嵌入注意力机制的轻量级钢筋检测网络
2022-09-25李姚舜刘黎志
李姚舜,刘黎志
(智能机器人湖北省重点实验室(武汉工程大学),武汉 430205)
0 引言
随着大数据和人工智能(Artificial Intelligence,AI)技术的广泛应用,社会各领域均向着智慧化方向发展,例如“智慧城市”“智慧图书馆”“智慧工地”等[1],其中的理念就是将现有的机器人、大数据、人工智能等高新技术植入到工业设备中。
目标检测是一种常见的工业场景分析模块,随着卷积神经网络(Convolutional Neural Network,CNN)的发展,基于深度学习的目标检测技术被广泛研究。近年来,基于锚点(Anchor)框的Anchor-Based 检测器已成为目标检测的主流。一些基于RPN(Region Proposal Network)的二阶段目标检测框架,如RCNN(Region-CNN)[2]、Fast R-CNN(Fast Region-CNN)[3]、Faster R-CNN(Faster Region-CNN)[4]和Mask RCNN(Mask Region-CNN)[5]不断更新目标检测的最高精度,但这些方法必须依赖强大的GPU 算力。随后出现了SSD(Single Shot MultiBox Detector)[6]、DSSD(Deconvolutional Single Shot Detector)[7]、YOLO(You Only Look Once)系列[8-11]、RetinaNet[12]等一阶段的模型,由于其检测速度可以同时满足静态图片及实时视频需要,在业界应用十分广泛。尽管如此,它们仍然需要大量的计算开销和运行内存来保持良好的检测性能。
随着FPN(Feature Pyramid Network)[13]和Focal Loss[12]的提出,学术界的注意力转向到Anchor-Free 的检测方法。Anchor-Free 检测器取消了Anchor 框的设置,将目标检测看作对象关键点的预测。通常包括两种检测方法:一种是首先定位几个预定义的或自学习的关键点,然后绑定对象的空间范围,这种检测器称为基于关键点的检测方法[14-16];另一种使用对象的中心点或区域来定义目标范围,然后预测中心点到对象边界的4 个距离,这种检测器称为基于中心点的检测方法[17-18]。Anchor-Free 检测器消除了与Anchor 相关的超参数,简化了编码过程,通过一定的训练可以取得与Anchor-Based 检测器相似的性能,在泛化能力方面更具潜力;但是Anchor-Free 检测器训练时间长、训练过程不稳定,并且在检测精度上仍然有一定的瓶颈,无法较好地应用在生产和实践过程中。
虽然神经网络模型在各领域都取得了不错的进展,但是人们发现其在实践中经常有难以预测的错误,这对于要求可靠性较高的系统很危险[19],因此引起了对神经网络可解释性的关注。Itti 等[20]提出了图像的显著性图,在此基础上发展而来的显著性目标检测,通过输出不同网络层的显著性图,可以看到神经网络关注的图像位置,从而解释了神经网络为什么能看到目标[21-22]。此外,注意力机制(Attention Mechanism)也可提高神经网络的可解释性,近几年来在图像、自然语言处理等领域中,注意力机制都取得了重要的突破,有益于提高模型的性能。Hu 等[23]提出的SENet(Squeezeand-Excitation Network)成功地将注意力机制应用到了计算机视觉领域,赢得了最后一届ImageNet 2017 竞赛分类任务的冠军。Li 等[24]将软注意力机制融合进网络提出了SKNet(Selective Kernel Network),使网络可以获取不同感受野的信息,提高了网络的泛化能力。在后续的研究过程中,Woo等[25]提出了一种轻量的注意力模块CBAM(Convolutional Block Attention Module),该模块在通道和空间维度上进行注意力权重推测,相比SENet 只关注通道的注意力机制可以取得更好的效果。Vaswani 等[26]在2017 年首次提出了基于自注意力的Transformer 模型,使用编码器和解码器的堆叠自注意层和点向全连接层,并使用注意力替换了原来Seq2Seq 模型中的循环结构,避免了重复和卷积。Parmar 等[27]把Transformer 模型推广到具有易于处理的似然性的图像生成序列建模公式中,最先使用完整的Transformer 做图像生成的工作。Dosovitskiy 等[28]提出了ViT(Vision Transformer),将纯Transformer 模型直接应用于图像输入,验证了基于Transformer 的体系结构可以在基准分类任务上取得有竞争力的结果。Carion 等[29]提出了一种用于目标检测的DETR(DEtection TRansformer)模型,将目标检测任务视为一种图像到集合的问题。给定一张图像,模型必须预测所有目标的无序集合,每个目标基于类别表示,并且周围各有一个紧密的边界框。在定位图像中的目标以及提取特征时,相比传统的计算机视觉模型,DETR 使用更为简单的神经网络,提供了一个真正的端到端深度学习解决方案。与DETR 范式不同,Beal 等[30]将ViT 与RPN 进行结合,即将CNN 主干替换为Transformer,组成 ViT-FRCNN(Vision Transformer-Faster Region-CNN),用于处理复杂的视觉任务(例如目标检测)。上述基于注意力机制的目标检测框架,虽然达到了一定的检测效果,但在检测小目标和检测精度上与其他的CNN 框架还有一定的差距,框架中包含的全连接结构使网络结构的参数量大幅增加,不仅增加了训练难度,同时还大幅降低了检测速度,因此暂时无法部署到实际生产过程中。
在智慧工地的应用中,有一项必不可少的工作就是钢筋数量检测,由于钢筋本身价格较昂贵,且在实际使用中数量很多,误检和漏检都需要人工在大量的标记点中找出,所以对检测精度要求非常高,目前的钢筋检测仍为人工盘点。文献[31-32]中提出可利用传统的图像处理技术,对输入图像进行预处理,并结合面积、形态等因素进行匹配计数,但在密集或有遮挡的情况下效果表现不佳。为进一步提高钢筋计数效率和精度,文献[33-34]中提出利用神经网络算法开展钢筋识别研究,在检测效率上显著提高,但是精度稍显劣势。Zhu 等[35]提出了一 种SWDA(Strong-Weak Distribution Alignment)的数据增强方法,首先将每根钢筋的位置进行裁剪,然后输入全卷积网络(Fully Convolutional Network,FCN)模型以获得语义掩码,最后利用3 个FCN 模型对钢筋端面进行高质量的语义分割和组合,虽然取得了较好的准确率,但这种多阶段的网络设计模型较大,且要求输入的图片清晰度较高,因此,如何在不降低检测精度的前提下来减少网络的参数和模型大小成为一个亟待解决的问题。
文 献[36]中指出利用残差网络(Residual Network,ResNet)可以有效解决神经网络的梯度弥散、爆炸以及网络退化的问题,使得输入的信息能够在网络中传播得更远,也可以提升网络的性能。由于深层网络的感受野比较大,语义信息表征能力强,但是特征图的分辨率低,几何信息的表征能力弱;低层网络的感受野比较小,几何细节信息表征能力强,虽然分辨率高,但是语义信息表征能力弱。使用金字塔池化可以融合高低层特征,使得网络最终的语义信息特征和空间信息特征都比较好[37]。在YOLOv3 基础上,本文结合ResNet、FPN、注意力机制重新设计了一种嵌入注意力机制的轻量级钢筋检测网络RebarNet。与其他钢筋检测网络相比,它具有更小的模型尺寸、更少的可训练参数、更快的推理速度,并且没有降低检测精度。
1 YOLOv3模型
在YOLOv3 网络中,32 倍下采样的13×13 尺寸的特征图具有大的感受野,适合检测大目标的物体;16 倍下采样的26×26 尺寸的特征图适合检测中等大小目标的物体;8 倍下采样的52×52 尺寸的特征图具有较小的感受野,适合检测小目标[10]。YOLOv3 模型采用Darknet-53 作为骨干网络,极大地提高了算法的稳定性及目标检测的准确率,其结构细节如图1 所示。
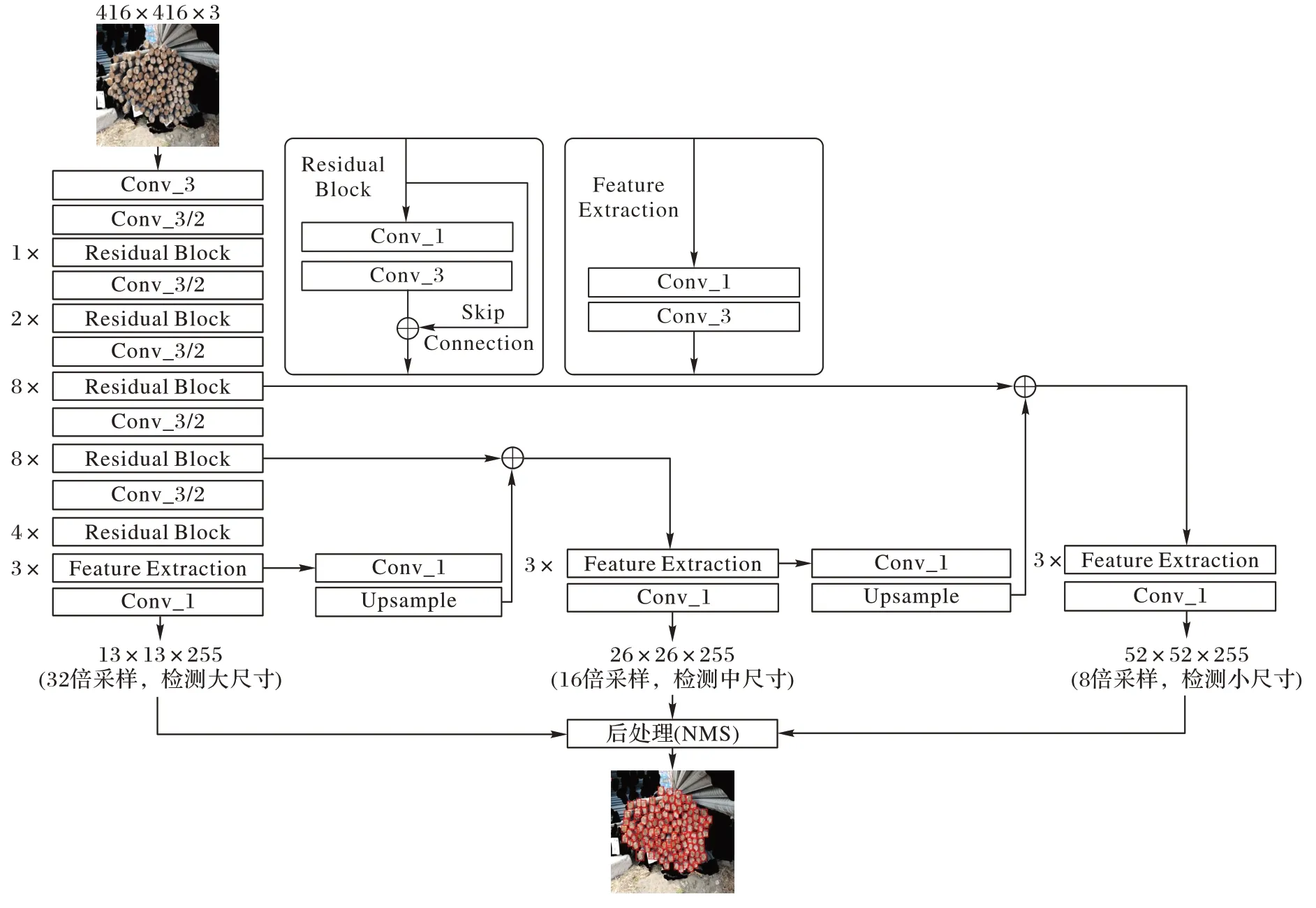
图1 Darknet-53结构Fig.1 Structure of Darknet-53
YOLOv3 将目标检测看做目标中心点、目标宽高的预测,并设置Anchor 先验框。YOLOv3 模型对于特征图上每个点共预测5 个数值:该点右下角存在目标中心的概率p、目标中心相对于当前特征点的横坐标偏移量cx、纵坐标偏移量cy、目标宽高相对于Anchor 框宽高的比例系数tx、ty。预测过程如图2 所示。

图2 特征图预测过程示意图Fig.2 Schematic diagram of feature map prediction process
图2 中黑线框表示预测框,w、h表示预测框的宽高,设Anchor 先验框的宽高为Awidth、Aheight,比例系数tx、ty与w、h之间的转换参见式(1)、(2):

2 RebarNet
2.1 可行性分析
为了能够检测不同尺寸、方向的物体,帮助模型快速收敛,YOLOv3 在COCO 数据集上利用K-Means 聚类,为每个检测通道设置了3个Anchor先验框(仅包含宽高),如表1所示。
利用Python语言对训练集图片中的钢筋宽高进行统计,所有宽高均归一化至416×416大小,对应的散点图如图3所示。
根据图3 所示,钢筋宽度主要分布在10~40 像素,高度主要分布在10~50 像素,钢筋的宽高分布比较紧凑,出现异常的宽高值比较少。结合表1 的Anchor 先验框分析,钢筋的宽高主要分布在YOLOv3 的52×52 检测通道中,由此考虑是否可以仅利用YOLOv3 的52×52 检测通道对钢筋图像进行检测。为验证这一猜想,本文统计了训练集和验证集共250 幅图像在YOLOv3 检测过程中,共36 802 根钢筋真实(Ground True,GT)框的分布情况,其中,包含94.72%(34 859)的钢筋GT 分布在52×52 的检测小目标通道中,仅有5.28%(1 943)的GT 分布在26×26 的检测中等目标通道中,而在检测大目标的13×13 通道中没有GT 出现。可见13×13、26×26 的检测通道对于钢筋图像的检测几乎没有贡献,可以尝试仅保留52×52 的检测通道。

表1 YOLOv3设置Anchor框Tab.1 Anchors of YOLOv3

图3 钢筋宽高分布情况Fig.3 Distribution of width and height of rebar
为了验证52×52 的通道的检测效果,本文首先根据钢筋的不同数量级从小到大选取了6 张图片,如图4(a)所示;然后将图片依次输入训练完成的YOLOv3 网络中进行检测,并将52×52 检测通道的显著性图映射回原图;最后输出52×52检测通道的热力图(Heatmap),如图4(b)所示。

图4 不同钢筋检测网络52×52通道的HeatmapFig.4 Heatmap of 52×52 channel in different rebar detection networks
热力图中,颜色越亮的位置,表示该处的权重值越大,也就意味着网络更多地注意到了该位置,该处存在目标的可能性更大。分析图4(b)可以发现,YOLOv3 网络的52×52 检测通道的热力图所有亮度均一致,表示每一个像素点的权重分布相同,即网络认为钢筋背景和前景具有同样的重要性,可以推测网络仅仅是在盲目地搜索目标。
为进一步验证注意力机制在目标检测中的有效性,本文在YOLOv3 网络中加入CBAM 注意力模块[25]并重新训练模型。为了不影响Darknet-53 网络预训练参数的加载,仅在Darknet-53 网络的第一层和最后一层卷积中加入CBAM 模块。然后将图4(a)中的图片依次输入网络中进行检测,最后再次输出52×52 检测通道的Heatmap,如图4(c)所示。
分析图4(c),加入CBAM 注意力模块之后,52×52 检测通道的权重分布比之前更加集中于钢筋中心点的位置,由此说明加入注意力模块之后,网络更加能注意到钢筋目标的位置,而并不是盲目地搜索。但是图4(c)中的网络也仅仅更多地注意到了小部分钢筋目标,仍然有大多数的钢筋目标被忽略,说明该通道的权重分布仍然有提升的空间。据此可以推测,如果能够设计更优的网络结构,进一步调整网络在检测钢筋图像时的权重分布,使得权重更多地集中于钢筋目标的位置,就能够提升52×52 通道的检测效果。
基于上述实验的结果,本文结合ResNet[36]、FPN[13]和注意力机制[23-25]设计了一个嵌入注意力机制的轻量级钢筋检测网络RebarNet。
2.2 骨干网络
为了简化模型的大小而不显著降低模型的检测精度,本文利用残差块ResidualBlock 作为网络的基本单元。
ResidualBlock 组成如下:首先利用BasicBlock_1 和BasicBlock_2 作为特征提取模块,其中BasicBlock_2 包含一个步长为2 的卷积操作,用于对特征图进行2 倍下采样;然后利用1×1 大小、步长为2 的卷积对BasicBlock_1 输出的特征图进行2 倍下采样,将输出的特征图与BasicBlock_2 输出的特征图进行残差跳连,以延长网络记忆特征的距离;然后利用1×1、3×3 的卷积对前述特征图进行特征提取;最后在末尾添加通道注意力(Channel Attention,CA)和空间注意力(Spatial Attention,SA)模块[25],调整特征图分配权重。
ResidualBlock 会对输入特征图进行2 倍下采样处理。YOLOv3 网络中52×52 尺寸的检测通道,是对输入特征图进行8 倍下采样后的结果。2.1 节的分析表明,仍有少量的GT框分布于26×26 尺寸的检测通道中,因此本文在骨干网络的设计过程中,包含了4 个ResidualBlock 模块,即对输入特征图进行24=16 倍下采样,避免了26×26 通道中的信息丢失。前一个ResidualBlock 输出的特征图经过1×1 大小、步长为2的卷积进行2 倍下采样处理后,与后一个ResidualBlock 输出的特征图进行残差跳连,从而延长ResidualBlock 模块记忆特征的距离。整个骨干网络共包含3 次模块间跳连过程。
为了使最终输出的52×52 检测通道的特征图包含26×26检测通道的信息,此处将16 倍下采样后的26×26 尺寸的特征图进行2 倍上采样(Upsample)处理,得到52×52 尺寸的特征图,与8 倍下采样后得到的52×52 尺寸的特征图进行特征金字塔融合,以增大网络的感受野,最后输出52×52 尺寸的特征图。将得到的特征图再次利用1×1、3×3 的卷积进行特征提取,并对输出的特征图添加通道注意力和空间注意力模块[23],调整特征图分配权重,最后输出52×52 尺寸的特征图用于检测钢筋。骨干网络的结构如图5 所示。
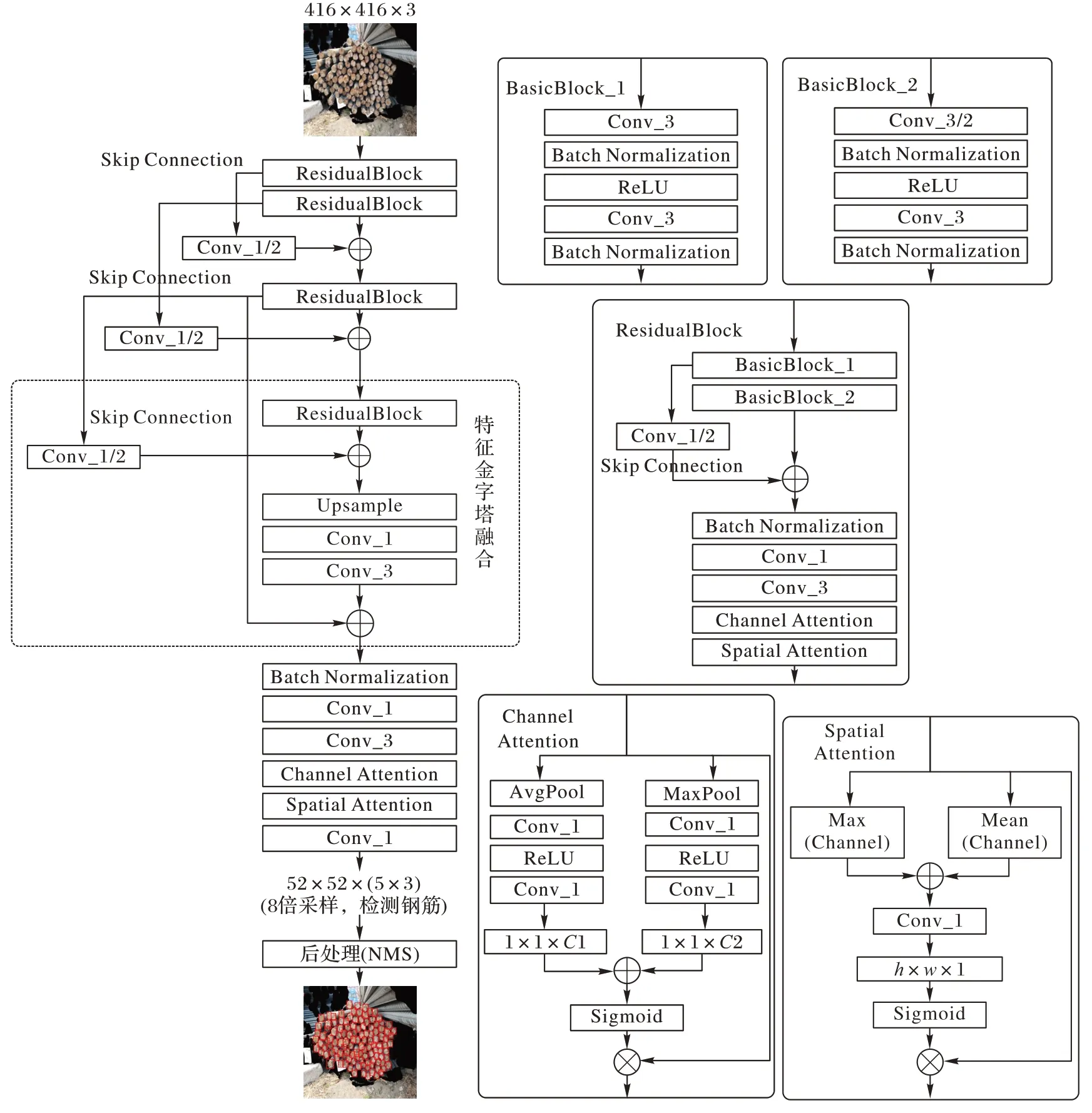
图5 本文模型的骨干网络结构Fig.5 Backbone structure of the proposed model
利用本文网络重新训练钢筋数据集至模型拟合,输出52×52 检测通道的热力图如图4(d)所示。
分析图4(d)可以发现,本文网络更多地聚焦到了钢筋中心点所在的位置,抑制了无关的背景特征,可见网络提取钢筋特征的能力增强。结合图4、5 进行分析,本文网络相比添加了CBAM 模块后的Darknet-53 网络更能关注到图像中钢筋的位置,是否可以推测本文网络检测钢筋的性能得到了一定的提升,后续3.3 节将验证此推论。
每个特征点对应3 个Anchor 先验框,因此骨干网络输出大小为52×52×(5×3),每个特征点输出3 个预测框。后处理部分首先对输出的52×52×3=8112 个预测框进行置信度筛选,然后对筛选出来的预测框进行非极大值抑制(Non-Maximum Suppression,NMS)[37]处理,删去重复的预测框,最后将预测框映射回原图进行输出。
RebarNet 网络检测钢筋的流程如图6 所示。
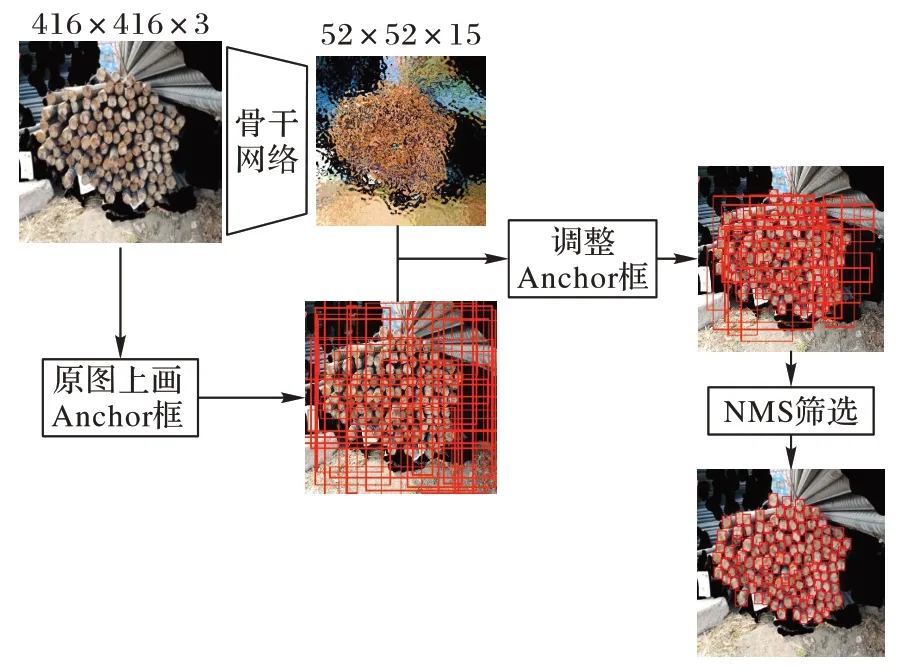
图6 RebarNet网络检测钢筋流程Fig.6 Flowchart of rebar detection by RebarNet network
本文选取了EfficientDet(Scalable and Efficient Object Detection)[38]、SSD(Single Shot MultiBox Detector)[6]、CenterNet[18]、RetinaNet[12]、Faster RCNN(Faster Region-CNN)[4]、YOLOv3[10]、YOLOv4[11]、YOLOv5m(YOLOv5s 模型的检测精度偏低,适合检测大物体;YOLOv5l模型和YOLOv5x模型的参数量过大,钢筋检测的速度不理想,因此本文选取了YOLOv5m 做对比实验)等8个经典的目标检测网络与本文网络做对比。各模型的参数量、训练占用显存以及训练模型权重比较如表2所示。

表2 模型参数量对比Tab.2 Comparison of model parameters
分析表2 可知,本文提出的网络包含的参数量最少,较YOLOv3、YOLOv4 模型减少了约95%,较YOLOv5m 模型减少了84%,参数量的大幅减少,使得训练模型训练所占用的GPU 显存也大幅减少。模型参数减少意味着训练过程所需时间同样会减少,后续的3.2 节的实验将证实此推论。
2.3 损失函数
本文网络的损失函数由两个部分组成:一部分是预测框位置与真实框位置带来的误差损失LOSSLocation;另一部分是目标置信度带来的交叉熵损失LOSSClassification。
LOSSLocation包括:预测框中心点(x,y)相对于特征图上对应位置的 偏移量损 失,采用二元交叉熵(BinaryCrossEntropyLoss,BCELoss)进行计算;预测框宽高相对于Anchor 先验框的比例损失,采用MSE(Mean Square Error)均方误差进行计算。LOSSLocation参见式(3)。
LOSSClassification包括:预测框正样本相对于GT 的置信度损失,采用BCELoss 进行计算;预测框负样本相对于GT 的置信度损失,此处考虑到训练集中负样本中的难易检测样本不平衡,采用Focal Loss[12]计算损失,对其中的易分负样本进行惩罚。LOSSClassification参见式(4)。

2.4 模型评价指标
衡量模型的性能指标为:TrainTime、FPS(Frames Per Second)、mAP(mean Average Precision)及 Accuracy。TrainTime 为训练1 个epoch 的平均时间,FPS 为模型每秒可连续检测图片的数量,用来评价模型的检测速度。下面重点分析mAP 及Accuracy 这两个评价指标。
2.4.1 mAP
mAP 是用于目标检测模型的性能评价指标,通过计算Precision-Recall 曲线下的面积,得到每个类别的AP(Average Precision)值,所有类别的AP求均值便得到mAP,mAP计算参见式(5):

其中n为训练集中类别的个数,由于钢筋检测中n=1,即mAP=AP。
交并比(Intersection Over Union,IOU)是度量预测框与GT 的重叠程度的指标,用于衡量边界框是否正确标识了目标在图像中的位置,其计算参见式(6):

其中:Bp表示预测框,Bgt表示真实框。一般认为若IOU>0.5,则表示预测框正确标识了目标在图像中的位置。
图像目标检测任务的Precision(P)的计算参见式(7);Recall(R)的计算参见式(8):

TP(True Positive)表示Bp与Bgt的IOU>0.5 的Bp的数量,每个Bgt只计算一次;FP(False Positive)表示表示Bp与Bgt的IOU<0.5 的Bp的数量,或者检测到同一个Bgt多余的数量;FN(False Negative)表示没有检测到的Bgt的数量。将训练得到的网络模型用于预测验证集Val,对大于置信度阈值0.5 的Bp经过NMS算法[26]处理后,将得到的有效预测框集合BVal按置信度进行排序。对集合BVal中的每一个Bp确定其是TP还是FP,然后根据Pascal Voc2010的规定的算法计算AP。
2.4.2 Accuracy
钢筋点数问题的关键在于点数是否准确,即识别出的钢筋数量和实际数量的差距,本文设置了Accuracy(A)评价指标,对钢筋检测的准确性进行评价,计算参见式(9):

其中:n为钢筋图像的数量,Ri为第i张图像中的钢筋的实际数量,PRi为第i张图像通过模型识别的数量,|Ri-PRi|为Ri与PRi计数差异的绝对值。
3 实验及分析
本文实验采用Pytorch 框架进行网络结构修改和量化的操作,操作系统为Windows 10,GPU 显存为6 GB。
3.1 实验数据集
本文数据集来自“智能盘点-钢筋数量AI 识别大赛(https://www.datafountain.cn/competitions/332/datasets),数据集划分及用途如表3 所示。

表3 数据集划分及用途Tab.3 Partition and usage of dataset
分析表3 可知,Train 数据集中仅有225 张图片,为提高模型的鲁棒性,本文采用翻转、旋转、缩放、裁剪等数据增强的方式在训练过程中扩充数据集。数据增强方式如图7所示。
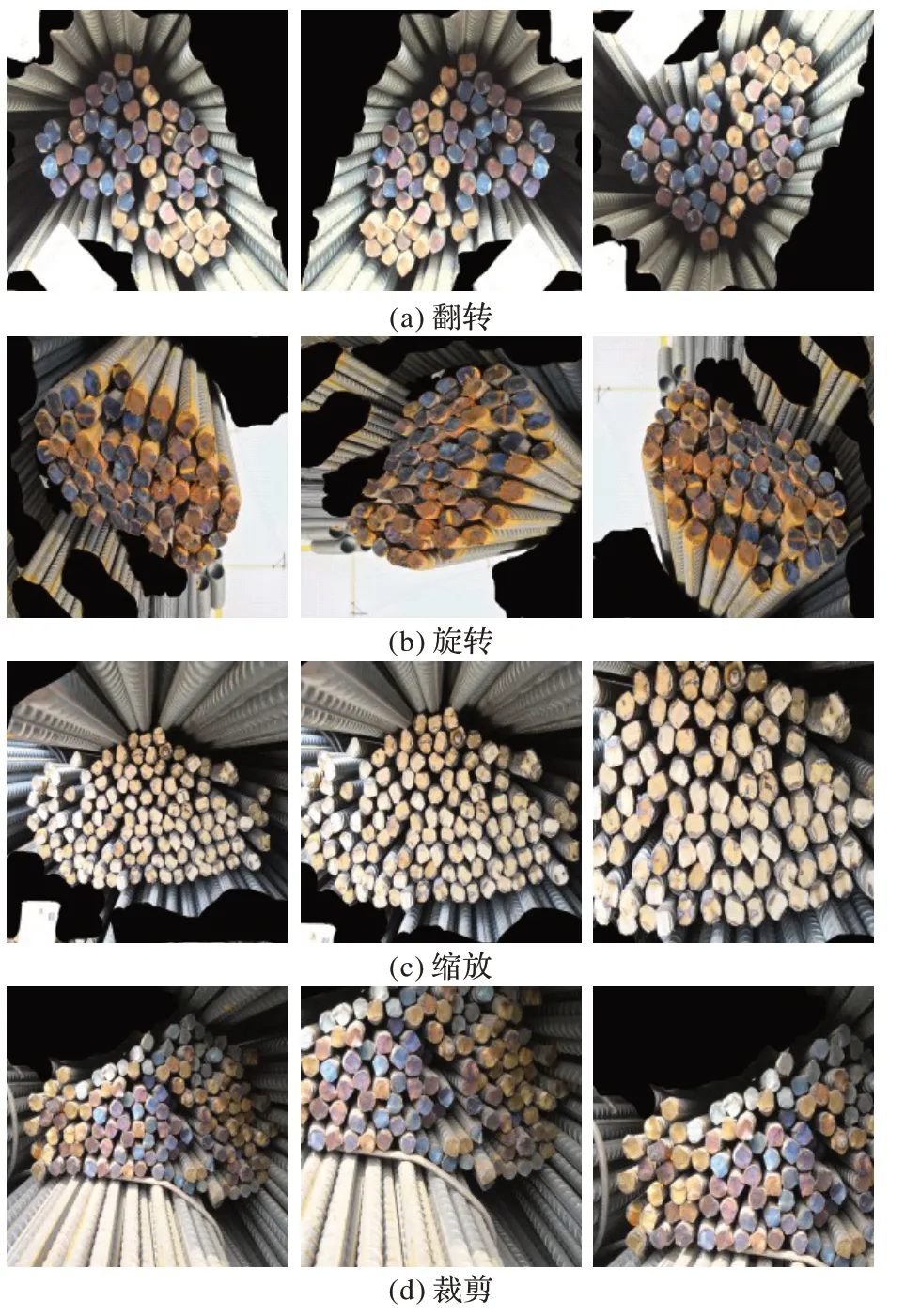
图7 数据增强Fig.7 Data augmentation
经过上述方式的随机数据增强后,训练集可扩充至原有大小的4~5 倍,可极大提高网络的健壮性。
3.2 评价结果
为了验证所提网络的有效性,本文基于Pytorch 框架实现各个目标检测网络,并将Train 数据集分别在各个网络上进行训练,训练过程中设置BatchSize=5,统计训练过程中的TrainTime指标。本文将不同网络训练得到的收敛模型用于Val 数据集、Test 数据集检测,统计检测过程中的mAP、Accuracy、FPS指标。统计结果如表4 所示。

表4 不同网络的评测指标Tab.4 Evaluation indexes of different networks
分析TrainTime结果可知,本文所提网络训练所需时间短于大多数网络,大致与CenterNet 网络相近,从而验证了2.2 节中网络训练时间缩短的推论。
从衡量网络整体性能的mAP值可以发现,EfficientDet、SSD、CenterNet、RetinaNet 和Faster RCNN 在钢筋检测过程中错误较多,mAP值处于0.7 以下;YOLOv3 表现良好,mAP达到了0.889;YOLOv4 相比YOLOv3提高了2.5 个百分点;YOLOv5m 模型的mAP值最高达到了0.931,而本文提出网络的mAP值虽然没有超过YOLOv5m,但与其仅相差0.4 个百分点,几乎达到了一致的检测效果。
进一步比较Accuracy指标可以发现,本文网络与YOLOv5m 的Accuracy指标表现最优,与mAP检测结果一致。此处结果说明了本文所提网络在检测效果上满足要求,同时验证了2.2 节中钢筋检测性能提升的推论。
分析FPS指标可知,本文提出的网络相比其他检测网络在钢筋检测速度上有极大提升。除了YOLOv5m 以外,其他模型的检测速度均在50 FPS 以下。虽然YOLOv5m 的mAP检测指标比本文网络略优0.4 个百分点,但是本文网络的检测速度达到了106.8 FPS,是YOLOv5m 检测速度的1.8 倍,对生产环境中的使用更加友好。
3.3 检测效果
为验证各网络在实际生产环境中的检测效果,本文在Test 数据集中按不同钢筋数量级选取了6 张图片,如图8(a)所示。本文将图8(a)中图片依次输入9 个检测网络中,输出检测后的结果如图8(b)~(j)所示,图片中用矩形框包围的部分表示网络检测出来的钢筋目标位置,图片左上角的数字为网络检测出的实际数量。
分析图8(b)~(j)可见,在钢筋数量、图片光线、角度不同的情况下,YOLOv3、YOLOv4、YOLOv5m、本文网络相比其他模型有更高的检测精度,更低的误检、漏检率,其中,YOLOv5m、本文网络的检测效果最优,两者相差不大,这里同时验证了3.2 节中对应网络的评价结果,并且进一步验证了本文所提网络在实际检测过程中的有效性。

图8 Test数据集上的钢筋实际检测效果Fig.8 Actual detection effect on Test dataset
4 结语
本文基于YOLOv3 模型,结合ResNet、FPN、注意力机制等技术,提出了一种嵌入注意力机制的轻量级钢筋检测网络RebarNet。实验结果表明,本文所提网络在不降低检测精度的前提下,训练速度更快、模型文件更小,极大提升了检测速度,对于智慧工地的钢筋检测应用有着推动的作用;但是该网络对于钢筋数量比较密集、光线不够明亮的图片,检测效果仍然存在一定的误差。下一步将对模型结构进行继续改进,进一步提高模型精度,使其能适应更多的环境,在生产实践中真正发挥作用。
