top to bottom and then to accessories or in an inverse order) and utilized bidirectional long short-term memories (Bi-LSTMs) to predict the next item in an outfit.
In general, Hanetal.[8]proposed to learn the compatibility relationship visual-semantic embedding and image features of fashion elements in an end-to-end network. This method requires both image and word embedding information for training. But in actual scenes, users often need to get the corresponding collocation directly after shooting the clothing image. They do not label the clothing image with text description, and the use of text information in the actual scene is greatly limited. but this method cannot be applied to images without semantic expressions. As a result, this cannot be applied for some real-world applications.
To handle the above problem, we develop an end-to-end framework for clothing collocation learning in this work. Specifically, to extract high-level semantic information, we utilize the feature maps obtained from classification branch of mask regional convolutional neutral network (Mask-RCNN) for feature extraction of certain clothing items. We first combine such features with the ones from Inception-V3 for feature fusion. As a result, both low-level feature information as well as high-level semantic information can be grasped for characterizing the features of certain clothing item. Then, we feed the fused features of clothing outfits into a collocation learning module, which is modeled by a Bi-LSTM. This can be reasonable as the collocation clothing outfits can be viewed as a set of series and Bi-LTSM is an effective approach for sequence prediction. Finally, simulations are conducted based on DeepFashion 2 dataset and the results verify the effectiveness of the proposed work.
The rest of this paper is organized as follows. In section 1, we will develop our new feature fusion module by combining low-level feature information and high-level semantic information learned from Mask-RCNN for feature representation. Based on such fusion module, we then develop an end-to-end framework to jointly learn the compatibility relationships among fashion items as well as visual-semantic embedding; extensive simulations based on DeepFashion2 datasets are conducted in section 2 and final conclusions are drawn in section 3.
1 Clothing Collocation Framework
1.1 Network structure
The clothing collocation network proposed in this paper is an optimized network[8], which is mainly composed of three modules (shown in Fig. 1).

Fig. 1 Feature extraction module structure
(1)Feature extraction module, which extracts low-level feature information and high-level semantic information of clothing images and converts them into feature vectors with the same dimensions.
(2)Feature fusion module, which generates the reference features of fuse information for charactering more image information.
(3)Style compatibility learning module, which treats each item image in the collocation as a time point, uses the Bi-LSTM time series model to learn front to back and back to front, and learn style compatibility between clothing items by learning transformation between time points.
1.1.1Featureextractionmodule
In Ref. [8], the image feature was extracted by adopting Inception-V3 CNN model[10]and then was transformed into 512 dimensionality with one fully connected layer before feeding into the Bi-LSTM. In order to extract high-level semantic information and avoid the above problems, this paper proposes a method of using feature maps as advanced image semantic information in the classification branch of Mask-RCNN network. Specifically, Mask-RCNN maps the adjusted target frame to the corresponding feature layer of the feature pyramid networks (FPN), and only takes the feature map in the target frame for subsequent classification of the target frame. The feature map obtained is connected to a fully connected layer and a SoftMax function to obtain the category of the target frame. It can be seen that the feature map contains as least category information, while the category information and style information are complementary. Therefore, the feature map can be used as high-level semantic information for clothing collocation, and can replace the role of semantic labels to a certain extent. Compared with semantic tag information, this high-level semantic information does not require additional annotations such as text description. In practice, people can directly update a dressed photo to the system and obtain the compatibility score, which is good for handling online clothing recommendation. In addition, since it uses the same parameters to extract image features, it has higher stability and less interference from different clothing attributes and different labeled information, which is conducive to the training of subsequent style compatibility learning modules.
1.1.2Featurefusionmodule
MM-fashion method uses Inception-V3 network to characterize the low-level feature information and design a method that maps image information and text information to an embedded space to fuse the two types of information. The main drawback of this method is that there is a large semantic gap between the image feature information and the text information, which is difficult to optimize and obtain better results. In addition, by adding the loss to the overall loss calculation of the network, the fusion process only assists in optimizing the image feature vector of the input Bi-LSTM. In fact, as the feature vector representing the image, it still mainly depends on the features extracted by the Inception-V3 pre-trained model, and does not use the fused information.
To solve this problem, we propose a feature fusion module by utilizing the low-level feature information and high-level semantic information from Mask-RCNN for eliminating the need to manually label the image description information. We also involve a reference vector for each image as the feature vector of image and input into the Bi-LSTM, which combines both high-level and low-level information of the image to make the semantic interval between the two features can be smaller and easier for optimization. Motivated by this end, a new loss function is designed, which can not only improve the similarity between the three feature vectors, but also increase the discrimination of the reference vector between different images.
In detail, letVliandVhibe the low-level feature information and high-level semantic information after the clothing item imageMiis input to Inception-V3 and Mask-RCNN. Then similar to the work in Ref. [8], we adopt weight matricesWlandWhto mapVliandVhiinto low-level feature vectorfliand high-level semantic vectorfhiwith the same dimension. We also definefeias a reference vector of image, which is equivalent to the mean offliandfhi. Calculate the distances between the reference vectorsfeiandflior between the reference vectorsfeiandfhi, respectively, and calculate the distance between the reference vectors of the other imagesMj,j∈C,j≠iin the clothing item image setCof the reference vectorfei. Define the loss functionLpullto makedlianddhias small as possible and the loss functionLpushto makedijas large as possible.
(1)
where Δ is the threshold. It can be observed if the reference vector, the low-level feature vector, and the high-level semantic vector belong to the same image, optimizingLpullwill make the distances between them smaller; if the feature vectors belong to different images, optimizingLpushwill make the distances of their reference vectors larger. Compared with the method in MM-fashion, the feature fusion module proposed in this paper does not need to label the image. And both the low-level feature vector and the high-level semantic vector belong to the image feature vector, which can be easily integrated. In addition, the reference vector has a stronger ability to express images as more discriminative information.
1.1.3Stylecompatibilitylearningmodule
This paper considers a collocation of clothing item images as an ordered sequence, which is arranged in the order of tops, bottoms, shoes and accessories, and each image is considered as an independent time point. As shown in Fig. 2, for the clothing collocation task, the order from left to right and right to left has the same style, and they are all ordered sequences. For example, if the image at the current time point is a short skirt, it is reasonable that the image at the previous time point is coat and shoes. Based on this feature of the clothing collocation task, this paper uses Bi-LSTM (bilateral LSTM) to capture the forward and backward style information at the same time, and establish the visual compatibility relationship of collocation. This detail illustration of Bi-LSTM can be seen in Ref. [8].

Fig. 2 Illustration of compatibility learning module via Bi-LSTM
1.2 Joint training
The feature fusion module proposed in the previous section is a sub-module in the collocation network. The low-level feature vectors and high-level semantic vectors of the input image can be trained according to the loss function. However, if this process is independent of the collocation network, the reference vectors may not be well applied to the Bi-LSTM-based style compatibility module. To solve this problem, the two modules are jointly trained in this paper. The objective function of the overall network is
(2)
whereΘ={Θf,Θb,Θe}, and the first two terms are the objective functions of Bi-LSTM while the third term is the loss function of the feature fusion module. The entire framework can use time-based back-propagation through time(BPTT) algorithm to complete end-to-end training.
2 Experiments
2.1 Overall system design of clothing collocation
The previous section introduced the use of the improved Mask-RCNN and the clothing collocation network to achieve the instance segmentation of clothing pictures and the collocation recommendations of clothing items. The two parts are independent of each other, but in practice, users often want to input an image containing multiple items of clothing, such as images of their own clothing wearing, to get corresponding collocation recommendations. This requires segmenting the clothing in the image and then sending it to the clothing collocation network. Therefore, a complete clothing collocation system should be composed of two parts (shown in Fig. 3): the early instance segmentation and the later clothing collocation recommendation. The designing clothing collocation system will combine these two parts to complete an end-to-end clothing collocation system. In order to make the segmentation mask of the clothing items more accurate, the mask post-processing module is added after the instance segmentation network output mask to improve the accuracy of the segmentation mask.
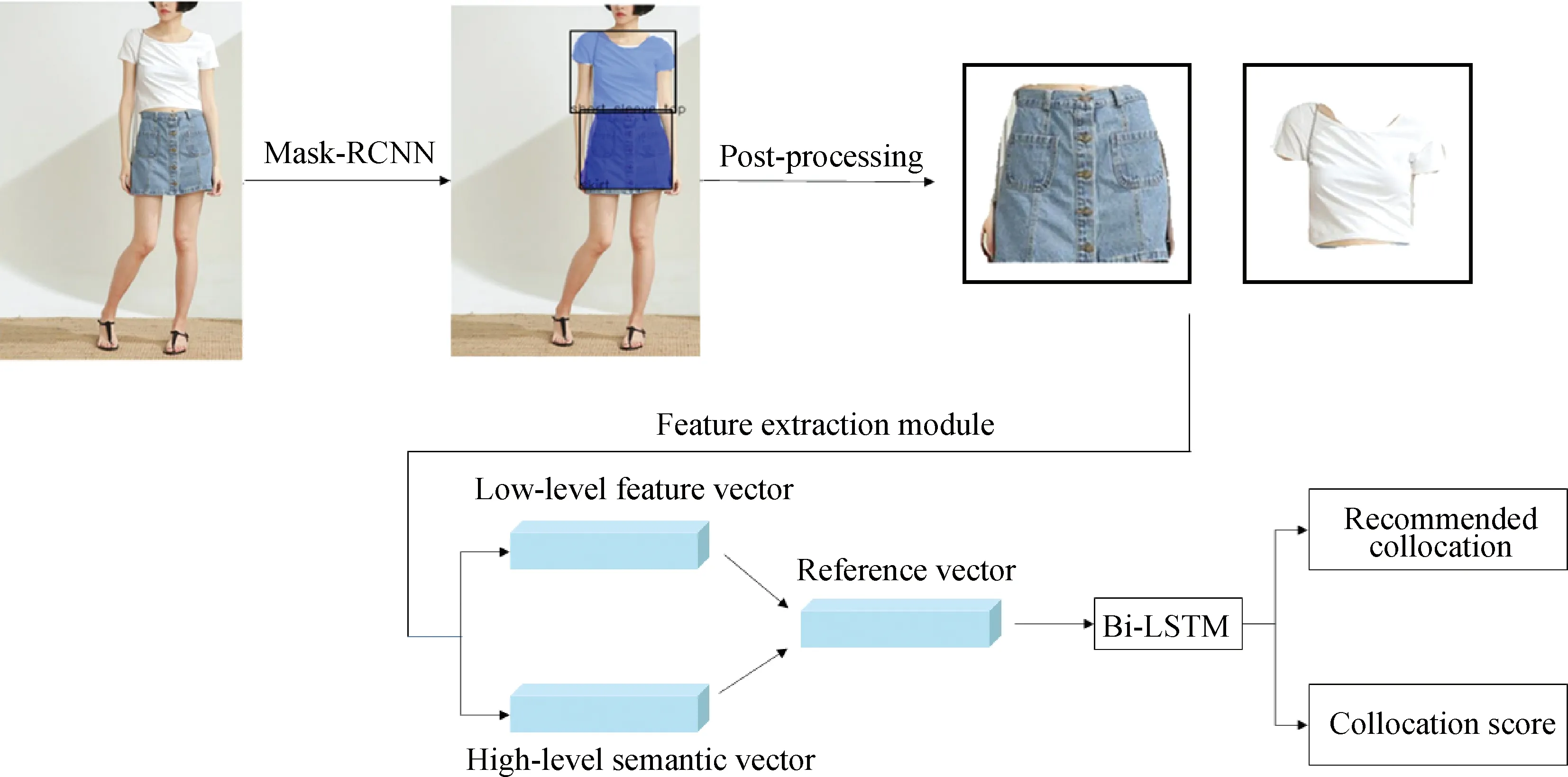
Fig. 3 Overall clothing collocation system
2.2 Mask processing
The segmentation branch of Mask-RCNN is actually a small full convolutional network (FCN), which performs pixel-by-pixel segmentation by predicting the category of each pixel in the image. This segmentation method is easy to appear in a complete object. The category prediction of most pixels is correct and a small number of pixels are caused by the interference of light, noise and other factors to cause the category prediction error. The mask is post-processed to correct it. In addition, Mask-RCNN is an object corresponding to a target frame. If there are multiple objects in a target frame, the segmentation prediction is incorrect. The method adopted in this paper is to count the number of objects in the target frame. If it has more than one object, only the object with the largest area in the target frame is retained.
This work first performs a closed operation on the segmentation mask (the foreground is 1 and the background is 0) within a target frame. However, the predicted mask belonging to a clothing item may be split into two parts due to a small number of pixels in the background predicted as the foreground. The work will then perform another operation to delete such small number of miss-predicted pixels in order to merge into a complete mask. Finally, based on the contour of the mask in the target frame, if the number of contours is greater than 1, only the mask within the area of the largest contour is preserved as the final clothing item mask.
2.3 Specific process of clothing collocation system
The flow diagram of the clothing collocation system proposed in this paper is shown in Fig. 2, and the specific steps are as follows.
(1) The image is input into the Mask-RCNN network to obtain the target frame, mask, and category information of the clothing item.
(2) The mask of the clothing item in each target frame is sent to a post-processing module to obtain a finer mask and segment the clothing items from the original image into an independent single product image.
(3) The clothing item images are input to the feature extraction module to extract the low-level feature information and the high-level semantic information.
(4) The extracted two image features are sent to the feature fusion module to obtain the image reference vector, and they are input to the Bi-LSTM based style compatible module to complete subsequent collocation tasks.
2.4 Experimental verification of clothing collocation system
2.4.1Clothingcollocationrecommendation
For this task, the test data set constructed in this paper is based on DeepFashion2 dataset[9]. The images are input to the Mask-RCNN network to obtain clothing item images, where those item images formulate a clothing item library. Images of clothing items are extracted from the image features using the clothing collocation network to make an image feature library. For each clothing item separated from the input image, randomly select 10 images from the clothing item library as the candidate image set, the clothing item features of the input image and the image features corresponding to the candidate image are input to the clothing collocation network for scoring. Each image in the candidate image set is scored and the image with the highest score is selected as the final result. Figures 4 and 5 show the process and results. From simulation results in Fig. 5, the proposed approach can well handle the clothing collocation recommendation task by giving relatedly more collocational outfits.
2.4.2Clothingcollocationscoring
For scoring the images in the DeepFashion2 dataset, the process of extracting the feature of clothing items in the early stage is the same as that for clothing collocation recommendations. In detail, the features of all single product images are input to the clothing collocation network to calculate the sum of losses of the Bi-LSTM, where such losses are then converted into probability. Some results are shown in Fig. 6. From simulation results in Fig. 6, we can observe the collocation score is quite closely related to popular aesthetic. This shows the effectiveness of the proposed method for handling clothing collocation scoring task.
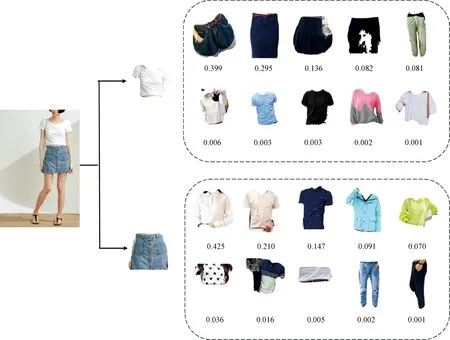
Fig. 4 Process and results of clothing collocation system on DeepFashion2 dataset

Fig. 5 DeepFashion2 dataset clothing recommendation result map

Fig. 6 DeepFashion2 dataset clothing collocation score results
3 Conclusions
This paper proposes a clothing collocation learning framework, which consists of two parts: the early instance segmentation and the later clothing collocation recommendation. From the perspective of choosing collocation tasks and scoring tasks, the proposed framework has a better effect on clothing collocation tasks. This improvement is believable to be true due to the useful information. That is, both the low-level feature information and the high-level semantic information are adopted for feature extraction. In addition, the proposed framework do not utilize any label information of text description, which is more practical for handling online clothing collocation task. Though the proposed work achieves satisfied results, our future work will lie in adopting transformer strategy to further enhance the performance of the accuracy.
杂志排行

Journal of Donghua University(English Edition)的其它文章
- Classification of Preparation Methods and Wearability of Smart Textiles
- Computer-Based Estimation of Spine Loading during Self-Contained Breathing Apparatus Carriage
- Click-Through Rate Prediction Network Based on User Behavior Sequences and Feature Interactions
- Predictive Model of Live Shopping Interest Degree Based on Eye Movement Characteristics and Deep Factorization Machine
- Object Grasping Detection Based on Residual Convolutional Neural Network
- Time Delay Identification in Dynamical Systems Based on Interpretable Machine Learning