基于词向量的npm包推荐标签方法
2022-09-24刘宣彤刘华虓郜山权
孙 凯, 刘宣彤, 张 莉, 刘华虓, 王 禹, 郜山权
(1. 吉林大学 计算机科学与技术学院, 长春 130012; 2. 外交学院 英语系, 北京 100037;3. 白城医学高等专科学校 信息化学院, 吉林 白城 137000)
目前, JavaScript编程语言已广泛应用于Web浏览器和服务器上[1], 为帮助开发者分享和重用代码, npm(node package manager)不仅是管理JavaScript第三方库的管理工具, 同时也已成为分享代码的开源平台. 随着npm包(第三方库)的不断发展, 越来越多的软件系统依赖于npm包所提供的多样且高效的功能.
当开发者需要一个合适的npm包满足开发需求时, 其庞大的数量使开发者需耗费大量的时间用于搜索. 而标签作为简洁、 直观的描述方式, 为开发者在搜索过程中提供了有效的帮助[2]. 开发者不仅可通过浏览标签快捷地获得包的描述信息, 而且可通过点击标签获得与该标签相关的所有包, 即通过使用标签缩小搜索的范围[3]. 包的创建者为创建的包打上恰当的标签可提高其被索引到的概率, 从而被更多的开发者使用. 但有超过40%的npm包没有标签, 而且由于赋予标签的方式和标签的内容都具有极大的自由度, 使得一些包的标签质量较低, 无法具有展示包功能的作用.
因此, 本文提出一种为npm包推荐标签的自动化方法. 首先, 对npm平台中现有的标签进行分析, 根据标签内容与彼此之间的相关程度解决标签同义问题, 建立标签库; 其次, 利用包的Readme文档进行词向量的训练, 借助词向量挖掘出包的描述文本与标签库中标签的联系; 最后, 由计算得到的关联程度进行排序生成标签推荐列表, 完成标签推荐工作.
1 方法设计
本文首先分析npm社区中已存在的标签, 用关联关系挖掘算法构建标签关联关系网络图, 并利用社区检测算法将标签聚成社区, 在每个标签社区中, 整合具有相同语义的标签, 以解决标签同义的问题并生成标签库; 然后利用word2vec技术将npm包的Readme文件作为训练文本进行词向量的训练; 最后根据得到的标签库与生成的词向量, 给定一个没有标签的npm包, 以计算其Readme中的单词词向量与标签库中标签的相关度, 生成标签推荐列表. 方法流程如图1所示.

图1 方法流程Fig.1 Flow chart of method
1.1 构建标签库
由于npm包的创建者可自由地为其包打上任意内容、 任意数量的标签, 无任何约束, 从而导致npm社区的标签数量庞大, 种类繁多, 却没有一致性[4]. 标签作为展示包特点的窗口, 应具有简洁、 直观、 易懂的特点[5], 但打标签是一个具有分布式特点且不协调的过程, 使得npm社区出现很多冗余的标签. 为达到推荐恰当标签的目的, 本文首先对现有标签进行分析整合, 构建一个合理的标签库.
在现有标签中, 一些标签的出现率极低, 因为这些标签具有定制化的特性, 只适合于所属项目. 但主要还是因为这些标签的内容很难使大多数开发者认同, 无法得到广泛使用. 此外, 很多标签是以不同的语法形式表达相同的语义, 如log,logs和logging都是指代日志功能. 同一单词的不同语法形式导致标签的冗余, 从而在通过标签进行搜索的管理过程中造成不便. 对于以单词作为内容呈现的标签, 除上述语法问题外, 还存在单词缩写和单词同义问题, 这些问题统称为标签同义词问题[6].
定义1标签句TagSentence可定义为对于存在标签的npm包p, 所属于p的所有经过词干提取和词形还原的标签{t1,t2,…,tn}构成的标签集.
定义2标签关联关系ti⟹tj可定义为对于两个标签ti和tj, 若存在由关联关系挖掘算法[7]得到的Lift(ti⟹tj)大于阈值threshold, 则认定两标签构成关联关系:
其中confidence(ti⟹tj)计算拥有这两个标签的标签句占只含有标签ti的标签句比例, support(ti)计算标签ti出现在所有标签句中的次数, #tagSent表示tagSentence的数量.
定义3标签关联图G〈V,E〉定义为对于标签关联关系ti⟹tj, 标签ti,tj作为图G〈V,E〉中以无向线段连接的两个节点, 所有存在标签关联关系的标签构成节点集V, 其关联关系构成边集E.
图2为标签关联图的样例.本文利用关联社区检测方法[8], 使位于同一社区内的标签具有相同颜色.通过人工观察标签关联图, 找出拥有相同语义的标签归为一类, 在每类中选择出现频率最高的标签作为代表标签构建成标签库TL={T1,T2,…,Tn}.

图2 标签关联图样例Fig.2 Sample of a tag correlation graph
1.2 训练词向量
npm包的Readme文档详细地给出了包的功能、 使用方法、 安装环境等信息, 所以可利用Readme文档中描述功能的文本计算与标签的关联. 本文将Readme描述功能的文本作为训练数据, 利用skip-gram模型[9]得到的词向量完成后续的标签关联度计算过程.
标签是对每个npm包的总结概述或描述其所拥有的特性, 而这些内容开发者也可通过阅读包的Readme 文档得到, 因此可通过挖掘Readme文档中的相关信息实现推荐标签. 由于包的Readme文档所呈现的内容角度多(简介、 使用方法、 参与者等)且形式多样(文字、 图片、 表格等), 而只有介绍包功能的描述文本才是挖掘的对象, 所以本文首先对Readme文档进行处理, 抽取其中介绍包功能的描述文本并进行预处理. 研究表明, 大多数包Readme文档的第一章文字都是介绍包的主要功能和特性[10], 这与标签所展示的内容相符, 所以抽取这部分内容作为可利用的描述文本.
定义4Readme Token序列Lp定义为对包p原始Readme文档描述文本Dp移除其中的图片、 表格及超链接后, 再进行分词、 词干提取及词形还原得到的单词序列.

图3 Skip-gram模型Fig.3 Skip-gram model
词向量是对单词的低维向量表示, 其建立在具有相似含义的单词在相似上下文中呈现的假设上. 单词的词向量可捕捉到单词在文中的语义信息, 即可以使用词向量比较单词之间的语义相似度[11]. skip-gram模型[12]是一种高效的学习词向量方法, 该模型由一个简单的3层神经网络组成, 包括输入层、 隐藏层和输出层, 如图3所示, 其中w(t)是中心词, 也称为给定输入词.首先, 隐藏层执行权重矩阵和输入向量w(t)之间的点积运算; 其次, 隐藏层中的点积运算结果被传递到输出层; 最后, 输出层计算隐藏层输出向量和输出层权重矩阵之间的点积, 再用Softmax激活函数[13]计算在给定上下文位置中单词出现在w(t)上下文中的概率.通过skip-gram算法, 每个单词都会得到一个词向量. 某个词在句子中的位置与中心词的位置越近, 则通过skip-gram 算法获得该词的词向量与中心词的词向量在向量空间中越接近, 即词向量间的关系反映了词在句子中的密切程度[14].
定义5词向量Vw定义为以Readme Token序列R形式为样本的训练集在skip-gram模型中训练得到的关于单词w的向量.
由于标签是以单词的形式对npm包进行概括性地描述, 使得同样具有描述功能且更详细的Readme文档中的描述文本会覆盖标签的内容, 即标签会出现在Readme文档中. 因此, 词向量Vw也可作为以单词w为内容的标签T的向量, 记为VT.
1.3 标签关联度计算
本文通过计算描述文本中的单词与标签库中标签的词向量相似度建立两者之间的联系, 再对取得联系的标签进行排序, 最终挑选出合适的标签进行推荐. 词向量的语义相似度可捕捉到文本中单个单词与标签的关联程度, 而描述文本由许多单词组成, 对所有单词进行相似度的计算即能捕获整个描述文本与标签的关联程度. 但单词在描述文本中出现的频次在一定程度上影响了文本的主题, 因此本文考虑词频对标签相关度的影响, 从而更准确地计算描述文本与标签的关联程度. 算法描述如下:
步骤1) 抽取Readme文档中的描述文本Dp并进行预处理, 生成 Token序列Lp;
步骤2) 对Token序列Lp中每个单词w的词向量Vw与标签库中每个标签T的词向量VT进行语义相似度的计算, 结果为Sw,T;
步骤3) 由单词w在Token序列Lp中的词频TF(w)与Sw,T的乘积得到关于词频的相关度Rw,T, 并将结果按对应的标签进行累加, 最终生成每个标签与描述文本Dp的关联程度RT;
步骤4) 根据标签与描述文本的相关程度RT进行排序, 得到标签推荐列表;
步骤5) 推荐排名前k的标签.
算法1RT.
输入: ReadmeRpof npm packagep; Tag LibraryTL={T1,T2,…,Tn};
输出: topktags;
1) Extract descriptionDpfromRp;
2) Generate token listLpby preprocessingDp;
3) forw∈Lpdo
4) forT∈TLdo
5)Sw,T=Similarity(Vw,VT);
6)Rw,T=Sw,T×TF(w);
7)RT=RT+Rw,T;
8) end for;
9) end for;
10) rank the tags according toRT;
11) return the topktags.
2 实验验证
2.1 实验设计
在构建标签库和训练词向量两个步骤中, 都需要可靠的数据样本作为数据集. 本文在选取实验数据集时进行如下操作:
1) 考虑到现有标签数量庞大, 且很多标签利用率极低, 本文选择最流行的8 000个包作为样本;
2) 根据对npm包的质量、 流行度、 维护程度的官方评价指标, 本文选择在样本中综合评分在60分以上的包作为数据集, 以保证实验数据有高质量的Readme文档和标签;
3) 对标签数大于10的包进行过滤, 这是因为过多的标签对npm是冗余的, 也无法确定哪些标签必要, 最终数据集包含6 753个npm包;
4) 从数据集中随机抽取100个包作为最终的测试集.
由数据集构建的标签库包含126个代表标签, 代表标签与其同义标签的部分示例列于表1.

表1 代表标签与其同义标签的部分示例
实验与两种最新的针对开源软件仓库进行主题推荐的方法进行对比: 文献[2]提出在Github开源软件仓库中利用多种文本信息训练多标签分类器以达到最好的主题预测效果; 文献[6]提出基于Multinomial Naive Bayes算法对Github开源软件仓库进行主题分类以生成推荐主题. 其中两种对比方法使用的数据集与本文方法一致, 本文进行多次实验, 取最好结果进行对比.
选择Recall@k作为实验指标[15]. 在推荐方法的评价指标中, Precision@k和Recall@k是最常用的两个指标, 而Recall@k更符合本文问题的设定, 定义为
其中n是测试集的总数, Tagp是包p的实际拥有标签, Recp是方法为包p推荐的top-k标签.
2.2 实验结果
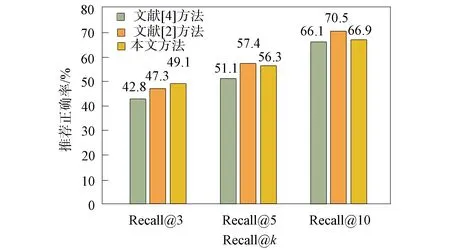
图4 实验结果Fig.4 Experimental results
图4为本文推荐标签方法的性能. 实验结果表明, 本文方法能完成为npm包推荐标签的工作. 由图4可见: 推荐得分最高的3个标签时, Recall@3为49.1%; 推荐得分最高的5个标签时, Recall@5为56.3%, 即超过50%的标签都推荐正确; 而推荐得分最高的10个标签时, 正确率提高了10%. 本文方法在3项指标上都高于文献[6]方法, 在Recall@5和Recall@10指标上接近文献[2]方法, 且在更精细的Recall@3指标上本文方法性能更好.
对推荐错误的标签进行分析, 主要原因有: 某些包的Readme文档描述文本过少, 不能从中抽取到足够的信息, 也无法通过词频显现出描述文本的主题, 从而导致本文方法无法准确地构建包与标签之间的联系, 最后导致分析结果错误. 由于文献[2]方法不仅利用了Readme文档而且利用了文件名、 wiki等文本进行数据挖掘训练, 所以在推荐数量较多标签时效果略优于本文方法, 但当推荐标签数量较少时, 本文方法准确率更高.
综上所述, 本文提出了一种为npm包推荐标签的方法, 通过解决现有标签同义词的问题建立标签库, 并基于词向量挖掘包的描述文本与标签之间的语义关系实现标签推荐. 实验结果表明, 该方法能有效完成推荐标签的工作.
