Object Grasping Detection Based on Residual Convolutional Neural Network
2022-09-29WUDiWUNailong吴乃龙SHIHongrui石红瑞
WU Di(吴 迪), WU Nailong(吴乃龙) , SHI Hongrui(石红瑞)
College of Information Science and Technology, Donghua University, Shanghai 201620, China
Abstract: Robotic grasps play an important role in the service and industrial fields, and the robotic arm can grasp the object properly depends on the accuracy of the grasping detection result. In order to predict grasping detection positions for known or unknown objects by a modular robotic system, a convolutional neural network(CNN) with the residual block is proposed, which can be used to generate accurate grasping detection for input images of the scene. The proposed model architecture was trained on the standard Cornell grasp dataset and evaluated on the test dataset. Moreover, it was evaluated on different types of household objects and cluttered multi-objects. On the Cornell grasp dataset, the accuracy of the model on image-wise splitting detection and object-wise splitting detection achieved 95.5% and 93.6%, respectively. Further, the real detection time per image was 109 ms. The experimental results show that the model can quickly detect the grasping positions of a single object or multiple objects in image pixels in real time, and it keeps good stability and robustness.
Key words: grasping detection; residual convolutional neural network(Res-CNN); Cornell grasp dataset; household objects; cluttered multi-objects
Introduction
Humans can grasp unknown objects easily and quickly owing to their own experience and instincts, but it is a big problem for robotic arm to achieve the accurate grasping of any objects. As science and technology become more and more intelligent, it is urgently required for robots to grasp a variety of objects quickly and accurately in industrial parts assembly, sorting and other applications. A successful grasp is that the robot can use the learned knowledge to find the position of the grasping object and the corresponding posture accurately.
With the great success of deep learning in the detection, classification and regression, and the popularity of low-cost depth cameras, the grasping detection of robots has also made breakthrough progress. In 2011,Jiangetal.[1]proposed a five-dimensional representation method for robot grasps. As shown in Fig. 1, the grasping rectangle is represented by a five-dimensional vector:g=(x,y,w,h,θ), where (x,y) is the center of the rectangle of the grasping object in the image,wandhare the width and height, respectively, andθis the orientation of the reference horizontal axis. This method of using five-dimensional vector representation converts the grasping detection into a problem similar to object detection in computer vision.
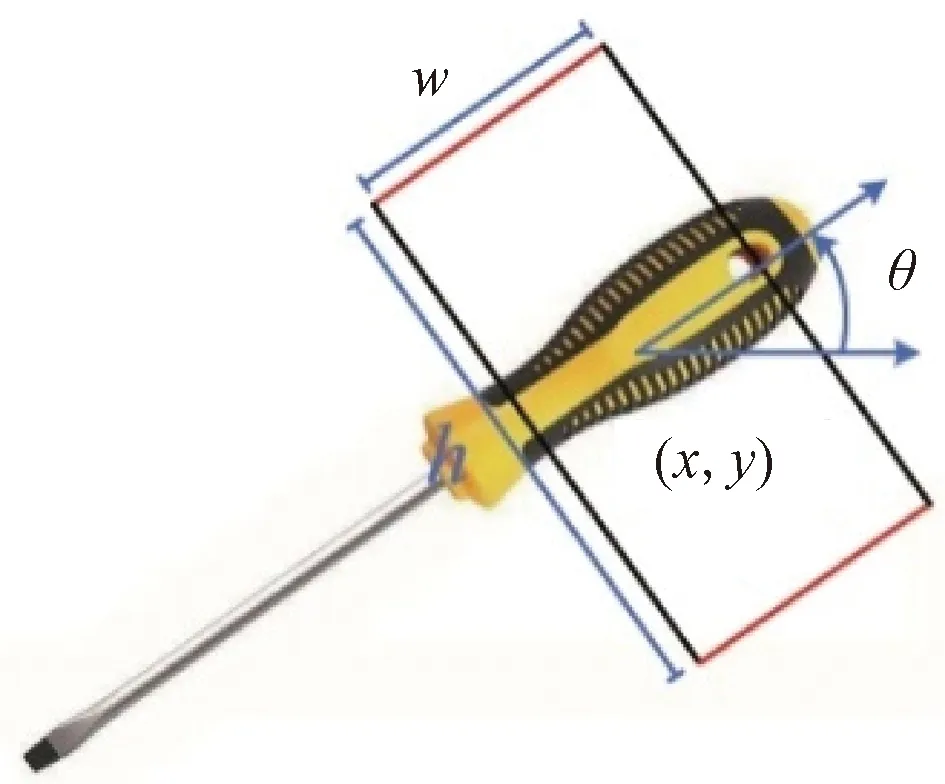
Fig. 1 Five-dimensional grasping rectangle diagram
Lenzetal.[2]proposed a cascading method of multi-layer perceptrons and used support vector machine (SVM) to predict whether there were grasping objects in the image, but it took a long time to traverse the layers. Redmon and Angelova[3]used the currently popular AlexNet convolutional neural network(CNN) model to obtain higher detection accuracy, but the detection speed was slow.
In the previous work[1-3], the grasping prediction rectangle was the best one among many possible grasping rectangles. Different from these grasp detection algorithms, the paper proposes a residual convolutional neural network (Res-CNN) that outputs three images from the input image to predict the grasping position. The red-green-blue (RGB) image and the aligned depth obtained from the RGB-D camera are preprocessed and fed into the Res-CNN. The input image is passed through the network to generate three images, which are grasping quality, grasping width and grasping angle, respectively. The final grasping detection position can be inferred from the three images. In addition, the network can also grasp multiple objects in a cluttered environment one by one or at the same time, which greatly enhances the performance of the network.
The main contributions of the work are as follows.
(1) A new Res-CNN is proposed, which can be used to predict appropriate grasping position of novel objects.
(2) The model is evaluated on the publicly available Cornell grasp dataset, and the accuracy of image-wise splitting detection and object-wise splitting detection was 95.5% and 93.6%, and the real detection time for per image is 109 ms.
(3) The model can not only detect the grasping position of a single object, but also infer multiple grasping rectangle positions of multiple objects in one-shot.
1 Grasping Point Definition
When an object appears in the scene, a reliable method needs to be found to detect and grasp this object. Therefore, the problem of robotic grasping is defined as from the RGB-D input image of the object in the scene to predict the grasping position. Like the method proposed by Morrisonetal.[4], this paper considers the problem of grasping detection on novel objects as a graspg=(p,φ,ω,q), perpendicular to a planar surface. A grasp point detected from the input depth imageI=RH×W, which is described by
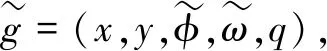
(1)
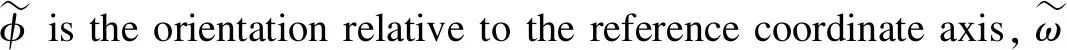
The grasp sets in an image is defined as
G=(Φ,W,Q)∈R3×H×W,
(2)
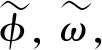
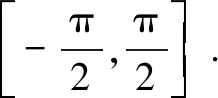
Wis an image that represents the required grasping width at every point. The value is in the range of [0, 100] pixel, and 100 indicates the maximum width measurement grasped by the gripper, which can be calculated from the depth camera parameters and the measured depth.
Qis an image that represents the required grasping quality score to be executed at every point (x,y) , and its value is between 0 and 1. The closer its value is to 1, the greater probability of a successful grasp is.
2 Grasping Detection with Neural Networks
CNN has been proven to be superior to the performance of manually designed feature spaces, and is currently far superior to other technologies in computer vision, such as object classification[5]and object detection[6]. As a classifier in the sliding window method[2], CNN also shows good performance in grasping detection. Based on the previous CNN model, this paper proposes a new Res-CNN model, which is mainly used to predict the appropriate grasping positions of the objects in the field of the camera.
2.1 Prediction model
The architecture of the prediction model is shown in Fig. 2. First, the RGB image and the aligned depth image are obtained through the RGB-D camera(Intel D435i, USA). After preprocessing, the image is resized to 224×224 pixels, which is then fed into the Res-CNN. Secondly, the input pre-processed image that enters the Res-CNN is subjected to feature extraction to generate three images, which are the grasping quality score, the grasping angle, and the grasping width. Finally, the final grasping detection position can be inferred from the three images.

Fig. 2 Prediction model
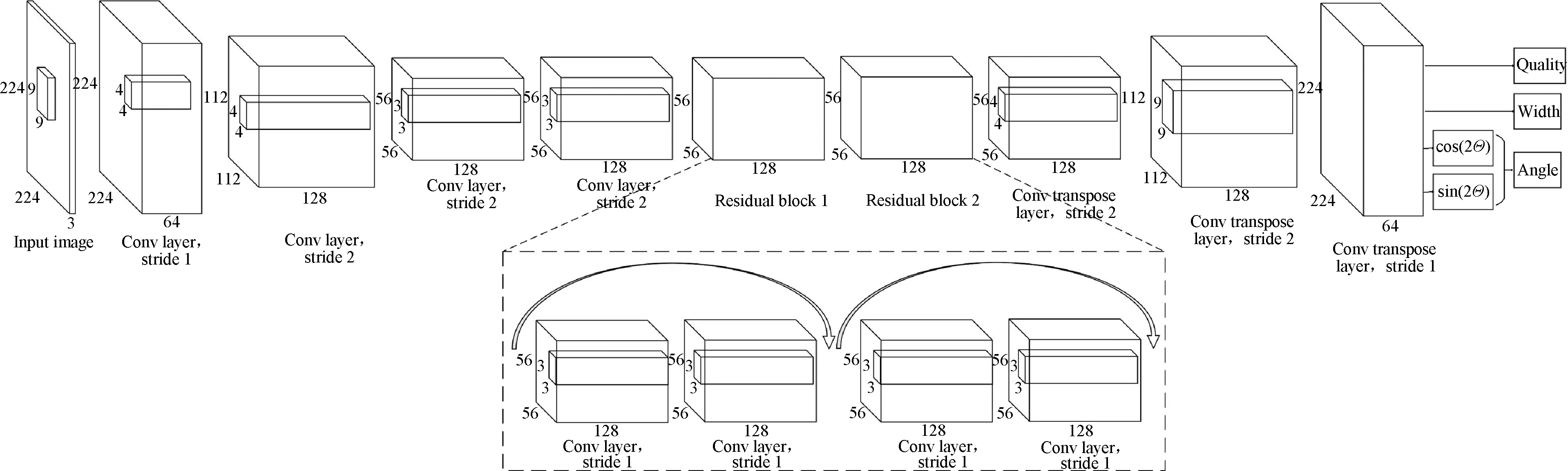
Fig. 3 Res-CNN model architecture
2.2 Data preprocessing
On the premise that the data can be used for calculation, the data preprocessing can improve the accuracy of the analysis results and shorten the calculation process, which is the purpose of data preprocessing. Before feeding the input image into the network, a series of preprocessing operations are performed on it. The depth image is normalized to fall between 0 and 255. Objects in the image may not be able to obtain depth information because of occlusion, and 0 is used to replace these pixel values. When preparing the data for training, we perform data augmentation by some operations such as random cropping, translation, and rotation on the image. This image is then resized to 224×224, which meets the input image size of the network.
2.3 Network architecture
Figure 3 shows the Res-CNN model architecture. The network model proposed in the paper is derived from the generative residual convolutional neural network (GR-CNN) model for grasping detection proposed by Kumraetal.[7]The model consists of four convolution layers, two residual block layers, and three convolution transpose layers. The input image is passed through the network to generate three images of the required grasping quality, the required grasping width, and the required grasping angle.
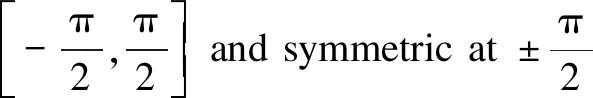
It can be seen from the architecture of network model that the residual block layer is closely followed by the convolutional layer. In the previous training neural network model, as the number of layers increases, the accuracy will also increase; but when the number of layers increases to a lot, there will be problems of gradient disappearance and dimensional errors, which will lead to saturation and decrease of accuracy. Therefore, using the residual layer to skip connections can deepen the number of network layers while also solving the problem of gradient disappearance and improving the accuracy of the model. After feature extraction of the convolution layer, the size of the output image is 56×56. In order to preserve the spatial features of the image, the size of the output image should be consistent with that of the input image. Therefore, a convolution transpose layer is added to upsample the image to increase the size to 224×224.
From the input of the convolutional layer to the output of the final convolutional transpose layer, the Res-CNN network contains 1 714 340 parameters. Compared with other CNN[3,9-10]models with similar but complex grasp architectures for grasping detection, it shows that the network architecture is shorter, which makes it faster and more affordable in terms of calculation.
2.4 Training
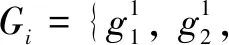
Commonly used loss functions includeL1loss,L2loss, and the smoothL1loss. Combined with the performance of the network for these types of loss functions and in order to solve the problem of gradient explosion, the smoothL1loss has the best effect. It is defined as
(3)
whereGiis the grasping position predicted by the Res-CNN, andGTis the ground truth.
3 Experiments and Evaluation
3.1 Training datasets
In order to train the network, the Cornell grasp dataset which is mostly suitable for grasping objection is used. The Cornell grasp dataset consists of 885 images containing 240 distinct objects marked with 5 110 positive and 2 909 negative grasping ways. The resolution of the images is 640×480. Each object in each image is marked with multiple grasping rectangles representing different possible methods to grasp the object, as shown in Fig. 4. These labels are rich and diverse in direction, position, and size, but they do not describe every possible grasp in detail, instead, list a variety of possible grasps to get the most accurate grasp.

Fig. 4 Cornell grasp dataset containing various objects with multiple labelled grasps
Although the Cornell grasp dataset is relatively small compared to some recent synthetic grasp datasets[13-14], it is most suitable for pixel-wise grasp that provides multiple labels for each image. In this paper, we use 80% of training datasets for training the network and 20% for the evaluation datasets.
3.2 Metric
For the evaluation of the Cornell grasp dataset, two different metrics are commonly used. The point metric compares the distances from the detected grasping center to each of the ground truth grasping centers. If any one of them does not exceed some certain threshold, then it can be judged as a successful grasp. The main problem with this method is that it does not consider the difficulty of selecting the grasping angle or size and the threshold. Therefore, the point metric method is not used.
The rectangle metric[1]is mainly used to measure the entire grasping rectangles compared to the ground truth. According to the proposed rectangle metric, whether a grasping rectangle is effective or not depends on the following two conditions.
(1) The angle is within 30° between the detected grasp rectangle and the ground truth grasp rectangle.
(2) The Jaccard index of the detected grasp rectangle and the ground truth rectangle is greater than 25%.
It is defined as
(4)
whereAis the detected grasp rectangle andBis the ground truth grasp rectangle.
The rectangle metric is more suitable to distinguish the accuracy of grasping than point measurement. Although the Jaccard index has a lower threshold, it is similar to the index used in object detection because there are multiple possible grasp locations. A predicted grasping rectangle can be judged as a more accurate grasp as long as it overlaps a ground truth grasping rectangle by 25%. The rectangle metric is used to evaluate the entire experiment.
3.3 Physical components
In order to obtain the RGB image and depth image of the experimental object, realsense depth camera D435i was used during the grasping detection experiment, which is composed of camera module and computing processor board. The hardware platform which the Res-CNN runs on is Jetson AGX Xavier, and the environment it carries is Ubuntu 18.04 and CUDA10, with the code predominantly written in Python3. On this platform, the detection time of the network for the input image is 109 ms.
3.4 Test objects
For commonly used grasping objection experiments, there is no fixed set of test objects, and most people often use novel “household” objects which are not easy to replicate. In this experiment, the following objects are used to evaluate the trained network: standard Cornell grasp dataset, household objects, and cluttered multiple objects.
Household objects consist of ten objects in different sizes, shapes, and geometric structures randomly, with minimal redundancy (i.e., almost no similarities between each other), including novel objects that have not been learned. The objects are selected from the commonly used robot grasping dataset ACRV Picking Benchmark(APB)[15]and Yale-CMU-Berkeley(YCB) object set[16]. Although APB and YCB object set have enough objects which can be used for experiment, many objects can not be geometrically grasped and detected, such as screws (too small), envelopes (too thin), large boxes (too large), or pans (too heavy). Excluding these objects, various types of objects should be selected for experiments to compare the results with other works using the same object sets[1-3,17]. A series of objects used in the experiment are shown in Fig. 5.

Fig. 5 Objects used for grasping experiments
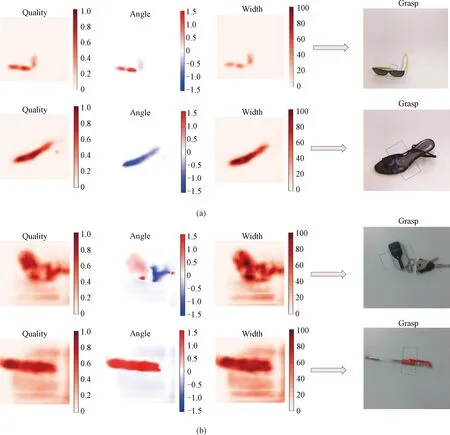
Fig. 6 Single object grasping detection results: (a) unseen objects from Cornell grasp dataset;(b) household single objects
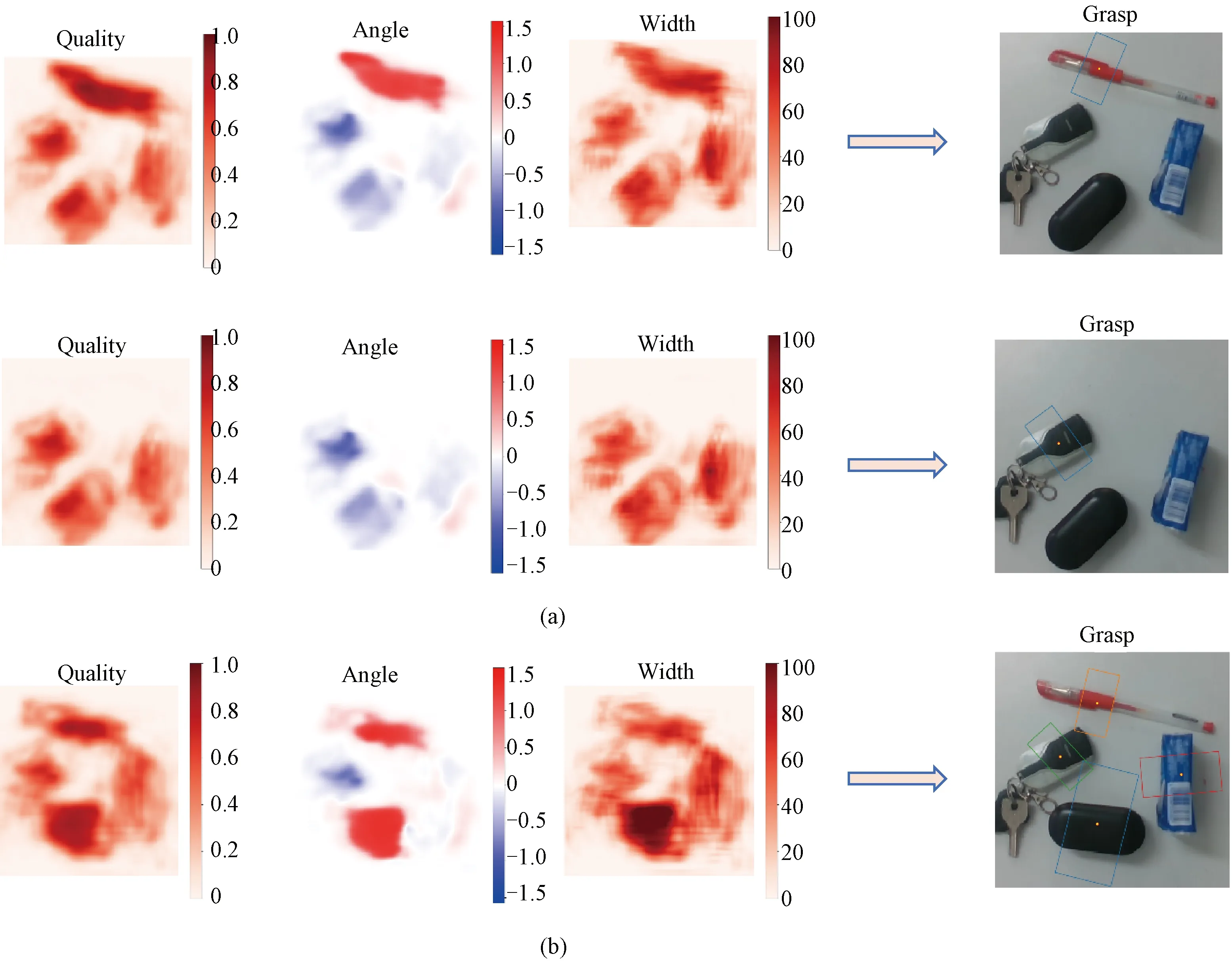
Fig. 7 Grasp results in a cluttered environment with multiple objects: (a) single successive grasp for multiple objects; (b) multiple grasps for multiple objects
Cluttered multiple objects refer to placing multiple objects randomly and disorderly together. In industrial applications, it is necessary to grasp single objects one by one in a cluttered environment of multiple objects.
Therefore, in order to evaluate the robustness of the model on cluttered objects, a group of different objects were selected from novel objects that have not been seen before to form a clutter environment for experimentation. The evaluation criterion is to see whether the model can accurately detect the grasping position of a single object or multiple grasping positions of multiple objects.
4 Results and Analysis
The model is trained on the Cornell grasp dataset and evaluated on the novel objects from the Cornell grasp datasets. In addition, novel household objects are used for experiment to evaluate that the model has strong robustness for various types of objects. The results show that the network model can be well extended to novel objects that have not been seen before and can generate accurate grasps.
Figure 6 shows the results of the grasping detection of single objects. It contains test data from Cornell dataset and household objects that have never been seen before. The model can perform accurate grasping detection for the data in the Cornell dataset, and can also show good performance for grasping detection of novel household objects.
Figure 7 shows the grasping detection in a cluttered environment with multiple objects. The model can accurately detect the grasping detection position of single objects among multiple objects in clutter, which is suitable for successive grasps in the industrial field. Moreover, despite being trained only for a single object, the model can be used to detect multiple grasps for multiple objects in a cluttered environment. This proves that the network has good robustness and can be applied to object grasping detection in various environments.
Like the previous work[2-3,10,18], the experimental results adopt cross-validation and divide the data into image-wise (IW) splitting and object-wise (OW) splitting. The IW splitting tests the ability of the model to generate grasping detection for objects that have been seen before. OW splitting tests the performance of the network on unknown objects. In experiments, since different objects in the data set exhibit similar characteristics, these two techniques can generate comparative results (for example, different glasses have different sizes and materials, but have similarities).
Table 1 shows the comparison of the grasping accuracy and speed between Res-CNN model and other grasping detection technologies. The results of model in IW splitting detection and OW splitting detection accuracy rates have reached 95.5% and 93.6%, and the detection speed for each image is 109 ms, which is better than other grasping detection techniques. In addition, the results of grasping objects that have not been learned before show that the Res-CNN model can grasp various types of objects robustly. According to the above comparison, the Res-CNN model has better performance.
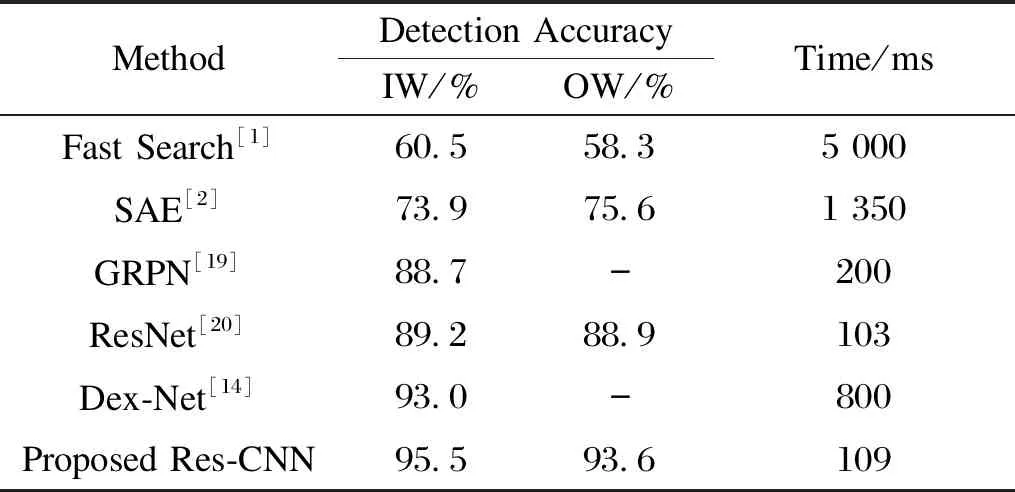
Table 1 Comparison of experimental results of grasping detection
5 Conclusions
This paper proposes a Res-CNN model to solve the problem of grasping novel objects. The input RGB-D images in the scene are used to predict grasping positions for each pixel in an image through the network. It is trained and evaluated on the standard Cornell grasp dataset. Compared with other grasp detection algorithms, the Res-CNN model can ensure a higher accuracy rate while achieving a faster detection speed. The model not only validated single grasps of novel household objects, but also validated a single-sequential grasp and multiple grasps of multiple objects in a cluttered environment. The result demonstrates that the model can predict grasps accurately for previously unknown objects. At the same time, the faster prediction speed makes the model suitable for grasping detection in real time. In future research work, we will further improve the network model’s grasping detection accuracy and the image detection speed, and extend the model for more complex types of objects(for example, the launch and the recovery of a kind of underwater vehicle).
杂志排行

Journal of Donghua University(English Edition)的其它文章
- Classification of Preparation Methods and Wearability of Smart Textiles
- Computer-Based Estimation of Spine Loading during Self-Contained Breathing Apparatus Carriage
- Click-Through Rate Prediction Network Based on User Behavior Sequences and Feature Interactions
- Predictive Model of Live Shopping Interest Degree Based on Eye Movement Characteristics and Deep Factorization Machine
- Time Delay Identification in Dynamical Systems Based on Interpretable Machine Learning
- Online Clothing Recommendation and Style Compatibility Learning Based on Joint Semantic Feature Fusion