基于YOLOv5的雾霾天气下交通标志识别模型
2022-09-25尹靖涵瞿绍军姚泽楷胡玄烨秦晓雨华璞靖
尹靖涵,瞿绍军*,姚泽楷,胡玄烨,秦晓雨,华璞靖
(1.湖南师范大学信息科学与工程学院,长沙 410081;2.湖南师范大学湘江人工智能学院,长沙 410081)
0 引言
交通标志识别(Traffic Sign Recognition,TSR)作为智能交通系统(Intelligent Transportation System,ITS)中的关键一环,实现兼顾准确性和实时性的交通标志识别具有重要意义。交通标志中包含道路状况、驾驶环境、限速警告等重要语义信息,在智能车的路径规划、驾驶安全、车速调节等方面起到关键作用。随着无人驾驶汽车的增加、辅助驾驶技术的普及,雾霾、雨雪等恶劣天气对车载摄像头、传感器的干扰问题渐受关注,恶劣天气下的交通标志识别也成为一项重大挑战。
文献[1-2]中对受雾霾干扰的图像采用人工预设强特征提取,结合分类器实现标志识别;文献[3-6]中对受干扰图像亮度、对比度等属性进行增强,减弱恶劣天气干扰,改进深度学习算法检测标志;文献[7-9]中基于雾霾形成原理构造物理模型,将图像复原至人眼可观察状态,构造深度学习模型检测特征;文献[10-11]中将滤波网络与深度学习网络融合,构建端到端的标志识别系统。交通标志识别算法将任务分解为前端滤波(或强特征提取)和识别两个阶段,在恶劣天气下获得了良好的精度提升。滤波器指向性强,由于天气噪声类型不同,针对雾霾天气的滤波前端难以在雨雪或照明不良天气下保持算法优势,反之亦然。如何克服滤波器局限性,建立可同时应对多种恶劣天气的交通标志识别算法需深入研究。
文献[12-16]中对深度学习方法在目标检测的研究进展、代表性算法、常用数据集和性能评价指标进行了详细的探讨。陈飞等[17]对传统方法与深度学习方法在交通标志识别方面的研究现状、算法原理、算法性能进行了综述,将算法应用环境细分为雾霾、雨雪、复杂光照条件。基于深度学习的目标检测算法根据是否具有区域选取(Region Proposal,RP)分为双阶段目标检测算法和单阶段目标检测算法。双阶段目标检测算法先经过RP 生成推荐候选框,再进行类别、边界回归,对多目标识别精度高,但计算开销大、训练时间长,适用于云端、算力强设备,其代表有区域推荐卷积神经网络(Region Convolutional Neural Networks,RCNN)、高速区域推荐卷积神经网络(Fast Region Convolutional Neural Networks,Fast-RCNN)、超高速区域推荐卷积神经网络(Faster Region Convolutional Neural Networks,Faster-RCNN)。单阶段目标检测算法采用网格单元代替RP 约束检测框,对图像直接检测,算法速度快、可移植性好,但容易漏检、精度偏低,适用于移动终端以及嵌入式设备,其代表有YOLO(You Only Look Once)、SSD(Single Shot mutibox Detector)、
Retina-Net。廖璐明等[18]提出了融合空间变化网络与注意力机制构造规模小、参量少的交通标志识别系统;林雪等[19]提出了采用LAOSS 回归对VGG(Visual Geometry Group)模型剪枝,提高算法运行速度;江金洪等[20]在YOLOv3 网络中融合深度可分离卷积并改进算法损失函数,检测精度获得有效提升;Shen 等[21]提出了在特征金字塔中引入多尺度注意力机制以抑制背景特征干扰,改进后模型可兼容实现多种规模的交通标志识别;Xiao 等[22]提出了用ResNet101 替换成为YOLOv3 的主干网络,利用密集残差网络实现多层特征融合,解决小目标特征易丢失、难以识别的问题,改进后模型精度明显提升;Yao 等[23]提出了一种适用于交通标志识别的多尺度特征融合算法,在损失函数中引入高斯分布特征,将算法移植入Nvidia Jetson Tx2 平台验证其检测精度和实时性;陈名松等[24]提出了基于改进CapsNet 的交通标志识别模型,采用路由动态算法优化特征传递,标志位置、姿态信息被更好保留,模型收敛能力、识别精度都获得了提升;孙伟等[25]将卷积神经网络(Convolutional Neural Networks,CNN)多层特征池化联合成交通标志特征向量,极限学习机分类器输出向量最大值实现标志检测,克服了顶层特征局限性;王子键[26]改进了SSD 模型,根据距离因素自适应选择负样本,模型可更快向全局极值收敛,同时调整特征层数量、损失函数,平均精度均值(mean Average Precision,mAP)指标获得明显提升;Xu 等[27]提出了通过软教师网络实现端到端半监督目标检测,选择可靠的伪框进行回归学习;Zhang 等[28]提出了在不同网络分支上采用逐通道注意力机制,在不引入额外计算成本情况下,实现注意块直接用于检测任务;Li 等[29]提出削减LeNet-5 网络中的链接和计算,融合多层特征提高网络泛化能力;Tai 等[30]提出了在空间金字塔中融合尺度分析,实现对多尺度目标的同时学习;Zhou 等[31]提出了可并行融合注意模块的注意网络,并在德国交通标志数据集中验证其鲁棒性。残差结构、特征融合技术可以有效改善小目标特征消失的问题,损失函数、超参数调整等方法可辅助模型拟合。
本文基于YOLOv5 模型,削减双特征金字塔深度、限制最高下采样倍数、强化小目标特征、调整残差模块深度、抑制背景特征重复叠加,实验证明特征融合和残差模块的结合使用,给标志识别带来显著增益。本文同时在模型中融合K-means 先验框、全局非极大值抑制(Global Non-Maximum Suppression,GNMS)等有助于精度提升的机制。在模型评估指标方面,考虑到实际应用特殊性,将模型识别速度也作为一项重要指标。最后将不同模型在三种恶劣天气增强数据集中测试分析,并将其中的雾霾天气作为实验分析重点,均取得了明显的精确度提升,同时模型在输入较大高清图片时也能保持实时性。实验结果表明,本文改进模型解决了模型在不同环境下复用困难问题,具备较强的抗环境干扰能力以及通用性,在不同恶劣天气下均能保持识别精度。
1 基于YOLOv5的交通标志识别模型
1.1 YOLOv5模型框架
原始YOLOv5 模型框架如图1 所示,分为Backbone、Neck、Head 三大部分,模型规模由小到大有YOLOv5s、YOLOv5m、YOLOv5l 多个版本。
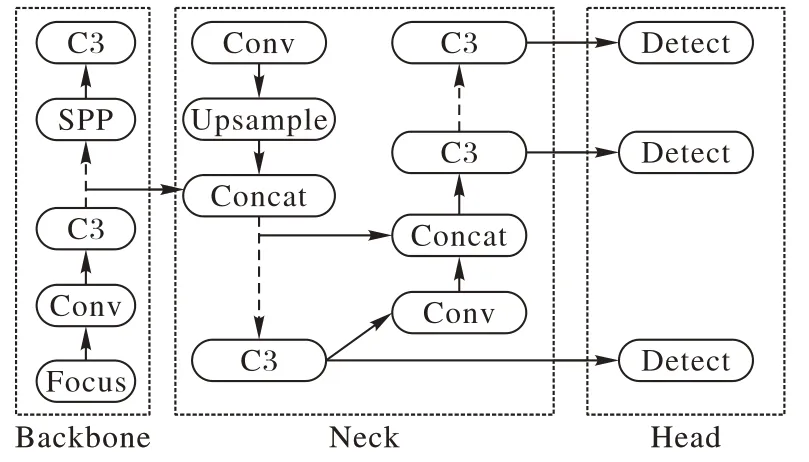
图1 YOLOv5模型框架Fig.1 Framework of YOLOv5 model
Backbone 是YOLOv5 的骨干结构,由Focus、Conv、C3、空间金字塔池化(Spatial Pyramid Pooling,SPP)等模块(如图2所示)组成。Focus 模块将输入在纵向和横向间隔切片再拼接,与卷积下采样相比,Focus 输出深度提升4 倍,保留更多的图像信息;Conv 为YOLOv5 的基本卷积单元,对输入依次进行二维卷积、正则化、激活操作;C3 由若干个Bottleneck 模块组成,Bottleneck 为一种经典残差结构,输入经过两层卷积层后与原始值进行Add 操作,在不增加输出深度的同时完成残差特征传递;SPP 为空间金字塔池化层,SPP 对输入执行三种不同尺寸的最大池化操作,并将输出结果进行Concat 拼接,输出深度与输入深度相同。
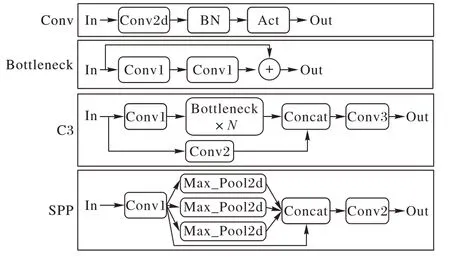
图2 YOLOv5主要模块结构Fig.2 Main module structures of YOLOv5
Neck 的核心为特征金字塔网络(Feature Pyramid Networks,FPN)和路径聚合网络(Path Aggregation Networks,PAN)结构。目标特征根据内容分为类别特征与位置特征,类别特征代表该目标属于前景或背景、属于哪一类别,位置特征代表该目标所处空间位置、边界大小信息。卷积网络中随着卷积次数增加,特征层级由低层向高层转变。低层特征接近图像本身视觉内容,低层特征内大目标的位置特征和小目标的类别、位置特征突出;高层特征更加抽象,人无法直接理解,高层特征内大目标的类别特征丰富。FPN 和PAN 结构实现高层特征与低层特征融合互补:FPN 结构将高层的大目标的类别特征向低层传递;PAN 结构将低层的大目标的位置特征和小目标的类别、位置特征向上传递,两者互补并克服各自局限性,强化模型特征提取能力。
Head 为YOLOv5 的检测结构,传统CNN 只将最高层特征输入检测层,网络存在一个普遍难题:小目标特征在多层传递后丢失导致难以识别。YOLOv5 将三种不同大小的特征输入Detect 模块,分别针对大、中、小体型的目标识别,克服顶端特征的局限性。
1.2 改进YOLOv5模型
1.2.1 特征金字塔结构改进
本文对标志占用像素大小进行统计,指导特征金字塔结构改进。由于交通标志外轮廓接近正方形,采用标志宽度和长度的均值向下取整后的结果来衡量该标志占用像素大小。统计结果显示长宽均值介于区间[2,32]的标志数量为14 039,介于区间[33,64]的标志数量为13 092,介于区间[65,395]的标志数量为6 867。
交通标志长宽均值集中在区间[2,64]内,识别任务以小目标为主。在FPN 和PAN 结构中,金字塔上层视野广,单个特征值覆盖像素区域大,大目标的特征显著,小目标被背景以及噪声淹没,原始特征金字塔结构不适用于交通标志识别任务。本文通过削减FPN 和PAN 结构(如图3,P/N代表进行N倍下采样),降低网络深度来解决小目标特征被淹没的问题。限制最高下采样倍数,输入Detect 层的为输入为原始特征经过4、8、16 倍下采样的结果,强化低层小目标特征。
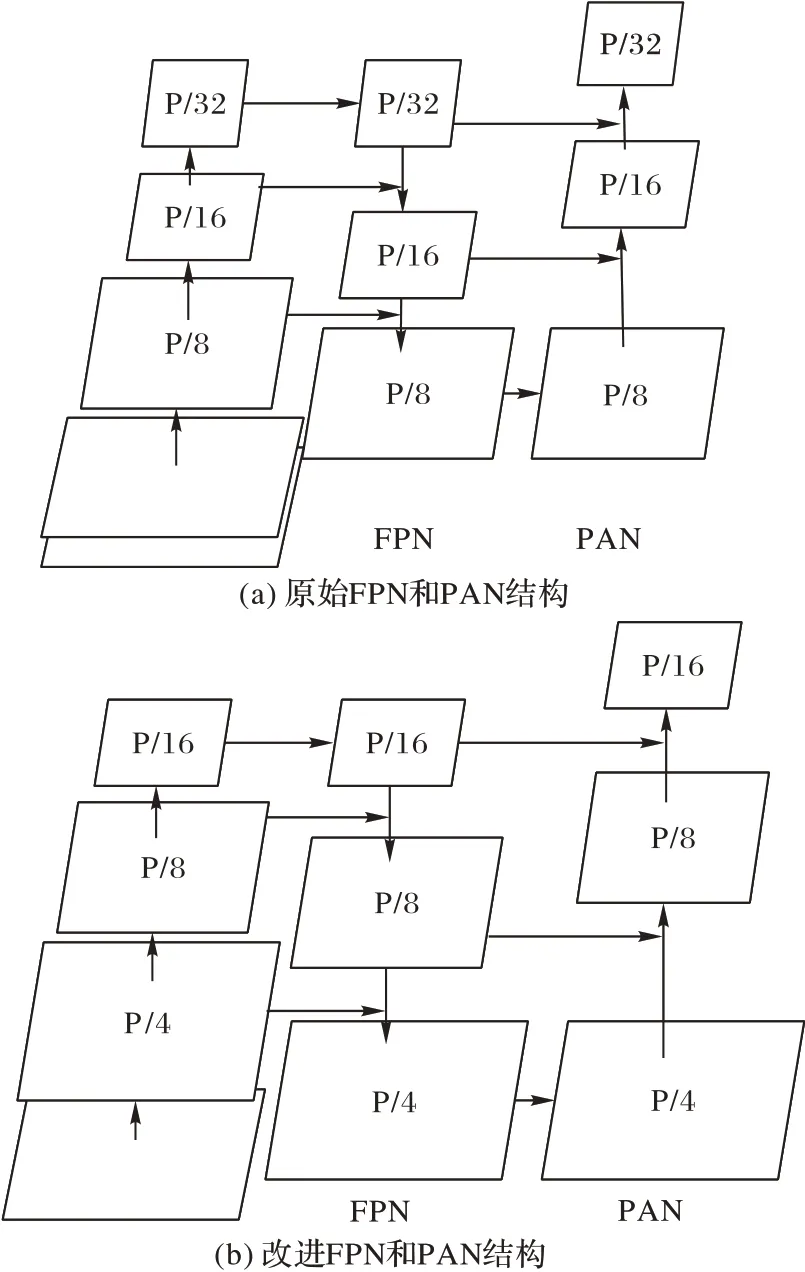
图3 FPN和PAN结构改进前后对比Fig.3 Comparison of FPN and PAN before and after structural improvement
1.2.2 上采样算法改进
PAN 需先对高层特征上采样后再向下传递,原始YOLOv5 模型采用最邻近插值法上采样,最邻近插值法的计算开销极小,但算法精度低,本文改进使用双线性插值法上采样,削弱离群点对特征传递造成的干扰。最邻近插值法和双线性插值法都基于后向映射原理,从目标特征映射到源特征,区别在于最邻近插值法在源特征中只取一个参考点,双线性插值法同时计算4 个参考点。若上采样后特征大小为n×n,则最邻近插值法时间复杂度为O(n2),双线性插值法时间复杂度为O(4n2),在580 张分辨率为2 048×2 048 的测试数据集中,采用最邻近插值法检测速率为58 FPS,采用双线性插值法检测速率为50 FPS,相对于精确性的提升,带来的额外计算开销可以接受。
1.2.3 适配残差模块深度
Bottleneck 为残差模块的核心,对特征的深度传递、抑制模型梯度消失都具有积极影响,但过于深入的残差模块容易造成无关背景多次叠加,计算开销增长,面对不同检测任务需重新适配残差模块深度。经过实验发现在Backbone 与Neck 结构中的残差模块里采用Bottleneck×1 的数量级可以兼顾识别精度和检测速度,改进后残差模块如图4 所示。

图4 改进后残差模块Fig.4 Improved residual module
1.2.4K-means聚类算法重获初始锚框
Head 结构为3 个Detect 模块预备不同固定宽高的初始锚框,初始锚框包含标志的先验知识,其选择将对网络的训练以及目标检测效果带来极大的影响,本文采用K-means 聚类算法重新获取初始锚框,聚类散点如图5 所示,其中K=9,改进后初始锚框为:

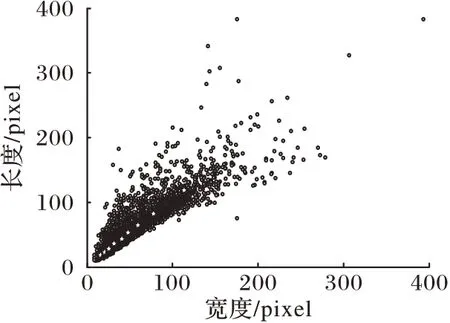
图5 聚类散点图Fig.5 Clustering scatter diagram
1.2.5 增加多尺度训练
小体型目标识别极容易受输入图像尺度影响,多尺度训练使网络在面对不同分辨率的输入图像时都能保持鲁棒性。本文在模型训练过程中将输入图像随机放缩至768×768 至1 120×1 120 区间,削弱检测精度受输入图像尺度影响。
1.2.6 获得最佳归一化尺寸
图像在被输入模型前都需被归一化至img-size×img-size(pixel×pixel),img-size为预设归一化尺寸。提高img-size有助于识别精度提升,但增加计算负担,导致检测速率下降,通过图6 可衡量img-size增大为网络带来的精度提升和检测速度下降之间的变化关系。通过观察曲线发现,在img-size大于960 时,精度基本保持稳定,FPS 明显下降。本文采用imgsize=960,网络可在保持高精确度的同时维持稳定检测速度。
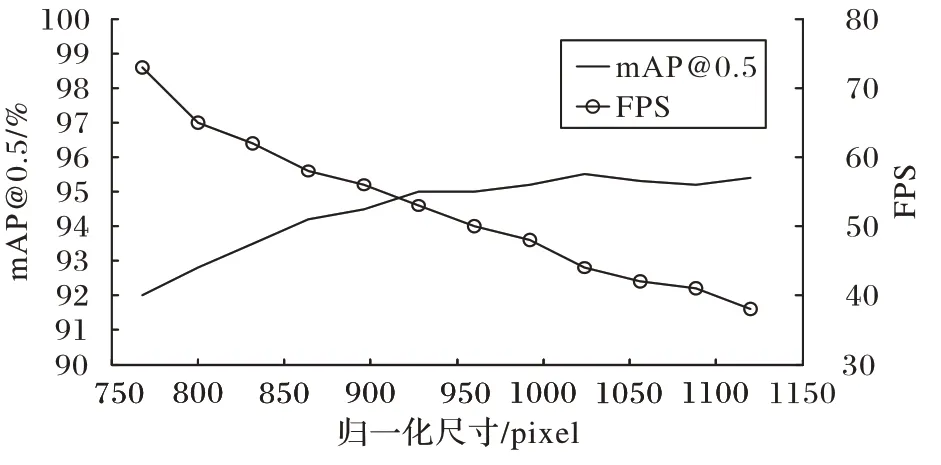
图6 mAP@0.5和FPS随归一化尺寸变化曲线Fig.6 Curve of mAP@0.5 and FPS varying with img-size
1.2.7 全局非极大值抑制
由于交通标志在空间位置上具有特殊性,亦即不存在交通标志之间发生重叠、遮挡的现象,本文对此改进使用全局非极大值抑制(GNMS),所有类别同时参与非极大值抑制(Non-Maximum Suppression,NMS),并降低交并比(Intersection Over Union,IOU)阈值。实验证明GNMS 可有效滤除置信度较低的检测结果。
1.2.8 提前终止训练
实验发现原始YOLOv5 模型都出现了不同程度的过拟合,YOLOv5m、YOLOv5l 测试mAP@0.5 指标下降4.79 个百分点、6.74 个百分点。通过图7 看到,训练精度在150 轮之内就已经达到了最高值,在此之后长时间训练模型将学习到无用特征,导致在未接触过的数据集中表现下降。本文在模型训练过程中引入提前终止机制,当精度变换起伏连续15轮不超过1 个百分点时,认为模型已训练充分,此时提前终止训练。

图7 mAP@0.5随迭代次数的变化曲线Fig.7 Variation curve of mAP@0.5 with the number of iterations
1.2.9 针对梯度爆炸改善激活函数
实验发现原始YOLOv5 模型均出现了程度不一的梯度爆炸,如图8 所示,网络规模最深的YOLOv5l 梯度爆炸现象最为严重。本文根据链式法则,重新调配激活函数抑制梯度爆炸。
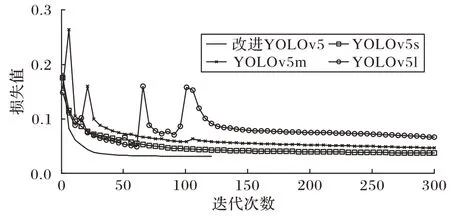
图8 损失值随迭代次数的变化曲线Fig.8 Variation curve of loss value with the number of iterations
原始YOLOv5 模型采用SiLU 激活函数,如式(1)所示,由图9 可知SiLU 部分导函数大于1,有概率导致梯度爆炸。本文将部分激活函数改进为LeakyReLU,如式(2)所示,由图9可知LeakReLU 的导函数保持≤1,可以避免梯度爆炸,且LeakyReLU 不含指数运算,计算开销小。
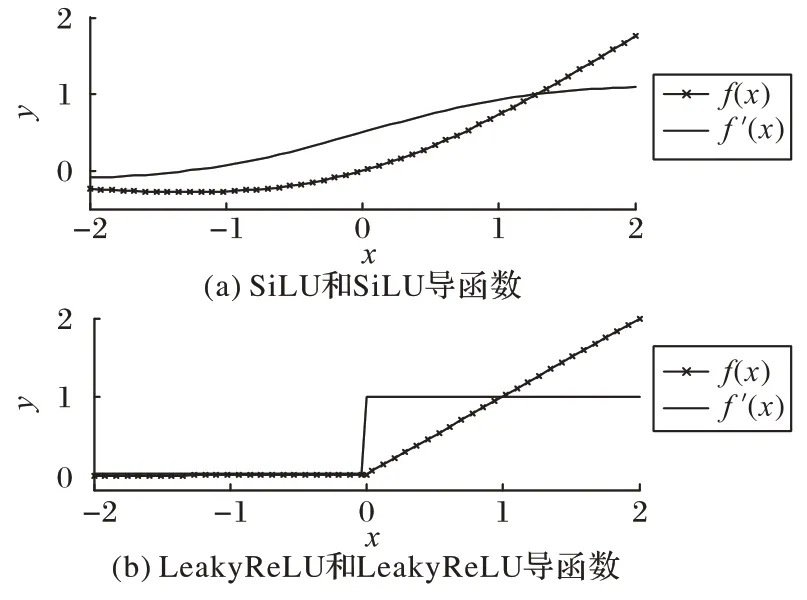
图9 激活函数以及导函数Fig.9 Activation function and derivative function
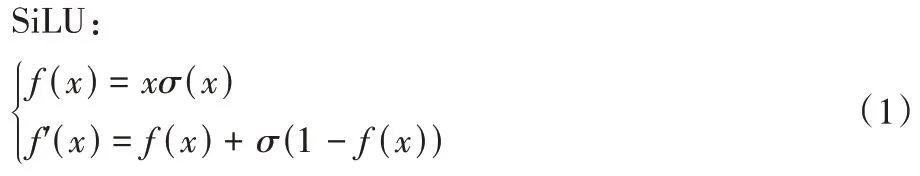
LeakyReLU:

1.3 改进YOLOv5检测算法
算法1 改进后的YOLOv5 检测算法。展示了改进后交通标志识别系统的工作原理,并列举了其中的关键处理步骤:
输入 训练权重weights,检测数据地址source,图像归一化大小img-size,置信度阈值conf-thres,IOU 阈值iou-thres;
输出 检测结果output。

算法2 mode 函数。前向传播是检测算法中的核心部分,mode 函数展示了输入图像在网络中前向传播的过程、各层模块的参数设置以及功能:伪代码中包含的注释//Pn,表示该步骤所得为原始输入的n倍下采样特征。序号1)~12)与传统卷积神经网络类似,输入图像逐层卷积得到最高层特征;序号13)~18)对应FPN 结构,最高层特征上采样后向下传递,各层级特征互补;序号19)~23)对应PAN 结构,特征再次向上传递,加强各层级特征融合;序号24)~25)为检测层。
输入 输入图像images;
输出 前向传播后的结果pred。


2 实验与结果分析
2.1 实验数据集
2.1.1 数据集概述
本文选用中国交通标志数据集TT100K。TT100K 基数庞大、语义信息丰富,采用高清摄像头拍摄真实街景图获得(如图10 所示),可还原驾驶第一视角、单一的机动车道或者复杂的城市背景;但数据集数量分布不均匀,出现次数最多的交通标志达1 479 次,最低的仅有112 次,网络在基数小的标志上难以收敛,同时数据集无法模拟在车辆驾驶中随时面临的低曝、过曝、雨雪、雾霾等恶劣天气。

图10 TT100K数据集样本Fig.10 TT100K dataset samples
2.1.2 数据集筛选
本文从TT100K 中筛选出具有重要语义信息的25 类交通标志,如图11 所示,包含机动车道指示牌、限速指示牌、禁止通行指示牌、禁止停车指示牌、注意行人指示牌等,25 类交通标志数量分布如图12 所示。

图11 25类交通标志Fig.11 Twenty-five kinds of traffic signs
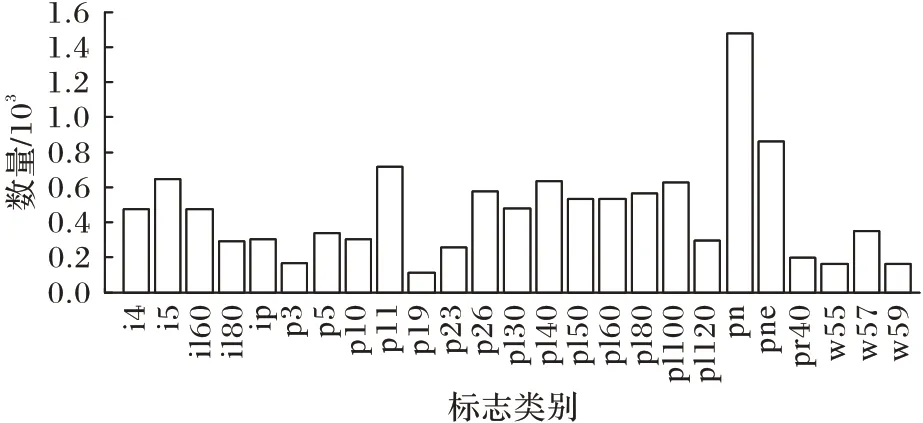
图12 增强前交通标志数量分布Fig.12 Traffic sign quantity distribution before augmentation
2.1.3 数据集增强
TT100K 中标志数量差距大,标志p19 仅出现112 次,导致网络无法学习到该类标志的特征。本文对数量少的标志进行扩充,扩充后各标志数量分布如图13 所示。
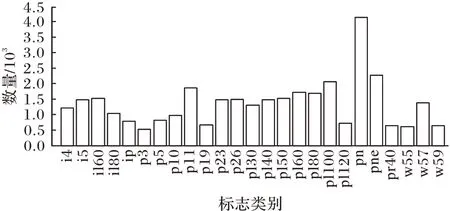
图13 增强后交通标志数量分布Fig.13 Distribution of traffic sign quantity after augmentation
本文使用python 语言编写的imgaug 库增强数据集,模拟驾驶过程中可能经历的过曝、欠曝、雾霾、雪天、雨天等恶劣天气,增强模型在恶劣天气下的鲁棒性,数据增强效果如图14 所示。

图14 增强后TT100K 数据集样本Fig.14 TT100K dataset samples after augmentation
2.1.4 数据集划分
本文将增强后的14 051 份样本按照6∶2∶2 划分为训练集、验证集、测试集。为测试模型在面对不同恶劣天气时性能,对测试集进一步划分:高清测试集、混合天气增强测试集、雾霾天气增强测试集。数据集文件组织如下:
1)训练集:8 438 份高清与天气增强样本混合。
2)验证集:2 717 份高清与天气增强样本混合。
3)测试集1:2 899 份高清与多种天气增强样本混合。
4)测试集2:580 份高清样本。
5)测试集3:580 份混合天气增强样本。
6)测试集4:580 份雾霾天气增强样本
2.2 实验结果
2.2.1 模型识别精度衡量指标
本文选用F1-score、mAP@0.5、mAP@0.5:0.95 作为模型精度衡量指标,三者依赖于混淆矩阵(Confusion Matrix)、精确率、召回率的计算。以下将简要介绍几者之间的关系:混淆矩阵将测试结果按表1 划分为真阳性(True Positive,TP)、真阴性(True Negative,TN)、假阳性(False Positive,FP)、假阴性(False Negative,FN),进一步运算可得到精确率与召回率,表中:TP为IOU≥阈值的预测框数量;FP为IOU<阈值的预测框数量;FN为没有检测到的目标数量。
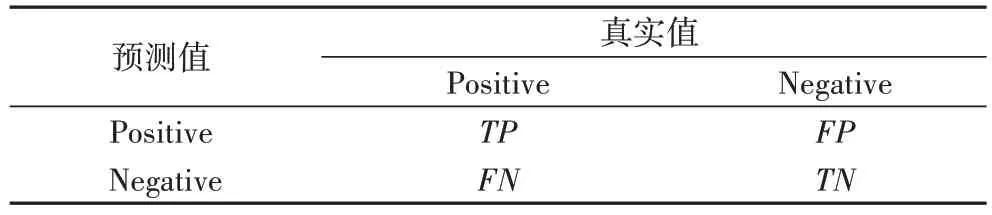
表1 混淆矩阵Tab.1 Confusion matrix
精确率(Precision,P)定义为所有预测值为Positive 的目标中真实值为Positive 的样本所占比例,精确率最直观衡量模型错检程度,计算见式(3):

召回率(Recall,R)定义为所有真实值Positive 的目标中预测值为Positive 的样本所占比例,召回率最直观衡量模型漏检程度,计算见式(4):

F1-score(F)为综合考虑精确率和召回率的指标,通常情况下精确率和召回率相互约制,在模型召回率提升时有可能伴随精确率下降,反之亦然。由于交通标志识别任务涉及驾驶安全等方面重要信息,对精确率、召回率具有高要求。本文采用精确率和召回率权重相同的F1-score,计算见式(5):

2.2.2 模型检测速率衡量指标
本文选用FPS 作为模型的检测速率衡量指标,FPS 定义为模型每秒可渲染显示的帧数量。人眼视觉的时间特性最低要求为15 FPS,当FPS>15 时,人眼认为检测流畅。
2.2.3 改进YOLOv5模型测试实验
为测试改进YOLOv5 模型检测性能,本文将所有模型都训练至理想状态,在测试集1 中评估识别精度、检测速率,结果如表2 所示。
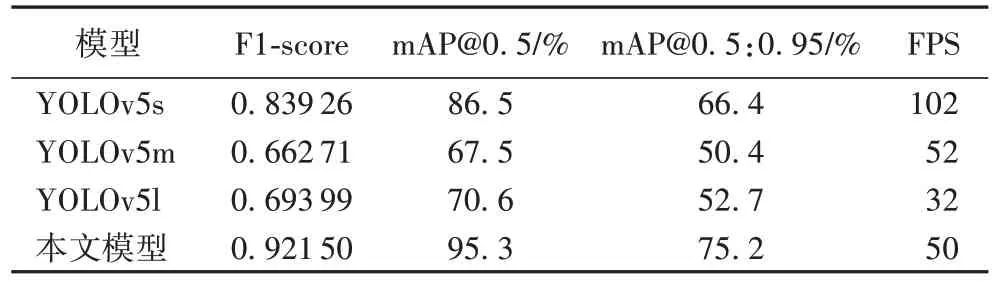
表2 不同YOLOv5模型性能对比Tab.2 Performance comparison of different YOLOv5 models
由表2 数据可知,改进YOLOv5 模型在各指标上均取得了显著提升。相较于YOLOv5s,F1-score 提升0.082 24;mAP@0.5 提升8.8 个百分点,各类别检测准确率显著提升;mAP@0.5:0.95 提升8.8 个百分点,模型高精度边界拟合能力增强;检测速率达50 FPS 满足实时性需求。数据对比发现,针对小目标为主的检测任务,模型深度过大导致标志特征受背景干扰,不利于特征学习;相反通过简化模型结构,融合多种精度提升机制可以取得较为理想的识别精度提升,模型结构简化也为检测速率提升带来积极作用。
2.2.4 模型受气候影响鲁棒性分析
为验证模型在不同恶劣天气下的鲁棒性,本文在测试集2、测试集3、测试集4 上测试实验,通过模型在增强测试集3、测试集4 上的精度下降幅度衡量不同天气对识别精度造成的影响以及模型的抗恶劣天气干扰能力,测试结果见表3~5 所示。
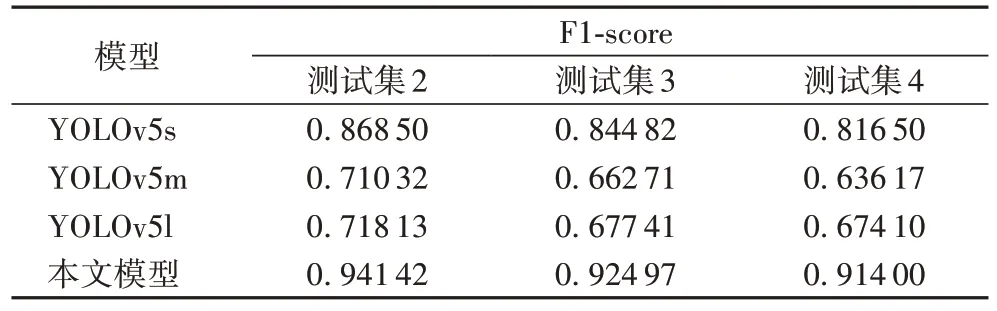
表3 不同天气下F1-score对比Tab.3 F1-score comparison in different weather conditions
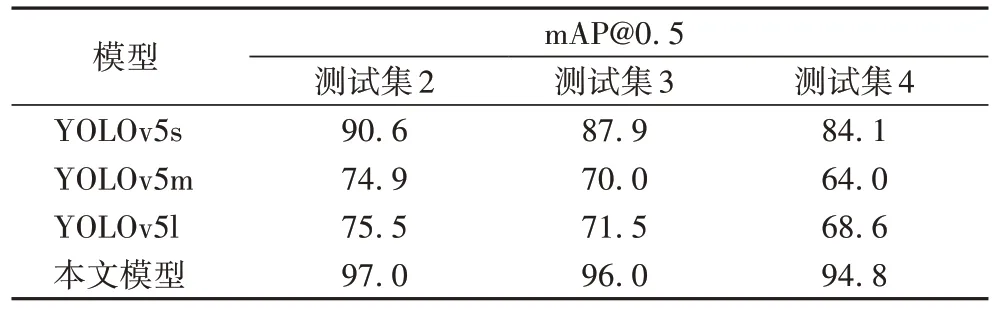
表4 不同天气下mAP@0.5对比 单位:%Tab.4 mAP@0.5 comparison in different weather conditions unit:%
由表3~5 测试数据可知恶劣天气对模型识别精度造成了显著影响,各个模型精度均存在不同程度的下降。在多种恶劣天气中,雾霾天气对模型检测精度影响最为显著,YOLOv5m 模型F1-score下降0.074 15、mAP@0.5下降10.9个百分点、mAP@0.5:0.95 下降8.3 个百分点。本文模型具备较好的泛化能力,在恶劣天气下也能提取出有效的特征信息,将天气影响控制在理想范围内,检测精度均维持在95%上下,波动不超过0.2%,属于可接受范围。
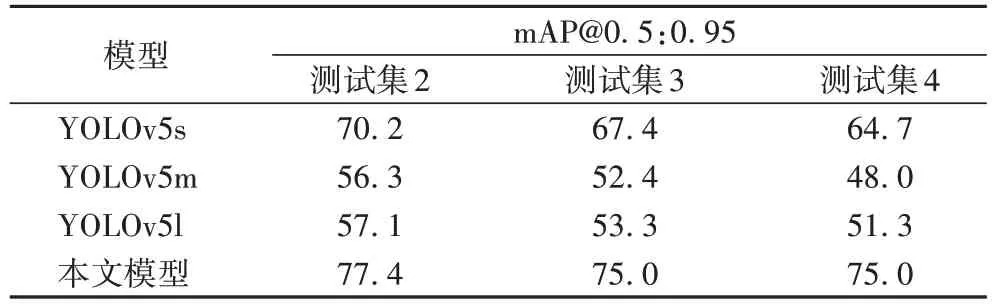
表5 不同天气下mAP@0.5:0.95对比 单位:%Tab.5 mAP@0.5:0.95 comparison in different weather conditions unit:%
2.2.5 多种雾霾天气下交通标志识别模型对比
雾霾天气造成模型精度下降是多种恶劣天气中最为显著的,本文将多种雾霾天气下交通标志识别模型进行测试比较,YOLOv5 模型作为分类器,前端融合抗雾霾干扰滤波器:包括基于图像复原理论的暗通道先验滤波(Dark Channel Prior,DCP)、基于图像增强理论的带色彩恢复的多尺度视网膜恢复算法(Multi-Scale Retinex with Color Restoration,MSRCR)滤波、直方图均衡化(Histogram Equalization,HE)、基于神经网络的一体化去雾网络(All-in-One Network for Dehazing,AOD-Net)。模型在测试集4 中测试,结果如表6 所示,组别1 采用本文改进模型在增强数据集中训练、雾霾数据集中测试;组别2 采用本文改进模型在无增强数据集中训练、测试作为对照;组别3~7 采用原始YOLOv5s 模型。各模型前端分别做以下处理:组别3 不采用滤波器、组别4 融合DCP 滤波器、组别5 融合MSRCR 滤波器、组别6 融合HE 滤波器、组别7 融合AOD-Net 滤波器,皆在无增强数据集中训练,雾霾数据集中测试;组别8 采用文献[27]算法,组别9 采用文献[28]算法,训练与测试数据集均与组别1 保持一致。

表6 多种模型对比Tab.6 Comparison of several models
组别3 无滤波器的模型在雾霾测试集中表现急剧下降,F1-score 为0.774 31 相对无雾霾干扰下降0.116 81、mAP@0.5 仅为77.6%下降15.3 个百分点、mAP@0.5:0.95仅为58.4%下降12.7 个百分点,原始模型在雾霾天气下交通标志识别效果极为不理想。模型前端融合去雾滤波器后识别精度获得明显提升,增加AOD-Net 滤波网络后,F1-score提升0.054 88,mAP@0.5 提升6 个百分点,mAP@0.5:0.95 提升4.7 个百分点,有效改善雾霾天气下识别精度,但还有待进一步提升。组别8、9 相对于原始模型具有精度上的优势,但F1-score 和mAP@0.5 低于无雾霾干扰状态下的测试结果,本文模型改进了此缺陷,在雾霾干扰下可获得高精度的检测结果。模型检测部分结果如图15 所示,组别3 在雾霾天气下漏检明显;组别4~7 通过滤波处理复原、增强图像边缘、颜色细节,模型检测结果取得一定程度改善,但仍未达到较理想状态;组别8、9 可检测出大部分目标,但存在部分小体型目标漏检。改进YOLOv5 模型没有复原雾霾图像,借助强拟合能力取得了较好的检测结果。改进YOLOv5 模型在增强数据集中学习特征,具备在最恶劣的雾霾天气下提取理想特征的能力,在测试集中精度提升效果明显,改进后模型具备克服恶劣天气引起的精度下降的能力。

图15 模型检测结果Fig.15 Model detection results
3 结语
本文提出了一种基于YOLOv5 的雾霾天气实时交通标志识别模型,对YOLOv5 模型结构进行优化,并引入多种提高识别精度机制,通过削减特征金字塔深度、限制最高下采样倍数解决小目标难以识别问题;通过调整残差模块特征传递深度,抑制背景特征的重复叠加;引入数据增强、K-means先验框、全局非极大值抑制等机制到网络模型;针对实际应用的需求,提高网络在面对恶劣天气时识别的鲁棒性。通过在不同测试集,对比其他模型,改进后模型在面对恶劣天气时具备强泛化能力,且保持识别精度的稳定性。本文模型也存在一定的局限性,从众多交通标志中只选取25 类进行实验,模型可检测交通标志的种类可进一步进行扩展。针对智能驾驶系统的需求,将模型移植入算力有限的移动终端,并取得实时的性能进行测试。这两点也是下一阶段的改进和研究的目标。
