致密低渗油藏压裂井网气驱深度学习预测模型
2022-09-27朱璇袁彬同元辉赵明泽郑贺刘秀磊
朱璇,袁彬,同元辉,赵明泽,郑贺,刘秀磊
1)中国石油大学(华东)石油工程学院,山东青岛 266580;2)中国石油塔里木油田实验检测研究院油气分析测试中心,新疆库尔勒841009
2021年,中国原油和天然气对外依存度分别高达73%和43%[1],油气资源高效开发成为能源安全重大需求.中国致密油藏储量巨大,占全国新增探明储量的75%以上,但致密油储层品位低、物性差、产量低[2],亟需提高采收率.压裂气驱是当前开采致密低渗油藏最有效的提高采收率技术之一,准确模拟压裂气驱过程、预测生产效果是实现致密低渗油藏注气高效开发的关键理论基础.目前,进行油藏生产效果预测的方法主要有传统油藏工程方法和油藏数值模拟方法.传统油藏工程方法仅能建立较简单的预测模型,难以考虑不同油藏类型、开发阶段和工作制度等因素;油藏数值模拟方法可以模拟实际生产井条件,预测任意措施的效果,但需要以准确的地质模型和历史拟合为基础,模拟拟合预测周期较长,调参繁琐,不适合短期、局部的快速调整预测.
近年来,深度学习算法在油气勘探和生产分析中得到广泛应用[3],包括压力体积温度(pressure&volume &temperature,PVT)特性预测、矿物识别、渗透率预测、增产措施预测、油藏描述[4]、流体分析[5]和生产曲线分析[6]等.针对本研究所聚焦的压裂场景,MAKHOTIN等[7]采用梯度提升算法预测水力压裂增产效果;LIU 等[8]利用含有多隐藏层的人工神经网络预测了多裂缝性页岩储层产油量;SONG 等[9]基于粒子群优化的长短期记忆单元(long short-term memory,LSTM)算法预测了火山岩储层压裂水平井产能.针对井网注采场景,目前采用机器学习方法预测注水开发效果等研究较多,包括KALAM 等[10]利用人工神经网络预测了层状油藏五点注水开发的采收率;PAL[11]将基于LSTM 的递归神经网络模型应用于致密碳酸盐岩油藏长水平井注水开发产量预测;DONG等[12]研究了基于深度学习的CO2最小混相压力预测等.但目前采用深度学习方法预测注气开发效果研究相对较少.
压裂气驱是将油藏压裂与注气驱油相结合,是当前开采致密低渗油藏提高采收率有效技术之一,然而,水力裂缝性质和多相流动的复杂性,使得通过建立精细油藏数值模拟预测压裂井网注气开发效果变得更加困难和耗时[13].为此,本研究将深度神经网络(deep neural network,DNN)算法与油藏压裂注气开采技术相结合,实现基于数据模型的油藏生产效果准确高效预测,提高生产效率,对致密低渗油藏开发与管理提供借鉴.
1 油藏数值模拟模型建立
基于Eclipse 的E300 组分模拟器,分别建立致密低渗双孔双渗油藏压裂衰竭开发和注气开发数值模拟基础模型,所建模型基本参数如表1.
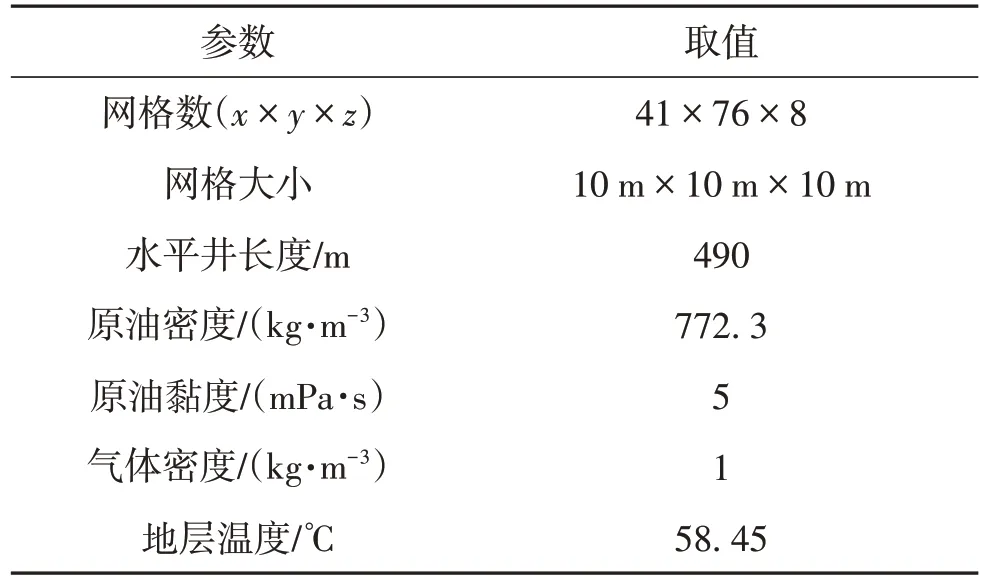
表1 模型基本参数Table 1 Basic parameters of the model
所建立的致密低渗油藏压裂衰竭开发模型和注气开发模型[14]中,采用局部网格加密技术,对压裂生产水平井多级水力裂缝进行模拟.其中,等效裂缝导流能力范围为0.15~0.51 μm2·m,等效裂缝网格宽度为0.1 m.在致密低渗油藏注气开发模型中,对每口注气直井分别压裂,双翼裂缝沿x方向、缝长为60 m,等效导流能力范围为0.15~0.51 μm2·m,等效裂缝网格宽度为0.1 m.水力裂缝导流能力等效公式为

其中,f=1,2,…,n(n为各数值模拟模型水力裂缝条数);wf和Δf分别为水力裂缝和等效水力裂缝网格的宽度,单位:m;分别为水力裂缝和等效水力裂缝网格的渗透率,单位:μm2.
本研究建立的致密低渗油藏压裂井网注气开发数值模拟模型如图1,压裂衰竭开发模型无注气井.
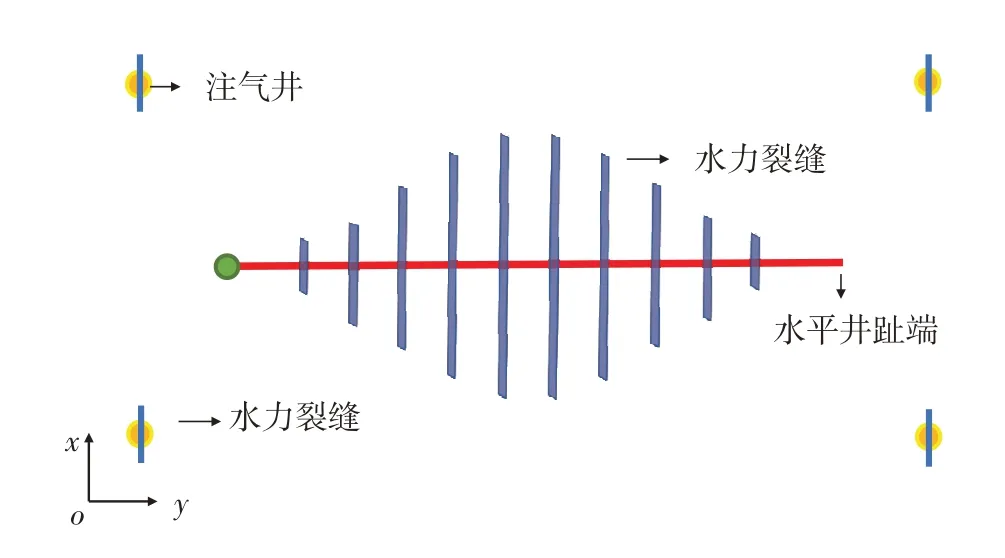
图1 致密低渗油藏压裂井网注气开发数值模拟模型示意图Fig.1 Schematic diagram of numerical simulation model of gas flooding in fractured well pattern in tight oil reservoirs.
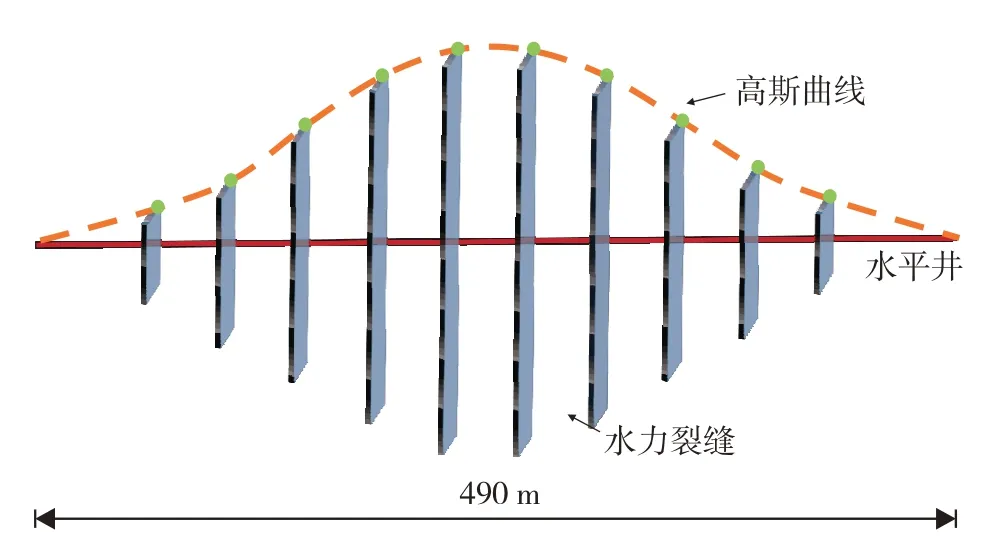
图2 水平井水力裂缝分布示意图Fig.2 Schematic diagram of horizontal well distribution.Gaussian function curve(dashed line)was introduced to calibrate the position of heel,toe and equivalent hydraulic fracture tip of horizontal well(green dots).
一维高斯函数公式为

其中,a为曲线尖峰的高度;b为标准方差;d为尖峰中心的坐标.水平井水力裂缝以水平井中心位置左右对称,本研究设置d=0.5.
油藏基质系统油-气两相相对渗透率可采用Stone公式计算,如式(3)至式(6)所示.

其中,Sw为含水饱和度;Swc为束缚水饱和度;Sorw为油水系统残余油饱和度;krw为油水系统水相相对渗透率;krwmax为油水系统最大水相相对渗透率;nw为油水系统水相指数.krow为油水系统油相相对渗透率;now为油水系统油相指数;Sg为含气饱和度;Sgc为束缚气饱和度;Sorg为油气系统残余油饱和度;krg为油气系统气相相对渗透率;krgmax为油气系统最大气相相对渗透率;ng为油气系统气相指数.krog为油气系统油相相对渗透率;nog为油气系统油相指数.
2 深度学习预测模型建立
代理模型指通过训练复杂度低的数学模型,替代原有模型进行设计优化[16].常用的代理模型有克里金方法、多项式响应面法和神经网络方法等.本研究中构建并对比了3种神经网络代理模型.
2.1 误差反向传播神经网络
误差逆传播(back propagation,BP)神经网络是一种典型多层前馈神经网络,只在一个方向训练模型,不考虑过去输入数据的反馈,任何一层的输出不影响在同一层进行的训练过程(即没有记忆).
2.2 长短期记忆单元
与前馈神经网络不同,基于反馈的神经网络是动态的,模型状态不断变化,直到达到平衡状态.传统前馈神经网络不能处理顺序输入,而且所有输入(和输出)必须彼此独立.而基于反馈的递归神经网络模型(recurrent neural network,RNN)提供门来存储并利用之前输入的顺序信息,成为时间序列数据建模的有效选择.
Email:cefs@vip.163.com(有意参加者,请先发邮件索要报名表)。投稿和演讲日程等学术事宜,请联系臧建成大夫(电话)13261797099
普通RNN 不能记忆长时间输入,LSTM 是针对RNN的完善扩展,能记忆长时间输入数据,解决梯度消失问题.图3 为单个LSTM 神经元的运算示意图.由图3 可见,在1 个LSTM 单元结构中,输入t时刻输入值xt、t-1时刻输出值ht-1和t-1时刻单元状态值ct-1,生成4 个加权输入参数(Zo、Zi、Zf和Z),运算后输出t时刻输出值ht和t时刻单元状态值ct.

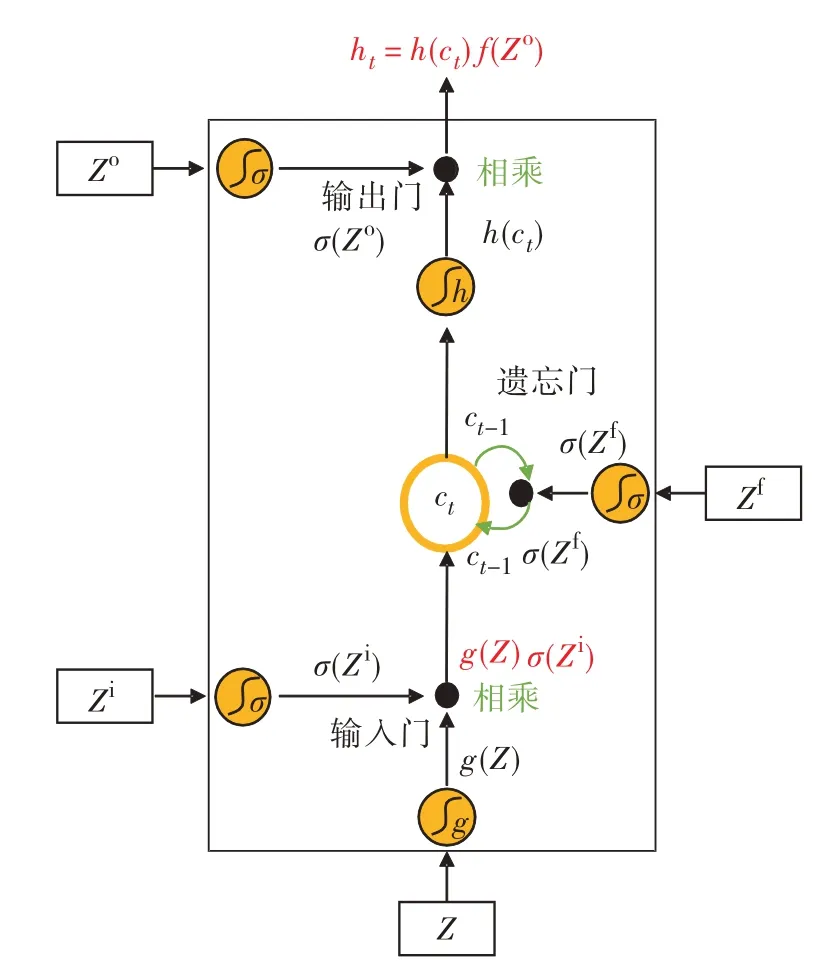
图3 单个LSTM神经元的运算Fig.3 The operation of single LSTM neuron.
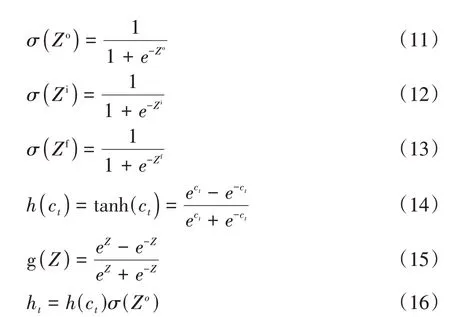
其中,下标f、i 和o 分别为遗忘门、输入门和输出门;W是输入权值;U是循环权值;B为偏差.
2.3 双向长短期记忆单元
双向长短期记忆单元(bi-directional long shortterm memory,BiLSTM)网络网络是普通LSTM 网络的升级演化,提出双向架构是为了利用过去和未来时间窗所有可用信息来训练网络.模型可从输入到输出、从输出到输入进行双向训练[17],优化目标函数[18].通过双向架构,两个或多个LSTM 层可以在两个方向进行堆叠,以实现最佳序列学习.
2.4 均方根传播优化算法
本研究神经网络优化器采用均方根传播(root mean square propagation,RMSProp)优化器.均方根传播是一种自适应学习率方法.RMSProp将动量思想引入梯度的累加计算中,使用指数衰减平均以丢弃遥远过去的历史,使其能够在找到凸碗装结构后快速收敛[19],抑制梯度的锯齿下降.在RMSProp算法中,对每个参数单独迭代,每次迭代根据式(17)至式(19)完成.

其中,gt为t时刻沿着ωj方向的梯度值;ϑt为t时刻梯度的平方的指数平均值;ϑt-1为t-1 时刻梯度的平方的指数平均值;ρ为衰减速率.

其中,η为全局学习率;ωt为t时刻参数;∊为小常数,用于除数过小时的数值稳定.

3 模型应用实例
3.1 建立致密低渗油藏压裂注气/衰竭开发数据库
机器学习被用于预测石油产量,过去的许多研究仅使用节流阀压力和气油比等工程参数,没有考虑与生产油藏地质有关的参数,如ALIYUDA 等[20]基于随机森林算法实证研究了地质参数对油田动态的重要影响.本研究通过正交试验设计(orthogonal experimental design,DOE)法,涉及地质、裂缝和生产等参数变量,设计473 套压裂注气/衰竭开发方案,试验变量及其取值范围如表2.其中,注气模型因所涉及的地质和流体条件变化范围大,使用单一正交试验设计表匹配的生产制度并不适用(如注气量Q过大等).为符合实际生产,调试不同范围地质、流体条件变化数模中生产制度,采用多个正交试验设计表进行方案设计.

表2 试验变量及其取值范围Table 2 Test variables and the corresponding value range
根据试验方案中的a、b、n和L取值,以L、水平井长度、最大裂缝半长和裂缝等间隔分布等作为限制条件,自动寻找a的近似值,并生成水平井水力裂缝位置和半长,建立对应油藏裂缝模型.自动参数生成与建模程序流程如图4.
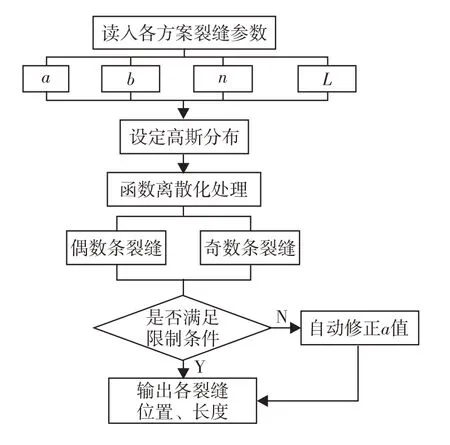
图4 水平井水力裂缝构建流程Fig.4 Programming flow chart of horizontal well hydraulic fracture construction.
基于Python编程建立值模拟模型并提取处理数据,最终建立致密低渗双孔双渗油藏压裂注气和衰竭开发数据库.
3.2 基于随机森林的参数特征选择
油田生产由一系列相互作用的地质、流体、生产参数控制,所有参数重要性可用数字来描述和估计,用于确定包括建立日产油(field oil production rate,FOPR)、地层压力(field pressure,FPR)和采出程度(field oil extraction,FOE)的油藏整体性能.随机森林是一种通过袋外数据进行评估揭示所有输入变量对预测贡献的算法,该方法简单且计算成本小.为防止样本数据量小产生过拟合风险,如图6,应用随机森林算法[21]分别选取各预测代理模型重要性占比>2%的特征作为下一步训练的输入参数.选取各预测代理模型特征参数如下:FOPR 代理模型特征参数包括生产时间t、Q、Cf、km、a、P和kfi;FPR 代理模型特征参数包括t、Cf、P、a和km;FOE 代理模型特征参数包括t、P、Cf、km、Q、a、kfn和L.由图6可见,FOPR、FPR和FOE整体变化趋势受时间因素影响较大,而地质、生产和裂缝等参数对压裂气驱效果初始状态影响较大.
3.3 深度学习预测模型建立
预测代理模型可以根据历史数据预测未知,准确地复制油藏模拟器的行为.通过BP 神经网络、LSTM 和BiLSTM 算法分别训练3 种预测代理模型.为避免偶然性,调用程序自动将注气和衰竭开发模型数据打乱混合,划分训练集(90%)和测试集(10%),利用训练集分别训练FOPR、FPR 和FOE预测代理模型,在测试集上进行盲测.采用的评价标准有均方根误差(root mean square error,RMSE)、平均绝对误差(mean absolute error,MAE)和决定系数(coefficient of determination,R2),如式(20)至式(22).
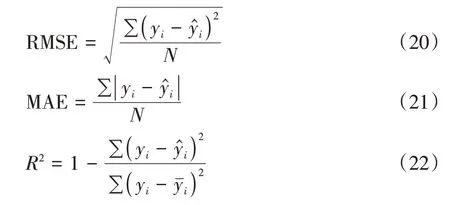
其中,y为真实值;为预测值;为真实值的平均值;N为测试样本数;i=1,2,…,N.
预测代理模型拟合结果如表3,真实值预测值对比如图6.
由表3 可知,较FOPR 和FPR 预测代理模型,BP 神经网 络、LSTM 和BiLSTM 算法在FOE 预测代理模型上的表现最优.同一预测代理模型中,各算法的预测表现为BiLSTM >LSTM >BP.其中,BiLSTM和LSTM的预测表现十分接近,较BP神经网络效果好很多,说明LSTM 门结构特点更适合解决时间序列相关问题,也验证了图5中时间重要性占比显著的结论,而BiLSTM 网络是普通LSTM 网络的升级演化,模型从输入到输出、从输出到输入进行双向训练,能发掘隐藏信息,使其较传统LSTM 可以更好预测复杂油藏条件压裂气驱产能随时间变化规律.
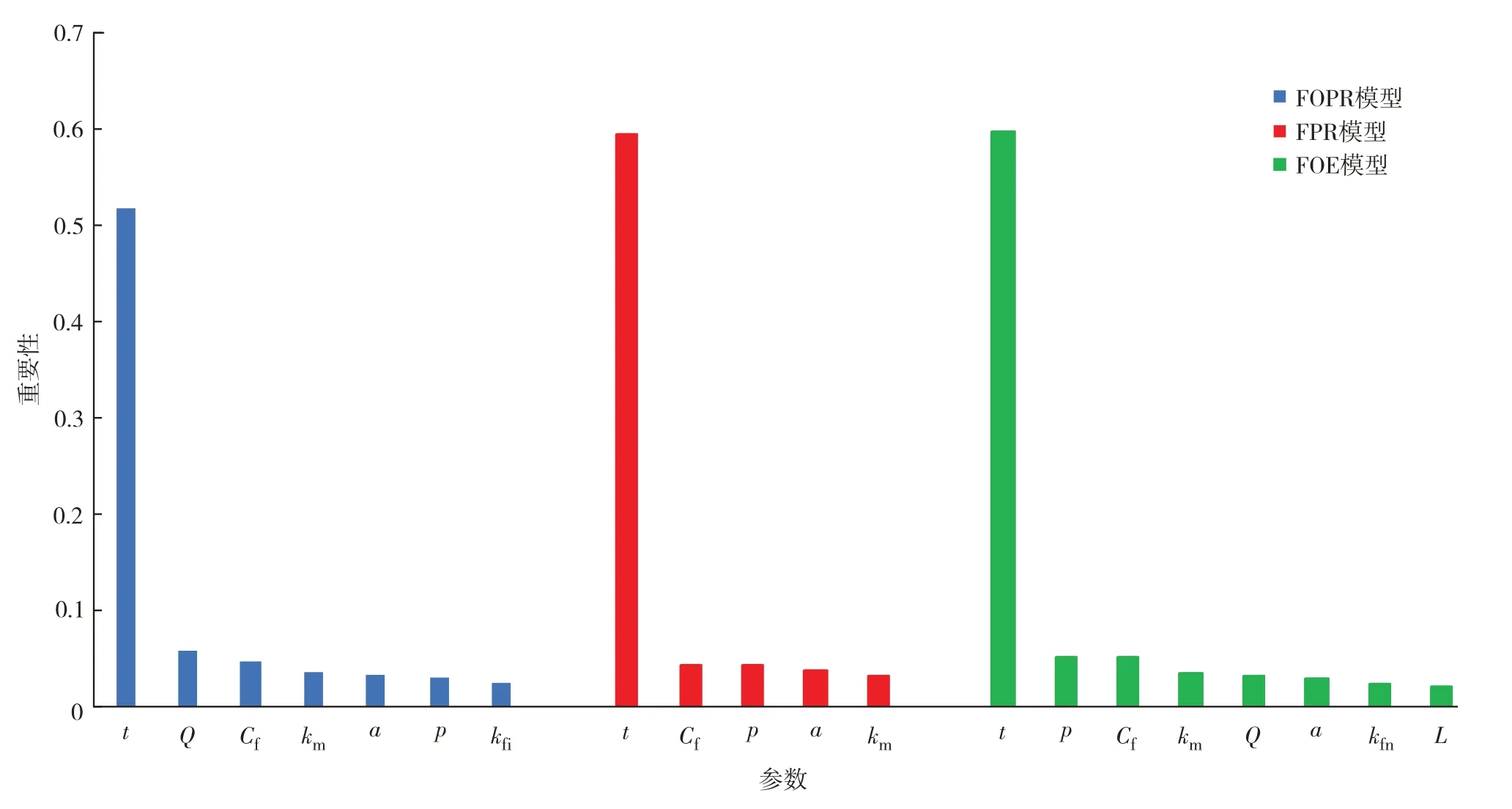
图5 FOPR、FPR和FOE 三种预测模型特征重要性暴风图Fig.5 Characteristic importance storm chart prediction models of FOPR(blue column),FPR(red column),and FOE(green column).
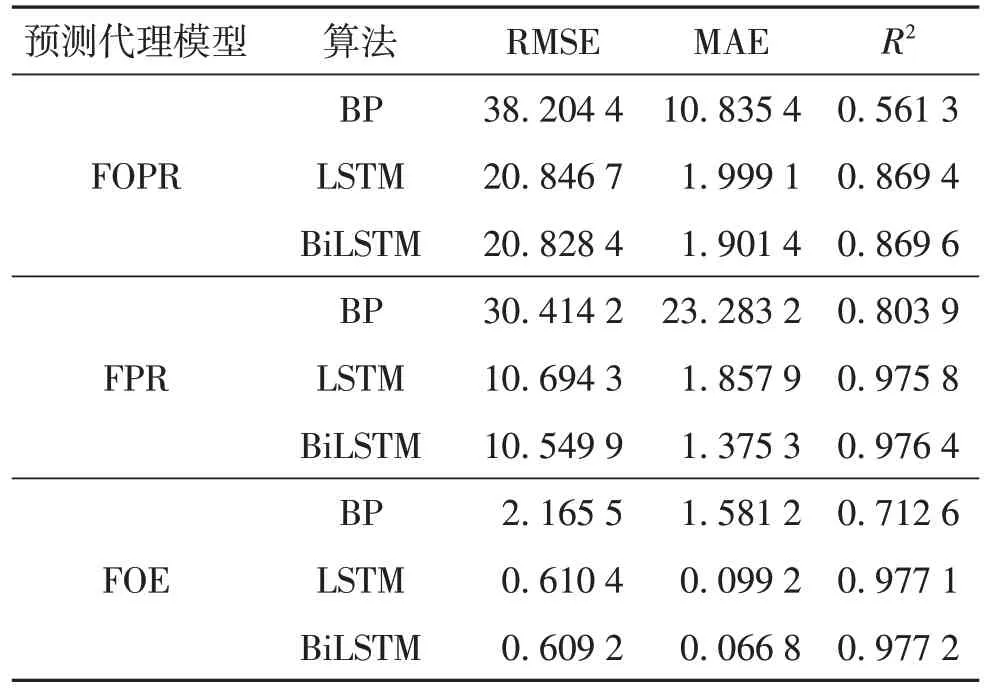
表3 预测代理模型拟合结果Table 3 The fitting results of pridicted proxy models
图6 为基于BiLSTM 算法的多个预测模型真实值预测值的对比.由图6 可知,代理模型真实值与预测值的差异程度依次为FOPR >FPR >FOE,这与各预测代理模型数据分布范围有密切关系,FOPR 预测代理模型的数据分布范围最广,FPR 次之,FOE预测代理模型的数据分布范围最小.
结语
基于RMSProp 的BiLSTM 算法提出预测代理模型,可准确高效地模拟预测致密低渗油藏压裂井网气驱效果.与油藏数值模拟结果对比,FOE预测代理模型准确度更高.不同预测代理模型准确性表现次序为BiLSTM >LSTM >BP,其中,BiLSTM 和LSTM 预测表现接近.综合分析,BiLSTM 算法预测致密低渗油藏压裂井网气驱、衰竭开发效果最好.本研究基于深度学习算法所建立的压裂气驱效果预测代理模型,为指导致密低渗油藏高效生产提供借鉴.
